论文分享
https://dl.acm.org/doi/pdf/10.1145/3357384.3357900![]() https://dl.acm.org/doi/pdf/10.1145/3357384.3357900
https://dl.acm.org/doi/pdf/10.1145/3357384.3357900
论文代码
https://github.com/gjzheng93/frap-pub![]() https://github.com/gjzheng93/frap-pub
https://github.com/gjzheng93/frap-pub
摘要
越来越多可用的城市数据和先进的学习技术使人们能够提高我们城市功能的效率。其中,提高城市交通效率是最突出的课题之一。最近有研究提出将强化学习(RL)用于交通信号控制。与传统交通方式严重依赖先验知识不同,强化学习可以直接从反馈中学习。然而,如果没有仔细的模型设计,现有的强化学习方法通常需要很长时间才能收敛,并且学习的模型可能无法适应新的场景。例如,一个对上午交通训练良好的模型可能不适用于下午的交通,因为交通流可能会逆转,从而导致非常不同的状态表示。
本文基于交通信号控制中直观的相位竞争原理,提出了一种新颖的FRAP设计,即当两个交通信号冲突时,优先考虑交通量较大(即需求较高)的信号。通过阶段竞争建模,实现了对交通流中翻转、旋转等对称情况的不变性。
通过全面的实验,我们证明了我们的模型在复杂的全相位选择问题上比现有的RL方法找到了更好的解,在训练过程中收敛速度更快,并且对不同的道路结构和交通条件具有更好的泛化能力。
介绍
当前,强化学习作为一种可行的解决方案已经被用于现实场景的交通信号控制中。强化学习模型能够直接通过与环境交互学习控制策略。为了实现这个目的,一种典型的方法是为每个交叉路口设置一个Agent,Agent通过做完动作后环境的反馈,来优化奖励。
这些强化学习模型能有效对2或4个信号相位的交叉路口进行控制。但对于8相位的交叉路口,研究发现会出现状态空间爆炸的问题。在2相位问题中,只有4个直行车道,假设状态定义为每个车道上的车辆数和当前信号相位,每个车道的车辆容量为n,则2相控制问题的状态空间大小为 。而在8相位问题中,有4个直行车道和4个左转车道,状态空间大小会增加到
。所以其挑战是减少问题空间并更有效地寻找不同场景,故强化学习算法需要在最小范围里找到最优解。
之前的强化学习方法独立输入8车道并利用回归得到Q ( s , a ),因此其需要尝试在各种状态上尝试8种动作,大约个样本才能获得最终估计。
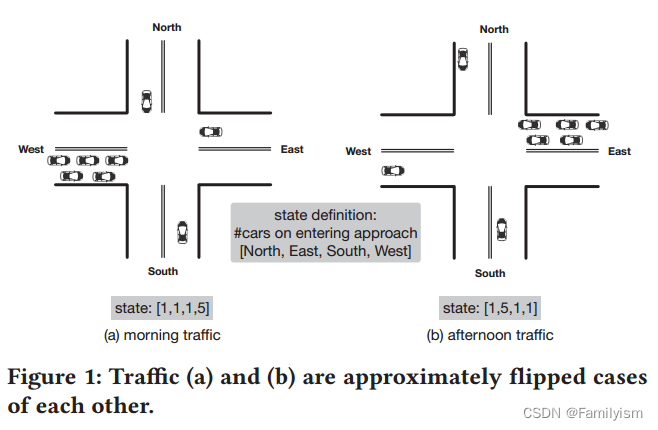
但事实上,相当一部分状态-动作对是不必要探究的。以图1为例。这两种情况大致是镜像(流量翻转)。这种翻转是人们早上从住宅区通勤到商业区,下午反向交通的常见现象。由于这样的翻转将导致现有方法的完全不同的状态表示,已经了解第一种情况的RL代理仍然不能处理第二种情况。但是根据常识,这两种情况几乎是相同的,人们希望从第一种情况中学习的模型可以处理第二种情况或其他类似的情况。此外,如图2所示,给定任何特定的状态,可以通过旋转和翻转生成七个其他案例。因此,即使在训练期间只看到一个案例,理想的RL模型也能处理所有八个案例,具有一定的泛化能力。

基于上述观察,我们提出了一个新的模型设计称为FRAP,它是不变的对称操作,如翻转和旋转,并考虑所有相位置。关键的想法是,与其考虑单个的交通时刻如关注不同交通运动之间的时刻。这个想法是基于交通信号控制中冲突的直观原理:
(1)较大的交通流量表明对绿色信号的需求较高;
(2)当两个交通流冲突时,我们应该优先考虑需求较高的一个。
总之,本文的主要贡献包括:
1.提出了一种新的基于强化学习的交通信号控制模型设计框架FRAP。通过捕捉不同信号相位之间的冲突关系,该算法实现了对对称性的不变性,从而更好地解决了困难的全相位交通信号控制问题。
2.我们所展示的FRAP框架在通过真实世界数据的综合实验的学习过程中收敛速度比现在的RL算法要快的多。
3.我们进一步证明了FRAP的优越的延展性。更特别的是,我们证实了FRAP能够处理不同的道路结构,不同的交通流,真实世界中复杂的相位设置,以及多交叉环境。
思路
模型概览
文章采用了Ape-X DQN来解决强化学习问题。模型采用交通流动的状态特征作为输入,预测每个动作的分数。这可以用贝尔曼公式形式化描述出来:

