1 线性结构和非线性结构的理解
1.1 线性结构
线性结构是什么?
数据结构中线性结构指的是数据元素之间存在着"一对一"的线性关系的数据结构。线性结构是一个有序数据元素的集合。
线性结构特点:
线性结构有唯一的首元素(第一个元素)
线性结构有唯一的尾元素(最后一个元素)
除首元素外,所有的元素都有唯一的"前驱"
除尾元素外,所有的元素都有唯一的"后继"
数据元素之间存在"一对一"的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。
如数组(a1,a2,a3,...,an),a1为第一个元素,an为最后一个元素,此集合即为一个线性结构的集合。
常用的线性结构有线性表,栈,队列,双队列,循环队列,一维数组,串。
线性表中包括顺序表、链表等,其中,栈和队列只是属于逻辑上的概念,实际中不存在,仅仅是一种思想,一种理念;线性表则是在内存中数据的一种组织、存储的方式。
1.2 非线性结构
非线性结构是什么?
非线性结构中各个数据元素不再保持在一个线性序列中,数据元素之间是一对多,或者是多对一的关系。根据关系的不同,可分为层次结构(树)和群结构(图)。
常见的非线性结构有二维数组,多维数组,广义表,树(二叉树等),图。(其中多维数组是由多个一维数组组成的, 可用矩阵来表示,他们都是两个或多个下标值对应一个元素,是多对一的关系,因此是非线性结构。)
相对应于线性结构,非线性结构的逻辑特征是一个结点元素可能对应多个直接前驱和多个后继。
2 数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
注意点:①.数组是一种线性表;②.连续的内存空间和相同类型的数据
由于第二个性质,数组支持 "随机访问",根据下表随机访问的时间复杂度为O(1);但与此同时却使得在数组中删除,插入数据需要大量的数据搬移工作,时间复杂度O(n)。
暂且可以把「数组」分为两大类,一类是「静态数组」,一类是「动态数组」。
2.1 静态数组
静态数组在创建的时候就要确定数组的元素类型和元素数量。只有在 C++、Java、Golang 这类语言中才提供了创建静态数组的方式,类似 Python、JavaScript 这类语言并没有提供静态数组的定义方式。
静态数组的用法比较原始,实际软件开发中很少用到,写算法题也没必要用,我们一般直接用动态数组。但为了理解原理,在这里还是要讲解一下。
定义静态数组并访问
c
// 定义一个大小为 10 的静态数组
int arr[10];
// 用 memset 函数把数组的值初始化为 0
memset(arr, 0, sizeof(arr));
// 使用索引赋值
arr[0] = 1;
arr[1] = 2;
// 使用索引取值
int a = arr[0];拿 C++ 来举例吧,int arr10 这段代码到底做了什么事情呢?主要有这么几件事:
1、在内存中开辟了一段连续的内存空间,大小是 10 * sizeof(int) 字节。一个 int 在计算机内存中占 4 字节,也就是总共 40 字节。
2、定义了一个名为 arr 的数组指针,指向这段内存空间的首地址。
那么 arr1 = 2 这段代码又做了什么事情呢?主要有这么几件事:
1、计算 arr 的首地址加上 1 * sizeof(int) 字节(4 字节)的偏移量,找到了内存空间中的第二个元素的地址。
2、从这个地址开始的 4 个字节的内存空间中写入了整数 2。
数据结构无非就是增删改查,上面已经实现了数组改和查,下面看看数组的增删功能。
低效的插入和删除
插入操作
假如数组的长度为n,我们需要将一个数据插入到数组的第k个位置,我们需要将第k~n位元素都顺序地往后挪动一位。
最好情况时间复杂度为O(1),此时对应着在数组末尾插入元素;
最坏情况时间复杂度为O(n),此时对应着在数组开头插入元素;
平均情况时间复杂度为O(n),因为我们在每个位置插入元素的概率相同,故(1+2+3+......+n)/n=O(n);
但是根据我们的需求,有一个特定的场景。如果数组的数据是有序的,那么我们在插入时就一定要那么做;但是如果数组中存储的数据并没有任何规律,数组只是被当成一个存储数据的集合,我们可以有一个取巧的方法:
直接将第k个元素搬移到数组元素的最后,把新的数据直接放入第k个位置即可(是不是很简单啊),这时插入元素的复杂度为O(1)。
删除操作
和插入操作一样,为了保证内存的连续性,删除操作也需要搬移数据。
最好情况时间复杂度为O(1),此时对应着删除数组末尾的元素;
最坏情况时间复杂度为O(n),此时对应着删除数组开头的元素;
平均情况时间复杂度为O(n),因为我们删除每个位置的元素的概率相同,故(1+2+3+......+n)/n=O(n);
当然,在某些特殊情况下,我们并不一定非要进行复杂的删除操作。我们只是将需要删除的数据记录,并且假装它以经被删除了。直到数组没有更多空间存储数据时,我们再触发一次真正的删除操作即可。
这其实就和生活中的垃圾桶类似,垃圾并没有消失,只是被"标记"成了垃圾,而直到垃圾桶塞满时,才会清理垃圾桶。2.2 动态数组
动态数组并不能解决静态数组在中间增删元素效率差的问题。数组随机访问的超能力源于数组连续的内存空间,而连续的内存空间就不可避免地面对数据搬移和扩缩容的问题。
动态数组底层还是静态数组,只是自动帮我们进行数组空间的扩缩容,并把增删查改操作进行了封装,让我们使用起来更方便而已。
下面给出cpp中动态数组的使用示例
// 创建动态数组
// 不用显式指定数组大小,它会根据实际存储的元素数量自动扩缩容
vector<int> arr;
for (int i = 0; i < 10; i++) {
// 在末尾追加元素,时间复杂度 O(1)
arr.push_back(i);
}
// 在中间插入元素,时间复杂度 O(N)
// 在索引 2 的位置插入元素 666
arr.insert(arr.begin() + 2, 666);
// 在头部插入元素,时间复杂度 O(N)
arr.insert(arr.begin(), -1);
// 删除末尾元素,时间复杂度 O(1)
arr.pop_back();
// 删除中间元素,时间复杂度 O(N)
// 删除索引 2 的元素
