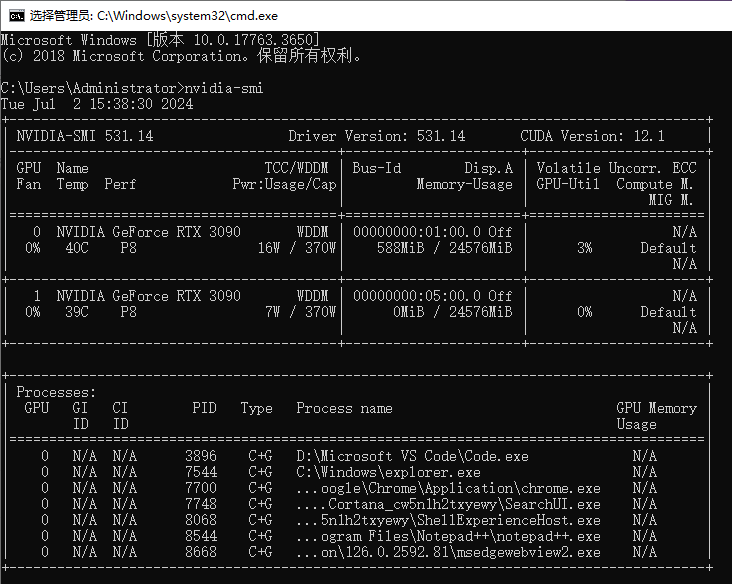
一、确认本机显卡配置
二、下载大模型
国内可以从魔搭社区下载,
下载地址:https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/files
三、运行官方代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("E:\openai\ChatGLM4\glm-4-9b-chat", trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"E:\openai\ChatGLM4\glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))结果如下
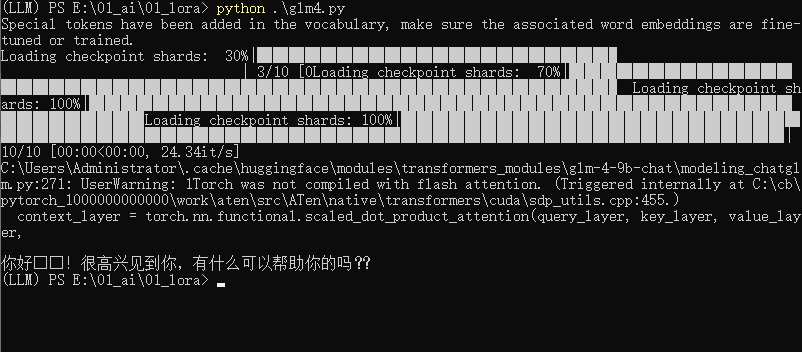
中间需要安装环境,建议用anaconda来安装
官方文档中说到可以用vLLM的方式跑起来,即CPU的方式
使用 transformers 后端进行推理 使用 vLLM 后端进行推理: 区别是什么
使用不同的后端进行推理,主要区别在于性能、灵活性和易用性方面。以下是使用transformers后端和vLLM后端进行推理的一些区别:
性能:transformers后端使用硬件加速(如GPU、TPU等)进行推理,因此在处理大量数据和复杂模型时具有更高的性能。而vLLM后端使用CPU进行推理,性能相对较低,但适用于轻量级模型和移动设备。
灵活性:transformers后端支持多种预训练模型和任务,如文本分类、命名实体识别、机器翻译等。您可以根据需求选择合适的模型。vLLM后端主要针对轻量级语言模型,适用于文本生成和补全任务。
易用性:transformers后端提供了丰富的API和工具,方便用户进行模型加载、推理和部署。vLLM后端相对较简单,易于在移动设备和嵌入式设备上集成和使用。
资源消耗:transformers后端在推理过程中可能消耗较多的计算资源和内存,尤其是在使用大型模型时。vLLM后端资源消耗相对较低,适合在资源受限的环境中运行。
总之,选择哪种后端进行推理取决于您的具体需求,包括任务类型、性能要求、资源限制等因素。如果需要高性能、灵活性和丰富的功能,可以选择transformers后端;如果关注轻量级、易于集成和低资源消耗,可以选择vLLM后端。
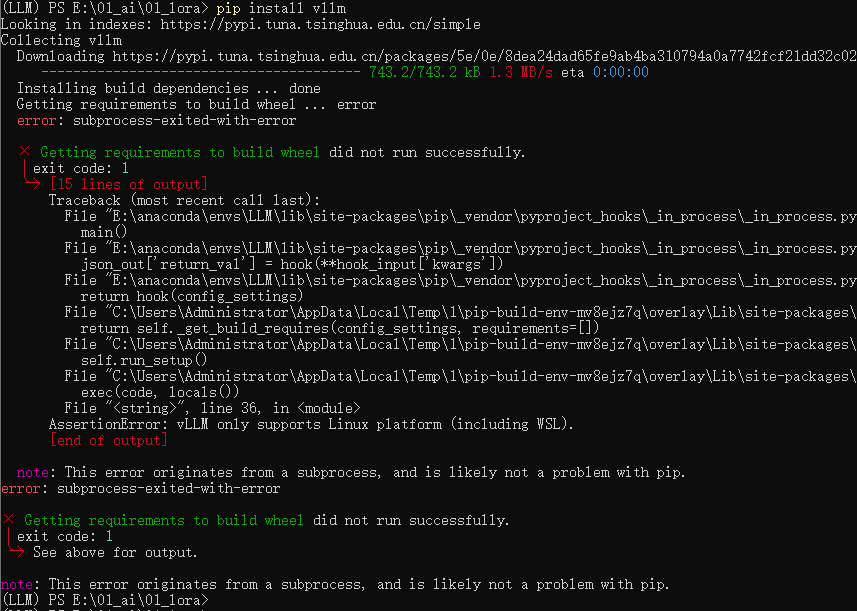
python安装vLLM的时候报错,只能装在linux上