FRAP基于两条特别的规则:
**竞争规则:**更大的交通溜达代表着对绿灯更高的需求,当两种信号出现冲突,应该给更高需求的相位高优先级。
**不变性规则:**信号控制应该对旋转、对称具有不变性。
算法框架
Ape-X DQN,标准的深度强化学习可以被分为两个部分,包括执行和学习。执行部分包括部署多个具有不同策略的参与者与环境交互,并将观察到的数据存储到经验存储器中。学习部分适用于对经验存储器中的训练数据进行采样,从而来更新模型。两个部分同时运行。
相位不变信号控制设计
文章将相位分数预测分为三个阶段:相位需求建模(Phase demand modeling)、相位对表示(Phase pair representation)、相位对竞争(Phase pair competition)。





实验
实验设置
本文使用CityFLow模拟平台,将交通数据作为输入,模拟器能够为模型提供交通情况的观测并执行信号控制动作。 与真实世界一致,绿灯以后设置了3s黄灯和2s全红灯。 在交通数据集中,每辆车描述为( o , t , d ) :其中o是起始位置,t是时间,d是终点位置。 在多交叉路口网络中,文章使用了真实路网。在单交叉路口中,除非其他特殊规定,路网将设为一个拥有300米路段的四向交叉路口。
数据集
文章使用了济南、杭州和亚特兰大的数据集。 济南:文章收集了济南7个十字路口的监控摄像头数据。该数据集中每条记录包含摄像头的位置、车辆到达十字路口的时间以及车辆信息。 杭州:该数据集记录了2018年4月1日到2018年4月30日的杭州6个路口的监控摄像头数据,记录完成,数据处理方法于济南数据类似。 亚特兰大:该数据集由8台摄像机记录了2006年11月8日亚特兰大Peachtree Street的主干道。该车辆轨迹数据集提供了研究区域内车辆的精确位置,共考虑了五个交叉路口。
参数设置
1.Adam学习率设置为0.001 (这里使用的Adam优化器是一种自适应学习率的优化算法,它根据梯度的一阶和二阶矩估计来调整每个参数的学习率)
2.每一轮训练中,从内存中采样1000个样本,以20的batch_size进行训练 (这指的是在每次训练迭代中,从经验回放缓冲区(replay memory)中随机抽取1000个过去的样本(状态、动作、奖励、下一个状态)。这样做可以让智能体从过去的经验中学习,而不是仅依赖于最新的数据,这有助于提高学习效率和稳定性)
3.3个Actor并行以实现Ape-X DQN框架 (Ape-X DQN框架是一种分布式强化学习框架,它通过多个actor(执行者)并行地与环境交互来提高数据收集和学习效率。这里设置3个actor意味着有3个并行的智能体在环境中执行动作,收集数据,并存储到共享的回放缓冲区中供学习者(learner)使用)
4.将10s设置为两次动作的间隔 (这是指在智能体选择并执行一个动作后,需要等待10秒才能执行下一个动作。这个时间间隔被设置为10秒,是因为实验表明模型性能对这个参数不是特别敏感,也就是说,即使间隔时间有所变化,对模型性能的影响也不大。)
评价指标
1.旅行时间 (Travel Time):这是评估交通信号控制方法性能的主要指标。定义为车辆在接近车道上花费的平均旅行时间,以秒为单位。该指标反映了车辆通过交通信号控制路口所需的总时间,是交通领域中常用的性能评估指标。

2.收敛速度 (Convergence Speed):收敛速度衡量了强化学习模型在训练过程中学习策略并达到稳定性能的速度。文档中提到FRAP模型在收敛速度上优于其他强化学习方法。

3.对不同交通流量的适应性 (Adaptability to Different Traffic Volumes):衡量模型在不同交通流量条件下的性能,包括高峰和非高峰时段。FRAP模型显示出良好的适应性,即使在训练时使用的是一个交通流量,也能很好地迁移到另一个不同的交通流量环境中。

4.对称性不变性 (Invariance to Symmetry):衡量模型对于交通流对称操作(如翻转和旋转)的不变性。FRAP模型设计考虑了交通信号控制的对称性,因此在面对交通流的翻转和旋转时,模型性能保持稳定。

