kafka consumer客户端消费逻辑解析
一、主要步骤
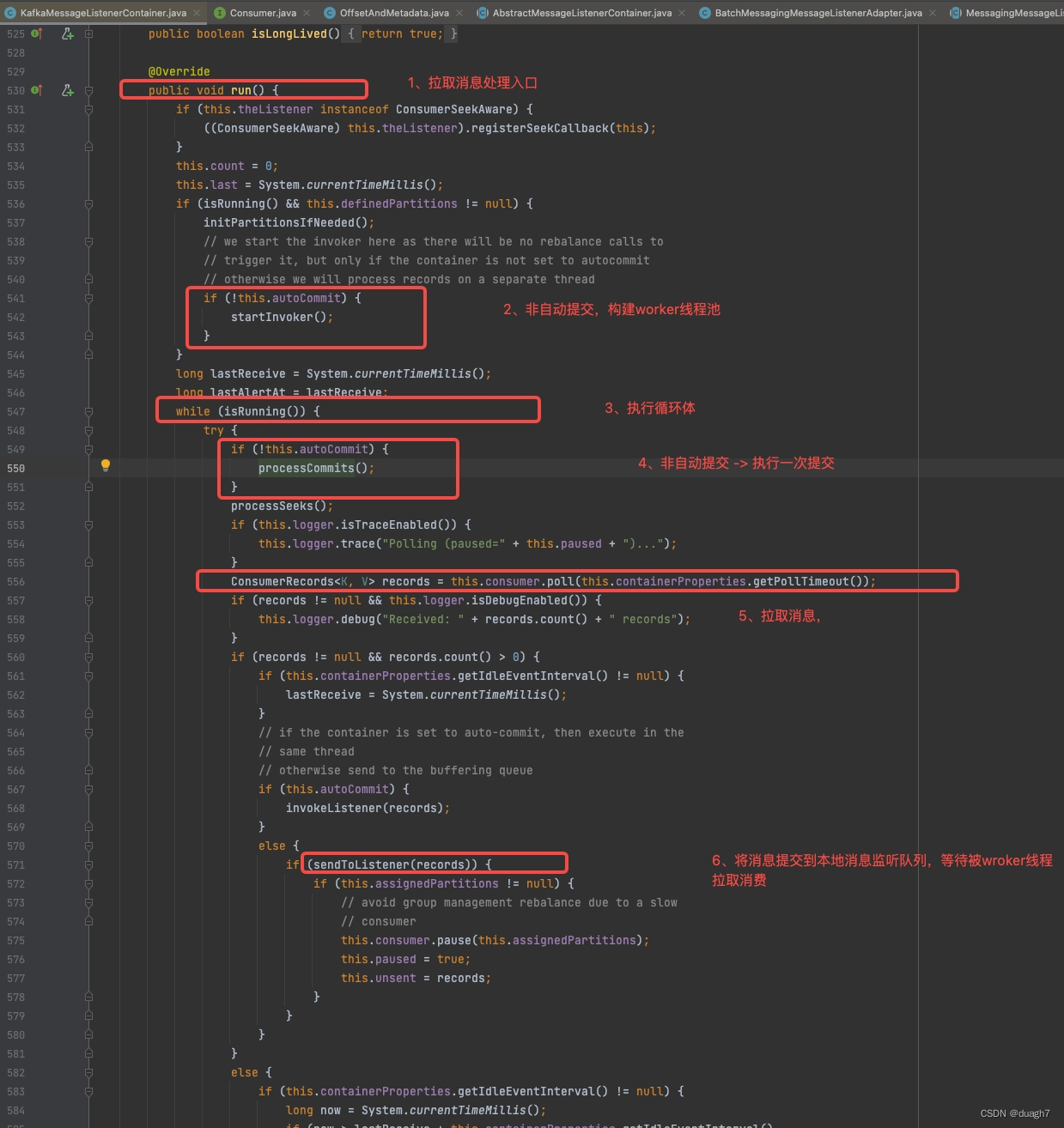
这是kafka客户端拉取消息的入口,有4个主要部分
1、启动后的准备
consumer线程启动后,如果非自动提交模式,构建worker线程放入worker线程池,供后续消费消息使用
2、运行期逻辑循环------提交策略
3、运行期逻辑循环------消息拉取
4、运行期逻辑循环------消息消费
二、提交策略
【步骤2代码解析】
2.1 在拉取消息之前,如果非自动提交,进行提交判定:
