亚太(中文赛)分享资料(问题一代码+论文+思路)链接(已完成更新更新):
链接:https://pan.baidu.com/s/14REVRHSvZUTOrY9zDlOvwA
提取码:sxjm
洪水灾害的数据分析与预测
摘要
洪水是由暴雨、融雪、风暴潮等自然因素引起的江河湖泊水位迅速上涨的自然灾害。历史上,洪水频繁发生,早在中国先秦时期已有记载,欧洲、西亚和非洲也有古老的洪水记载。近年来,全球洪水频发,造成数十亿美元的经济损失。人口增长迅速,扩展耕地、围湖造田、乱砍滥伐等人类活动加剧了地表状态变化,改变了水文条件,增加了洪灾风险。长江上游的乱砍滥伐导致大量土壤流失和河床淤积,长江流域的洪灾威胁日益加剧。全球范围内,森林破坏成为洪灾发生和加剧的重要因素,许多地区因此变成不毛之地。随着人类活动的不断扩展和环境的恶化,对洪水防治和生态保护的需求日益迫切。
针对问题1,分析并可视化指标与洪水发生的关联。首先进行数据预处理,观察洪水指标数据的整体分布,检查缺失值与异常值,进行替换或删除操作。其次,计算各指标与洪水发生概率之间的相关系数,使用热力图(heatmap)可视化相关矩阵,突出高相关性和低相关性的指标。最后,采用决策树和因子分析降维寻找主要影响因素,并根据相关指标提出合理的防洪措施和预防建议。
针对问题2,使用 K-means算法对洪水发生概率进行聚类,划分高、中、低风险类别。识别高、中、低风险类别的关键指标,建立加权评分模型,计算每个洪水事件的风险评分,然后通过调整指标权重,分析模型对不同指标变化的敏感度,绘制敏感度分析图,识别对模型影响最大的指标。
针对问题3,基于问题 1 中的分析结果,选择关键指标作为特征变量,然后使用特征选择算法优化特征集,建立MLP神经网络进行模型训练与评估,在采用5个关键指标时,使用逐步回归与特征选择算法重新选择最重要5个指标,然后逐步调整模型参数,提高预测准确性。
针对问题4,基于问题3中的最终模型,对 test.csv 中的数据进行预测,并绘制预测洪水概率的直方图和折线图,观察数据分布。最后使用Shapiro-Wilk 检验分析结果分布是否符合正态分布。
3 模型假设和符号分析
3.1 模型假设
1.假设数据集中的样本是相互独立的,即每个样本的出现不会影响其他样本。
2.假设选择的特征(如侵蚀、政策因素、基础设施恶化、森林砍伐、气候变化、河流管理、流域、淤积、农业实践、季风强度)对洪水概率有显著影响。
3.假设经过处理和标准化后,数据集符合模型的要求,模型能够有效地进行训练和预测。
4.假设洪水概率分布符合一定的统计规律,可以通过概率图和统计分析验证分布假设。
5.假设数据集中的样本是相互独立的,即每个样本的出现不会影响其他样本
4 模型建立与求解
4.1 问题1模型建立与求解
4.1.1 数据预处理
针对洪水指标数据,首先要进行确保数据质量,检查数据的完整性与数据属性分布分析,处理缺失值和异常值。针对该数据,绘制缺失值数量的条形图,如图1所示,可以看到我们的训练数据是没有缺失值的。因此不需要对缺失值进行填补或删除操作。