arr.erase(arr.begin() + 2);
// 根据索引查询元素,时间复杂度 O(1)
int a = arr[0];
// 根据索引修改元素,时间复杂度 O(1)
arr[0] = 100;
// 根据元素值查找索引,时间复杂度 O(N)
int index = find(arr.begin(), arr.end(), 666) - arr.begin();手写动态数组
c
3 链表
数组作为一个顺序储存方式数据结构为我们的程序设计带来了大量的便利,几乎任何的高级程序设计,算法设计都离不开数组的灵活使用,但是,数组最大的缺点就是我们的插入和删除时需要移动大量的元素,显然这需要消耗大量的时间。
一条链表并不需要一整块连续的内存空间存储元素。链表的元素可以分散在内存空间的天涯海角,通过每个节点上的 next, prev 指针,将零散的内存块串联起来形成一个链式结构。
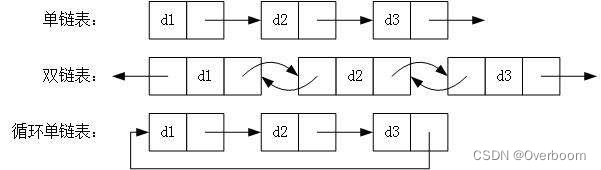
3.1 单链表
单链表数据结构定义
链表是由一个个结点串联而成的,而每个结点分为两块区域,一块是数据域,相当于数组中存储的那个数据;另一块是指针域,这里存放的是指向下一个结点的地址。

故,对于一个单链表的结点定义,可以代码描述成:
c
//定义结点类型
typedef struct Node {
int data; //数据类型,你可以把int型的data换成任意数据类型,包括结构体struct等复合类型
struct Node *next; //单链表的指针域
} Node,*LinkedList;
//Node表示结点的类型,LinkedList表示指向Node结点类型的指针类型单链表节点创建
LinkedList LinkedListInit() {
Node *L;
L = (Node *)malloc(sizeof(Node)); //申请结点空间
if(L==NULL){ //判断申请空间是否失败
exit(0); //如果失败则退出程序
}
L->next = NULL; //将next设置为NULL,初始长度为0的单链表
return L;
}创建单链表(头插法)
在初始化之后,就可以着手开始创建单链表了,单链表的创建分为头插入法和尾插入法两种,两者并无本质上的不同,都是利用指针指向下一个结点元素的方式进行逐个创建,只不过使用头插入法最终得到的结果是逆序的。
如图,为头插法的创建过程:
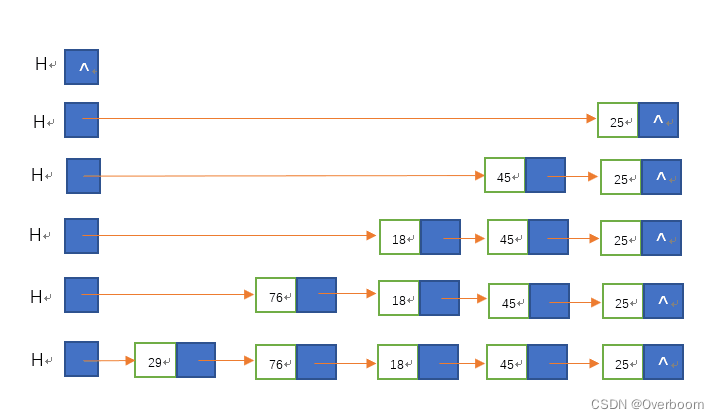
该方法从一个空表开始,生成新结点,并将读取到的数据存放到新结点的数据域中,然后将新结点插入到当前链表的表头,即头结点之后。
创建单链表(尾插法)
如图,为尾插入法的创建过程。
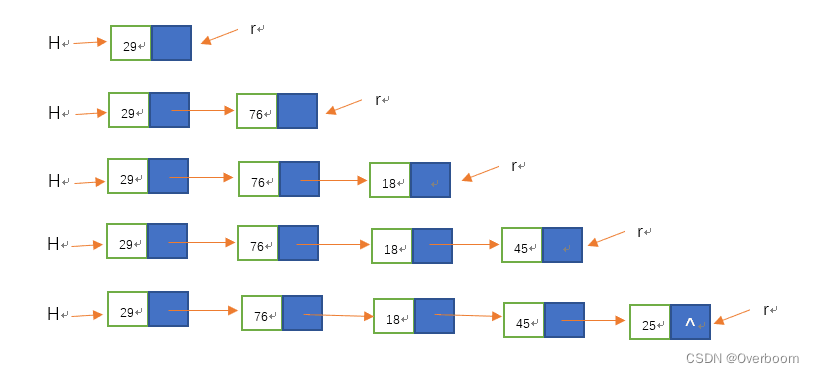
头插法建立单链表的算法虽然简单,但生成的链表中结点的次序和输入数据的顺序不一致。若希望两者次序一致,可采用尾插法。
该方法是将新结点逐个插入到当前链表的表尾上,为此必须增加一个尾指针 r, 使其始终指向当前链表的尾结点,否则就无法正确的表达链表。
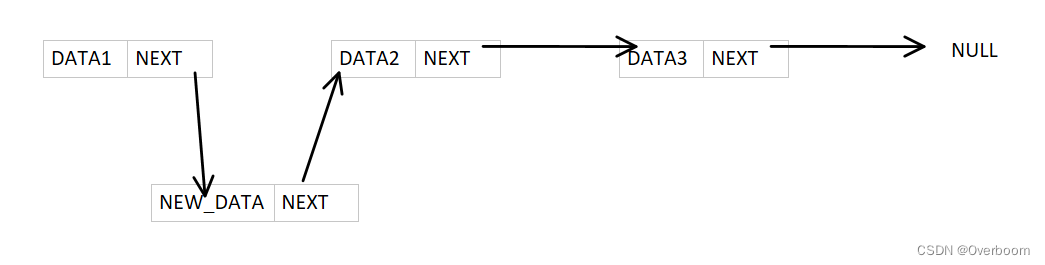
链表插入操作
链表的增加结点操作主要分为查找到第i个位置,将该位置的next指针修改为指向我们新插入的结点,而新插入的结点next指针指向我们i+1个位置的结点。其操作方式可以设置一个前驱结点,利用循环找到第i个位置,再进行插入。
如图,在DATA1和DATA2数据结点之中插入一个NEW_DATA数据结点:
从原来的链表状态
 到新的链表状态:
到新的链表状态:
 代码实现如下:
代码实现如下:
c
//单链表的插入,在链表的第i个位置插入x的元素
LinkedList LinkedListInsert(LinkedList L,int i,int x) {
Node *pre; //pre为前驱结点
pre = L;
int tempi = 0;
for (tempi = 1; tempi < i; tempi++) {
pre = pre->next; //查找第i个位置的前驱结点
}
Node *p; //插入的结点为p
p = (Node *)malloc(sizeof(Node));
p->data = x;
p->next = pre->next;
pre->next = p;
return L;
}链表删除操作
删除元素要建立一个前驱结点和一个当前结点,当找到了我们需要删除的数据时,直接使用前驱结点跳过要删除的结点指向要删除结点的后一个结点,再将原有的结点通过free函数释放掉。
参考如图
 以下是代码实现:
以下是代码实现:
c
//单链表的删除,在链表中删除值为x的元素
LinkedList LinkedListDelete(LinkedList L,int x) {
Node *p,*pre; //pre为前驱结点,p为查找的结点。
p = L->next;
while(p->data != x) { //查找值为x的元素
pre = p;
p = p->next;
}
pre->next = p->next; //删除操作,将其前驱next指向其后继。
free(p);
return L;
}链表增删改查基本实现
c
#include <stdio.h>
#include <stdlib.h>
//创建一个结构体表示链表中的节点
typedef struct node
{
struct node *next;//指针域,注意这里类型是node,而不是T_NODE
int var;//数据域
}T_NODE;
//初始化一个链表,并将第一个值传入(有的实现头结点不插入数据,自己选择)
T_NODE *list_init(int var)
{
//创建根节点
T_NODE *head = (T_NODE *)malloc(sizeof(T_NODE));
if(NULL == head) {
printf("错误。申请内存失败,创建节点失败\n");
exit(1);
}
//初始化头节点
head->var = var;
head->next = NULL;
return head;
}
