目录
三:用getpid(),getppid()获取该进程的PID,PPID

接下来的日子会顺顺利利,万事胜意,生活明朗-----------林辞忧
一:进程概念
1.操作系统学科层面的概念
一个加载到内存中的程序,叫做进程; 正在运行的程序叫做进程
2.深层次的进程概念
对于一个操作系统不仅仅只能运行一个进程,而是可以运行很多个进程,为了更好的管理这些进程,就需要用先描述再组织的思想
因此对于任何一个进程在加载到内存当中的时候,形成真正的进程时,操作系统要先创建描述该进程(属性)的struct结构体对象,即PCB(进程属性的集合)----进程控制块
PCB是在操作系统中定义的struct结构体类型。当加载进程的时候,本质上不仅仅是把对应的数据和代码加载到内存,而且操作系统会根据描述该进程的PCB类型为当前进程创建对应的PCB对象,把该进程的相关属性值填充完成初始化。这个PCB结构体变量是由操作系统自己形成的。
进程=内核PCB数据结构对象(描述该进程所有的属性值)+对应的代码和数据
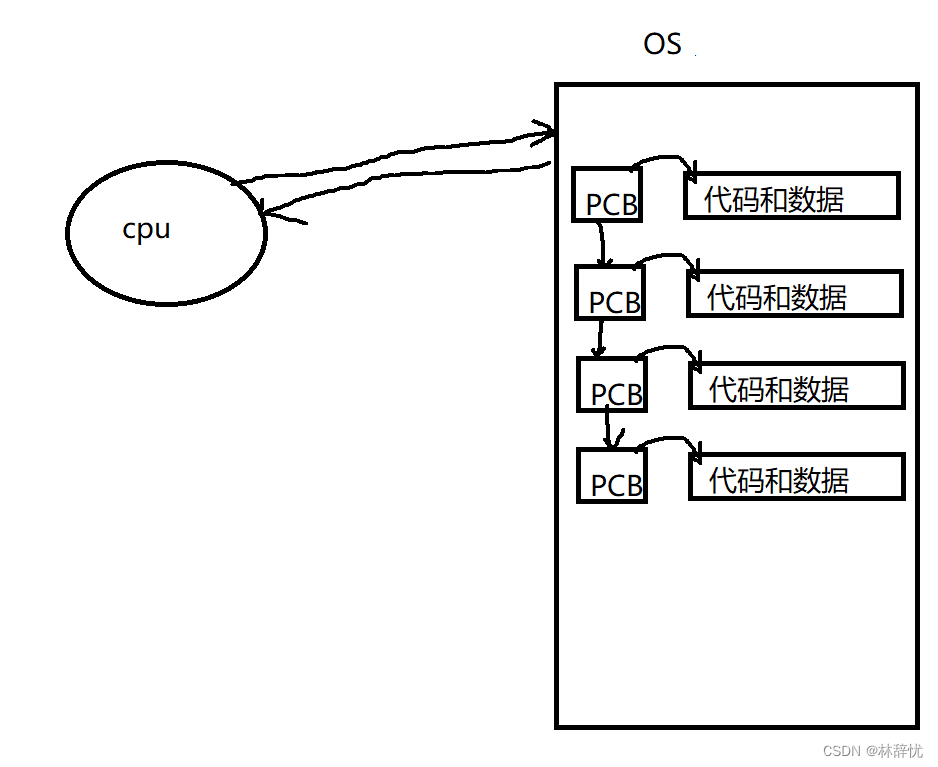
在操作系统中,对于所有进程的PCB结构体对象使用双向链表的方式 进行连接,在每个PCB结构体对象中包含相应的指针字段指向该进程对应的代码和数据,此后操作系统只需对PCB对象进行管理,便可以达到管理进程的目的,这样对于进程的管理就转化为对这个链表的增删查改
二:Linux中的进程概念
1.在Linux中描述进程的结构体叫做task_struct(Linux系统中的PCB)。
2.task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息
