作者:默语佬
CSDN技术博主
原创文章,转载请注明出处
前言
最近在社群里看到一个有趣的现象:很多技术同学在面试时,简历上写了使用某款消息中间件的经验,结果面试官追问"为什么选这款而不选那款?"时,往往答不上来。这让我想起自己多年前面试时的窘境------我能熟练使用RocketMQ,却说不清楚为什么团队当初选了它而不是Kafka。
作为一名在分布式系统领域摸爬滚打十年的老兵 ,我深刻体会到:技术选型不是技术比武,而是业务需求的精准匹配。今天,我想从实战角度,深入剖析RocketMQ、Kafka、RabbitMQ三大主流消息中间件的选型逻辑,帮助大家建立系统化的技术决策思维。
目录
消息中间件选型的本质
选型的三个维度
我个人认为,消息中间件的选型本质上是在平衡三个核心维度:性能、可靠性、功能复杂度。
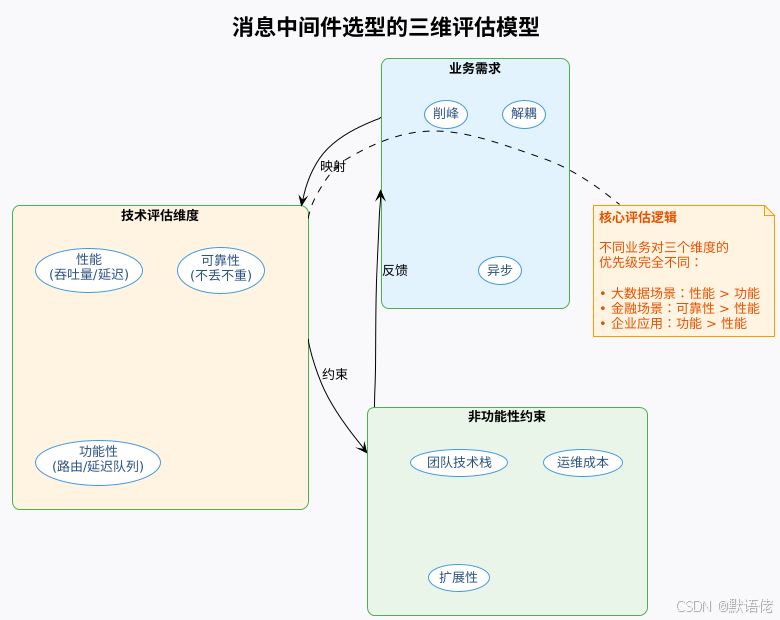
我的观点 :很多团队在选型时,容易陷入"性能至上"的误区,认为吞吐量越高越好。但实际上,过度追求性能往往会牺牲可靠性和功能性。比如,一个日处理百万级订单的电商系统,如果为了追求极致吞吐选择了Kafka,可能会在订单一致性保障上遇到技术难题,反而增加了开发成本。
常见的选型误区
根据我多年的实战经验,总结出以下几个常见误区:
| 误区 | 表现 | 后果 | 正确做法 |
|---|---|---|---|
| 跟风选型 | "大厂都用Kafka,我们也用" | 业务场景不匹配,投入产出比低 | 先分析自身需求 |
| 过度设计 | "万一以后要用,先选功能最全的" | 系统复杂度高,运维成本大 | 按当前需求选型 |
| 忽视运维 | "选最快的就行,运维交给运维" | 上线后故障频发,背锅 | 评估团队运维能力 |