void print_list(T_NODE *list_head)
{
int i = 0;
if(NULL == list_head) {
printf("链表为空\n");
}
//指针域为NULL,表示这是最后一个节点,但是该节点是有效节点,所以这里用do while
do
{
printf("链表节点%d的值是:%d\n",++i,list_head->var);
list_head = list_head->next;
}while(list_head);
}
//计算链表的长度
int list_lenth(T_NODE *list_head)
{
int lenth = 0;
while(list_head) {
lenth++;
list_head = list_head->next;
}
return lenth;
}
//单个数据插入,尾插法
int list_tail_insert(T_NODE *list_head,int var)
{
T_NODE *list_new_node = (T_NODE *)malloc(sizeof(T_NODE));
if(NULL == list_new_node) {
printf("error,malloc failed\n");
return -1;
}
while(list_head->next) {
list_head = list_head->next;
}
list_new_node->var = var;//将值给该节点,并将上一个节点的指针域指向该节点地址
list_new_node->next = NULL;
list_head->next = list_new_node;
return 0;
}
//单个数据插入,头插法
T_NODE *list_head_insert(T_NODE *list_head,int var)
{
T_NODE *list_new_node = (T_NODE *)malloc(sizeof(T_NODE));
if(NULL == list_new_node) {
printf("error,malloc failed\n");
return NULL;
}
list_new_node->next = list_head;
list_new_node->var = var;
list_head = list_new_node;
return list_head;
}
//指定位置插入,可以插入头,尾,或者头尾之间任意位置
T_NODE *list_specific_insert(T_NODE *list_head,int location,int var)
{
int len = list_lenth(list_head);
int i = 1;//为保持人的习惯,第1个位置表示1而不是0
T_NODE *node_last = NULL;
T_NODE *node_temp = list_head;
//位置是1,插在链表的开头,用头插法
if(1 == location) {
list_head = list_head_insert(list_head, var);
return list_head;
}
//位置比链表长度大1,插在链表尾部
if((len + 1 ) == location) {
list_tail_insert(list_head, var);
return list_head;
}
//指定的位置最大是链表长度加1,location=1表示头,location=len+1,表示插在尾部
if((location > (len + 1)) ||(location < 1)) {
printf("插入失败。请检查链表长度,指定插入位置不对\n");
return list_head;
}
//这里采用头插法插入,也可以采用尾插法
while(i < location) {
node_last = node_temp;
node_temp = node_temp->next;
i++;
}
node_temp = list_head_insert(node_temp, var);
node_last->next = node_temp;
return list_head;
}
//从链表头开始删除整个链表
T_NODE *del_list(T_NODE *list_head)
{
T_NODE *node_temp = (T_NODE *)malloc(sizeof(T_NODE));
if(NULL == node_temp) {
printf("error.%s:%d. malloc error\n",__FUNCTION__,__LINE__);
}
while(list_head->next) {
node_temp = list_head->next;
free(list_head);
list_head = node_temp;
}
free(list_head);
printf("整个删除链表成功\n");
return NULL;
}
//修改链表中的指定元素值
void change_specific_var(T_NODE *list_head,int old_var,int new_var)
{
while (NULL != list_head) {
if(old_var == list_head->var) {
list_head->var = new_var;
printf("将%d修改为%d成功\n",old_var,new_var);
return;
}
list_head = list_head->next;
}
printf("将%d修改为%d失败\n",old_var,new_var);
}
//删除链表中的指定元素值
T_NODE * del_specific_var(T_NODE *list_head,int del_var)
{
T_NODE *list_temp = NULL;
T_NODE *list_head_temp = list_head;
while(NULL != list_head) {
if(del_var == list_head->var) {
