简介
最近开始用3568的板子,之前是在用3399,cpu的话3399比3568强,但是3568有1T的npu算力,所以模型移植过来用npu使用,之前用ncnn感觉太慢了,rk的npu使用没有开源,所以没法兼容,只能跑rknn了。
rk3568查询npu命令,通过adb shell进入,android系统
1、查询npu使用率
cat /sys/kernel/debug/rknpu/load
2、查询npu电源开关
cat /sys/kernel/debug/rknpu/power
3、查询npu当前频率
cat /sys/class/devfreq/fde40000.npu/cur_freq
4、查询npu驱动版本
cat /sys/kernel/debug/rknpu/driver_version
有些版本可以有限制,无法查询当前的命令,但是如果代码能够正常执行就行。
这里采用的模型是 insightface 的 det_500m.onnx 模型,用来做人脸目标检测。
环境部署&模型转换
我这边采用的docker方式,自己不想部署环境了,直接用现成的镜像快,只是docker有点大,有10g多。
1、下载镜像
地址:
https://meta.zbox.filez.com/v/link/view/ef37a9687973439f94f5b06837f12527提取码:
rknn需要下载对应的客户端才可以直接下载,下载速度还可以
下载如下两个文件

主要要用的是:rknn-toolkit2-2.0.0b0-cp38-docker.tar.gz
确保docker已经安装,直接docker ps 看看是否包含
docker ps我的docker是安装在centos里面

2、加载镜像
docker load --input rknn-toolkit2-2.0.0b0-cp38-docker.tar.gz需要等待一会儿,成功了可以通过
docker images查询出如下就代码加载成功了。

3、执行镜像-创建容器rknn2
执行镜像,把容器的名称改为rknn2
docker run -t -i --privileged --name=rknn2 rknn-toolkit2:2.0.0b0-cp38 /bin/bash在容器里面创建一个文件夹,在根目录创建/
cd /
mkdir model4、拷贝onnx模型到容器
记住得在宿主机拷贝,不能进入容器拷贝
docker cp model/det_500m_sim.onnx rknn2:/model/5、创建转换脚本-转换模型脚本
查询model下面是否包含了det_500m_sim.onnx
然后再model下面创建一个目录rknn
cd /model/
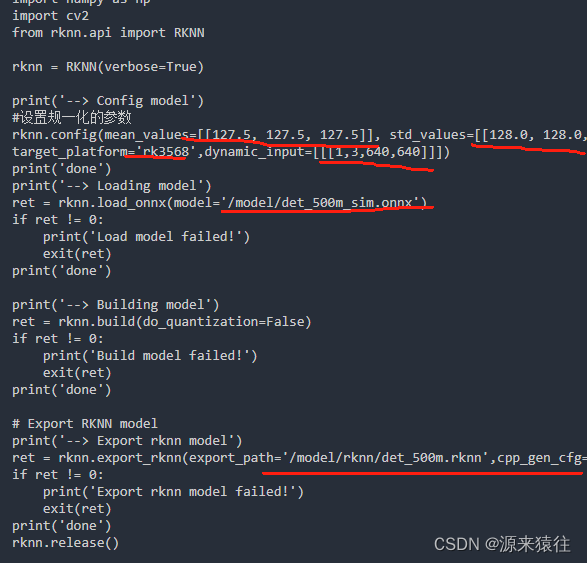
mkdir rknn其中归一化参数按照训练代码里面填写
*注意还有target_platform 为板子型号,这里写rk3568
*如果包含动态入参,必须要添加dynamic_input ,我这里指定了一个\[\[1,3,640,640]] ,如果有多个就输入多个,在执行的时候也需要相应执行 rknn_set_input_shapes 设置参数的输入类型
具体代码如下:
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
rknn = RKNN(verbose=True)
print('--> Config model')
#设置规一化的参数
rknn.config(mean_values=[[127.5, 127.5, 127.5]], std_values=[[128.0, 128.0, 128.0]], target_platform='rk3568',dynamic_input=[[[1,3,640,640]]])
print('done')
print('--> Loading model')
ret = rknn.load_onnx(model='/model/det_500m_sim.onnx')
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
print('--> Building model')
ret = rknn.build(do_quantization=False)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export rknn model')
ret = rknn.export_rknn(export_path='/model/rknn/det_500m.rknn',cpp_gen_cfg=False)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
rknn.release()具体内容如上,具体参数可以参考文档:
如果参数我这边写的,修改如下的参数就行了
03_Rockchip_RKNPU_API_Reference_RKNN_Toolkit2_V2.0.0beta0_CN.pdf
文档地址:(需要翻墙)
csdn:(rknn说明文件打包)
https://download.csdn.net/download/p731heminyang/89482092
6、执行转换脚本-转换模型
python convert.py具体如下,没有报错
在rknn目录下查询是否包含 rknn的模型,我这边执行了几次所以有几个。

7、从容器中拷贝模型出来
*必须在宿主机上面执行,不然无法拷贝
docker cp rknn2:/model/rknn/det_500m_sim.rknn ./如果显示成功,那么模型就拷贝出来了。
android模型部署
1、获取android库