| 技术债务 | "先能跑就行,以后再优化" | 历史包袱重,迁移成本高 | 选型时考虑长远 |
三大中间件的核心特性剖析
接下来,我将从架构设计、性能表现、功能特性三个角度,深入剖析三款中间件的核心差异。
Kafka:为大数据而生的高吞吐引擎
设计哲学 :Kafka最初由LinkedIn开发,核心目标是解决海量日志数据的实时传输 问题。因此,它的所有设计都围绕"高吞吐、低延迟、水平扩展"展开。
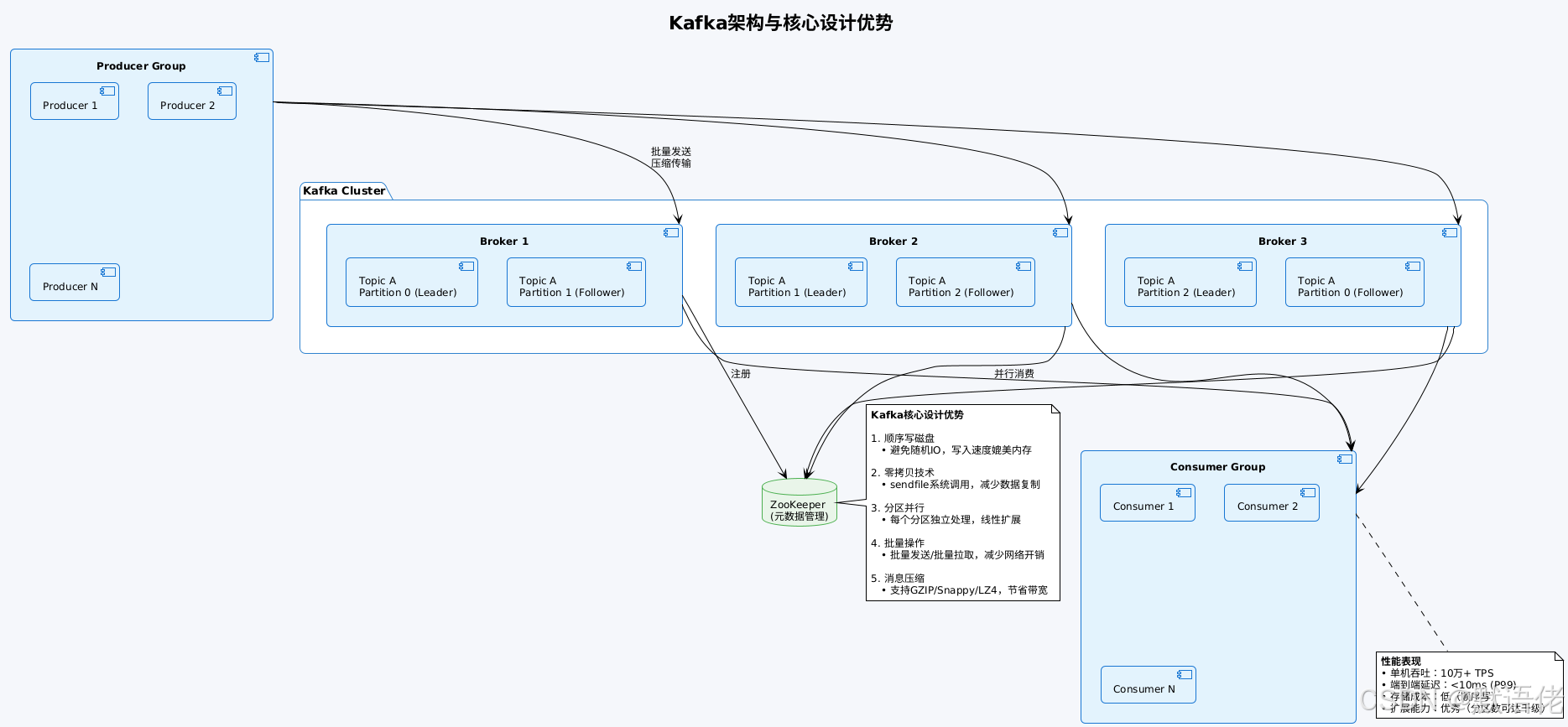
核心优势:
-
吞吐能力无敌
- 单机可达10万+条/秒,集群可轻松达到百万+条/秒
- 我曾在一个日处理50亿条消息的日志系统中使用Kafka,6台普通服务器就能稳定支撑
-
存储成本低
- 通过顺序写和时间段保留策略,可以低成本存储TB级消息
- 支持消息回溯,可以"重放"历史数据
-
生态成熟
- 与Flink、Spark、Hadoop等大数据组件深度集成
- Kafka Streams、Kafka Connect等周边工具丰富
核心劣势:
-
事务支持弱
- 虽然Kafka 0.11+支持事务,但只能保证"消息发送的原子性",无法保证"本地业务+消息发送"的跨系统事务
-
功能相对简单
- 只支持Topic-Partition的简单路由,没有延迟队列、死信队列等高级特性
-
运维复杂
- 依赖ZooKeeper(虽然新版KRaft模式已去除),集群运维有一定门槛
我的实战经验 :在一个电商的用户行为分析项目中,我们需要收集每天100亿+的用户点击事件,传输到实时计算平台。最开始团队考虑用RocketMQ,但压测发现单机吞吐只有3万+TPS,需要部署30+台机器。后来改用Kafka,6台机器就能稳定支撑,且与Flink集成非常顺畅。这个案例让我深刻理解:Kafka的定位就是大数据场景的"数据总线"。