//如果删除的是头结点
if(NULL == list_temp) {
list_temp = list_head;
list_head = list_head->next;
free(list_temp);
return list_head;
} else { //删除的不是头结点
list_temp->next = list_head->next;
free(list_head);
return list_head_temp;
}
}
list_temp = list_head;
list_head = list_head->next;
}
return list_head_temp;
}
//测试头插法
T_NODE *test_head_insert(T_NODE *list_head,int arr[])
{
int i;
//头插法,头结点已经初始化,从第二个开始加入链表
for(i = 1; i < 6; i++) {
list_head = list_head_insert(list_head, arr[i]);
}
printf("测试头插法,链表的长度是%d\n",list_lenth(list_head));
print_list(list_head);
return list_head;
}
//测试尾插法
void test_tail_insert(T_NODE *list_head,int arr[])
{
int i;
for(i = 1; i < 6; i++) {
list_tail_insert(list_head, arr[i]);
}
printf("\n测试尾插法,链表的长度是%d\n",list_lenth(list_head));
print_list(list_head);
}
//测试指定位置插入
T_NODE *test_specific_insert(T_NODE *list_head)
{
int len = 0;
//测试头尾之间插入节点
printf("\n开始测试指定位置插入-->-->-->-->-->-->\n");
printf("链表第4个节点插入数据4。。。\n");
list_head = list_specific_insert(list_head, 4, 4);
printf("操作完成后链表长度%d\n",list_lenth(list_head));
print_list(list_head);
printf("\n链表第1个节点插入数据100。。。\n");
list_head = list_specific_insert(list_head, 1, 100 );
printf("操作完成后链表长度%d\n",list_lenth(list_head));
print_list(list_head);
len = list_lenth(list_head);
printf("\n链表第%d个节点插入数据%d。。。\n",len + 1,len + 1);
list_head = list_specific_insert(list_head, (list_lenth(list_head) + 1), (list_lenth(list_head) + 1));
printf("操作完成后链表长度%d\n",list_lenth(list_head));
print_list(list_head);
printf("\n链表第0个节点插入数据200。。。\n");
list_head = list_specific_insert(list_head, 0, 200);
printf("操作完成后链表长度%d\n",list_lenth(list_head));
print_list(list_head);
printf("\n链表第20个节点插入数据20。。。\n");
list_head = list_specific_insert(list_head, 20, 20);
printf("操作完成后链表长度%d\n",list_lenth(list_head));
print_list(list_head);
printf("-->-->-->-->-->-->结束测试指定位置插入\n");
return list_head;
}
void test_change_specific_var(T_NODE *list_head)
{
printf("\n开始测试修改指定值-->-->-->-->-->-->\n");
printf("将4替换成5。。。\n");
change_specific_var(list_head, 4, 5);
print_list(list_head);
printf("\n将666替换成888。。。\n");
change_specific_var(list_head, 666, 888);
print_list(list_head);
printf("\n将100替换成888。。。\n");
change_specific_var(list_head, 100, 888);
print_list(list_head);
printf("-->-->-->-->-->-->结束测试修改指定值\n");
}
T_NODE* test_del_specific_var(T_NODE *list_head)
{
printf("\n开始测试删除指定值-->-->-->-->-->-->\n");
printf("将5删除。。。\n");
list_head = del_specific_var(list_head,5);
print_list(list_head);
printf("\n将888删除。。。\n");
list_head = del_specific_var(list_head, 888);
print_list(list_head);
printf("\n将9删除。。。\n");
list_head = del_specific_var(list_head,9);
print_list(list_head);
printf("-->-->-->-->-->-->结束测试删除指定值\n");
}
int main(void)
{