采用的是rknn-api,首先需要下载对应的android lib库
2.0.0b0\rknn-toolkit2-v2.0.0-beta0\rknn-toolkit2-v2.0.0-beta0\rknpu2\runtime\Android\librknn_api
这个把之前另外一个下载的文件解压

进入后可以看到android的lib库
找到这个了就可以引用了。
2、编写代码
参考文档:rk的官方文档,参数传参参考
04_Rockchip_RKNPU_API_Reference_RKNNRT_V2.0.0beta0_CN.pdf
github:
csdn:(rknn说明文件打包)
https://download.csdn.net/download/p731heminyang/89482092
封装代码如下
*如果是动态输入,每次切换输入值的时候,都需要提前指定输入的shapes,我就是在这里卡了很久,而且不报错,直接就不执行了。
rknn运行流程
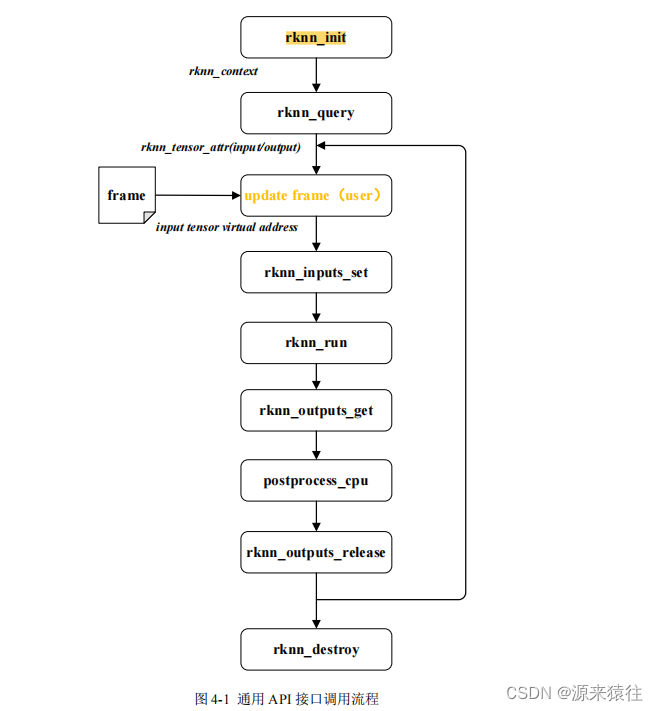
RknnBase.h
//
// Created by Administrator on 2024/6/20.
//
#ifndef NCNNFACE_RKNNBASE_H
#define NCNNFACE_RKNNBASE_H
#include "rknn_api.h"
#include <vector>
#include <android/asset_manager.h>
#include <android/asset_manager_jni.h>
//rknn输入输出内存自动管理模块
class RknnTesnsor{
public:
RknnTesnsor();
RknnTesnsor(const RknnTesnsor& rhs) ; // 拷贝构造函数
virtual ~RknnTesnsor();
RknnTesnsor& operator=(const RknnTesnsor& other) ;
bool alloc(int in_count, int out_count,
rknn_tensor_attr *p_input_attrs,rknn_tensor_attr *p_output_attrs );
void init();
bool isOk();
rknn_input* getInput();
rknn_output* getOutput();
int getInputCnt();
int getOutputCnt();
private:
void free();
private:
uint32_t n_input;
uint32_t n_output;
rknn_input *p_input;
rknn_output *p_output;
bool isSuc;
volatile int * ref_cnt ;
};
//rknn模型操作功能类
class RknnBase {
public:
RknnBase();
virtual ~RknnBase();
//动态输入的时候设置输入 参数
int setInputShapes(rknn_tensor_attr *p_input_attrs, int input_count);
//创建模型
//图片的宽高 通道、模型路径、是否零拷贝
int create(int im_height, int im_width, int im_channel, char *model_path,
bool isZeroCopy = false);
//如果使用assert路径
int create(AAssetManager* mgr,int im_height, int im_width, int im_channel, char *model_path,
bool isZeroCopy = false);
//模型执行解析
int detect(rknn_input *input, int in_count, rknn_output * output, int out_count);
//根据模型构建输入输出空间 根据isSuc是否返回
RknnTesnsor alloc(bool &isSuc);
protected:
//初始化输入输出结构信息
virtual int init_inout(int in_count, int out_count);
private:
void free_attr();
int init_deal(int im_height, int im_width, int im_channel,
bool isZeroCopy = false);
protected:
rknn_context ctx;//rknn句柄
uint32_t n_input;//输入个数
uint32_t n_output;//输出格式
rknn_tensor_attr *p_input_attrs;//输入属性
rknn_tensor_attr *p_output_attrs;//输出属性
rknn_tensor_mem **p_input_mems;//输入内存,采用rknn分配内存,0拷贝
rknn_tensor_mem **p_output_mems;//输出内存,采用rknn分配内存,0拷贝
int img_width ;
int img_height;
int m_in_width;
int m_in_height ;
int m_in_channel;
bool m_isZeroCopy;
bool created;
};
#endif //NCNNFACE_RKNNBASE_HRknnBase.cpp
//
// Created by Administrator on 2024/6/20.