3.根据task_struct实例化进程对象,创建一个具体的PCB对象,再把所有对象的PCB组织起来
4.task_struct中包含的进程属性
标示符: 描述本进程的唯一标示符,用来区别其他进程(PID)
状态: 任务状态,退出代码,退出信号等
优先级: 相对于其他进程的优先级
程序计数器: 程序中即将被执行的下一条指令的地址
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据休学例子,要加图CPU,寄存器
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表
其他信息
6.查询进程信息相关指令
ps axj 查看进程信息
top 查看正在运行的进程信息
ls /proc -l :在系统当中启动的所有进程默认在/proc目录里,就会给相应进程在/proc目录里创建以该进程PID命名的文件夹/目录,在该目录里保存了进程的大多属性;在关机后,/proc目录下的所有数据就都没有了,在开机时,操作系统会自动创建这些目录/文件,这上面显示的所有信息是Linux操作系统用文件系统的方式把内存当中的文件/进程信息可视化出来,而且这些信息都是内存级别的
ls /proc/进程PID -l 显示系统当中具体动态运行的进程的相关信息
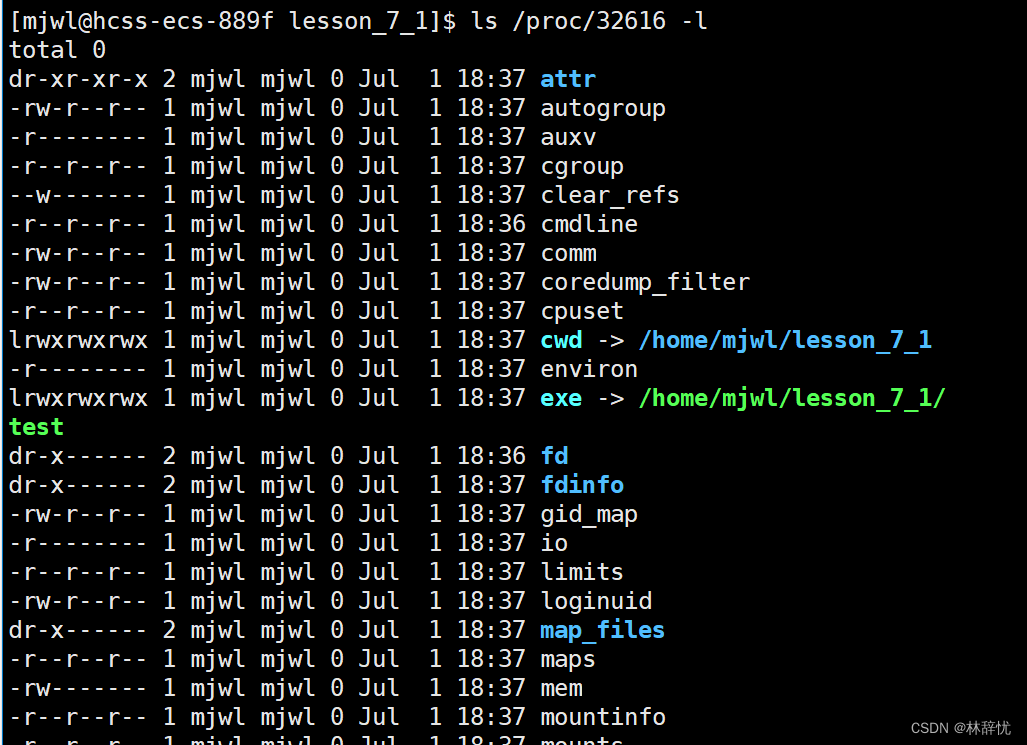
注:1.进程所对应的可执行程序是在磁盘exe目录下的这个文件当中,所以PID对应的进程的可执行程序是可以被找到的