RocketMQ:互联网核心业务的可靠保障
设计哲学 :RocketMQ诞生于阿里巴巴的电商场景,核心目标是解决高并发交易场景下的消息可靠性与一致性 问题。因此,它在高吞吐与强可靠性之间做了精妙的平衡。
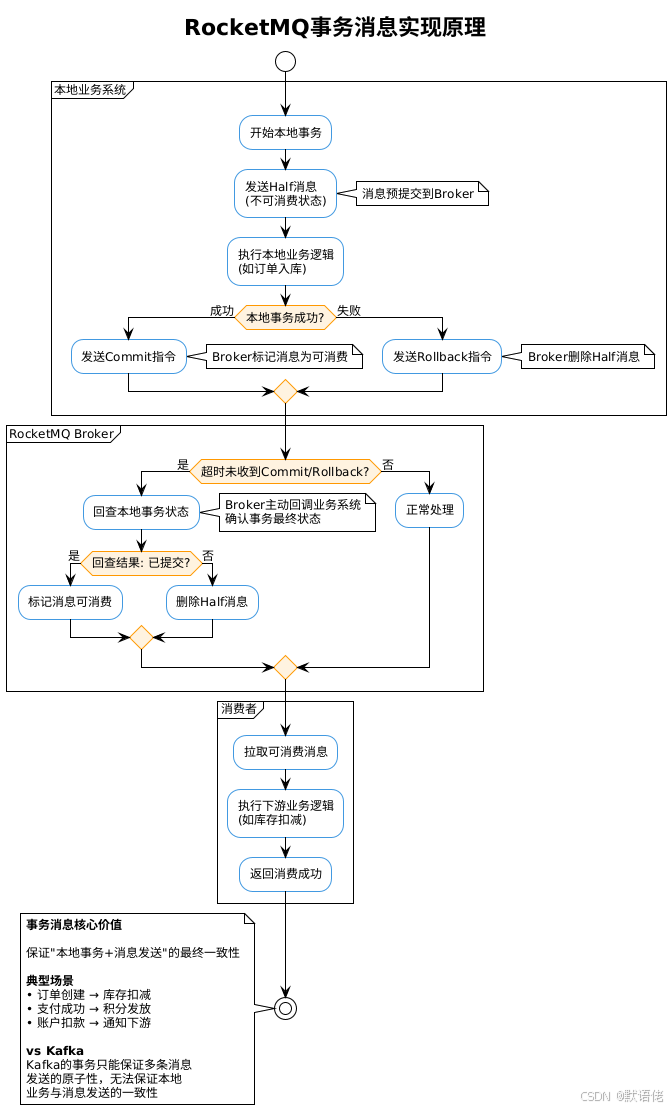
核心优势:
-
事务消息成熟
- 基于两阶段提交+事务回查机制,严格保证分布式事务一致性
- 这是RocketMQ相比Kafka的最大优势
-
性能与可靠性平衡
- 单机吞吐可达3-5万TPS(虽不及Kafka,但远超RabbitMQ)
- 支持同步刷盘、主从同步等可靠性配置,消息零丢失
-
削峰填谷能力强
- 支持流控、消息堆积、延迟消费等特性,能应对电商大促的突发流量
-
国内生态好
- 中文文档完善,社区活跃,阿里云提供商业版支持
核心劣势:
-
吞吐能力不及Kafka
- 在百万级TPS的场景下,需要更多机器资源
-
功能不及RabbitMQ灵活
- 路由能力相对简单,没有RabbitMQ的Exchange机制
-
运维学习曲线
- NameServer、Broker、消费组等概念需要学习成本
我的实战经验 :在一个金融支付项目中,核心需求是"用户扣款成功后,必须通知下游系统发放权益"。如果用Kafka,需要自己实现分布式事务补偿逻辑,开发成本高且容易出错。改用RocketMQ的事务消息后,Broker帮我们保证了"扣款+消息发送"的一致性,代码量减少了70%,且上线后零事故。这让我深刻体会到:RocketMQ的定位是"互联网核心业务的可靠中间件"。
RabbitMQ:企业级应用的灵活路由专家
设计哲学 :RabbitMQ基于AMQP协议实现,起源于金融行业,核心目标是提供灵活的消息路由与丰富的企业级特性。