//
#include "../include/RknnBase.h"
#include <cstdarg>
#include <cstdio>
#include <cstdlib>
#include <fstream>
#include <iostream>
#include <memory>
#include <sstream>
#include <string>
#include <ctime>
#include <cstdint>
#include <android/log.h>
#define RKNN_LOGI(...) __android_log_print(ANDROID_LOG_INFO, "rknn", ##__VA_ARGS__);
#define RKNN_LOGE(...) __android_log_print(ANDROID_LOG_ERROR, "rknn", ##__VA_ARGS__);
#ifdef __cplusplus
#define IM_C_API extern "C"
#define IM_EXPORT_API extern "C"
#else
#define IM_C_API
#define IM_EXPORT_API
#endif
int getTensorTypeSize(rknn_tensor_type type){
int sizeLen = 0;
switch(type){
case RKNN_TENSOR_INT8:
case RKNN_TENSOR_UINT8:
sizeLen = sizeof(char);
break;
case RKNN_TENSOR_INT16:
case RKNN_TENSOR_UINT16:
case RKNN_TENSOR_FLOAT16:
sizeLen = sizeof(short);
break;
case RKNN_TENSOR_FLOAT32:
case RKNN_TENSOR_INT32:
case RKNN_TENSOR_UINT32:
sizeLen = sizeof(float);
break;
case RKNN_TENSOR_INT64:
sizeLen = sizeof(int64_t);
break;
case RKNN_TENSOR_BOOL:
sizeLen = sizeof(bool);
break;
}
return sizeLen;
}
RknnBase::RknnBase():
n_input(0),n_output(0),ctx(0),p_input_attrs(NULL),p_output_attrs(NULL),
p_input_mems(NULL),p_output_mems(NULL),m_isZeroCopy(false),
img_width(0),img_height(0),m_in_width(0),m_in_height(0),m_in_channel(0),
created(false)
{
}
RknnBase::~RknnBase(){
for (int i = 0; i < n_input; ++i) {
rknn_destroy_mem(ctx, p_input_mems[i]);
}
for (int i = 0; i < n_output; ++i) {
rknn_destroy_mem(ctx, p_output_mems[i]);
}
rknn_destroy(ctx);
this->free_attr();
}
int RknnBase::init_inout(int in_count, int out_count){
if (in_count <= 0 || out_count <= 0){
RKNN_LOGI("in_count:%d out_count:%d fail!\n",in_count, out_count);
return 101;
}
n_input = in_count;
n_output = out_count;
this->free_attr();
p_input_attrs = new rknn_tensor_attr[n_input];
if (NULL == p_input_attrs){
RKNN_LOGI("new input_attrs(cnt %d total:%d) fail!\n",n_input, n_input * sizeof(rknn_tensor_attr));
return 102;
}
p_output_attrs = new rknn_tensor_attr[n_output];
if (NULL == p_output_attrs){
RKNN_LOGI("new output_attrs fail!\n");
this->free_attr();
return 102;
}
if (m_isZeroCopy){
p_input_mems = new rknn_tensor_mem*[n_input];
if (NULL == p_input_mems){
RKNN_LOGI("new p_input_mems fail!\n");
this->free_attr();
return 102;
}
p_output_mems = new rknn_tensor_mem*[n_output];
if (NULL == p_output_mems){
RKNN_LOGI("new p_output_mems fail!\n");
this->free_attr();
return 102;
}
}
return 0;
}
void RknnBase::free_attr(){
if (NULL != p_input_attrs){
delete []p_input_attrs;
p_input_attrs = NULL;
}
if (NULL != p_output_attrs){
delete []p_output_attrs;
p_output_attrs = NULL;
}
if (NULL != p_input_mems){
delete p_input_mems;
p_input_mems = NULL;
}
if (NULL != p_output_mems){
delete p_output_mems;
p_output_mems = NULL;
}
}
int RknnBase::setInputShapes(rknn_tensor_attr *input_attrs, int input_count){
int ret = rknn_set_input_shapes(ctx, input_count, input_attrs);
if (ret != RKNN_SUCC){
RKNN_LOGE("rknn_set_input_shapes error:%d",ret);
return -1;
}
return ret;
}
int RknnBase::init_deal(int im_height, int im_width, int im_channel,bool isZeroCopy ){
img_height = im_height;
img_width = im_width;
m_in_channel= im_channel;
m_isZeroCopy = isZeroCopy;
created = false;
int ret = 0;
// 获取模型SDK版本
rknn_sdk_version sdk_ver;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &sdk_ver, sizeof(sdk_ver));
if (ret != RKNN_SUCC)
{
fprintf(stderr, "rknn_query error! ret=%d\n", ret);
return -1;
}
RKNN_LOGI("rknn_api/rknnrt version: %s, driver version: %s\n", sdk_ver.api_version, sdk_ver.drv_version);
// 3. Query input/output attr.