2.cwd:当进程在启动时,该进程的PCB属性里就记录了当前Linux所在的绝对路径,也就是当前进程的工作目录;在当前特定目录下工作的一个进程,默认自己的进程在哪个目录下,这个目录就是这个进程的当前目录,创建文件/搜索文件都是在这个当前目录下完成的
三:用getpid(),getppid()获取该进程的PID,PPID
1.创建一个进程,就要操作系统创建对应的PCB,在Linux中称为task_struct结构体对象,当存在多个时,就要用双向链表方式进行连接管理,通过找到头结点来访问各个进程,为了区分这些进程,操作系统就分配了对应的PID,对应的PID是存在于task_struct结构体当中
2.进程在运行时,都会有独属于自己的PID,对于PID当每个进程在系统运行期间终止了后再启动,操作系统分配的PID标识符多数情况下是会改变的
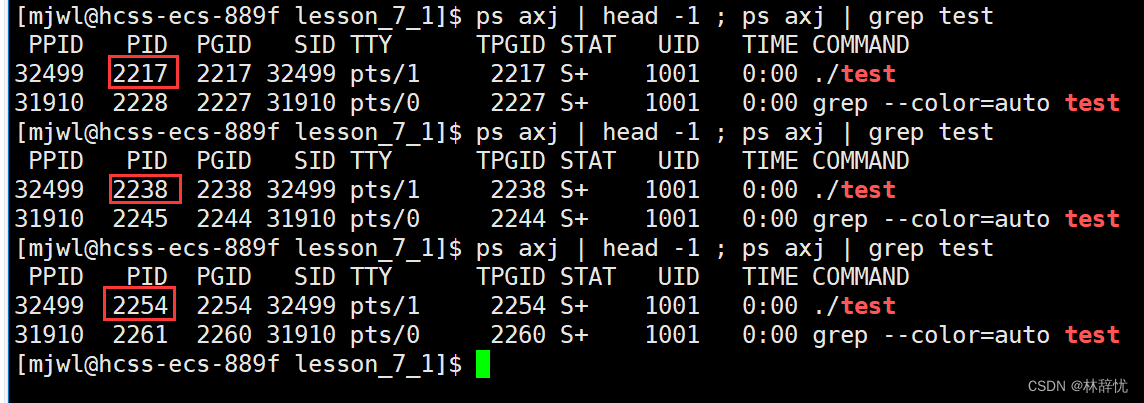
注:这里检索指令也可以写为 ps axj | head -1 && ps axj | grep test
当grep自己过滤时,也要变为一个进程,而grep命名的进程中也含有关键字test,所以当它在执行过滤系统当中的进程时,首先得把grep变为一个进程,然后被cpu调度执行过滤代码,在过滤时也就会把自己带上,所以所有指令运行时都是进程
ps axj | head -1 ; ps ajx | grep test | grep -v grep 这样的话就不会带自己了
3.ps指令的本质:遍历链表,在task_struct中将对应属性格式化打印出来
4.kill -9 进程PID 杀掉进程
5.PID存在于task_struct结构体当中,这个结构体是属于操作系统所维护的,是系统内的数据,所以用户不能直接通过task_struct结构体对象以.的方式访问PID,而是要通过对应的系统调用接口来获取进程的PID,对于PPID也是如此