需要提交的消息(ConsumerRecord)会维护在acks------本地已处理待提交消息队列(一个linkedBlockingQueue)中,这里会把acks里所有消息拿出来进行循环处理。
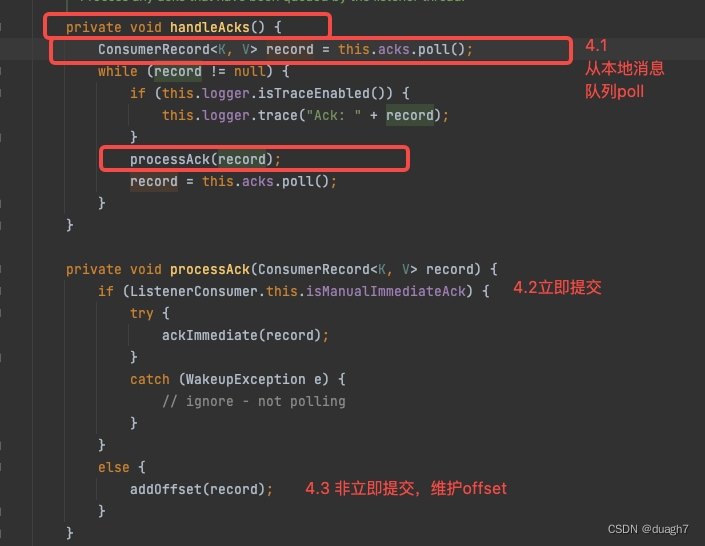
(2-1-1) ack策略-立即提交:说明在配置了手动提交-立即提交的ack策略时,提交动作是每次消息拉取前,worker线程已处理完的消息的offset,挨个put进本地的partition和offset的映射(metadata中一个map)。由于是循环处理worker队列,而消息是乱序存放的,所以put之前判断offset大于现有offset才会执行,确保低offset不覆盖高offset。