rknn_input_output_num io_num;
rknn_query_cmd cmd = RKNN_QUERY_IN_OUT_NUM;
// 3.1 Query input/output num.
ret = rknn_query(ctx, cmd, &io_num, sizeof(io_num));
if (ret != RKNN_SUCC) {
RKNN_LOGE("rknn_query io_num fail!ret=%d\n", ret);
return -1;
}
n_input = io_num.n_input;
n_output = io_num.n_output;
// 3.2 Query input attributes
if (0 != init_inout(n_input,n_output)){
RKNN_LOGE("init_inout fail!\n");
return -1;
}
memset(p_input_attrs, 0, n_input * sizeof(rknn_tensor_attr));
for (int i = 0; i < n_input; ++i) {
p_input_attrs[i].index = i;
cmd = RKNN_QUERY_INPUT_ATTR;
ret = rknn_query(ctx, cmd, &(p_input_attrs[i]), sizeof(rknn_tensor_attr));
if (ret < 0) {
RKNN_LOGE("rknn_query input_attrs[%d] fail!ret=%d\n", i, ret);
return -1;
}
RKNN_LOGI("fmt:%s n:%d height:%d width:%d channel:%d type:%s size:%d\n",
get_format_string(p_input_attrs[i].fmt),p_input_attrs[i].dims[0],
p_input_attrs[i].dims[1], p_input_attrs[i].dims[2],p_input_attrs[i].dims[3],
get_type_string(p_input_attrs[i].type), p_input_attrs[i].size);
}
// 3.2.0 Update global model input shape.
if (RKNN_TENSOR_NHWC == p_input_attrs[0].fmt) {
m_in_height = p_input_attrs[0].dims[1];
m_in_width = p_input_attrs[0].dims[2];
m_in_channel = p_input_attrs[0].dims[3];
RKNN_LOGI("RKNN_TENSOR_NHWC height:%d width:%d channel:%d type:%s size:%d\n",
m_in_height, m_in_width, m_in_channel, get_type_string(p_input_attrs[0].type), p_input_attrs[0].size);
} else if (RKNN_TENSOR_NCHW == p_input_attrs[0].fmt) {
m_in_height = p_input_attrs[0].dims[2];
m_in_width = p_input_attrs[0].dims[3];
m_in_channel = p_input_attrs[0].dims[1];
RKNN_LOGI("RKNN_TENSOR_NCHW height:%d width:%d channel:%d\n", m_in_height, m_in_width, m_in_channel);
} else {
RKNN_LOGE("Unsupported model input layout: %d!\n", p_input_attrs[0].fmt);
return -1;
}
//设置输入参数
if (setInputShapes(p_input_attrs, n_input) != RKNN_SUCC){
return -1;
}
// set scale_w, scale_h for post process
// scale_w = (float)m_in_width / img_width;
// scale_h = (float)m_in_height / img_height;
RKNN_LOGI("ctx:%ld rknn_set_input_shapes: count:%d n:%d w:%d h:%d c:%d\n",ctx,n_input, p_input_attrs[0].dims[0],
p_input_attrs[0].dims[1], p_input_attrs[0].dims[2], p_input_attrs[0].dims[3]);
RKNN_LOGE("test 0000\n");
// 3.3 Query output attributes
memset(p_output_attrs, 0, n_output * sizeof(rknn_tensor_attr));
for (int i = 0; i < n_output; ++i) {
p_output_attrs[i].index = i;
cmd = RKNN_QUERY_OUTPUT_ATTR;
ret = rknn_query(ctx, cmd, &(p_output_attrs[i]), sizeof(rknn_tensor_attr));
if (ret < 0) {
RKNN_LOGE("rknn_query output_attrs[%d] fail!ret=%d\n", i, ret);
return -1;
}
// set out_scales/out_zps for post_process
// out_scales.push_back(p_output_attrs[i].scale);
// out_zps.push_back(p_output_attrs[i].zp);
RKNN_LOGE("out_attr[%d] n:%d c:%d w:%d h:%d n_elems:%d type:%s\n",i,p_output_attrs[i].dims[0], p_output_attrs[i].dims[1], p_output_attrs[i].dims[2],
p_output_attrs[i].dims[3],
p_output_attrs[i].n_elems, get_type_string(p_output_attrs[i].type));
}
RKNN_LOGE("test 1111\n");
if (isZeroCopy){//是否为0拷贝
// 4. Set input/output buffer
// 4.1 Set inputs memory
// 4.1.1 Create input tensor memory, input data type is INT8, yolo has only 1 input.