6.当每次重新登录时,系统会为我们单独创建一个bash进程,即创建一个命令行解释的进程,在显示器中打印出对应的对话框终端
7.当运行一个进程时,命令行解释器会将后面的指令变为bash的子进程,由子进程执行对应的命令,当子进程出现问题时,不影响bash进程,即在命令行中输入的所有指令都是bash进程的子进程,bash进程只负责命令行解释
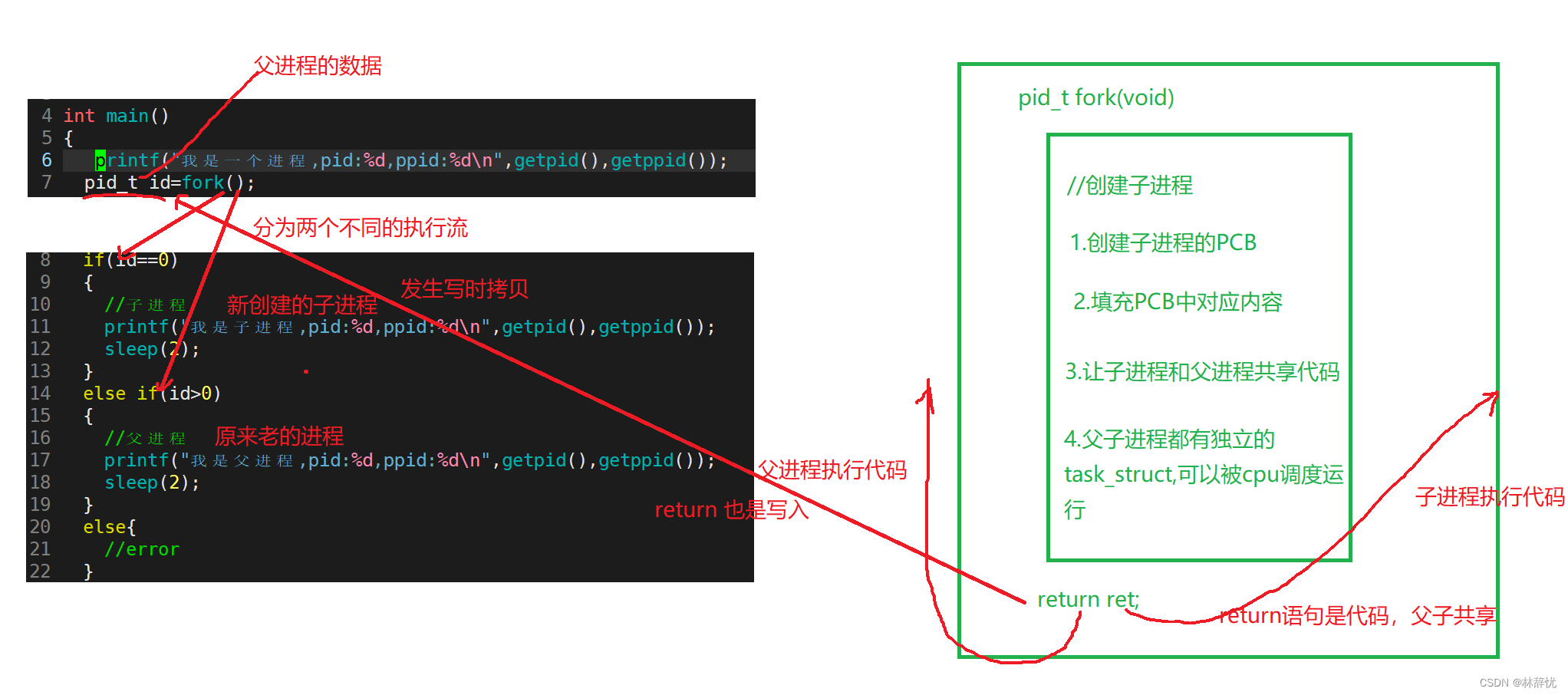
四:用fork()来创建子进程
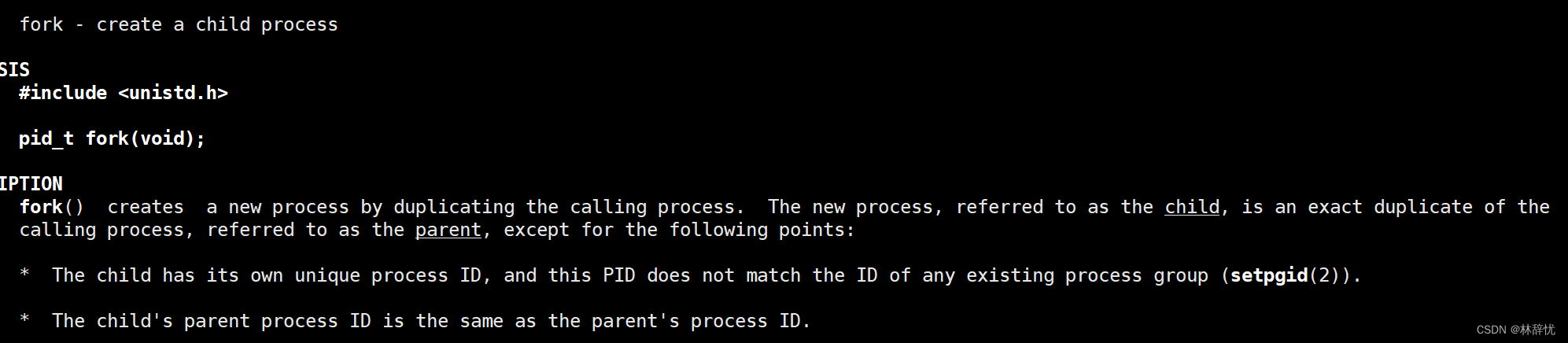
fork()是用来创建一个子进程,创建成功的话,给父进程返回子进程的PID,给自己返回0;失败的话,给自己返回-1
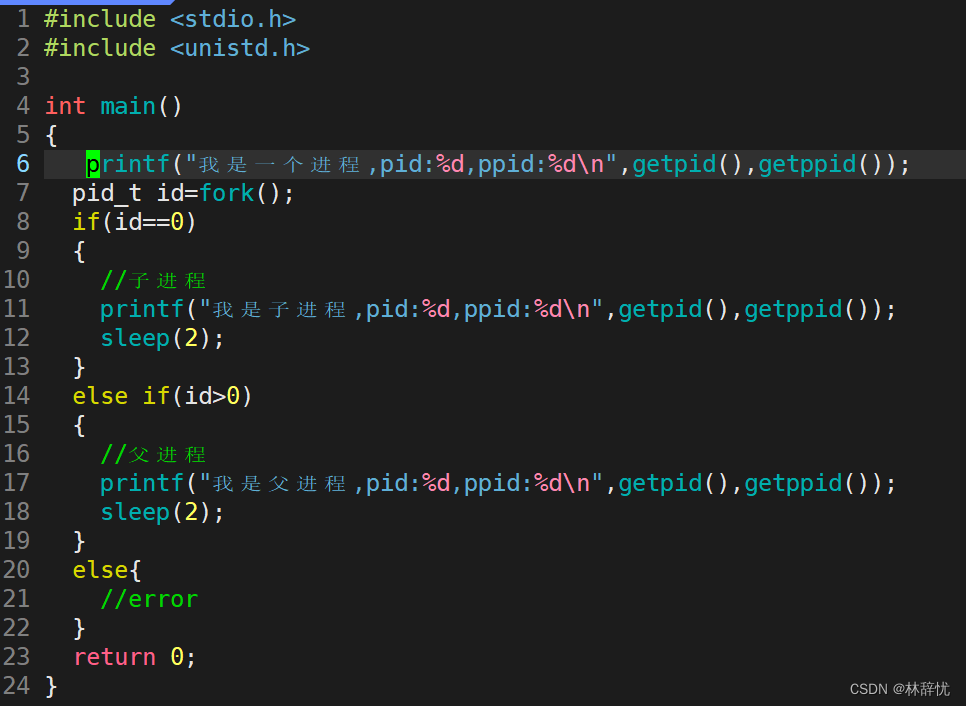

这里我们会发现fork()之后的代码执行了两次,即fork()之后会变成两个进程,执行不同的代码块
1.为什么fork要给子进程返回0,给父进程返回子进程的PID?
返回不同的返回值,是为了区分不同的执行流,执行不同的代码块
给父进程返回子进程的PID,是为了通过父进程的PID去明确控制访问的是哪个子进程(控制并区分子进程),PID也是用来标定子进程的唯一性的
而子进程只需要调用getpid()就能获取进程的PID/PPID,所以找到父进程很容易,只需要返回0来标识成功即可
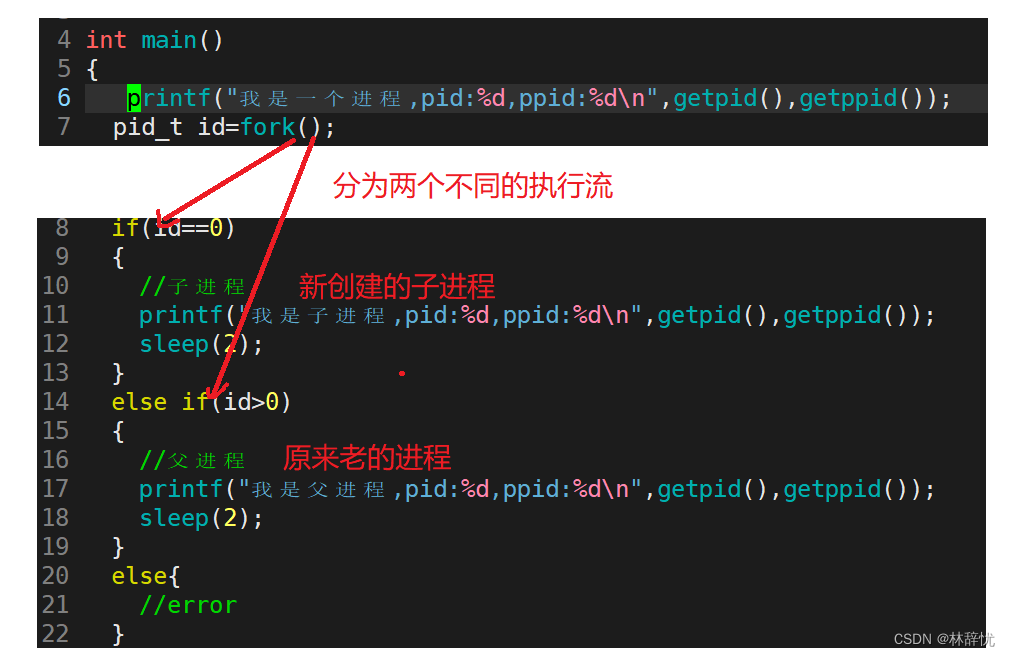
2.fork()函数究竟干了什么?