put后会直接进行网络请求提交到broker中。(由于在循环中,这里的请求会发生多次?没细看)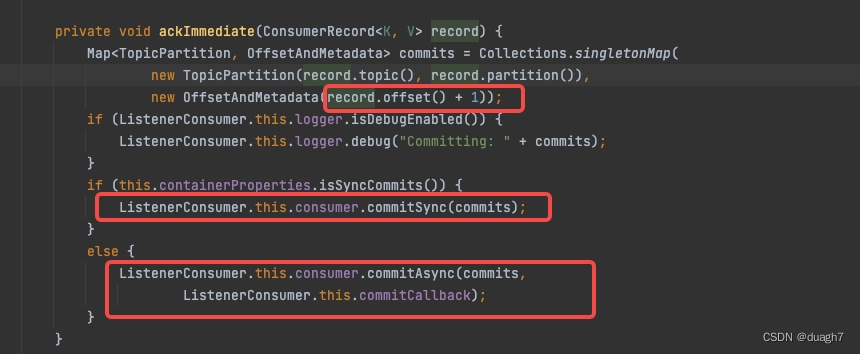

(2-1-2) ack策略-非立即提交:
和2-1-1一样,都会维护分区最高位移映射。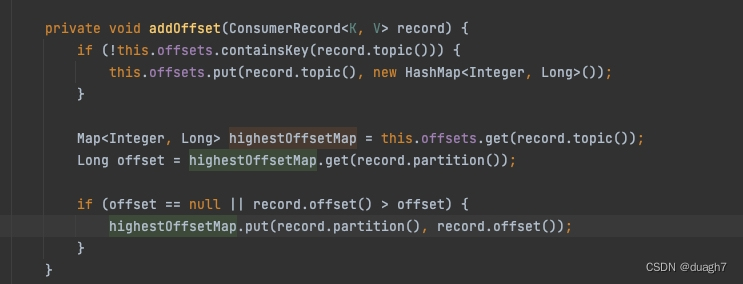
接下来会根据具体的提交规则配置来判定是否提交,
1、未提交数:未提交数 >= 配置
2、提交时间间隔:上次提交 - 当前时间 >= 配置
3、未提交数或提交时间间隔:1或2任意满足
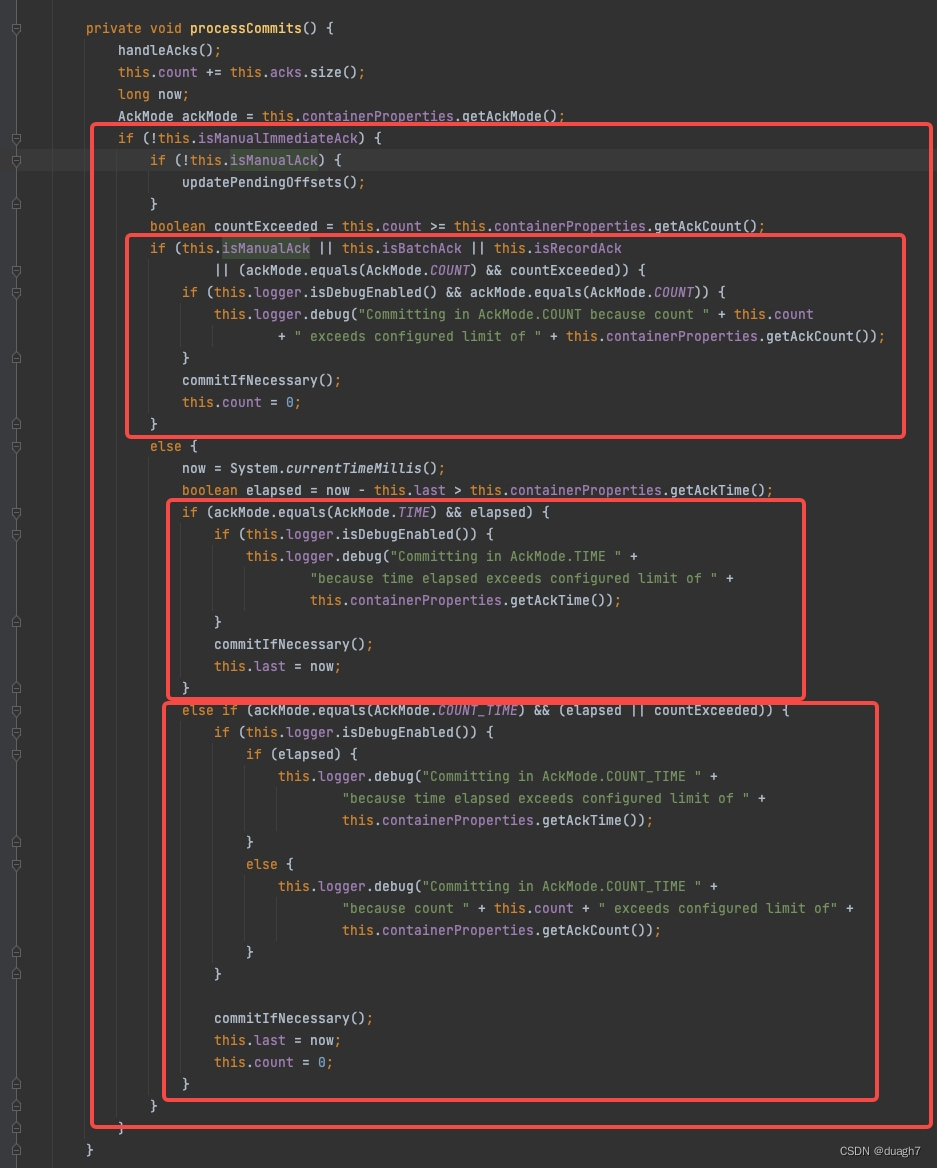