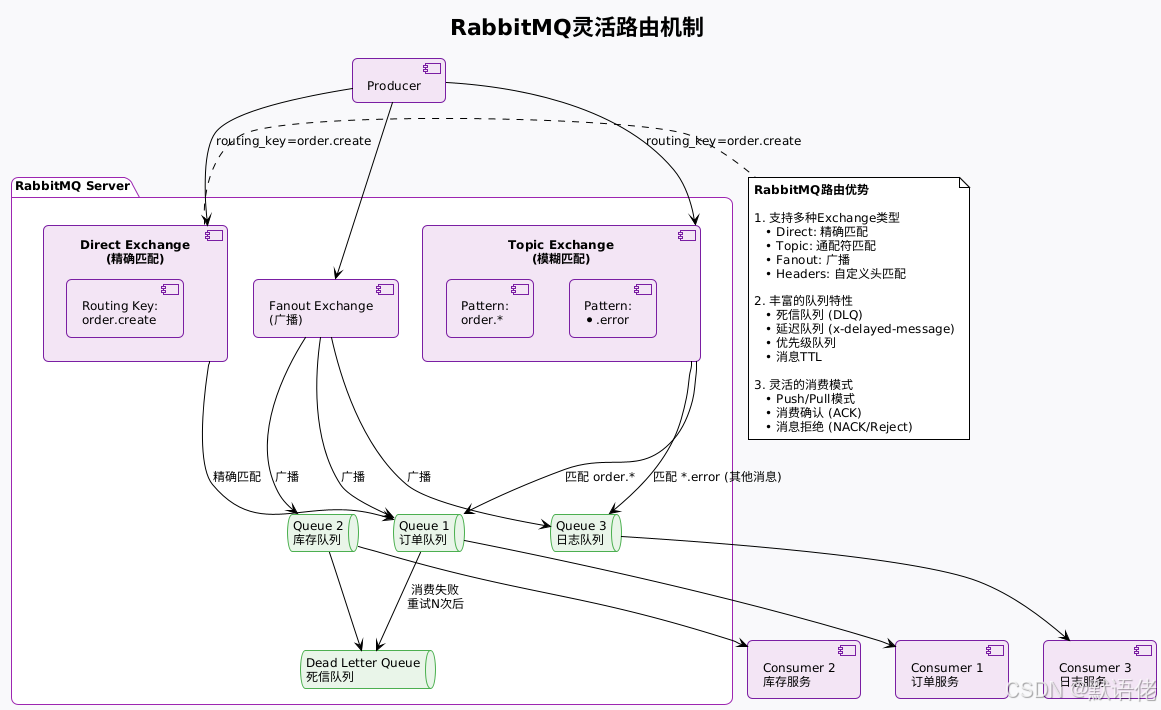
核心优势:
-
路由功能强大
- Exchange机制支持复杂的消息分发逻辑
- 我曾在一个企业ERP系统中,用Topic Exchange实现了"根据业务类型+优先级"的动态路由
-
功能特性完善
- 内置延迟队列、死信队列、消息TTL、优先级等特性
- 不需要额外开发就能实现订单超时取消、异常消息重试等场景
-
易用性高
- Web管理界面直观,配置简单
- 社区活跃,问题排查容易
-
跨语言支持好
- 官方提供Java、Python、Go、.NET等多种客户端
核心劣势:
-
吞吐能力有限
- 单机通常只有数千TPS,无法支撑大数据场景
-
集群扩展性差
- 集群节点数超过10个后,性能会明显下降
- 镜像队列机制导致网络开销大
-
可靠性配置复杂
- 需要正确配置持久化、镜像队列、发布确认等多个参数才能保证消息不丢
我的实战经验 :在一个B2B供应链系统中,同一个"货物入库"事件,需要通知采购、仓储、财务、物流等多个部门,且每个部门需要的数据字段不同。用Kafka需要创建多个Topic,且无法灵活过滤;用RocketMQ需要在消费端写大量if-else判断。最后选择RabbitMQ的Topic Exchange,通过routing_key实现了灵活路由,代码量减少50%。这个案例让我理解:RabbitMQ的定位是"企业级应用的消息总线"。
典型业务场景的最佳实践
基于实战经验,我总结了不同业务场景的中间件选型最佳实践:

场景一:电商订单系统(RocketMQ)
需求分析:
- 订单创建后,需要异步通知库存扣减、物流下单、积分发放等多个下游系统
- 核心诉求:保证订单与下游操作的最终一致性
- 流量特点:平时每秒数千订单,大促时每秒数万订单
为什么选RocketMQ而不是Kafka?