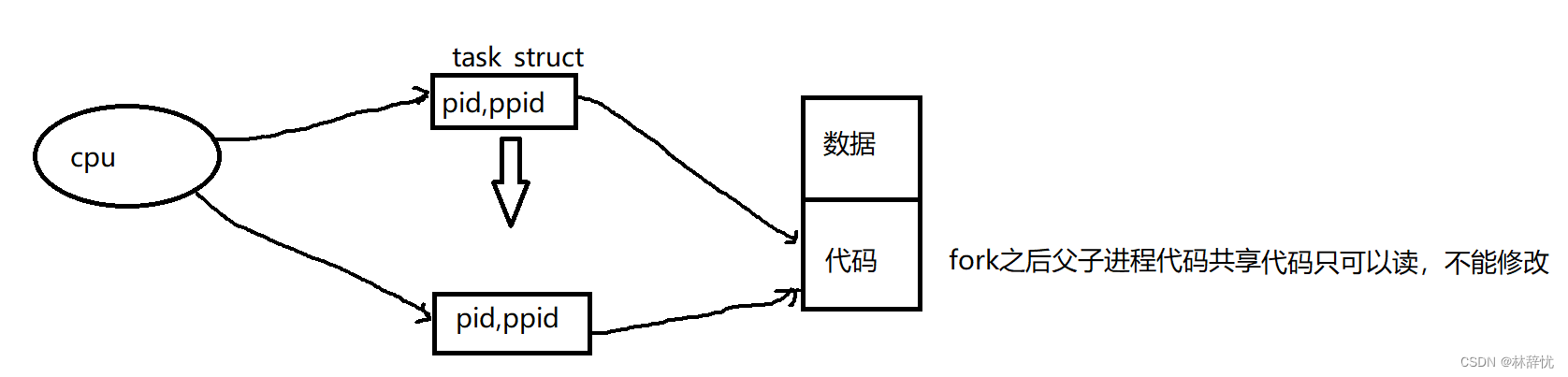
当执行到fork()时,就要创建对应的子进程,而进程=内核task_struct数据结构对象+对应的代码和数据,而创建对应的task_struct结构体对象是以原先老进程的task_struct为模板拷贝一份并用父进程的相应字段来初始化子进程,做相应修改,但对于代码是没有的,所以只能共享父进程的代码;而对于数据,如果子进程也把对应的和父进程共享的数据拷贝一份的话,由操作系统自动完成,但这样必然会造成子进程对这部分数据只修改一部分或者不修改,造成有两份相同的数据形成冗余,占有资源,因此当子进程要访问父进程的某一部分数据,并且操作系统识别到要对父进程的这部分数据做修改时,这时就在系统的内存位置重新开辟一块空间将数据拷贝过去,写入。这样对于子进程想对父进程修改的数据,就再开辟空间,在新空间写入==>父子进程间数据层面的写时拷贝
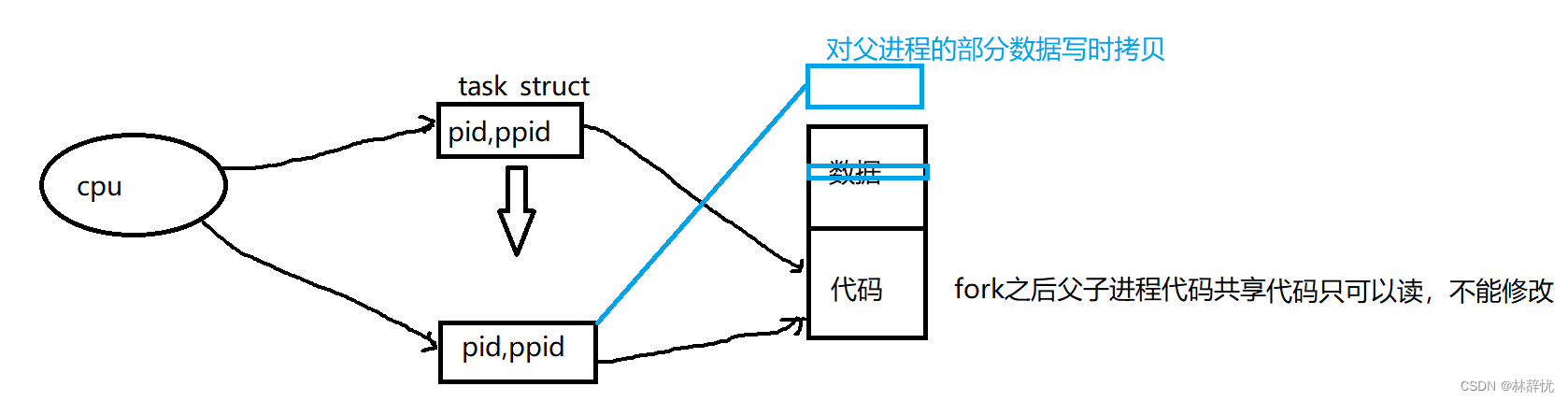
对于fork本质上是一个函数,也是一个系统调用,在操作系统当中是有实现的

所以这样同一个函数就返回了两次
3.一个变量是怎么会有不同的内容的?