RKNN_LOGE("test 222\n");
for (int i = 0; i < n_input; i++){
int sizeLen = getTensorTypeSize(p_input_attrs[i].type);
p_input_mems[i] = rknn_create_mem(ctx, p_input_attrs[i].size_with_stride );
RKNN_LOGE("test 222 ... %d sizeLen:%d ->%d \n",i,sizeLen,p_input_attrs[i].size_with_stride );
memset(p_input_mems[i]->virt_addr, 0, p_input_attrs[i].size_with_stride );
RKNN_LOGE("test 222 %d\n",i);
// 4.1.2 Update input attrs
p_input_attrs[i].index = 0;
// p_input_attrs[i].type = RKNN_TENSOR_UINT8;
// p_input_attrs[i].type = in_tensor_type;
RKNN_LOGE("index:%d p_input_attrs[i].size %d size: %d\n",i, p_input_attrs[i].size, m_in_height * m_in_width * m_in_channel * sizeLen);
p_input_attrs[i].size = m_in_height * m_in_width * m_in_channel * sizeLen;
p_input_attrs[i].fmt = RKNN_TENSOR_NCHW;
// TODO -- The efficiency of pass through will be higher, we need adjust the layout of input to
// meet the use condition of pass through.
p_input_attrs[i].pass_through = 0;
// 4.1.3 Set input buffer
RKNN_LOGE("test 222 %dsize: %d,%d\n",i, p_input_attrs[i].size_with_stride , p_input_attrs[i].size);
int ret = rknn_set_io_mem(ctx, p_input_mems[i], &(p_input_attrs[i]));
RKNN_LOGE("rknn_set_io_mem,%d ret=%d\n",i,ret);
// 4.1.4 bind virtual address to rga virtual address
// g_rga_dst = wrapbuffer_virtualaddr((void *)input_mems[0]->virt_addr, m_in_width, m_in_height,
// RK_FORMAT_RGB_888);
}
RKNN_LOGE("test 3333\n");
// 4.2 Set outputs memory
for (int i = 0; i < n_output; ++i) {
int sizeLen = getTensorTypeSize(p_output_attrs[i].type);
// 4.2.1 Create output tensor memory, output data type is int8, post_process need int8 data.
p_output_mems[i] = rknn_create_mem(ctx, p_output_attrs[i].n_elems * sizeLen);
memset(p_output_mems[i]->virt_addr, 0, p_output_attrs[i].n_elems * sizeLen);
// 4.2.2 Update input attrs
// p_output_attrs[i].type = out_tensor_type;
// 4.1.3 Set output buffer
rknn_set_io_mem(ctx, p_output_mems[i], &(p_output_attrs[i]));
}
RKNN_LOGE("test 4444\n");
}else {
// void *in_data = malloc(m_in_width * m_in_height * m_in_channel);
// memset(in_data, 0, m_in_width * m_in_height * m_in_channel);
// g_rga_dst = wrapbuffer_virtualaddr(in_data, m_in_width, m_in_height, RK_FORMAT_RGB_888);
}
created = true;
RKNN_LOGI("rknn_init success!");
return 0;
}
int RknnBase::create(AAssetManager* mgr,int im_height, int im_width, int im_channel, char *model_path,bool isZeroCopy){
AAsset* asset = AAssetManager_open(mgr, model_path, AASSET_MODE_UNKNOWN);
size_t fileLength = AAsset_getLength(asset);
char *dataBuffer2 = (char *) malloc(fileLength);
if (dataBuffer2 == NULL){
RKNN_LOGI("new dataBuffer2 fail!\n");
AAsset_close(asset);
return 101;
}
//read file data
AAsset_read(asset, dataBuffer2, fileLength);
//the data has been copied to dataBuffer2, so , close it
AAsset_close(asset);
// 2. Init RKNN model
int ret = rknn_init(&ctx, dataBuffer2, fileLength, 0, nullptr);
free(dataBuffer2);
if(ret < 0) {
ctx = 0;
RKNN_LOGE("rknn_init fail! ret=%d\n", ret);
return -1;
}
RKNN_LOGI("rknn_init model suc ctx:%ld ret=%d\n",ctx, ret);
return init_deal(im_height,im_width, im_channel, isZeroCopy);
}
int RknnBase::create(int im_height, int im_width, int im_channel, char *model_path,bool isZeroCopy ){
FILE *fp = fopen(model_path, "rb");
if(fp == NULL) {
RKNN_LOGI("fopen %s fail!\n", model_path);
return -1;
}
fseek(fp, 0, SEEK_END);
uint32_t model_len = ftell(fp);
void *model = malloc(model_len);
fseek(fp, 0, SEEK_SET);
if(model_len != fread(model, 1, model_len, fp)) {