我的理由是:
- 事务消息能力:RocketMQ的事务消息能保证"订单入库+消息发送"的原子性,Kafka做不到
- 性能够用:单机5万TPS足够支撑大促流量,且成本可控
- 削峰能力:RocketMQ的流控机制能平滑处理突发流量,避免下游系统被打垮
如果用Kafka,需要自己实现事务补偿逻辑(如定时任务扫描未通知的订单),开发成本高且容易出错。
场景二:用户行为分析(Kafka)
需求分析:
- 收集App端用户的点击、浏览、搜索等行为数据
- 核心诉求:支撑每天百亿级的海量数据传输,低延迟传给Flink做实时计算
- 可靠性要求:数据允许少量丢失(对业务影响小)
为什么选Kafka而不是RocketMQ?
我的理由是:
- 吞吐能力:Kafka单机10万+TPS,RocketMQ只有5万TPS,机器成本差一倍
- 生态集成:Kafka与Flink的集成最成熟,延迟最低
- 存储成本:Kafka的顺序写+时间段保留策略,存储成本低
如果用RocketMQ,需要部署2倍的机器才能支撑流量,且与Flink集成需要自己开发,得不偿失。
场景三:供应链多系统通知(RabbitMQ)
需求分析:
- 货物状态变更后,需要根据不同业务类型,通知不同的下游部门
- 核心诉求:灵活的消息路由,避免在代码里写大量if-else
- 流量特点:每秒数百条消息,但路由逻辑复杂
为什么选RabbitMQ而不是Kafka/RocketMQ?
我的理由是:
- 路由灵活:Topic Exchange的通配符路由完美匹配需求
- 功能丰富:内置延迟队列、死信队列等特性,满足复杂业务流程
- 吞吐够用:数千TPS的吞吐能力完全满足需求,无需过度设计
如果用Kafka,需要创建多个Topic,且消费端需要写大量过滤逻辑;用RocketMQ也有类似问题。只有RabbitMQ的Exchange机制能优雅解决。
技术选型决策模型
基于多年经验,我总结了一套实用的"四步决策法":
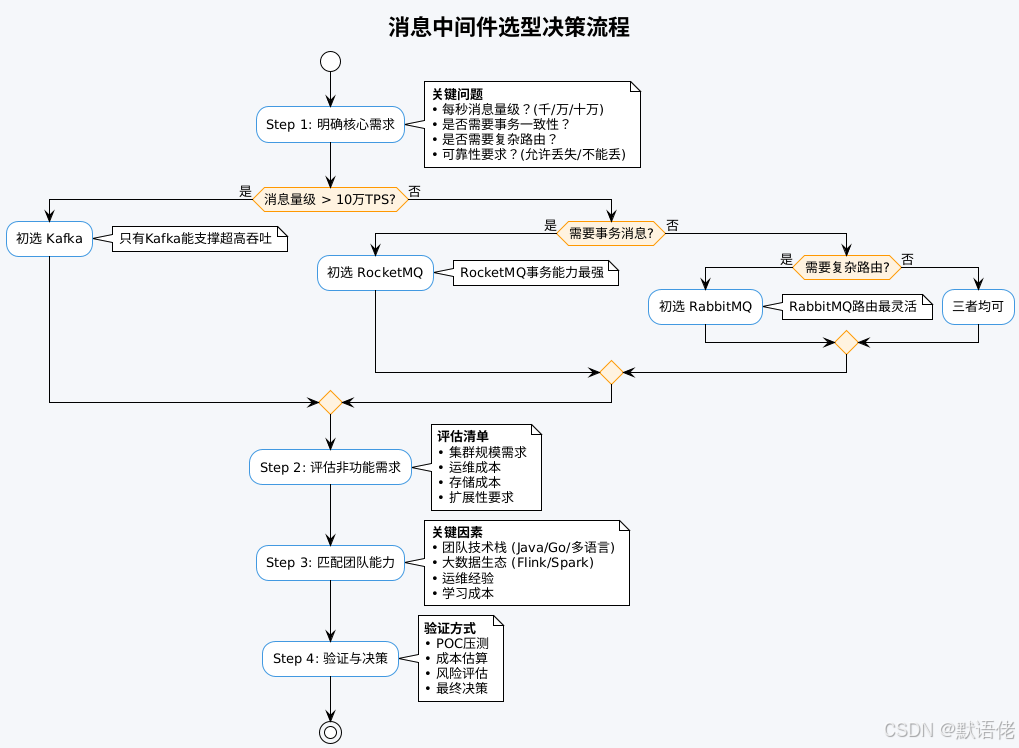
决策矩阵
我个人总结了一个"评分矩阵",帮助快速决策:
| 评估维度 | Kafka | RocketMQ | RabbitMQ | 权重 |
|---|---|---|---|---|
| 吞吐能力 | ⭐⭐⭐⭐⭐ (10万+) | ⭐⭐⭐⭐ (5万) | ⭐⭐ (5千) | 30% |
| 事务支持 | ⭐⭐ (弱) | ⭐⭐⭐⭐⭐ (强) | ⭐⭐⭐ (中) | 25% |
| 路由能力 | ⭐⭐ (简单) | ⭐⭐⭐ (中) | ⭐⭐⭐⭐⭐ (强) | 20% |
| 可靠性 | ⭐⭐⭐⭐ (高) | ⭐⭐⭐⭐⭐ (极高) | ⭐⭐⭐⭐ (高) | 15% |