【提交策略总结】
一、提交模式
1、自动提交:拉取消息后立即提交
2、手动(非自动)提交:
2-1、拉取消费前执行一次提交判定
二、提交判定
1、立即提交:无需判定
2、非立即提交:根据配置的规则判定
2-1、满足提交时间间隔可提交
2-2、满足未提交数计算可提交
2-3、满足2-1或2-2可提交
三、拉取策略

会循环尝试拉取消息直到超时(最大尝试拉取时长)
四、消费策略
【代码解析】
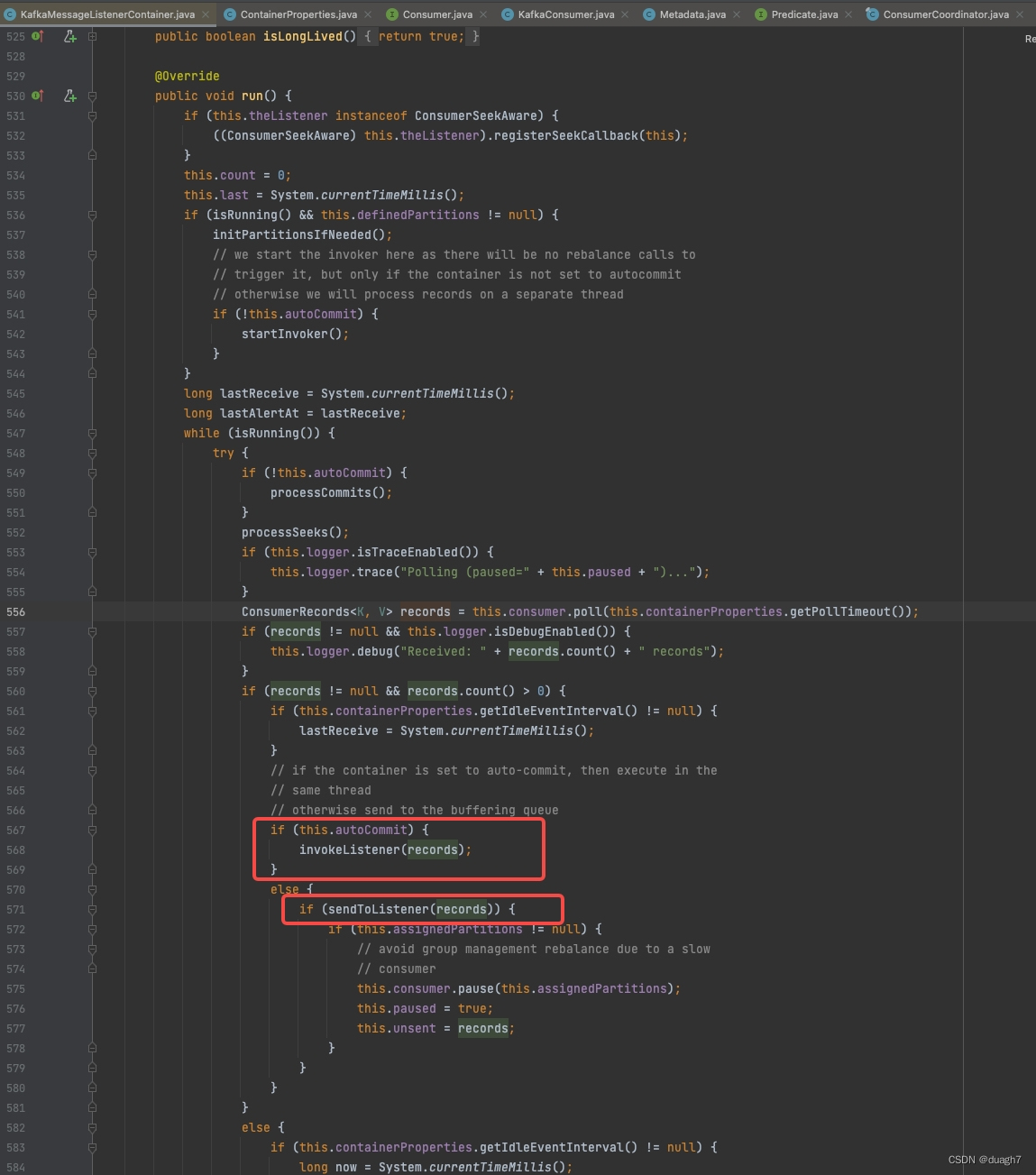
从待消费消息列表拉取消息,用当前线程或分配给worker线程。worker线程和拉取线程1:1(worker线程为什么不是多个?)