T_NODE *head;//存储一个链表的头节点地址
//T_NODE *new_node;//存储新创建节点的地址
//T_NODE *temp;//存储操作过程中移动节点的地址
int arr[6] = {1,2,3,6,7,8};//假设需要存储的是这5个数
//int i = 0;//循环变量
head = list_init(arr[0]);//初始化或者创建一个链表头结点
head = test_head_insert(head, arr);//测试头插法
del_list(head);//删除链表
head = list_init(arr[0]);//初始化或者创建一个链表头结点
test_tail_insert(head, arr);//测试尾插法
head = test_specific_insert(head);//测试指定位置插入
test_change_specific_var(head);//测试指定值替换
head = test_del_specific_var(head);//测试删除指定值
return 0;
}3.2 双链表
在单链表的基础上,对于每一个结点设计一个前驱结点,前驱结点与前一个结点相互连接,构成一个链表。
双向链表可以简称为双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
图:双向链表示意图
 一个完整的双向链表应该是头结点的pre指针指为空,尾结点的next指针指向空,其余结点前后相链。
一个完整的双向链表应该是头结点的pre指针指为空,尾结点的next指针指向空,其余结点前后相链。
双链表的数据结构
c
typedef struct line{
int data; //data
struct line *pre; //pre node
struct line *next; //next node
}line,*a;
//分别表示该结点的前驱(pre),后继(next),以及当前数据(data)3.3 循环单链表
4 栈
4.1 栈的定义
栈(Stack) :是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。
栈顶(Top) :线性表允许进行插入删除的那一端。
栈底(Bottom) :固定的,不允许进行插入和删除的另一端。
空栈 :不含任何元素的空表。
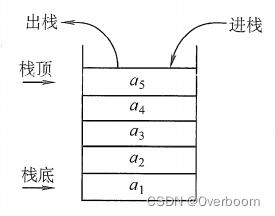
栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构
4.2 栈的常见基本操作
InitStack(&S):初始化一个空栈S。
StackEmpty(S):判断一个栈是否为空,若栈为空则返回true,否则返回false。
Push(&S, x):进栈(栈的插入操作),若栈S未满,则将x加入使之成为新栈顶。
Pop(&S, &x):出栈(栈的删除操作),若栈S非空,则弹出栈顶元素,并用x返回。
GetTop(S, &x):读栈顶元素,若栈S非空,则用x返回栈顶元素。
DestroyStack(&S):栈销毁,并释放S占用的存储空间("&"表示引用调用)。
4.3 栈的存储结构
顺序存储与链式存储都能实现一个栈。
4.3.1 顺序栈(静态栈)
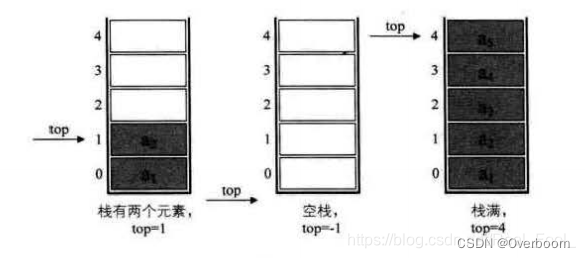
采用顺序存储的栈称为顺序栈,它利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针(top)指示当前栈顶元素的位置。
若存储栈的长度为StackSize,则栈顶位置top必须小于StackSize。一般的把数组的第一个位置0作为栈底,再单独定义一个变量指示栈顶。
栈的顺序存储结构可描述为:
c
/* 顺序栈结构 */
typedef int SElemType;
typedef struct
{
SElemType data[MAXSIZE];
int top; /* 用于栈顶指针 */
}SqStack;若现在有一个栈,StackSize是5,则栈的普通情况、空栈、满栈的情况分别如下图所示:
顺序栈的常见操作代码:
static_stack.h
c
#pragma once
#define StackSize 10
class CStaticStack
{
public:
CStaticStack();
~CStaticStack();
//判满
bool IsFull();
//判空
bool IsEmpty();
//入栈
bool Push(int data);
//出栈
bool Pop(int& data);
//按照出栈顺序打印
void Print();
private:
int m_iTop = 0;
int m_data[StackSize];
};static_stack.cpp
cpp
#include <iostream>
#include "StaticStack.h"
CStaticStack::CStaticStack()
{
}
CStaticStack::~CStaticStack()
{
}
bool CStaticStack::IsFull()
{
if ( m_iTop == StackSize )
{
return true;
}
return false;
}
bool CStaticStack::IsEmpty()
{
if ( m_iTop == 0 )
{
return true;
}
return false;
}
bool CStaticStack::Push(int data)
{
//先判断是不是满了
if (IsFull())
{
return false;
}
m_data[m_iTop++] = data;
return true;
}
bool CStaticStack::Pop(int& data)
{
//先判断是不是空了
if ( IsEmpty() )
{
return false;
}
data = m_data[--m_iTop];
return true;
}
void CStaticStack::Print()
{
int data;