RKNN_LOGE("fread %s fail!\n", model_path);
free(model);
fclose(fp);
return -1;
}
fclose(fp);
if (ctx != 0){
rknn_destroy(ctx);
ctx = 0;
}
// 2. Init RKNN model
int ret = rknn_init(&ctx, model, model_len, 0, nullptr);
free(model);
if(ret < 0 || ctx <= 0) {
ctx = 0;
RKNN_LOGE("rknn_init fail! ret=%d\n", ret);
return -1;
}
RKNN_LOGI("rknn_init model suc ret=%d\n", ret);
return init_deal(im_height,im_width, im_channel, isZeroCopy);
}
int RknnBase::detect(rknn_input *inputs, int in_count, rknn_output * outputs, int out_count){
int ret = 0;
if (!created) return -100;
if (NULL == inputs) return 101;
if (NULL == outputs) return 101;
RKNN_LOGI("rknn_inputs_set n_input %d in_count:%d n_output:%d out_count:%d \n",
n_input,in_count, n_output, out_count);
if (n_input != in_count || n_output != out_count) return 101;
#ifdef EVAL_TIME
struct timeval start_time, stop_time;
gettimeofday(&start_time, NULL);
#endif
if (m_isZeroCopy){//零拷贝
RKNN_LOGI("m_isZeroCopy:%d \n",m_isZeroCopy);
for (int i = 0; i < in_count; i++){
memcpy( p_input_mems[i]->virt_addr,inputs[i].buf, inputs[i].size *
getTensorTypeSize(inputs[1].type));
}
}else {
#ifdef EVAL_TIME
gettimeofday(&start_time, NULL);
#endif
RKNN_LOGI("ctx:%ld rknn_inputs_set:%d size:%d\n",ctx, in_count,inputs[0].size);
ret = rknn_inputs_set(ctx, in_count, inputs);
RKNN_LOGI("rknn_inputs_set:%d ret:%d \n",in_count,ret);
#ifdef EVAL_TIME
gettimeofday(&stop_time, NULL);
RKNN_LOGI("rknn_inputs_set use %f ms\n", (__get_us(stop_time) - __get_us(start_time)) / 1000);
#endif
}
#ifdef EVAL_TIME
gettimeofday(&start_time, NULL);
#endif
RKNN_LOGI("rknn_run: start\n");
ret = rknn_run(ctx, nullptr);
RKNN_LOGI("rknn_run: ret :%d \n",ret);
if(ret < 0) {
RKNN_LOGE("rknn_run fail! ret=%d\n", ret);
return 102;
}
#ifdef EVAL_TIME
gettimeofday(&stop_time, NULL);
RKNN_LOGI("inference use %f ms\n", (__get_us(stop_time) - __get_us(start_time)) / 1000);
// outputs format are all NCHW.
gettimeofday(&start_time, NULL);
#endif
if (m_isZeroCopy){
RKNN_LOGI("m_isZeroCopy: out :%d \n",ret);
for (int i = 0; i < out_count; i++){
memcpy(outputs[i].buf, p_output_mems[i]->virt_addr, p_output_attrs[i].n_elems *
getTensorTypeSize(p_output_attrs[i].type));
}
}else {
RKNN_LOGI("rknn_output: out :%d \n",ret);
rknn_output *p_outputs = new rknn_output [out_count];
if (p_outputs == NULL){
RKNN_LOGE("new mem p_outputs fail\n");
return 102;
}
memset(p_outputs, 0, sizeof(rknn_output) * out_count);
for (int i = 0; i < 3; ++i) {
p_outputs[i].want_float = 0;
}
rknn_outputs_get(ctx, out_count, p_outputs, NULL);
for (int i = 0; i < out_count; i++){
RKNN_LOGI("index:%d outname:%s n:%d w:%d h:%d c:%d",i,p_output_attrs[i].name,
p_output_attrs[i].dims[0],p_output_attrs[i].dims[1],p_output_attrs[i].dims[2],
p_output_attrs[i].dims[3]
);
memcpy(outputs[i].buf, p_outputs[i].buf, p_output_attrs[i].n_elems *
getTensorTypeSize(p_output_attrs[i].type));
}
rknn_outputs_release(ctx, out_count, p_outputs);
delete []p_outputs;
p_outputs = NULL;
}
RKNN_LOGI("RknnBase::detect:suc :%d \n",ret);
return 0;
}
RknnTesnsor RknnBase::alloc(bool &isSuc){
isSuc = true;
RknnTesnsor tesnsor;
if (!tesnsor.alloc(this->n_input,this->n_output, this->p_input_attrs, this->p_output_attrs)){
RKNN_LOGE("tesnsor alloc fail\n");
isSuc = false;
}
RKNN_LOGI("tesnsor alloc suc\n");
return tesnsor;
}
RknnTesnsor::RknnTesnsor():
n_input(0),n_output(0),p_input(NULL),p_output(NULL),ref_cnt(NULL),isSuc(false){
ref_cnt = new int;
*ref_cnt = 1;
}
RknnTesnsor::RknnTesnsor(const RknnTesnsor& rhs) // 拷贝构造函数
