MVCC是什么
MySQL的MVCC机制,全称为多版本并发控制(Multi-VersionConcurrency Control),是一种提高数据库并发性能的技术。MVCC的主要目的是在保证数据一致性的同时,提高数据库的并发性能。
它通过为每个读操作创建数据的快照来实现这一点,这样即使在数据被其他事务修改的同时,读操作也能够看到一致的数据视图。这种机制避免了同一个数据在不同事务之间的竞争,从而提高了系统的并发性能。
MVCC在MySQL中的实现主要是为了解决读写冲突问题,使得即使在有读写冲突的情况下,也能做到不加锁,非阻塞并发读。MVCC通过维护数据的不同版本来实现这一点,每个事务都可以看到适合自己版本的数据,而不会被其他事务的修改所影响。
MVCC适用范围
在MySQL中**,MVCC只在读取已提交(Read Committed)和可重复读(Repeatable Read)两个事务级别下有效。** 底层通过Undolog 日志中的版本链 和ReadView一致性视图来实现的。MVCC就是在多个事务同时存在时,SELECT语句找寻到具体是版本链上的哪个版本,然后在找到的版本上返回其中所记录的数据的过程。
当前读:总是读取当前最新的数据。
像select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)这些操作都是一种当前读
快照读 :像不加锁的select操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别 ,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本
update delete一定是当前读
表隐藏字段
-
DB_ROW_ID:隐藏主键,MySQL的B+树索引特性要求每个表必须要有一个主键。如果没有设置的话,会自动寻找第一个不包含NULL的唯一索引列作为主键。如果还是找不到,就会在这个DB_ROW_ID上自动生成一个唯一值,以此来当作主键(该列和MVCC的关系不大);
-
DB_TRX_ID:最后一次事务ID,记录的是当前事务在做INSERT或UPDATE语句操作时的事务ID(DELETE语句被当做是UPDATE语句的特殊情况,后面会进行说明);
-
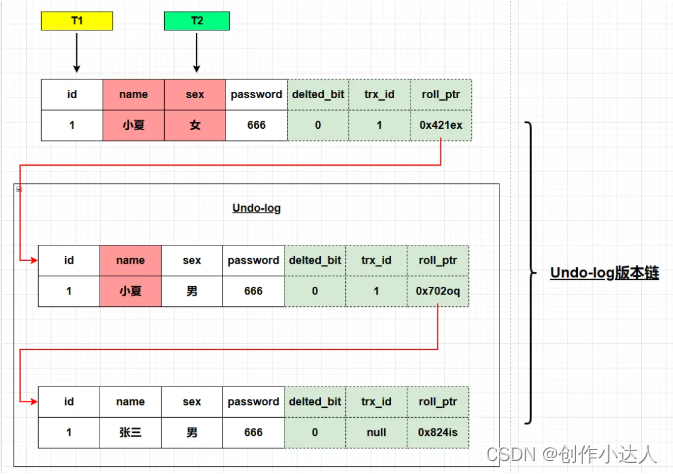
DB_ROLL_PTR :回滚指针,通过它可以将不同的版本串联起来,形成版本链。相当于链表的next指针。这个指针实际就是指向undolog的快照对应版本的数据。
MVCC的工作流程
-
事务开始时,获取一个唯一的事务ID。
-
当进行读取操作时,数据库会创建一个Read View,其中包含了当前系统中活跃事务的信息。
-
读取数据时,数据库会根据Read View中的信息来确定哪个版本的数据是可见的。
-
如果当前版本的数据不可见,数据库会通过undo日志找到合适的历史版本。
MVCC与锁机制的比较
MVCC和锁机制都是并发控制的手段,但它们在不同的场景下有不同的应用。锁机制通过在数据上加锁来保证事务的隔离性,是一种悲观锁的实现。而MVCC通过维护数据的多个版本来实现非锁定读取,是一种乐观锁的实现。
无锁架构:COW思想
Copy-On-Write(COW,写时复制)是一种常见的并发编程思想。