while ( Pop(data) )
{
std::cout << data << " ";
}
}测试用例
cpp
int main(int argc, char** argv)
{
int n, x;
CStaticStack test;
cout << "请输入元素个数n( 0 < n < 10):" << endl;
cin >> n;
cout << "请依次输入n个元素,依次入栈:" << endl;
while (n--)
{
cin >> x; //输入元素
test.Push(x);
}
cout << "元素依次出栈:" << endl;
test.Print();
getchar();
getchar();
return 0;
}4.3.2 链式栈(动态栈)
栈的链式存储通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。这里规定链栈没有头节点,Lhead 指向栈顶元素,如下图所示。
 对于空栈来说,链表原定义是头指针指向空,那么链栈的空其实就是top=NULL的时候。
对于空栈来说,链表原定义是头指针指向空,那么链栈的空其实就是top=NULL的时候。
链栈的结构代码可描述为:
c
/*构造链栈*/
typedef struct LinkStack{
LinkStackPtr top;
int data;
}LinkStack;链栈的常见操作代码如下:
dynamic_stack.h
cpp
struct StackNode
{
int data = 0;
StackNode* pNext = nullptr;
};
class CDynamicStack
{
public:
CDynamicStack();
~CDynamicStack();
//判空
bool IsEmpty();
//入栈
bool Push(int data);
//出栈
bool Pop(int& data);
//按照出栈顺序打印
void Print();
private:
bool CreatNode(StackNode*& pnode);
void DestroyNode(StackNode*& pnode);
private:
StackNode* m_pTop = nullptr;
};dynamic_stack.cpp
cpp
#include "DynamicStack.h"
#include <iostream>
CDynamicStack::CDynamicStack()
{
}
CDynamicStack::~CDynamicStack()
{
if ( m_pTop != nullptr )
{
while ( m_pTop )
{
StackNode* ptemp = m_pTop;
m_pTop = m_pTop->pNext;
DestroyNode(ptemp);
}
}
}
bool CDynamicStack::IsEmpty()
{
return m_pTop == nullptr;
}
bool CDynamicStack::Push(int data)
{
StackNode* ptemp = nullptr;
if ( !CreatNode(ptemp) )
{
return false;
}
ptemp->data = data;
ptemp->pNext = m_pTop;
m_pTop = ptemp;
return true;
}
bool CDynamicStack::Pop(int& data)
{
if ( IsEmpty() )
{
return false;
}
data = m_pTop->data;
StackNode* ptemp = m_pTop;
m_pTop = m_pTop->pNext;
DestroyNode(ptemp);
return true;
}
void CDynamicStack::Print()
{
int data;
while (Pop(data))
{
std::cout << data << " ";
}
}
bool CDynamicStack::CreatNode(StackNode*& pnode)
{
StackNode* ptemp = new StackNode;
if ( ptemp == nullptr )
{
return false;
}
pnode = ptemp;
return true;
}
void CDynamicStack::DestroyNode(StackNode*& pnode)
{
if ( pnode != nullptr )
{
delete pnode;
pnode = nullptr;
}
}测试用例:
cpp
int main(int argc, char** argv)
{
int n, x;
CDynamicStack test;
cout << "请输入元素个数n:" << endl;
cin >> n;
cout << "请依次输入n个元素,依次入栈:" << endl;
while (n--)
{
cin >> x; //输入元素
test.Push(x);
}
cout << "元素依次出栈:" << endl;
test.Print();
getchar();
getchar();
return 0;
}5 队列
5.1 队列的定义
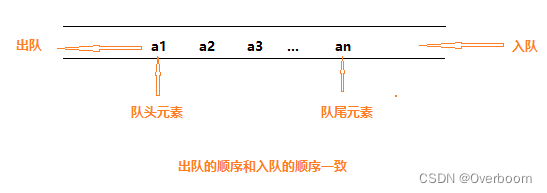
**队列(queue)是只允许在一端进行插入操作,在另一端进行删除操作的线性表,简称"队"。**所以队列是一种操作受限的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。
允许插入的一端称为队尾(rear) ,允许删除的一端称为队头(front)。
向队列中插入新的数据元素称为入队,新入队的元素就成为了队列的队尾元素。
从队列中删除队头元素称为出队 ,其后继元素成为新的队头元素。
5.2 队列常见操作
InitQueue(&Q): 初始化队列,构造-一个空队列 Q.
QueueEmpty(Q): 判队列空,若队列Q为空返回true,否则返回false.