:n_input(rhs.n_input),n_output(rhs.n_output),p_input(rhs.p_input),
p_output(rhs.p_output),ref_cnt(rhs.ref_cnt),isSuc(rhs.isSuc)
{
++(*ref_cnt);
RKNN_LOGI("RknnTesnsor ref_cnt:%d",*ref_cnt);
}
RknnTesnsor::~RknnTesnsor(){
if (ref_cnt == NULL)return;
(*ref_cnt)--;
RKNN_LOGI("~RknnTesnsor ref_cnt:%d",*ref_cnt);
if (*ref_cnt >= 0) return;
delete ref_cnt;
ref_cnt = NULL;
this->free();
}
void RknnTesnsor::free(){
if (p_input != NULL) {
for (int i = 0;i < n_input; i++){
if (p_input[i].buf != NULL){
delete [] p_input[i].buf;
}
}
delete []p_input;
}
if (p_output != NULL) {
for (int i = 0;i < n_output; i++){
if (p_output[i].buf != NULL){
delete [] p_output[i].buf;
}
}
delete[] p_output;
}
isSuc = false;
}
void RknnTesnsor::init(){
for (int i = 0 ; i < n_input; i++){
if (p_input[i].buf != NULL){
memset(p_input[i].buf, 0, p_input[i].size);
}
}
for (int i = 0 ; i < n_output; i++){
if (p_output[i].buf != NULL){
memset(p_output[i].buf, 0, p_output[i].size);
}
}
}
bool RknnTesnsor::alloc(int in_count, int out_count,rknn_tensor_attr *p_input_attrs,rknn_tensor_attr *p_output_attrs ){
if (p_output != NULL) return false;
if (p_input != NULL) return false;
if (in_count <= 0 || out_count <= 0) return false;
this->n_input = in_count;
this->n_output = out_count;
p_input = new rknn_input[in_count];
if (p_input == NULL){
RKNN_LOGE("RknnTesnsor::alloc new rknn_input error");
return false;
}
memset(p_input, 0 , sizeof(rknn_input) * in_count);
for (int i = 0 ; i < in_count; i++){
p_input[i].index = i;
p_input[i].fmt =p_input_attrs[i].fmt;
p_input[i].type =p_input_attrs[i].type;
p_input[i].size = p_input_attrs[0].size;
p_input[i].pass_through = 0;
p_input[i].buf = new char[p_input[i].size];
RKNN_LOGI("RknnTesnsor::alloc %d type:%d,%s size:%d ",i,p_input[i].type,
get_type_string(p_input[i].type)
,p_input[i].size
);
if (p_input[i].buf == NULL){
RKNN_LOGE("new input buf fail\n");
this->free();
return false;
}
memset(p_input[i].buf,0, p_input[i].size);
}
p_output = new rknn_output[out_count];
if (p_output == NULL){
RKNN_LOGE("RknnTesnsor::alloc new rknn_output error");
this->free();
p_input = NULL;
return false;
}
memset(p_output, 0 , sizeof(rknn_output) * out_count);
for (int i = 0 ; i < out_count; i++){
p_output[i].index = i;
p_output[i].size = p_output_attrs[i].size;
p_output[i].buf = new char[p_output[i].size];
RKNN_LOGI("RknnTesnsor::alloc out %d size:%d ",i,p_output[i].size
);
if (p_output[i].buf == NULL){
RKNN_LOGE("new output buf fail\n");
this->free();
return false;
}
memset(p_output[i].buf,0, p_output[i].size);
}
isSuc = true;
return true;
}
RknnTesnsor& RknnTesnsor::operator= (const RknnTesnsor& other){
if (this == &other) {
RKNN_LOGI("RknnTesnsor::operator= same");
return *this;
}
RKNN_LOGI("RknnTesnsor::operator= ref_cnt:%d ,other:%d",*ref_cnt, *(other.ref_cnt));
if (ref_cnt != NULL){
delete ref_cnt;
ref_cnt = NULL;
}
ref_cnt = other.ref_cnt;
(*ref_cnt)++;
n_input = other.n_input;
n_output = other.n_output;
p_input = other.p_input;
p_output = other.p_output;
return *this;
}
bool RknnTesnsor::isOk(){
return isSuc;
}
rknn_input* RknnTesnsor::getInput(){
return this->p_input;
}
rknn_output* RknnTesnsor::getOutput(){
return this->p_output;
}
int RknnTesnsor::getInputCnt(){
return this->n_input;
}
int RknnTesnsor::getOutputCnt(){
return this->n_output;
}上述封装了一个类,可以执行加载模型和执行模型,具体的,默认如果是FP16的格式,需要进行格式转换,不然数据会出错,如果是uint8 那么还好。
下面是根据网上搜索到的一个FP16和float进行转换的工具,没去研究怎么转了,直接使用了。
MathUtil.h//
// Created by Administrator on 2024/6/24.
