开篇
本文的目的在于实现一个用来爬取百度图片的爬虫程序,因该网站不需要登录,所以相对来说较为简单。下面的爬虫程序中我写了比较多的注释,以便于您的理解。
准备
请确保电脑上已经安装了与chrome浏览器版本匹配的chromeDriver,且电脑中已经安装了python3和pip库。在上面的要求均已达到的情况下,请按照下面的顺序下载包:
pip install selenium
pip install openpyxl
pip install pandas
代码实现
python
import os
import base64
import requests
import time
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 初始化WebDriver的方法
def setup_driver(chrome_driver_path, chrome_executable_path):
# 创建一个Options实例,用来配置Chrome浏览器的启动选项
options = Options()
# 启动浏览器时窗口最大化
options.add_argument("--start-maximized")
# 设置chrome浏览器的二进制位置
options.binary_location = chrome_executable_path
# 返回一个webdriver实例
return webdriver.Chrome(service=Service(chrome_driver_path), options=options)
# 创建保存图片的目录
def create_save_directory(dir):
if not os.path.exists(dir):
os.makedirs(dir)
# 下载图片
def download_img(url, filename):
if url.startswith('data:image'):
encoded = url.split(',', 1)[1]
data = base64.b64decode(encoded)
with open(filename, 'wb') as file:
file.write(data)
else:
response = requests.get(url)
if response.status_code == 200:
with open(filename, 'wb') as file:
file.write(response.content)
def main():
# 设置chromedriver路径
chrome_driver_path = r'F:\applications\chrome\chromedriver\chromedriver.exe'
# 设置chrome.exe的路径
chrome_executable_path = r'F:\applications\chrome\chrome\chrome.exe'
# 初始化WebDriver
driver = setup_driver(chrome_driver_path, chrome_executable_path)
try:
# 打开百度图片
driver.get("https://image.baidu.com/")
# 输入关键字并搜索
search_box = driver.find_element(By.NAME, 'word')
search_box.send_keys("狸花猫")
search_box.send_keys(Keys.RETURN)
# 等待页面加载
WebDriverWait(driver, 19).until(EC.presence_of_element_located((By.CSS_SELECTOR, 'img.main_img')))
# 创建保存图片的文件夹
save_directory = r'F:\codes\spider\baiduImgs'
create_save_directory(save_directory)
# 爬取图片
img_cnt = 0
while img_cnt < 100:
# 获取当前页面所有图片元素
imgs = driver.find_elements(By.CSS_SELECTOR, 'img.main_img')
for img in imgs:
if img_cnt >= 100:
break
try:
src_url = img.get_attribute('src')
if src_url:
filename = os.path.join(save_directory, f'{img_cnt + 1}.jpg')
download_img(src_url, filename)
img_cnt += 1
print(f'Downloaded {filename}')
except Exception as e:
print(f'Error downloading image: {e}')
# 下滑页面以加载更多图片
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3)
finally:
# 关闭浏览器
driver.quit()
if __name__ == "__main__":
main()效果图
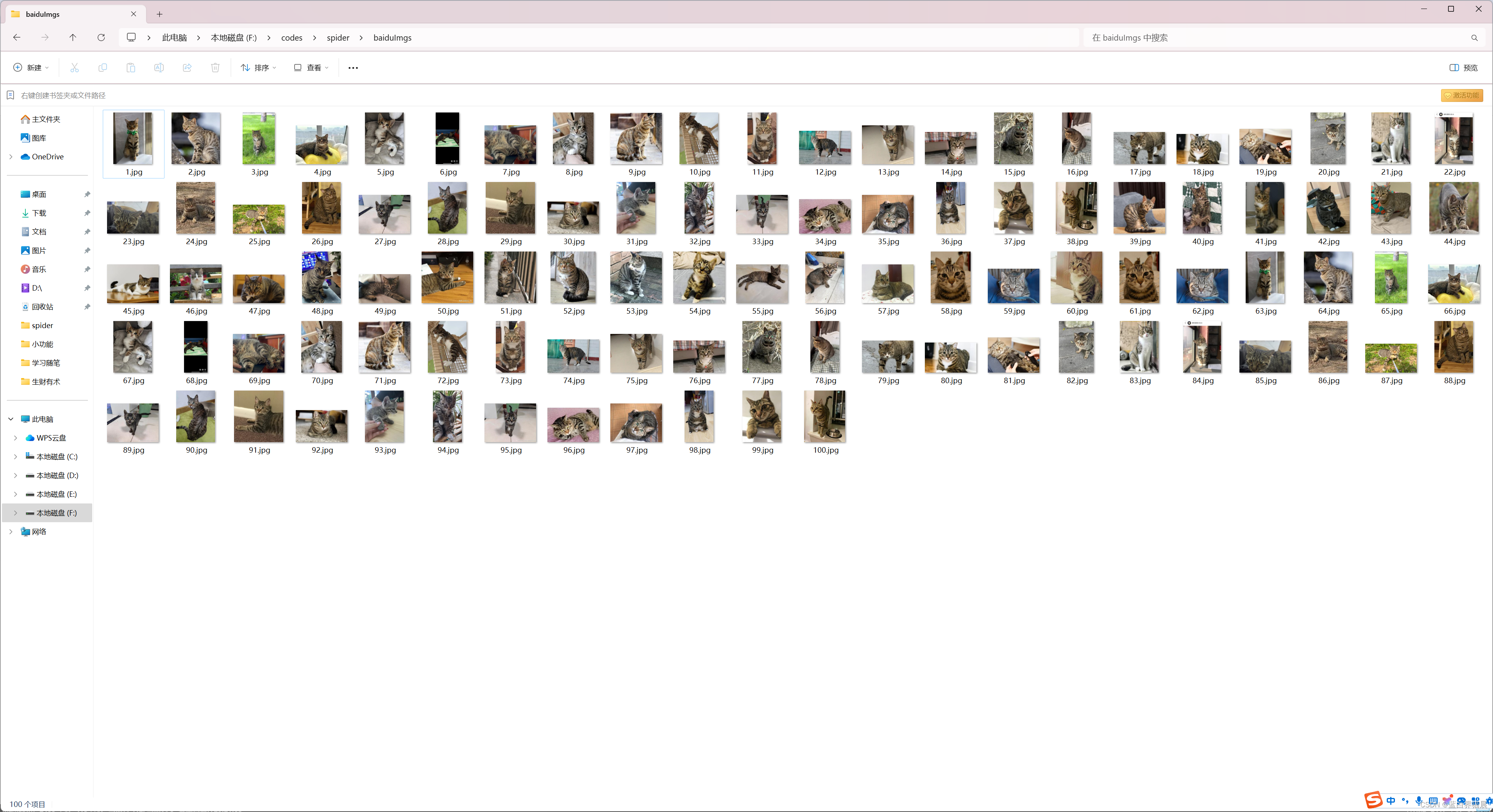
注
上面的代码即为百度图片爬虫的基本实现思路,希望能对您起到抛砖引玉的作用。