Copy-On-Write基本思想是,当多个线程需要对共享数据进行修改时,不直接在原始数据上进行操作,而是先将原始数据复制一份(即写时复制),然后在副本上进行Write。
Copy-On-Write 通过操作写操作副本,引入局部无锁架构,解决并且处理之间的数据冲突,提高了并发性能。
Copy-On-Write的实现步骤如下:
-
读取数据:多个线程同时读取共享数据时,它们可以直接访问原始数据,而不需要复制。因为读取操作不会修改数据,所以可以安全地共享原始数据。
-
写入数据:当某个线程需要修改共享数据时,首先会将原始数据进行复制(即写时复制),然后在副本上进行修改。这样做的好处是,其他线程仍然可以继续读取原始数据,不受写入线程的影响。
-
更新引用:写入线程完成修改后,会更新共享数据的引用,使得其他线程后续访问时可以获取到最新的数据副本。
Copy-On-Write的优点包括:
-
线程安全:通过复制数据副本并在副本上进行修改,避免了多线程并发修改原始数据时的数据冲突问题,从而提高了线程安全性。
-
减少锁竞争:由于读取操作不需要加锁,所以可以减少锁竞争,提高了并发性能。
-
节省内存:只有在有写入操作时才会进行数据复制,而读取操作可以共享原始数据,因此可以节省内存空间。
然而,Copy-On-Write也有一些缺点,主要是由于数据复制和更新引用所带来的额外开销,可能会导致内存和性能方面的消耗增加。因此,适用场景需要根据具体情况进行评估和选择。
COW思想写操作之间是要互斥的,并且每次写操作都会有一次copy,所以只适合读大于写的情况。所以,COW思想 专门用于优化读的次数远大于写次数的场景。比如,Java的 并发容器CopyOnWriteArrayList。
Java中的CopyOnWriteArrayList
CopyOnWriteArrayList 是jdk1.5以后并发包中提供的一种并发容器,写操作通过创建底层数组的新副本来实现,是一种读写分离的并发策略,我们也成为"写时复制容器"。
public boolean add(E e) {
//加锁,对写操作保证线程安全
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//拷贝原容器,长度为原容器+1
Object[] newElements = Arrays.copyOf(elements, len + 1);
//在新副本执行添加操作
newElements[len] = e;
//底层数组指向新的数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}CopyOnWriteArrayList底层实现添加的原理是先copy出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。
MVCC核心ReadView
先来思考如下的问题:
如果T1事务要查询id=1的一条行数据,此时这条行数据正在被T2事务修改,那也就代表着这条数据可能存在多个旧版本数据,T1事务在查询时,应该读这条数据的哪个版本呢?
此时就需要用到ReadView,用它来做多版本的并发控制,根据查询的时机,来选择一个当前事务可见的旧版本数据读取。
什么是ReadView呢?