QueueFull(Q); 判断队满,若队列Q满返回true,否则返回false.
EnQueue(&Q, x): 入队,若队列Q未满,将x加入,使之成为新的队尾。
DeQueue (&Q, &x): 出队,若队列e非空,删除队头元素,并用x返回。
GetHead(Q, &x): 读队头元素,若队列Q非空,则将队头元素赋值给x。
5.3 队列的存储结构
队列存储结构的实现有以下两种方式:
- 顺序队列:在顺序表的基础上实现的队列结构;
- 链队列:在链表的基础上实现的队列结构;
两者的区别仅是顺序表和链表的区别,即在实际的物理空间中,数据集中存储的队列是顺序队列,分散存储的队列是链队列。
5.3.1 队列的顺序存储结构
队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针:队头指针front 指向队头元素,队尾指针rear 指向队尾元素的下一个位置 (也可以让rear指向队尾元素、front 指向队头元素) 。
顺序队列结构可描述为:
c
typedef struct SqQueue
{
ElemType data[MaxSize]; //存放队列元素
int front; //队头指针
int rear; //队尾指针
}SqQueue;初始状态(队空条件):Q.front == 0, Q.rear==0
进队操作:队不满时,先送值到队尾元素,再将队尾指针加1。
出队操作:队不空时,先取队头元素值,再将队头指针加1。
队列操作图如下:
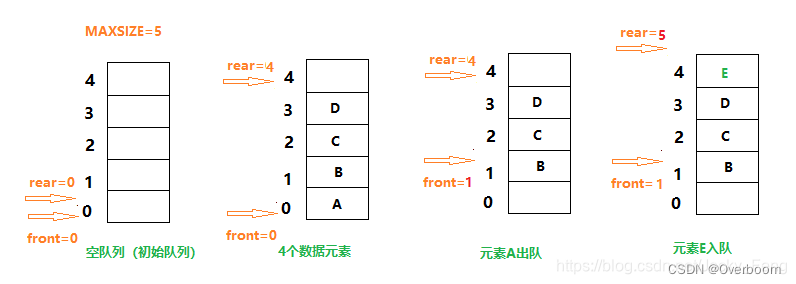
**顺序存储假溢出问题:**如果在插入E的基础上再插入元素F,将会插入失败。因为rear==MAXSIZE,尾指针已经达到队列的最大长度。但实际上队列存储空间并未全部被占满,这种现象叫做"假溢出"。
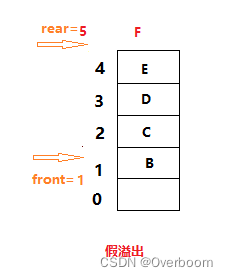
假溢出的原因是顺序队列进行队头出队、队尾入队,造成数组前面会出现空闲单元未被充分利用。
5.3.2 循坏队列
为了解决假溢出的问题,引入了循环队列,使其头尾相连。我们把队列的这种头尾相接的顺序存储结构称为循环队列。
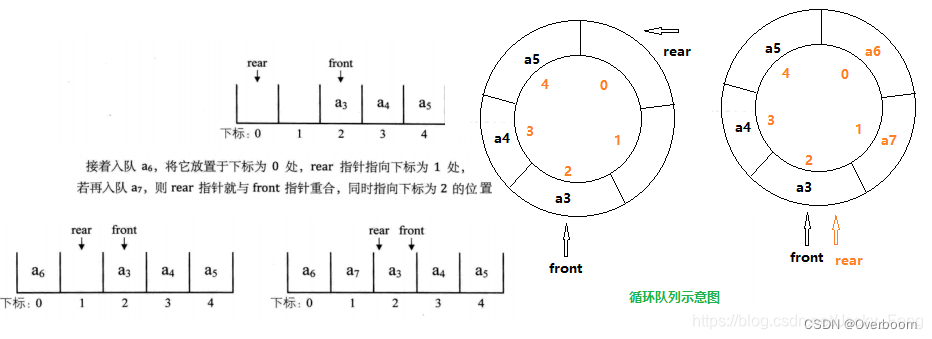 问题:当循环对列为空或满时,都是队尾指针等于队头指针,即rear == front 。当 rear==front时,该是判满还是判空呢?
问题:当循环对列为空或满时,都是队尾指针等于队头指针,即rear == front 。当 rear==front时,该是判满还是判空呢?