自动提交,用当前线程直接进行消费(可能阻塞消息拉取和位移提交)
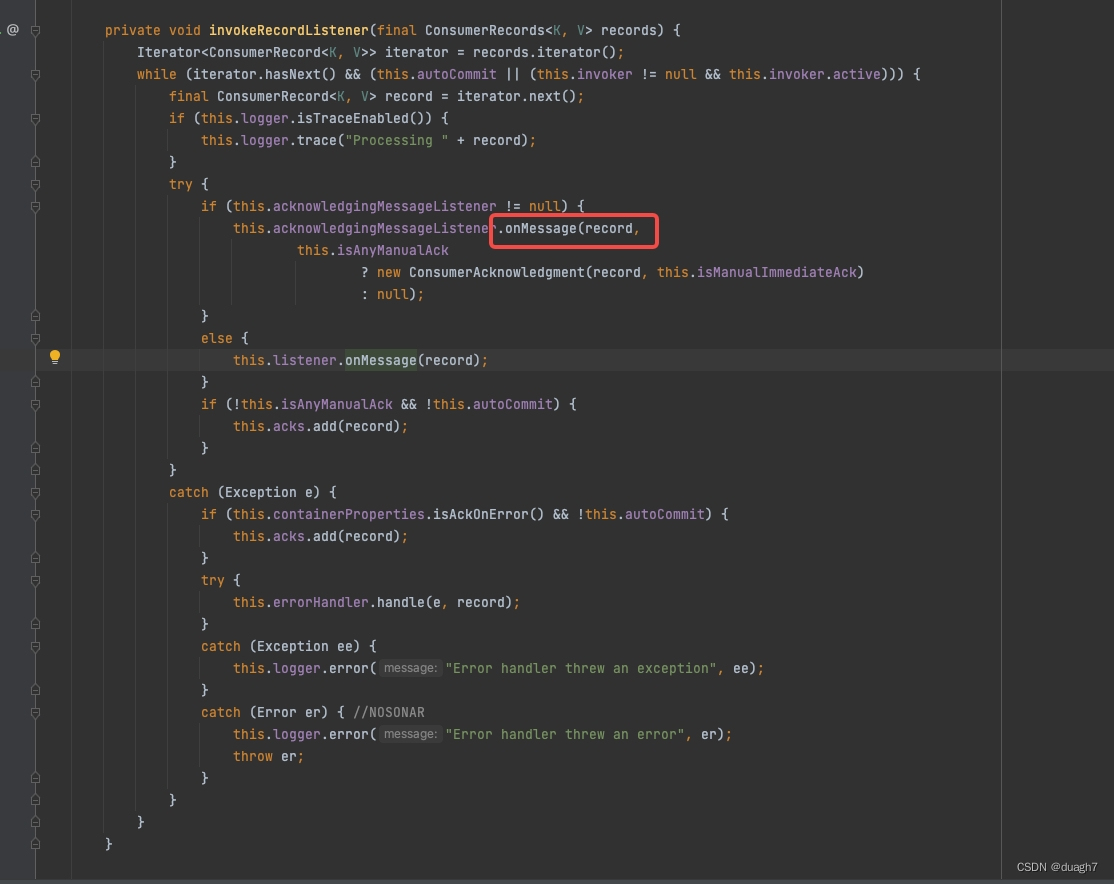
手动提交,加入待处理消息队列(一个linkedBlockingQueue),等待消费线程拉取并消费
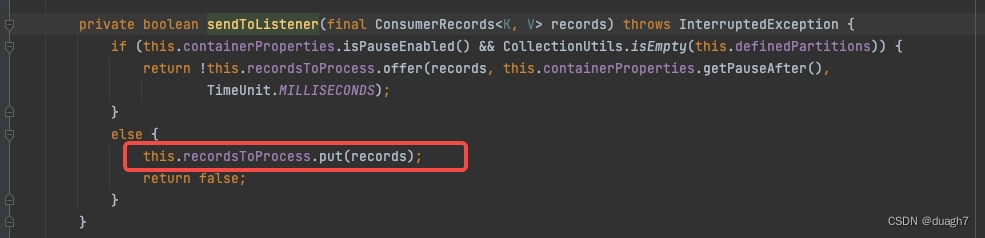
从待处理消息队列拉取消息,循环进行消费,消费后加入已处理待提交队列

【消费策略总结】
【消费主体】
1、自动提交:consume线程自我消费(会阻塞消息拉取和位移提交)
2、手动提交:worker线程异步消费
【消费模式】
循环消费