五:操作系统学科的进程状态
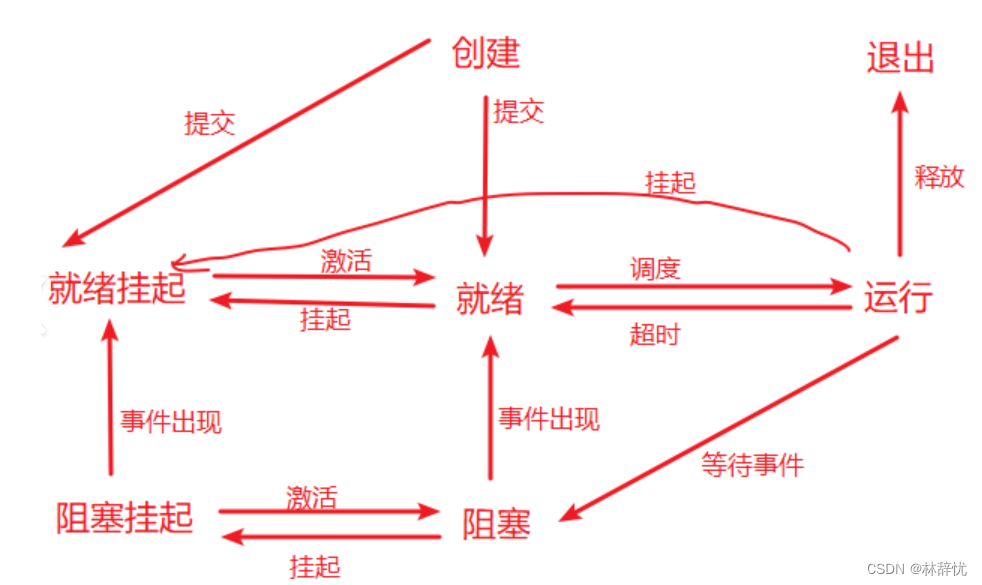
1.cpu负责把一个进程放到cpu中去执行,由调度器决定被调度的具体进程,所有进程参与到操作系统的调度过程,所有的进程之间对于cpu资源本质是一种竞争关系,所以存在调度器是为了保证进程间的公平调度
2.为合理调度,每个cpu都要维护一个runqueue的结构体,cpu以运行队列的形式对进程进行调度

3.对于每个进程都有时间片的概念,在时间片的时间中被cpu调度执行,时间结束,自动切换到下一个进程,如果这个进程还需要被调度执行的话,就会被链接到队列最后面排队等待调度执行
4.在一个时间段内,所有进程的代码都会被调度执行------->并发执行
把进程放到cpu上去执行,再拿下来--------->进程切换
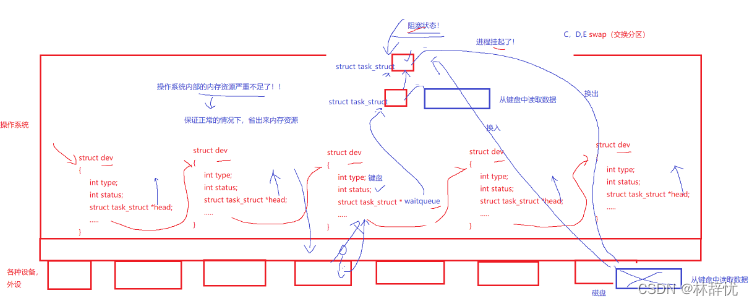
5.对于底层的硬件设备也可以采用先组织,再描述的方式进行管理,即每个外设都维护一个对应的结构体对象。这样操作系统对于底层设备的管理也就转换为在系统当中对某种设备结构体的管理,如果当前要访问的资源不存在/未准备好,此时进程卡住了,这就是阻塞状态
此时该进程 就在对应外设的等待队列中排队等待资源就绪,一旦资源就绪就可以链接到运行队列中等待被cpu调度执行
6.当进程资源不足时,操作系统会将进程的代码和数据置换到外设当中,这样数据和代码并未在内存当中,这时所处的状态就是挂起状态
六:Linux中的进程状态
1.Linux内核中的定义
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};- R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里