接下来对属性进行箱型图可视化,如图2,可视化每个属性的箱线图(最小值、第一四分位数、中位数、第三四分位数、最大值)以及异常值)。)从图2可以看到,大多数属性的中位数(箱体中的线)较低,表明数据倾向于较小的值,而一些属性的箱体较宽,例如河流管理和森林砍伐,表明数据在这些属性上的分散度较大。部分属性的箱线图显示出对称性,例如季风强度,意味着数据分布相对平衡。其他属性,如地形排水和侵蚀,显示出不对称的分布,表明数据偏斜。图3为每个属性的分布范围情况。

图3
图3的范围可以看到,仅有少数几个值的最大范围取值到了18,我们推测该点是数据集的异常值。图4统计了百万数据中每个指标时18的数量,可以看到,我们的属性值的范围大都处于0-17之间,仅有几个18的值,由于保留两位小数,他们的占比全部约等于0,因此我们当成异常值删除掉。同理,我们发现指标>10的数据占比非常小,从图6每个属性的直方图和核密度估计(KDE)图也能够看出,因此我们将特征值属性全都大于10的属性进行删除操作。得到了图5的数据结构。


图6是第一个图是每个属性的直方图和核密度估计(KDE)图,展示了各个属性的分布情况。大多数属性的分布非常集中,主要集中在特定值上。例如,季风强度、地形排水等属性的值大部分集中在0到5之间。某些属性具有较大的离散性,例如河流管理和森林砍伐,这些属性在较大范围内有较多数据点。很多属性显示出明显的正偏态分布,意味着大多数数据点集中在较低的值上,而少数数据点有较大的值。这在侵蚀、无效防灾、气候变化等属性中尤其明显。一些属性显示了多峰分布,例如河流管理,这可能表示数据分成了几个子群,每个子群具有不同的特征。处理并了解好数据集之后,接下来进行指标的相关性分析。
4.1.2 相关性分析
(1)Spearman相关性分析
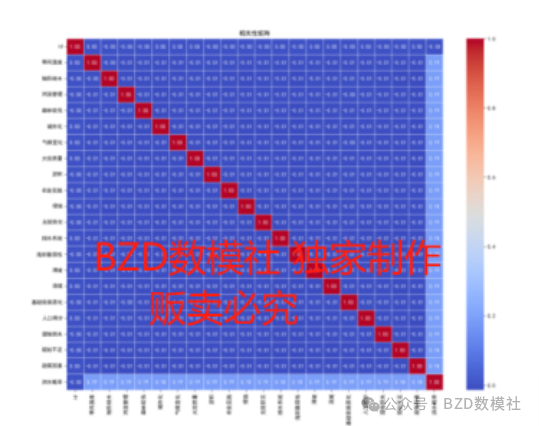
为了判断并分析上述20个指标中,哪些个指标对洪水的发生有着密切的关联,哪些指标对洪水的发生相关性不大,我们接下来进行相关性分析。需要计算各指标与洪水发生概率之间的相关系数。从图6的每个属性的直方图和核密度估计(KDE)图可以看出,我们的指标数据并不服从正态分布,因此采用Spearman相关系数进行相关性分析并判断。图7是Spearman相关系数的矩阵图。相关矩阵显示了每个特征与其他特征之间的线性关系,其值范围从-1到1。大部分相关系数接近于0,说明大多数特征之间没有明显的线性关系。而且大多数特征之间的相关性较低(接近0),这意味着这些特征是相对独立的,可以作为模型的独立变量使用。
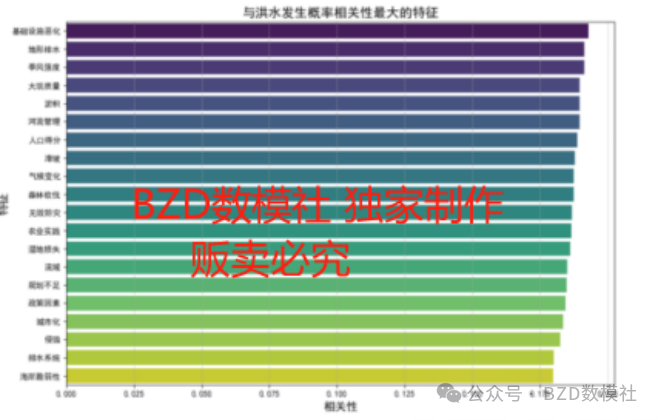
(2)因子分析
