nanochat 技术深度解析:低成本全栈 LLM 实现的架构与工程实践
1. 整体介绍
1.1 项目概览与现状
项目地址 :github.com/karpathy/na... (截至分析时,项目处于活跃开发初期,社区关注度正在增长,其前身 nanoGPT 已有超 40k stars,预示着该项目的潜在影响力)。
项目定位:一个单一、简洁、最小化、可高度定制且依赖极少的代码库,旨在完整实现类似 ChatGPT 的大型语言模型 (LLM),覆盖从数据准备、训练、评估到部署服务的全流程。
核心宣言:"100 美元能买到的最好的 ChatGPT"。这直观地概括了其设计哲学:在严格受限的计算预算下,提供一个可运行、可理解、可修改的 LLM 全栈基线。
1.2 核心功能与操作
项目通过一个名为 speedrun.sh 的主脚本串联所有流程。用户在一个配备 8 张 H100 GPU 的节点上(市场价约 24 美元/小时),执行该脚本约 4 小时后,即可获得一个约 5.61 亿参数(d20 配置)的对话模型,并可通过内置的 Web UI 进行交互。
项目截图示意:
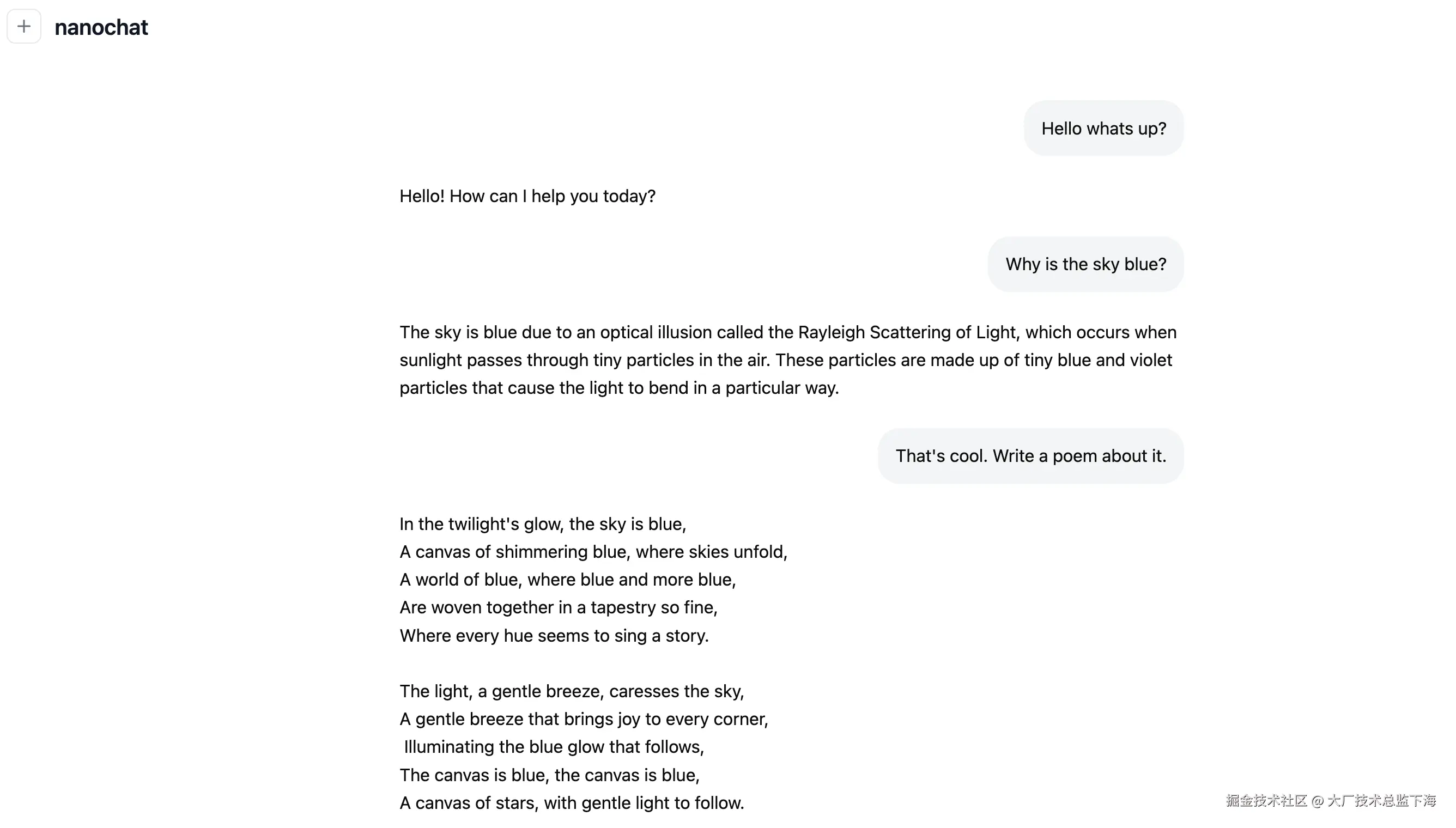 用户可通过类似 ChatGPT 的界面与自行训练的模型对话。
用户可通过类似 ChatGPT 的界面与自行训练的模型对话。
1.3 面临问题与目标人群
解决的问题要素:
- 认知与工程复杂性 :现代主流 LLM 框架(如 Hugging Face Transformers)为了通用性,引入了庞大的配置系统和抽象层,对于希望从头理解并掌控全流程的学习者、研究者或小型团队而言,构成了较高的入门门槛。
- 经济成本门槛:训练一个性能尚可的 LLM 通常需要数万至数百万美元的计算资源,将绝大多数个人和中小型团队拒之门外。
- "黑箱"与定制化困难:使用预训练 API 或微调大型模型,用户难以深入模型内部,注入特定知识、风格或能力的过程复杂且不透明。
目标场景与人群:
- 教育与研究:作为教学工具(如配套课程 LLM101n),帮助学生直观理解 LLM 训练的每个环节。
- 快速原型与实验:研究者需要在有限预算下验证新的训练算法、架构修改或数据策略。
- 个性化模型定制:开发者希望完全拥有并控制一个具备特定身份、语调或专业领域知识的轻量级对话代理。
1.4 解决方案与优势对比
传统/现有方案:
- 使用大型框架:功能全面但代码库庞大,依赖复杂,核心训练循环被多层封装。
- 依赖云 API:成本不可控,无法定制内部机制,存在数据隐私和供应商锁定风险。
- 微调超大基座模型:即使使用 LoRA 等技术,仍需支付高额的基座模型推理和微调成本,且无法修改模型架构。
nanochat 的新方式:
- 一体化端到端:从原始文本数据到可交互的 Web 服务,所有代码均在一个约 330KB 的代码库中,逻辑线性,易于跟踪。
- 成本精确透明:脚本直接关联云计算实例价格,训练时长、FLOPs、参数量与最终成本的关系清晰可计算。
- 最大化可读性与可黑客性 :代码风格极简,避免不必要的抽象,鼓励用户直接修改任何部分。例如,调整模型深度仅需修改
--depth参数。
核心优势 :在牺牲了前沿模型规模与性能上限的前提下,换来了前所未有的透明度、可控性和学习友好性。
1.5 商业价值预估
价值估算可从 "替代成本" 和 "教育/实验效率提升" 两个维度分析:
-
代码与工程成本替代:构建一个同等完整度(含分词器训练、多阶段训练、评估基准、Web服务)的 LLM 训练管线,需要一个高级工程师团队数月的开发时间。nanochat 提供了经过验证的、可直接部署的替代品。按人均成本估算,此项可替代数十万人民币的研发投入。
-
计算成本与问题空间覆盖:
- 基线 :100 美元方案(d20,~560M 参数,4小时)在 GSM8K 数学基准上得分约 2.5%,性能相当于一个"幼稚的儿童",但已能完成简单的对话和文本生成。其价值在于快速验证流程的可行性。