解决方案:
方案一:设置一个计数器,开始时计数器设为0,新元素入队时,计数器加1,元素出队,计数器减1。当计数器等于MAXSIZE时,队满;计数器等于0时,队空。
方案二:保留一个元素空间,当队尾指针指的空闲单元的后继单元是队头元素所在单元时,队满。
队满的条件为(Q.rear+1)%MAXSIZE == Q.front;
队空的条件为Q.rear==Q.front
循环队列代码操作:
c
#include<stdio.h>
#include<malloc.h>
#define MaxSize 5
typedef int ElemType;
typedef struct SqQueue
{
ElemType *data; //存放队列元素
int front; //队头指针
int rear; //队尾指针
}SqQueue;
void InitQueue(SqQueue *Q); //初始化队列
bool isEmpty(SqQueue Q); //判断队列是否为空
bool isFull(SqQueue Q); //判断队列是否已满
bool EnQueue(SqQueue *Q,ElemType e); //入队
bool DeQueue(SqQueue *Q,ElemType *e); //出队
void PrintQueue(SqQueue pQ);
int main()
{
SqQueue Q;
ElemType e;
InitQueue(&Q);
EnQueue(&Q,1);
EnQueue(&Q,2);
EnQueue(&Q,3);
EnQueue(&Q,4);
EnQueue(&Q,5);
EnQueue(&Q,6);
EnQueue(&Q,7);
PrintQueue(Q);
if(DeQueue(&Q,&e))
printf("出队成功,出队元素为:%d\n",e);
else
printf("出队失败\n");
PrintQueue(Q);
return 0;
}
void InitQueue(SqQueue *Q)
{
Q->data = (ElemType *)malloc(sizeof(ElemType)* MaxSize);
Q->front = Q->rear = 0;
}
bool isEmpty(SqQueue Q)
{
if(Q.rear == Q.front)
return true;
else
return false;
}
bool isFull(SqQueue Q)
{
if((Q.rear + 1) % MaxSize == Q.front)
return true;
else
return false;
}
bool EnQueue(SqQueue *Q,ElemType e)
{
if((Q->rear + 1) % MaxSize == Q->front)
return false; //队满报错
Q->data[Q->rear] = e;
Q->rear = (Q->rear +1) % MaxSize; //队尾指针加1取模
return true;
}
bool DeQueue(SqQueue *Q,ElemType *e)
{
if(Q->rear == Q->front)
return false; //队空报错
*e = Q->data[Q->front];
Q->front = (Q->front +1) % MaxSize; //队头指针加1取模
return true;
}
void PrintQueue(SqQueue pQ)
{
int i = pQ.front;
while(i != pQ.rear)
{
printf("%d ",pQ.data[i]);
i = (i+1) % MaxSize;
}
printf("\n");
}5.3.1 队列的链式存储结构
队列的链式存储结构就是只能在链表表尾进行插入,只能对链表的表头进行结点的删除,其余一切的操作均不允许,这样强限制性的"链表",就是我们所说的队列。
队列的链式存储结构代码可表示为:
c
//结点定义
typedef struct node{
int data;
struct node *next;
}node;
//队列定义,队首指针和队尾指针
typedef struct queue{
node *front; //头指针
node *rear; //尾指针
}queue;链式队列代码操作:
c
#include<stdio.h>
#include<stdlib.h>
//结点定义
typedef struct node{
int data;
struct node *next;
}node;
//队列定义,队首指针和队尾指针
typedef struct queue{
node *front;
node *rear;
}queue;
//初始化结点
node *init_node(){
node *n=(node*)malloc(sizeof(node));
if(n==NULL){ //建立失败,退出
exit(0);
}
return n;
}
//初始化队列
queue *init_queue(){
queue *q=(queue*)malloc(sizeof(queue));
if(q==NULL){ //建立失败,退出
exit(0);
}
//头尾结点均赋值NULL
q->front=NULL;
q->rear=NULL;
return q;
}
//队列判空
int empty(queue *q){
if(q->front==NULL){
return 1; //1--表示真,说明队列非空
}else{
return 0; //0--表示假,说明队列为空
}
}
//入队操作
void push(queue *q,int data){
node *n =init_node();
n->data=data;
n->next=NULL; //采用尾插入法
//if(q->rear==NULL){
if(empty(q)){
q->front=n;
q->rear=n;
}else{
q->rear->next=n; //n成为当前尾结点的下一结点
q->rear=n; //让尾指针指向n
}
}
//出队操作
void pop(queue *q){
node *n=q->front;
if(empty(q)){
return ; //此时队列为空,直接返回函数结束
}
if(q->front==q->rear){
q->front=NULL; //只有一个元素时直接将两端指向制空即可
q->rear=NULL;
free(n); //记得归还内存空间
}else{
q->front=q->front->next;
free(n);
}
}
//打印队列元素
void print_queue(queue *q){
node *n = init_node();
n=q->front;
if(empty(q)){
return ; //此时队列为空,直接返回函数结束
}
while (n!=NULL)
{
printf("%d\t",n->data);
n=n->next;
}
printf("\n"); //记得换行
}
//主函数调用,这里只是简单介绍用法
int main(){
queue *q=init_queue();
///入队操作/
printf("入队\n");
for(int i=1;i<=5;i++){
push(q,i);
print_queue(q);
}
///出队操作/
printf("出队\n");
for(int i=1;i<=5;i++){
pop(q);
print_queue(q);
}
return 0;
}对于循环队列与链队列的比较,可以从两方面来考虑,从时间上,其实它们的基本操作都是常数时间,即都为O(1)的,不过循环队列是事先申请好空间,使用期间不释放,而对于链队列,每次申请和释放结点也会存在一些时间开销,如果入队出队频繁,则两者还是有细微差异。对于空间上来说,循环队列必须有一个固定的长度,所以就有了存储元素个数和空间浪费的问题。而链队列不存在这个问题,尽管它需要一个指针域,会产生一些空间上的开销,但也可以接受。所以在空间上,链队列更加灵活。
总的来说,在可以确定队列长度最大值的情况下,建议用循环队列,如果你无法预估队列的长度时,则用链队列。