因子分析是一种统计技术,用于揭示观察变量之间的潜在结构或模式。它主要用于降低数据的维度,从而更好地理解数据集中隐藏的复杂性和关联性。它提供了一种系统性的方法来理解和简化数据背后的结构,使研究人员能够更深入地探索变量之间的关系,进而作出更有说服力的分析和推断。它主要通过旋转因子来使因子的解释更为清晰和可解释。因子载荷矩阵显示了每个特征在不同因子上的载荷量,用于解释特征在各因子上的权重或重要性。

该问题采用因子分析来判断哪些指标与洪水的发生有着密切的关联、哪些指标与洪水发生的相关性不大。图9为因子载荷矩阵,如图9所示,因子1主要负载在特征"无效防汛设施"和"洪水概率"上,表明这两个特征在因子1上具有较高的权重。因子2主要负载在"排水系统"和"森林砍伐"上,说明这些特征在因子2上具有较高的权重。因子3、因子4和因子5也各自负载了一些特征,具体特征见图9示。
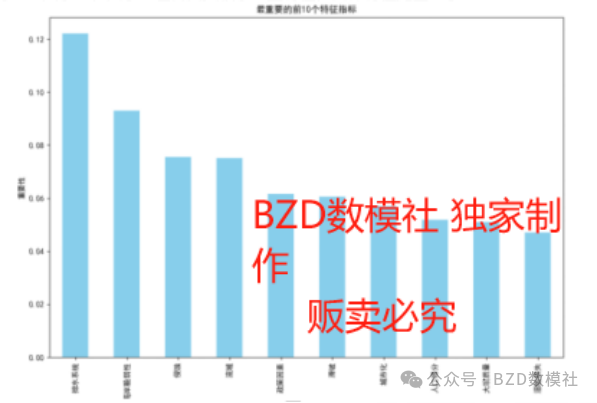
图10展现了影响洪水的10个最重要的指标,同理,剩余的10个指标则被判定为与洪水发生相关性不大的指标。
(2)决策树
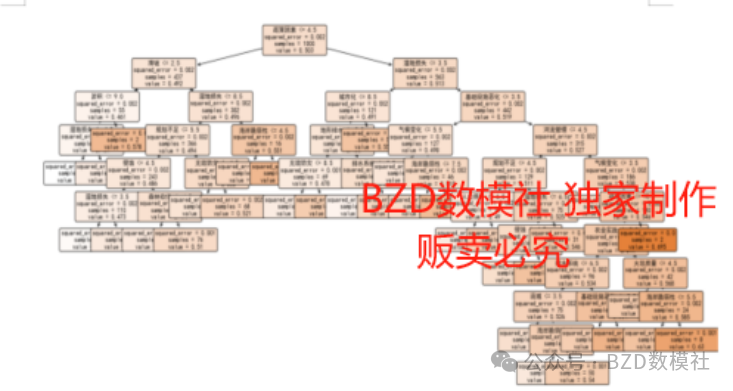
决策树是一个树状分类结构模型,每个非叶子节点表示一个特征属性,每个分支边代表着这个特征属性在某个值域上的输出,每个叶子节点存放一个类别。决策过程则是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。可通过"剪枝"来一定程度避免因决策分支过多,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致的过拟合。
该问题1采用决策树来判断哪些指标与洪水的发生有着密切的关联、哪些指标与洪水发生的相关性不大。在决策树之后,加入"剪枝"来让决策树学习算法对付"过拟合"。通过"剪枝"来一定程度避免因决策分支过多,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致的过拟合。本文采用的是后剪枝,它是在决策树构建完成后,通过剪掉部分节点或子树来减少过拟合。先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。图10代表了我们剪枝后的结果,在对其特征指标的重要性进行分析,如图11所以。可以看出,河流管理、湿地损失、无效防灾、基础设施恶化、大坝质量、人口得分、气候变化、政策因素、地形排水、森林砍伐这十个指标与洪水的发生有着密切的关联,剩余指标与与洪水发生的相关性不大,相关性最小的是农业实践。
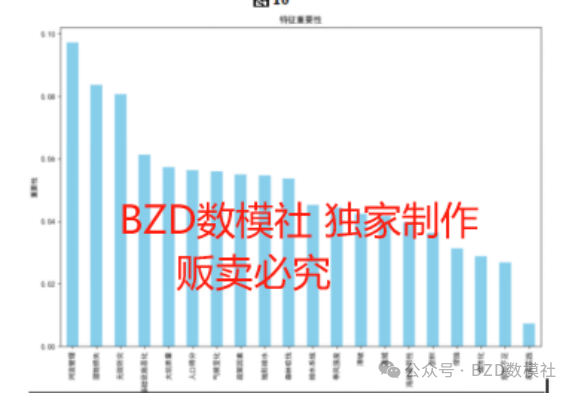
时,因子分析的结果可能不可靠。而决策树模型能够处理各种类型的数据(如连续型、分类型)且对数据分布没有过多假设,因此特征重要性指标对数据的适应性更强。基于上述原因,决策树的特征重要性在很多实际应用中比因子分析更受青睐,尤其是在构建和解释预测模型时。所以将决策树其作为我们判断特征重要与否的方法。