- 进阶:1000 美元方案(预估,~41.6小时)目标性能接近或超越 GPT-2 (2019)。对于一个希望拥有私有化、可完全定制化对话模型的小型企业或垂直应用,这提供了一个明确的性能与成本基准。相比于持续支付 API 调用费用或租赁大型模型,一次性的千美元级投入在长期可能更具经济性。
- 覆盖问题空间 :项目通过
tasks/目录下的多个评估任务(ARC, MMLU, GSM8K, HumanEval 等)定义了其优化的"问题空间"------即通用语言理解、推理和基础代码能力。它证明了在此问题空间内,千美元量级投入可获得具有基础实用性的模型。
生成逻辑 :价值并非源于其模型的绝对性能(目前远不及 GPT-4/Claude 等),而是源于它显著降低了进入"全栈 LLM 研发"领域的综合门槛(金钱、时间、认知)。它为原型验证、教育、特定轻量级应用提供了一个经济、高效的新起点。
2. 详细功能拆解(产品+技术视角)
| 功能模块 | 产品视角(用户价值) | 技术视角(核心设计) |
|---|---|---|
"一键式"训练管线 (speedrun.sh) |
屏蔽分布式训练、数据下载、阶段衔接的复杂性,提供开箱即用的体验。 | 使用 Bash 脚本编排 Python 训练脚本,管理后台进程,传递环境变量。关键环节:数据并行(torchrun)、梯度累积、检查点管理。 |
| 多阶段训练流程 | 模拟工业化 LLM 训练流程(预训练 -> 中间训练 -> 有监督微调 -> 强化学习),让用户理解各阶段作用。 | 1. Base Train :在大量无标签文本上进行自回归预训练。 2. Mid Train :注入对话格式、工具调用等特殊令牌,进行多任务学习。 3. SFT :在高质量对话数据上进行序列级指令微调。 4. RL(可选):在 GSM8K 任务上进行拒绝采样与强化学习优化。 |
| 可定制身份/能力 | 允许用户通过数据"塑造"模型的性格或为其添加新技能(如计算字母'r'的数量)。 | 提供 dev/gen_synthetic_data.py 等模板,指导用户生成特定格式的合成数据(JSONL),并将其混入 Mid-training 或 SFT 的数据集中。技术核心在于数据混合策略。 |
| 内置评估与报告 | 训练结束后自动生成"成绩单",让用户对模型能力有量化、多角度的认识。 | 在 tasks/ 下实现多个标准评测集的数据加载和指标计算。report.py 模块自动收集各阶段日志,合成最终的 report.md。 |
高效推理引擎 (engine.py) |
提供流畅的对话体验,并支持模型调用"计算器"工具。 | 实现 KV 缓存 (KVCache) 管理,支持流式生成和批量生成。集成简单的 Python 表达式安全评估器,实现工具调用逻辑。 |
| 最小化依赖与部署 | 简化环境配置,支持从多 GPU 服务器到 Mac MPS/CPU 的多种运行环境。 | 使用 uv 管理 Python 依赖和虚拟环境。pyproject.toml 中配置了 CPU/GPU 版本的 Torch 索引。模型代码自动检测设备类型。 |
3. 技术难点与核心创新因子
- 在极小内存预算下的模型配置 :如何在 8xH100(每卡 80GB)上高效训练 5.6 亿参数模型?解决方案包括:使用混合优化器 (对嵌入层和输出层使用 AdamW,对 Transformer 矩阵使用 Muon)、激活 checkpointing 、梯度累积 ,以及将词表大小填充至 64 的倍数以优化分布式矩阵计算效率。
- 端到端管线的健壮性与自动化:如何确保数小时的无监督脚本运行不因网络、数据或硬件问题中断?通过详尽的错误检查、数据下载重试机制、检查点保存与恢复,以及将中间状态记录到结构化报告中来应对。
- 低成本下的模型质量 :如何在有限数据和计算下获得尽可能好的性能?采用经过简化和调优的 Transformer 架构 (如 RoPE, QK Norm, ReLU² 激活),并遵循 Chinchilla 缩放法则(约 20 倍参数数的训练令牌数)来分配计算预算。
- 推理效率与工具使用的集成 :如何在资源有限的环境下实现快速响应和工具调用?自研轻量级
Engine类,管理 KV 缓存的动态增长,并将工具调用(如计算器)作为一个由特殊令牌触发的确定性子流程来执行,而非依赖模型生成函数调用字符串。
4. 详细设计图
4.1 核心架构图

4.2 核心训练链路序列图
4.3 核心类图 (GPT 模型)
4.4 核心函数(Engine.generate)拆解流程图
5. 核心函数与代码解析
5.1 GPT 模型的前向传播 (gpt.py)
这是模型计算的核心,集成了训练和推理两种模式。
python
def forward(self, idx, targets=None, kv_cache=None, loss_reduction='mean'):
B, T = idx.size()
# 1. 处理 Rotary 位置编码
T0 = 0 if kv_cache is None else kv_cache.get_pos() # KV缓存偏移量
cos_sin = self.cos[:, T0:T0+T], self.sin[:, T0:T0+T]
# 2. 通过嵌入层和层归一化
x = self.transformer.wte(idx)
x = norm(x) # RMSNorm
# 3. 逐层通过 Transformer Block
for block in self.transformer.h:
x = block(x, cos_sin, kv_cache) # 传入kv_cache用于推理时缓存
# 4. 最终层归一化
x = norm(x)
# 5. 计算 logits (词汇表概率分布)
logits = self.lm_head(x)
logits = logits[..., :self.config.vocab_size] # 移除填充部分
logits = logits.float() # 转为fp32以稳定计算
logits = softcap * torch.tanh(logits / softcap) # 平滑限制logits值域
# 6. 根据模式返回损失或logits
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)),
targets.view(-1),
ignore_index=-1,
reduction=loss_reduction)
return loss
else:
return logits技术要点:
- RoPE 动态应用 :根据当前序列位置
T0切片预计算的旋转矩阵,支持长文本生成。 - KV 缓存集成 :
kv_cache参数在推理时非空,block内部会调用kv_cache.insert_kv()来存储并复用已计算的 K, V 矩阵。 - Logits 平滑限制 :使用双曲正切函数将 logits 限制在
[-softcap, softcap]之间,防止训练不稳定。
5.2 KV 缓存管理 (engine.py)
这是实现高效自回归推理的关键。
python
class KVCache:
def insert_kv(self, layer_idx, k, v):
if self.kv_cache is None:
# 延迟初始化:根据第一次传入的k,v确定dtype/device
self.kv_cache = torch.empty(self.kv_shape, dtype=k.dtype, device=k.device)
t0, t1 = self.pos, self.pos + k.size(2) # 新KV的起止位置
# 动态扩展缓存空间(如果不够)
if t1 > self.kv_cache.size(4):
t_needed = t1 + 1024
t_needed = (t_needed + 1023) & ~1023 # 向上对齐到1024的倍数
# ... 分配新内存并拼接
# 将新的k, v存入缓存
self.kv_cache[layer_idx, 0, :, :, t0:t1, :] = k
self.kv_cache[layer_idx, 1, :, :, t0:t1, :] = v
# 返回截至当前时刻的完整K,V视图
key_view = self.kv_cache[layer_idx, 0, :, :, :t1, :]