| 易用性 | ⭐⭐⭐ (中) | ⭐⭐⭐ (中) | ⭐⭐⭐⭐⭐ (高) | 10% |
使用方法:根据业务对各维度的权重要求,计算加权得分,选择得分最高的中间件。
示例:
- 如果业务是"大数据日志采集",吞吐权重调高到50%,Kafka得分最高
- 如果业务是"金融支付",事务+可靠性权重调高到60%,RocketMQ得分最高
- 如果业务是"企业工作流",路由+易用性权重调高到60%,RabbitMQ得分最高
生产环境的实战经验
经验一:混合使用是常态
我的观点:在大型互联网公司,同时使用多款消息中间件是常态,而非"非此即彼"。
实战案例:在我负责的一个电商平台中,我们同时使用了三款中间件:
- Kafka:用于日志采集、用户行为埋点,每天处理100亿+条消息
- RocketMQ:用于订单、支付等核心交易链路,每天处理5000万+订单
- RabbitMQ:用于后台管理系统的异步任务(如报表生成、邮件发送),每天处理100万+任务
选择策略:
if (海量数据 && 实时计算):
选择 Kafka
elif (核心业务 && 需要事务):
选择 RocketMQ
elif (后台任务 && 需要灵活路由):
选择 RabbitMQ经验二:性能优化的关键点
基于生产环境踩过的坑,我总结了各中间件的性能优化要点:
Kafka优化清单:
- ✅ 合理设置分区数(建议:节点数 × 2 ~ 4)
- ✅ 启用消息压缩(推荐Snappy,压缩比与速度平衡)
- ✅ 调整batch.size和linger.ms(提高批量发送效率)
- ✅ 使用异步发送(吞吐提升3-5倍)
- ⚠️ 注意:分区数过多会增加元数据管理开销
RocketMQ优化清单:
- ✅ 根据可靠性需求选择刷盘策略(异步刷盘性能提升10倍)
- ✅ 合理配置消息堆积阈值(避免OOM)
- ✅ 使用顺序消息时,减少队列数量(避免锁竞争)
- ✅ 开启消息过滤(减少无效消费)
- ⚠️ 注意:同步刷盘+主从同步会大幅降低性能
RabbitMQ优化清单:
- ✅ 启用消息持久化(内存模式提升10倍,但会丢消息)
- ✅ 合理设置预取数量(prefetch_count)
- ✅ 避免使用镜像队列(性能下降50%)
- ✅ 使用lazy queue处理消息堆积
- ⚠️ 注意:发布确认机制会大幅降低吞吐
面试中的高分回答技巧
最后,回到开头的面试问题。我总结了一套"STAR"回答法:
STAR回答法
- S (Situation):描述业务场景
- T (Task):说明技术需求
- A (Action):阐述选型逻辑
- R (Result):展示选型效果
高分回答示例
问题1:为什么用RocketMQ而不用Kafka?
低分回答:
"因为RocketMQ功能更全面,支持事务消息。"
高分回答:
"我们的业务场景是电商订单处理系统(S),核心需求是保证订单创建与库存扣减的数据一致性,同时需要应对大促期间每秒数万条的订单流量(T)。
选型时我们对比了Kafka和RocketMQ:Kafka的吞吐能力更强,但它的事务只能保证多条消息发送的原子性,无法保证'本地订单入库+消息发送'的跨系统一致性。如果用Kafka,我们需要自己实现分布式事务补偿,开发成本高且容易出错。
而RocketMQ的事务消息基于两阶段提交+事务回查机制,能够严格保证订单入库与消息发送的最终一致性(A)。上线后,在大促期间峰值流量下,消息零丢失,且性能满足需求(单机5万TPS),节省了大量事务补偿的开发成本(R)。"
问题2:为什么用Kafka而不用RabbitMQ?
低分回答:
"因为Kafka性能更好,吞吐量高。"
高分回答:
"我们的业务场景是用户行为数据采集(S),需要收集App端用户的点击、浏览等行为,每天数据量达到50亿条,传输到Flink集群做实时分析(如实时推荐、实时画像)(T)。
选型时我们评估了RabbitMQ和Kafka:RabbitMQ的路由功能很强,但单机吞吐只有数千TPS,按我们的峰值流量(每秒10万条),需要部署50+台机器,成本过高。而且RabbitMQ与Flink的集成不如Kafka成熟。
Kafka的单机吞吐可达10万+TPS,且通过分区并行机制,6台机器就能支撑我们的流量(A)。同时,Kafka与Flink的集成非常成熟,延迟可控制在10ms以内,满足实时计算需求。上线后,系统稳定运行,机器成本相比RabbitMQ节省了80%(R)。"
总结
消息中间件的选型,本质上是业务需求与技术特性的精准匹配。没有"最好"的中间件,只有"最合适"的选择。
核心要点回顾:
-
Kafka = 大数据场景的首选
- 关键词:高吞吐、低延迟、大数据生态
- 适用:日志采集、实时计算、海量数据传输
-
RocketMQ = 互联网核心业务的保障
- 关键词:事务消息、高可靠、削峰填谷
- 适用:电商订单、金融支付、核心交易链路
-
RabbitMQ = 企业应用的灵活选择
- 关键词:灵活路由、功能丰富、易用性高
- 适用:企业工作流、异步任务、微服务通信
选型决策三步走:
- 明确核心需求(吞吐/事务/路由)
- 评估非功能约束(成本/团队/运维)
- POC验证+加权评分
面试技巧:
- 不要只说"X比Y好",而要说"我们的业务需要A特性,X有A特性,Y没有"
- 用STAR法结构化回答:场景-需求-行动-结果
- 体现对技术选型的深度思考,而非简单使用经验
最后,作为一名十年老兵,我想说:技术选型没有捷径,只有深入理解业务需求,才能做出正确决策。希望这篇文章能帮助大家建立系统化的选型思维,无论是应对面试,还是落地生产,都能游刃有余!
📝 作者信息
- CSDN:默语佬
- 专注于分布式系统、消息中间件、微服务架构
- 10年+大厂实战经验,欢迎交流讨论
原创不易,如果这篇文章对你有帮助,请给个三连:点赞👍、收藏⭐、关注🔔!
有问题欢迎评论区讨论,看到必回!下次面试遇到消息中间件选型问题,记得回来感谢我~ 😄