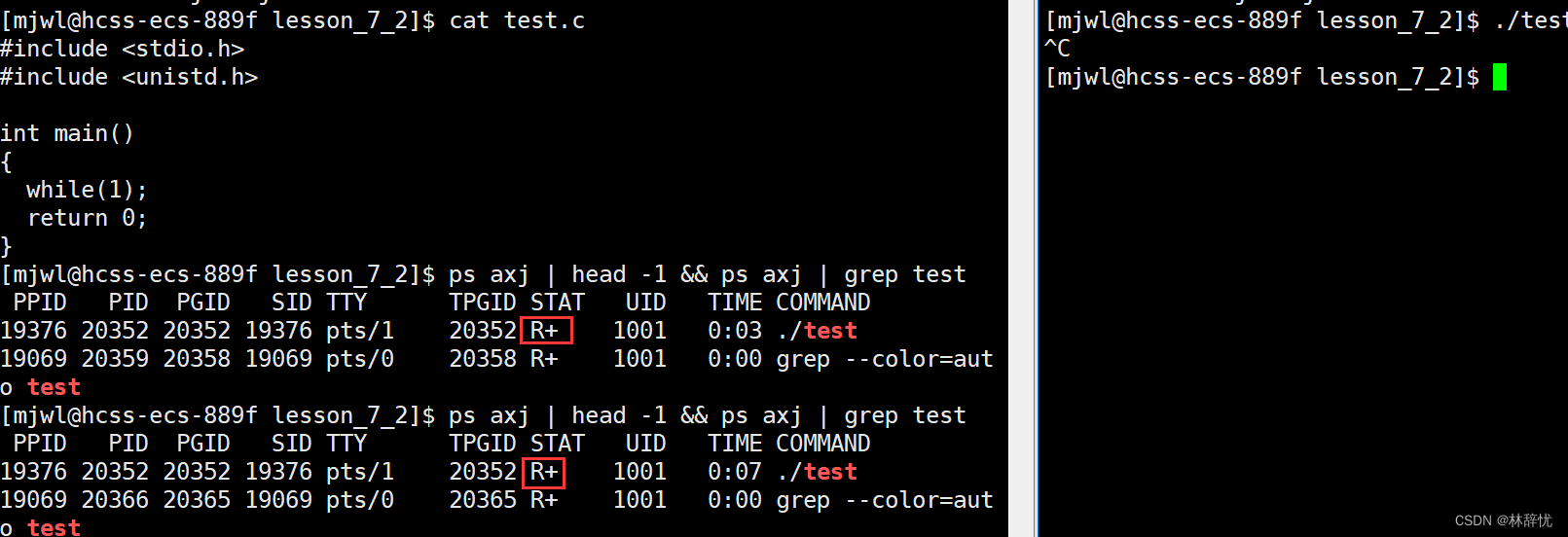
当无IO,纯运行时,就会变为R状态
3.S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠
(interruptible sleep)
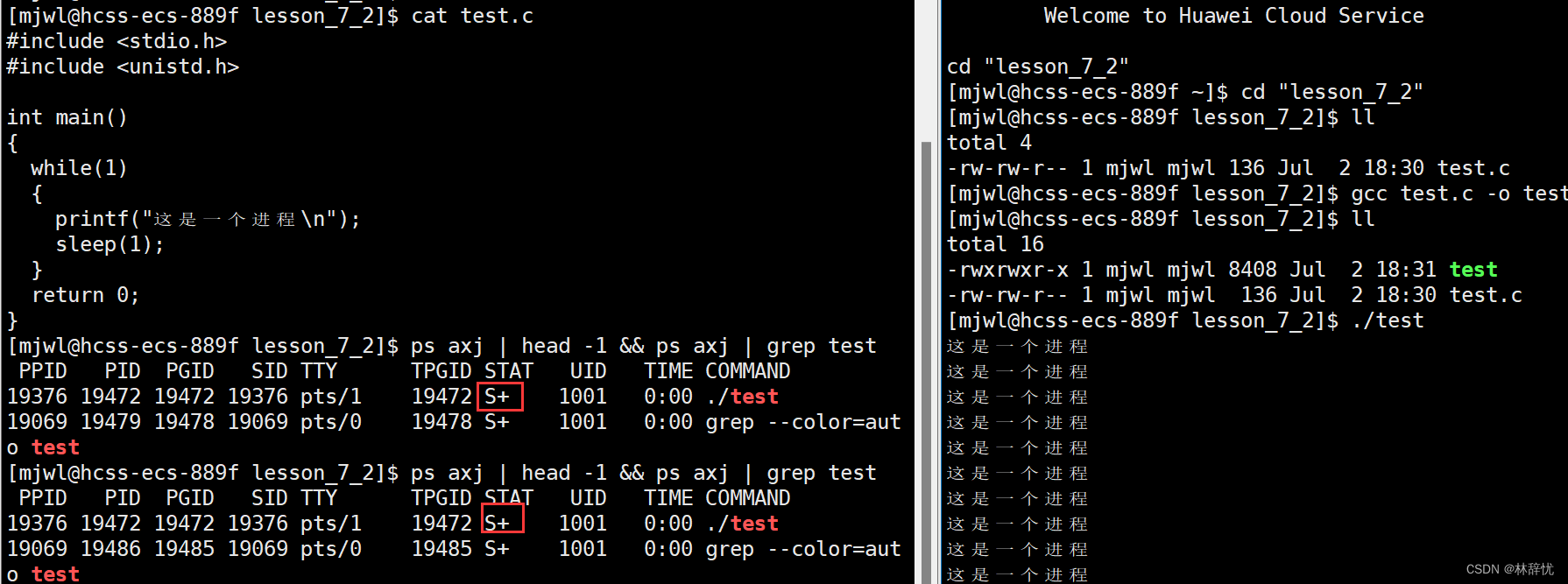
这里当printf是要访问显示器 的,当死循环打印时,设备不是处于一个正写入的状态,进程有很大可能是一直在等待的,所以是S+而不是R+;对于这里有+的表示是在前台执行的(当运行起来程序时,bash命令行解释器对输入的指令不再有反应),可以用ctrl+c终止进程,可以采用./test & 这样就会变为S,变为后台执行,此时就必须用kill -9 PID来终止进程
4.D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的进程通常会等待IO的结束
只要进程当前正在有写入任务交给磁盘时,如果磁盘没有办法立马响应的话,需要等待进程,这个进程就不能以S浅度睡眠的状态去等待,必须把自己设为D状态,D状态进程任何人都不能杀掉,包括操作系统,这样可以保证向磁盘中写入数据时,数据不会丢失。当磁盘把数据写完之后返回时,此时进程的状态就由D转变为R,供cpu调度执行
即进程在等待磁盘进行写入时,此时进程所处状态为D状态,是不响应操作系统的任何请求的
5.T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行
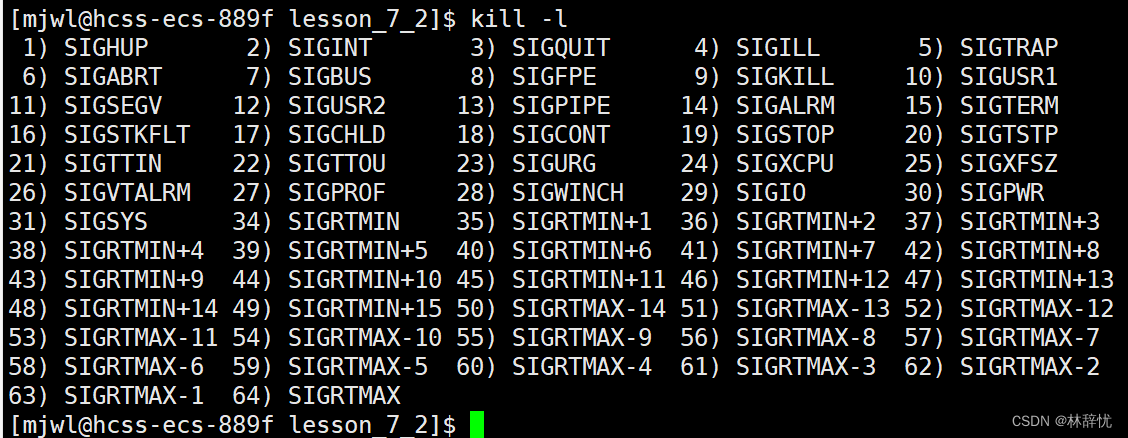
kill -l 查看信号