value_view = self.kv_cache[layer_idx, 1, :, :, :t1, :]
# 如果是最后一层,更新缓存位置指针
if layer_idx == self.kv_cache.size(0) - 1:
self.pos = t1
return key_view, value_view设计精妙之处:
- 延迟初始化:避免在未进行推理前分配大量 GPU 内存。
- 动态增长:缓存长度按需扩展,每次增加约 1024 个令牌的容量,并以 1024 为边界对齐,可能有利于内存访问效率。
- 返回视图:返回的是缓存张量的一个切片视图,而非拷贝,节省内存和计算。
5.3 混合优化器设置 (gpt.py)
针对模型不同部分使用不同的优化策略,以在有限内存下取得更好效果。
python
def setup_optimizers(self, unembedding_lr=0.004, embedding_lr=0.2, matrix_lr=0.02):
# 1. 参数分组
matrix_params = list(self.transformer.h.parameters()) # 所有Transformer层的线性权重
embedding_params = list(self.transformer.wte.parameters()) # 词嵌入矩阵
lm_head_params = list(self.lm_head.parameters()) # 输出层权重
# 2. 为AdamW参数组(嵌入和输出层)计算学习率缩放因子
dmodel_lr_scale = (self.config.n_embd / 768) ** -0.5 # 与模型维度平方根成反比
# 3. 创建 AdamW 优化器(用于嵌入和输出层)
adam_groups = [
dict(params=lm_head_params, lr=unembedding_lr * dmodel_lr_scale),
dict(params=embedding_params, lr=embedding_lr * dmodel_lr_scale),
]
adamw_optimizer = DistAdamW(adam_groups, betas=(0.8, 0.95), eps=1e-10)
# 4. 创建 Muon 优化器(用于主要的 Transformer 矩阵)
muon_optimizer = DistMuon(matrix_params, lr=matrix_lr, momentum=0.95)
# 5. 返回优化器列表,训练循环将依次更新
return [adamw_optimizer, muon_optimizer]策略解读:
- 分离优化器 :
Muon是一种类似 SGD 的轻量级优化器,可能比 AdamW 占用更少的显存(不存储动量和方差),适用于参数最多的矩阵部分。 - 差异化的学习率 :词嵌入和输出层通常需要更大的学习率。此处的缩放因子
(d_model/768)**-0.5是一种经验性调整,旨在使学习率适应不同的模型宽度。
总结
nanochat 是一个极具特色的工程项目,其技术价值不在于追求最先进的性能,而在于精心设计和实现了一条从零到对话的、低成本的、透明的 LLM 生产路径。通过对计算资源的极致规划、对代码复杂度的严格控制以及对教育目标的坚定聚焦,它为想要深入理解 LLM 内部机制的研究者和开发者提供了一个近乎理想的"沙盒"。
从架构上看,其一体化脚本、模块化训练阶段、自包含评估系统以及高效推理引擎,共同构成了一套闭环。从代码实现上,它对 RoPE、GQA、KV Cache、混合优化等现代技巧的应用,既保证了基线模型的竞争力,又保持了代码的整洁性。
当然,它目前适用于实验、教育和特定轻量级应用场景,而非替代大规模生产模型。但其体现的"在约束下创新"的工程思想,以及对 LLM 技术民主化的推动,值得所有对 AI 系统构建感兴趣的技术人员深入研究和借鉴。随着项目的持续演进,它有望成为开源 LLM 全栈开发中的一个重要参考基准。