//
#ifndef NCNNFACE_MATHUTIL_H
#define NCNNFACE_MATHUTIL_H
typedef unsigned short FP16;
typedef float FP32;
class MathUtil {
public:
//float转fp16数组
static void Fp32ArryToFp16(FP32 * fp32, void *fp16, int num);
//Fp16 转float 数组
static void Fp16ArryToFp32(void * fp16, FP32 *fp32, int num);
};
#endif //NCNNFACE_MATHUTIL_HMathUtil.cpp
//
#include "../include/MathUtil.h"
#include <math.h>
/***
*float16 float32 double 在内存的排列顺序 符号位S(1byte) + 指数位E + 有效数M
* 类型 位数 符号位(S) 指数(E) 尾数(M)
* half 16 1位(bit15) 5位(bit10~bit14) 10位(bit0-bit9)
* float 32 1位(bit31) 8位(bit23~bit30) 23位(bit0~bit22)
* double 64 1位(bit63) 11位(bit52-bit62) 52位(bit0-bit51)
*
*/
typedef unsigned int uint32_t;
typedef int int32_t;
#define TOINT(ch)((unsigned int)ch)
#define INFINITY 0
#define FP32_TO_FP16_S(ch) ((TOINT(ch) & 0x80000000) >> 16) //获取符合位置 并且 从32位移到16位
#define FP32_TO_FP16_W(ch) ((TOINT(ch) & 0x007FFFFF) >> 13) //取出尾部23位数字,然后左移13位得到最高的10位位数作为有效数字
#define FP32_TO_FP16_E(ch) ((TOINIT(ch)& 0x7F800000) >> 16) //中间8位取出来
void MathUtil::Fp32ArryToFp16(FP32* f32, void* f16, int num)
{
float* src = (float *)f32;
FP16* dst = (FP16 *)f16;
int i = 0;
for (; i < num; i++) {
float in = *src;
uint32_t fp32 = *((uint32_t *) &in);
uint32_t t1 = (fp32 & 0x80000000u) >> 16; /* sign bit. */
uint32_t t2 = (fp32 & 0x7F800000u) >> 13; /* Exponent bits */
uint32_t t3 = (fp32 & 0x007FE000u) >> 13; /* Mantissa bits, no rounding */
uint32_t fp16 = 0u;
if( t2 >= 0x023c00u )
{
fp16 = t1 | 0x7BFF; /* Don't round to infinity. */
}
else if( t2 <= 0x01c000u )
{
fp16 = t1;
}
else
{
t2 -= 0x01c000u;
fp16 = t1 | t2 | t3;
}
*dst = (FP16) fp16;
src ++;
dst ++;
}
}
void MathUtil::Fp16ArryToFp32(void * fp16, FP32 *fp32, int num)
{
FP16* src = (FP16 *)fp16;
float* dst = (float *)fp32;
int i = 0;
for (; i < num; i++) {
FP16 in = *src;
int32_t t1;
int32_t t2;
int32_t t3;
float out;
t1 = in & 0x7fff; // Non-sign bits
t2 = in & 0x8000; // Sign bit
t3 = in & 0x7c00; // Exponent
t1 <<= 13; // Align mantissa on MSB
t2 <<= 16; // Shift sign bit into position
t1 += 0x38000000; // Adjust bias
t1 = (t3 == 0 ? 0 : t1); // Denormals-as-zero
t1 |= t2; // Re-insert sign bit
*((uint32_t*)&out) = t1;
*dst = out;
src ++;
dst ++;
}
}3、使用方式
具体的使用方式
1、先通过 RknnBase 进行模型加载,加载成功后会返回0
//如果使用assert路径
int create(AAssetManager* mgr,int im_height, int im_width, int im_channel, char *model_path,
bool isZeroCopy = false);2、创建输入输出空间【选配】
方便管理,也可以自己管理,在使用的时候用局部变量或者全局变量,不需要分配。
//根据模型构建输入输出空间 根据isSuc是否返回
RknnTesnsor alloc(bool &isSuc);、3、动态输入【选配】
如果模型是输入是动态参数,那么必须使用此函数进行设置
输入的参数和参数的个数
//动态输入的时候设置输入 参数
int setInputShapes(rknn_tensor_attr *p_input_attrs, int input_count);3、模型执行
输入的参数放入到input里面,返回0 那么可以从output里面获取出模型的输出值
//模型执行解析
int detect(rknn_input *input, int in_count, rknn_output * output, int out_count);经过使用,使用了NPU,使用如下命令查询
cat /sys/kernel/debug/rknpu/load
但是算力只有1TOPS ,整体算下来比RK3399 速度快那么几十ms,也算是增速了。
具体demo和代码,可以参考yolov的版本android,不过例子不是动态输入,而且入参也是uint8,不是float的参数,可以通过工程移植到自己的项目里面。
如下源码:(此代码也在rknn例子里面)