kill -19 PID 让当前进程停下 kill -18 PID 恢复当前进程由T变为R状态
S状态一定是在等待某种资源,而T状态可能在等待某种资源/被其他进程控制
6.X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态
7.Z(zombie)-僵尸状态
当一个进程死亡的时候,在死亡之时,并不会立即进入dead的状态,而是先进入Z状态
当一个进程退出时,它并不是退出之后立即将所有资源进行释放,而是操作系统需要把当前进程退出之时的退出信息维持一段时间,当对应的父进程读取到进城的信息,进程的资源才会被释放,这段时间所处的状态为Z状态,即我们把这样已经死掉的,但是当前需要由父进程来关心,此时进程所维持的状态
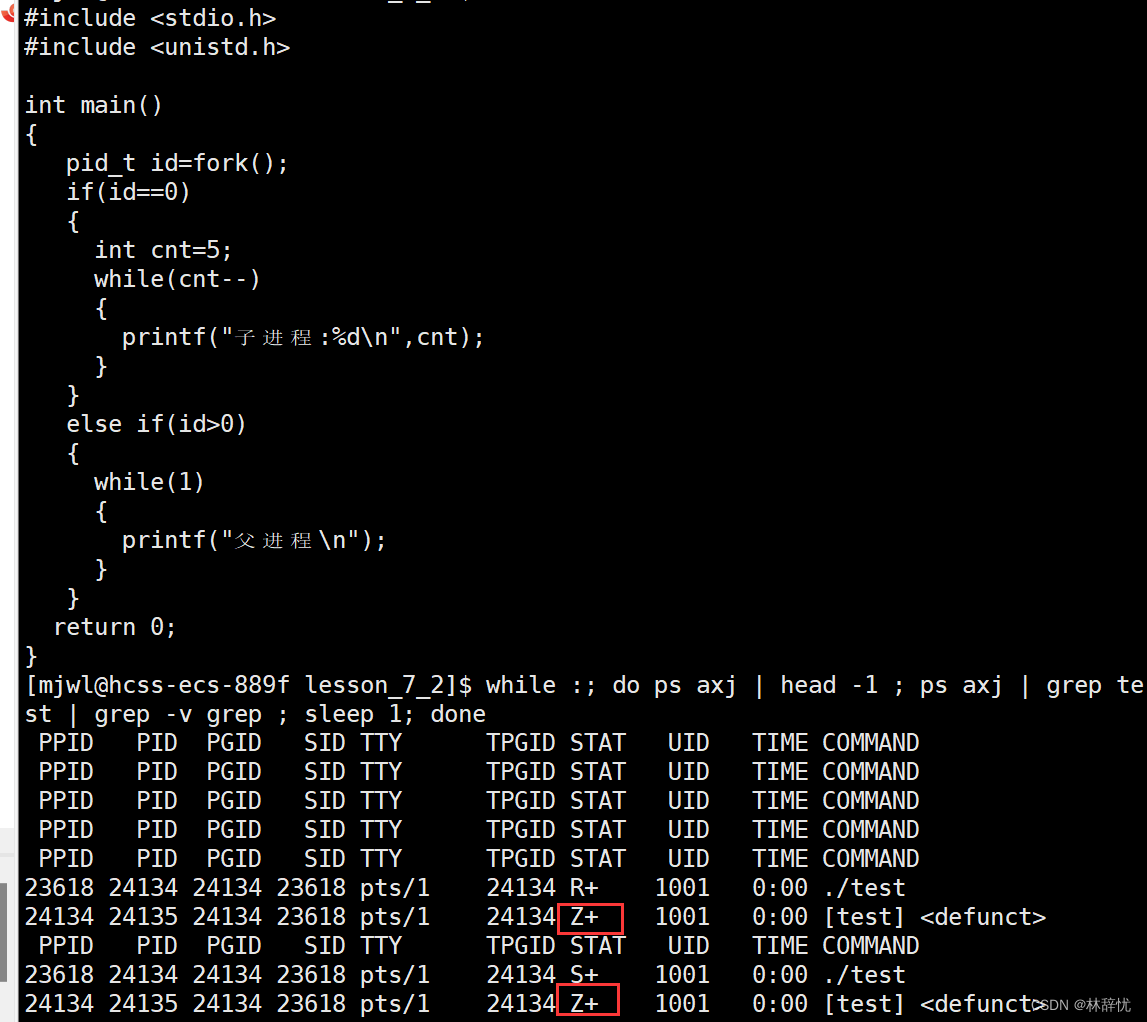
进程一般退出的时候,如果父进程没有主动收回子进程信息,子进程会让自己一直处于Z状态进程的相关资源尤其是task_struct结构体不能释放,所以会一直占用资源而且不释放,就会导致内存泄露,父进程是bash进程的子进程,退出时会被bash所回收
父子进程当父进程先退出,子进程的父进程会被改为1号进程(操作系统),即父进程是1号进程的子进程也叫做孤儿进程,该进程被操作系统所领养,为未来该进程退出时的释放资源
僵死状态(Zombies)是一个比较特殊的状态。当进程退出并且父进程使用wait()系统调用,后面讲没有读取到子进程退出的返回代码时就会产生僵死(尸)进程
僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码
只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态