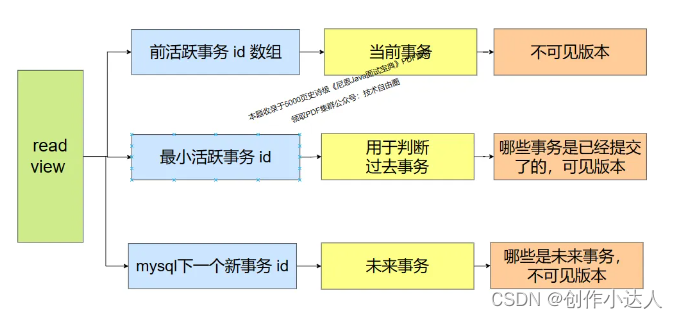
当一个事务在尝试读取一条数据时,MVCC基于当前MySQL的运行状态生成的快照,也被称之为读视图,即ReadView,在这个快照中记录着当前所有活跃事务的ID(活跃事务是指还在执行的事务,即未结束(提交/回滚)的事务)。
ReadView是事务在进行快照读的时候生成的记录快照, 可以帮助我们解决可见性问题的。
ReadView的核心属性
当一个事务启动后,首次执行select操作时,MVCC就会生成一个数据库当前的ReadView,
通常而言,一个事务与一个ReadView属于一对一的关系(不同隔离级别下也会存在细微差异),ReadView一般包含4个核心属性:

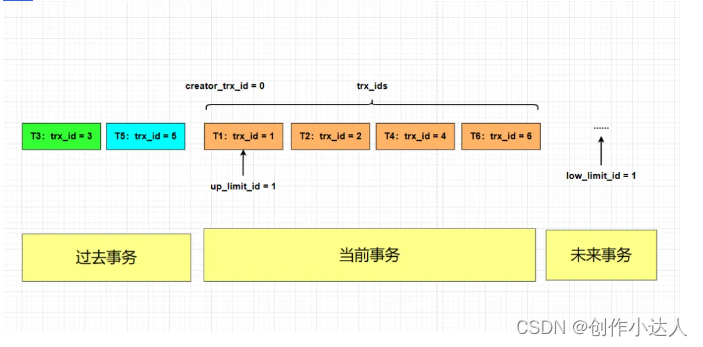
我们假设目前数据库中共有T1~T6这6个事务,T1、T2、T4、T6还在执行,T3已经回滚,T5已经提交,
此时当有一条查询语句执行时,就会利用MVCC机制生成一个ReadView,由于在MySQL中单纯由一条select语句组成的事务并不会分配事务ID,因此默认为0,所以目前这个ReadView的信息如下:
ReadView的读取规则
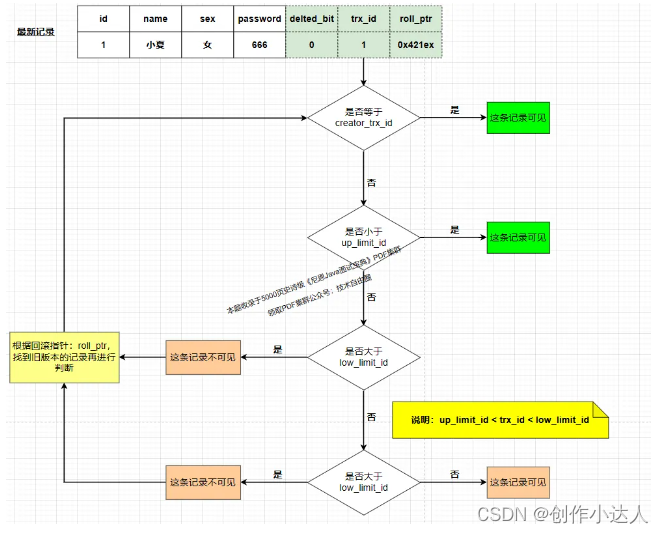
访问某条记录的时候如何判断该记录是否可见,具体规则如下:
-
如果被访问版本的
事务ID = creator_trx_id,那么表示当前事务访问的是自己修改过的记录,那么该版本对当前事务可见; -
如果被访问版本的
事务ID < up_limit_id,那么表示生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。 -
如果被访问版本的
事务ID > low_limit_id值,那么表示生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。 -
如果被访问版本的
事务ID在 up_limit_id和m_low_limit_id之间,那就需要判断一下版本的事务ID是不是在 trx_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问; -
如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
上面这种图,网上有上万篇文章, 都是抄来抄去, 没有一篇文章做了总结和简化。
关于这个对比规则,由于逻辑复杂,导致尽管大家看了那些文章,甚至看了很多视频,还是不能理解透彻, 迷迷糊糊的,面试的时候 说不清楚,也很容易忘了。
尼恩团队看不下去,用咱们的雄厚技术实力(洪荒之力), 给大家来总结和简化。
具体如下: