K8S之网络深度剖析
一 、关于K8S的网络模型
在K8s的世界上,IP是以Pod为单位进行分配的。一个Pod内部的所有容器共享一个网络堆栈(相当于一个网络命名空间,它们的IP地址、网络设备、配置等都是共享的)。按照这个网络原则抽象出来的为每个Pod都设置一个IP地址的模型也被称作为IP-per-Pod模型。
Kubernetes对集群网络有如下要求:
- 所有容器都可以在不用NAT的方式下同别的容器通讯。
- 所有节点都可以在不用NAT的方式下同别的容器通讯。
- 容器的地址和别人看到的地址是同一个地址。
二、Docker 网络
Docker 使用到的与Linux网络有关的主要技术:
- 网络命名空间(Network Namespace)
- Veth 设备对
- 网桥
- Iptables
- 路由
2.1 网络命名空间
为了支持网络协议栈中的多个实例,Linux 2.6.24内核版本的网络协议栈中引入了网络命名空间,这些独立的协议栈被隔离到不用的命名空间中。处于不用命名空间中的网络栈是完全隔离的,彼此之间无法通讯,就好像两个"平行宇宙"。通过对于网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境。Docker 正是利用了网络的命名空间特性,实现了不同容器之间的网络隔离。
在Linux的网络命名空间中可以有自己独立的路由表,及独立的Iptables设置来提供包转发、NAT、及IP包过滤等功能。
为了隔离出独立的协议栈,需要纳入命名空间的元素有进程、套接字、网络设备等。进程创建的套接字必须属于某个网络命名空间,套接字的操作也必须在命名空间中进行。同样,网络设备也必须属于某个命名空间。因为网络设备属于公共资源,所以可以通过修改属性实现在命名空间之间移动。当然,是否允许移动,和设备的特征有关系。
2.1.1 网络命名空间的实现
Linux的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的这些全局变量都必须被修改为协议栈私有,最好的办法就是让这些全局变量成为一个 Net NameSpace变量的成员,然后修改协议栈的函数调用,在加入一个NameSpace的参数,这就是Linux 实现网络命名空间的核心。
同时,为了保证对已经开发的应用程序,以及内核代码的兼容性,内核代码隐式地使用了网络命名空间中的变量,程序如果没有对网络命名空间有特殊需求,就不需要编写额外的代码,网络命名空间对应用程序而言是透明的。
在建立了新的网络命名空间,并将某个进程关联到这个网络命名空间后,就出现了如下图的数据结构,所有的网络栈变量都没放到了私有的命名空间,和其他进程组并不冲突。
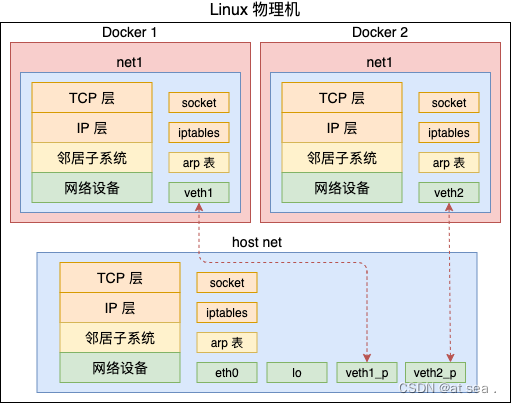
在新生成的理由命名空间中,只有回环设备,(名为"lo" 且是停止状态),其他设备默认都不存在,如果我们需要,则要一一手工建立,Docker容器中的各类网络栈设备都是Docker Daemon 在启动时自动创建和配置的。
所有的网络设备(物理的或虚拟接口、桥等在内核里都叫做Net Device)都只能属于一个命名空间、当然,物理设备(连接实际硬件的设备)通常只能关联到root 这个命名空间。虚拟的网络设备(虚拟的以太网接口或者虚拟网口对)则可以被关联到一个给定的命名空间,而且可以在这些命名空间中移动。
前面提到,由于网络命名空间代表的是一个独立的协议栈,所以它们之间是相互隔离的,彼此无法通讯,在协议栈内部都看不到对方, 那么有没有办法打破这种限制,让处于不同网络命名空间的网络互相通讯,甚至和外部的网络通讯呢? 答案就是"有",应用 "Veth设备对即可", Veth 设备对一个重要的作用就是打通互相看不到的协议栈的协议栈之间的壁垒,他就像一条管子,一端连着这个网络命名空间的协议栈,一端连着另一个网络命名空间协议栈,所以想要在两个命名空间之间通讯,就必须有一个 Veth 设备对。
2.1.2 网络命名空间的操作
我们可以使用 Linux iproute2 系列配置工具中的IP 命令来操作网络命名空间,注意: 这个命令需要使用root 用户来执行。
安装:
# alphine
apk add iproute2
# ubuntu
sudo apt install iproute2
# centos
sudo yum -y install iproute2创建一个网络命名空间:
ip netns add <name>创建一个名为test1 的网络命名空间
ip netns add test1在命名空间中执行命令:
ip netns exec <name> <command>在命名空间test1 执行 ip a s 命令
root@test:~# ip netns exec test1 ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00也可以先通过切换到对应的网络命名空间,执行各种命令:
ip netns exec <name> bash执行 exit 或Ctrl +d 退出当前网络命名空间。
上面的操作相当于网络命名空间进行了切换,文件系统还是当前,在Docker 中,其实也做了类似操作,并且将文件系统通过chroot 进行了切换,通过cgroup 对资源进行了隔离。
2.1.3 网络命名空间的实用技巧
操作系统网络命名空间的一些技巧如下:
我们可以在不同的网络命名空间之间转移设备,列如下面会提到的Veth 设备对的转移,因为一个设备只能属于一个命名空间,所以转移后在这个网络命名空间内就看不到这个设备了,具体哪些设备能被转移到不同的网络命名空间, 在设备里面有一个属性: NETIF_F_NETNS_LOCAL,如果这个属性为 on,就不能被转移到其他命名空间中。Veth 设备属于可转移设备,而其他设备如,lo 设备,vxlan,ppp 设备,bridge设备等都是不可转移的。将无法转移的设备移动到别的命名空间时,会得到无效的参数错误提示。
root@test1:~# ip link set lo netns test1
RTNETLINK answers: Invalid argument如何知道这些设备是否可以转移呢? 可以使用ethtool 工具查看:
root@test1:~# apt install ethtool
root@test1:~# ethtool -k docker0 | grep netns
netns-local: on [fixed]
root@test1:~# ethtool -k veth276e185 | grep netns
netns-local: off [fixed]2.1.4 使用nsenter 工具来切换网络命名空间
执行lsns 查看当前主机的namespace
root@test1:~# lsns
NS TYPE NPROCS PID USER COMMAND
4026531834 time 314 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531835 cgroup 312 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531836 pid 312 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531837 user 313 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531838 uts 308 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531839 ipc 312 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531840 net 308 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531841 mnt 297 1 root /lib/systemd/systemd --system --deserialize 35 splash
4026531862 mnt 1 62 root kdevtmpfs
4026532391 mnt 1 296 root /lib/systemd/systemd-udevd
4026532392 uts 1 296 root /lib/systemd/systemd-udevd
4026532421 mnt 1 471 systemd-resolve /lib/systemd/systemd-resolved
4026532422 mnt 1 472 systemd-timesync /lib/systemd/systemd-timesyncd
4026532423 mnt 1 2540333 systemd-oom /lib/systemd/systemd-oomd
4026532424 uts 1 2540333 systemd-oom /lib/systemd/systemd-oomd
4026532425 uts 1 472 systemd-timesync /lib/systemd/systemd-timesyncd
4026532426 mnt 1 10214 root /lib/systemd/systemd-logind
4026532427 uts 1 10214 root /lib/systemd/systemd-logind
4026532430 mnt 1 995086 fwupd-refresh /usr/bin/fwupdmgr refresh
4026532448 mnt 1 2435299 root sh
4026532449 uts 1 2435299 root sh
4026532450 ipc 1 2435299 root sh
4026532451 pid 1 2435299 root sh
4026532452 net 1 2435299 root sh
4026532483 mnt 1 30455 root /usr/libexec/accounts-daemon
4026532484 net 1 30455 root /usr/libexec/accounts-daemon
4026532485 net 1 10330 rtkit /usr/libexec/rtkit-daemon
4026532539 mnt 1 525 root /usr/sbin/irqbalance --foreground
4026532542 mnt 2 1469053 root /snap/snapd-desktop-integration/157/usr/bin/snapd-desktop-integration
4026532545 mnt 1 10629 root /usr/libexec/upowerd
4026532546 mnt 1 10631 root /usr/libexec/power-profiles-daemon
4026532547 user 1 10629 root /usr/libexec/upowerd
4026532549 mnt 1 10715 root /usr/sbin/ModemManager
4026532628 cgroup 1 2435299 root sh
4026532631 mnt 1 380128 root sh
4026532632 uts 1 380128 root sh
4026532633 ipc 1 380128 root sh
4026532634 pid 1 380128 root sh
4026532635 net 3 380128 root sh
4026532665 mnt 1 11076 colord /usr/libexec/colord
4026532692 cgroup 1 380128 root sh这里可以看到pid 380128 容器的namespace,主要为以下几个类型:
- mount
- uts
- ipc
- pid
- network
- user
我们可以通过如下的方法对容器进行抓包:
获取容器的Pid
root@test1:~# docker inspect -f "{{.State.Pid}}" a19dee489a47
380128可以看到有多个namespace
ls -l /proc/380128/ns/
total 0
lrwxrwxrwx 1 root root 0 7月 2 22:19 cgroup -> 'cgroup:[4026532692]'
lrwxrwxrwx 1 root root 0 7月 2 22:19 ipc -> 'ipc:[4026532633]'
lrwxrwxrwx 1 root root 0 7月 2 22:19 mnt -> 'mnt:[4026532631]'
lrwxrwxrwx 1 root root 0 6月 28 15:56 net -> 'net:[4026532635]'
lrwxrwxrwx 1 root root 0 7月 2 22:19 pid -> 'pid:[4026532634]'
lrwxrwxrwx 1 root root 0 7月 2 22:21 pid_for_children -> 'pid:[4026532634]'
lrwxrwxrwx 1 root root 0 7月 2 22:19 time -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 7月 2 22:21 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 7月 2 22:19 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 7月 2 22:19 uts -> 'uts:[4026532632]'进入对应Pid 的Network Namespace
root@test1:~# nsenter -t 380128 -n
root@test1:~# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
76: eth0@if77: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever2.2 Veth 设备对
Veth设备对的出现是为了解决不同的网络命名空间之间通讯,利用它可以将两个网络命名空间进行连接,由于要连接多个网络命名空间,所以Veth 设备基本都是成对出现的,很像一对以太网卡,并且中间有一根直连的网线。既然是一对网卡,我们将其中一端称之为另一端的peer。在veth 另一端发送数据时,它会将数据直接发送到另一端,并触发另一端的接收操作。
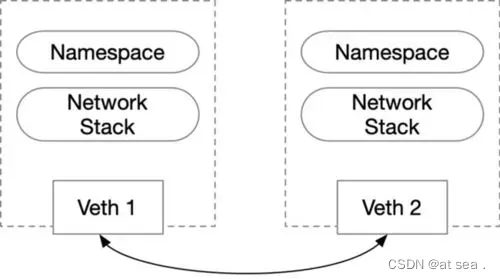
2.2.1 Veth 设备对的操作命令
创建veth设备对:
root@test1:~# ip link add veth0 type veth peer name veth1创建后,使用ip link show 查看所有网络接口
root@test1:~# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp6s18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 2e:8d:36:b4:77:40 brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ae:2b:65:9a brd ff:ff:ff:ff:ff:ff
69: veth9b5ea1d@if68: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 7e:29:46:4f:52:9e brd ff:ff:ff:ff:ff:ff link-netnsid 0
77: veth276e185@if76: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 0e:73:3e:73:b5:b3 brd ff:ff:ff:ff:ff:ff link-netnsid 1
82: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6e:3b:cf:dc:10:a6 brd ff:ff:ff:ff:ff:ff
83: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether da:61:bf:d0:bf:25 brd ff:ff:ff:ff:ff:ff可以看到,上面的命令生成了两个网络接口 一个是veth1 他的peer 是veth0,现在两个设备都在默认的命名空间,我们将其中一个设备加入到另一个命名空间
root@test1:~# ip link set veth1 netns test1这时在外面看两个设备的情况
root@test1:~# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp6s18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 2e:8d:36:b4:77:40 brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ae:2b:65:9a brd ff:ff:ff:ff:ff:ff
69: veth9b5ea1d@if68: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 7e:29:46:4f:52:9e brd ff:ff:ff:ff:ff:ff link-netnsid 0
77: veth276e185@if76: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 0e:73:3e:73:b5:b3 brd ff:ff:ff:ff:ff:ff link-netnsid 1
83: veth0@if82: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether da:61:bf:d0:bf:25 brd ff:ff:ff:ff:ff:ff link-netns test1只剩下一个veth 设备了,已经看不到另一个设备了,另一个设备已经被转移到了test1的网络命名空间中了。
在test1的网络命名空间中可以看到veth1 设备,符合预期
root@test1:~# ip netns exec test1 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
82: veth1@if83: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6e:3b:cf:dc:10:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 0现在我们看到,两个不用的命名空间中有一个veth 设备,在Docker的实现里面,它除了将veth 放入到容器内,还将它的名字改成了eth0
现在我们给他分配一个IP地址,让他们可以通讯
root@test1:~# ip netns exec test1 ip addr add 10.1.1.1/24 dev veth1
root@test1:~# ip addr add 10.1.1.2/24 dev veth0在启动他们:
root@test1:~# ip netns exec test1 ip link set dev veth1 up
root@test1:~# ip link set dev veth0 up现在两个网络命名空间可以互相通讯了
root@test1:~# ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.074 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.064 ms
root@test1:~# ip netns exec test1 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.130 ms在Docker内部,Veth 设备是连通容器与宿主机网络的主要设备。
2.2.2 veth 设备如何查看对端
一旦将veth 设备对的另一端放入另一个命名空间,在本命名空间就看不到它了,那我们如何知道设备的对端在哪里呢?可以使用ethtool 工具来查看(当网络命名空间较多时,这个也不太容器)。
首先,在命名空间test1中查询Veth设备对端接口在设备列表中的序列号:
root@test1:~# ip netns exec test1 ethtool -S veth1
NIC statistics:
peer_ifindex: 83获取另一端的接口序列号是83,我们在查看序列号83是什么设备
root@test1:~# ip link | grep 83
83: veth0@if82: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 10002.3 网桥
Linux可以支持多个不同的网络,他们之间可以相互通讯,如何将这些网络连接起来,并实现各网络中主机的相互通讯? 可以用网桥,网桥是一个二层的虚拟网络设备,把若干个网络接口"连接"起来,使得网络接口之间得报文能够互相转发,网桥能够解析收发得报文,读取目标MAC地址得信息,和自己记录得Mac表结合,来决策报文的转发目标网络接口,为了实现这些功能,网桥会学习源MAC地址(二层网桥转发得依据就是MAC地址),在转发报文时,网桥只需要向特定得网口进行转发,来避免不必要得网络交互,如果他遇到一个自己从未学习过得地址,就无法知道这个报文需要转发给哪个网络接口,就将报文广播给所有得网络接口(报文来源得接口除外)。
在实际得网络中,网络拓扑不可能永远不变,设备如果被移动到另一个端口上,却没有发送任何数据,网桥设备就无法感知这个变化,网桥还是向原来得端口转发数据时,这种情况数据就会丢失。所以网桥还要对学习到的MAC地址表加上超时时间(默认为5min)。如果网桥收到了对应带你看MAC地址回发的数据包,则重置超时时间,否则过了超时时间后,就认为设备已经不再那个端口上,它就会重新发送广播。
Linux内核支持网口的桥接(目前只支持以太网接口),但是与单纯的交换机不同,交换机只是一个二层设备,对于接收到的报文,要么转发,要么丢弃.运行着Linux 内核的机器本身就是一台主机,有可能时网络报文的目的地,其收到的报文除了转发和丢弃,还有可能会被送到网络协议栈的上层(网络层),从而被自己(这台主机本身的协议栈)消化,所以我们既可以把他当作一个二层设备,也可以当作一个三层设备。