5.多路口环境下的性能 (Performance in Multi-Intersection Environment):评估模型在包含多个交通信号控制路口的环境中的性能。FRAP在多路口环境中同样表现出色,这表明它具有在更复杂交通网络中应用的潜力。

6.策略解释性 (Policy Interpretability):通过可视化学习到的策略,分析模型为每个交通运动分配的绿灯时间与交通流量的百分比之间的关系。FRAP能够根据交通流量合理分配绿灯时间,与其他基线方法相比,显示出更好的策略解释性。

代码运行
本文作者在docker上提供了镜像,可以直接进行运行(详情见readme.md)
以下是根据提供的代码文件和它们的整理出的阅读顺序:
config.py:定义了实验配置、路径、交通环境配置、代理配置等。
network_agent.py:定义了基于神经网络的代理的抽象类,提供了构建网络和训练网络的通用方法。
transfer_dqn_agent.py:实现了一个特定的强化学习代理框架,处理全相位场景并实现对称变换的不变性。
anon_env.py :实现了一个交通信号控制的环境,包括交叉口的设置、信号灯的控制逻辑等。 sumo_env.py:定义了一个与SUMO模拟器交互的环境,用于获取交通数据。
generator.py :生成器类,用于加载模型、启动SUMO环境、进行模拟并记录结果。 construct_sample.py :从原始数据中构建训练样本,选择所需的状态特征并计算相应的平均/即时奖励。
updater.py :定义了模型更新的类,负责加载样本和更新网络。 model_pool.py :实现了模型池的逻辑,用于存储和评估最佳模型。
pipeline.py :实现了整个强化学习的流程,包括启动SUMO环境、运行模拟、构建样本、更新模型和模型池。
replay.py :用于回放模拟结果,可能用于可视化或进一步分析。 runexp.py:运行实验的脚本,可能用于启动pipeline.py中的流程。
model_test.py :定义了模型测试的逻辑,用于评估训练好的模型性能。
summary.py:包含用于分析和汇总实验结果的函数。它从记录的文件中提取数据,计算性能指标,绘制图表,并生成总结报告。该脚本处理训练和测试阶段的性能数据,包括平均持续时间、排队长度等,并生成可视化的图表来展示模型性能随时间的变化。
script.py :包含了一些通用函数,例如获取交通量等。
testexp.py :用于执行测试实验,可能包含了测试模型的逻辑。
run_batch.py :批量运行实验的脚本,可以用于自动化地运行多个实验配置。
agent.py :定义了不同代理的抽象类。
实验结果分析
test_results.csv
记录了每轮测试的详细结果,包括持续时间、排队长度、进入和离开车辆的数量。其中,部分轮次的持续时间和排队长度为-1.0,这可能是因为这些轮次的数据不完整或无效。

total_test_results.csv

traffic: 表示使用的交通文件的名称。这个文件定义了交通流量和车辆生成的规则。 traffic_file: 与 traffic 字段相同,记录了交通文件的名称。 min_queue_length: 测试期间记录的最小排队长度。排队长度是指在交叉口前等待的车辆队伍的长度。 min_queue_length_round: 记录到最小排队长度时的测试轮次。 min_duration: 最短持续时间。持续时间是指车辆通过交叉口所需的时间。这里记录为 inf(无穷大),可能表示没有有效的最小持续时间记录,或者在测试期间没有观察到足够低的持续时间。 min_duration_round: 记录到最短持续时间时的测试轮次。由于 min_duration 是 inf,这个字段可能没有记录有效数据。 final_duration: 测试阶段最后的平均持续时间。这个值是所有有效持续时间观测值的平均值。 final_duration_std: 最终持续时间的标准差,表示持续时间的波动情况。 convergence_1.2 和 convergence_1.1: 收敛性指标,用于衡量模型性能是否随着时间趋于稳定。这里两者都为0,可能表示模型性能没有达到预期的收敛标准,或者这些字段在测试中没有被正确更新。 nan_count: 数据中 NaN(不是数字)值的数量。NaN 值可能由多种原因造成,例如模型未能记录数据,或者在数据处理过程中出现了错误。较高的 NaN 计数可能影响性能指标的准确性。 min_duration2: 这个字段在提供的数据中是空的,可能用于记录另一种条件下的最短持续时间,或者用于其他相关的性能评估。

横坐标: 通常表示时间或轮次,是实验或模拟过程中的各个点。 纵坐标: 表示某个度量指标,可能是车辆的平均持续时间、平均排队长度或其他交通相关指标。 图表中的数值: 400, 200, 50, 100, 150, 250, 300, 350,这些可能表示横坐标的刻度值,代表不同的时间点或轮次。 "inter 0 1786": 这可能指的是某个特定的交叉口或实验设置的标识。 "final-37.8": 这可能表示实验或模拟的最终结果是37.8个单位(具体单位未知,可能是秒、分钟或其它)。

横坐标: 表示时间,从0开始,以50为增量,直至400。这可能代表了一个观测时间段,例如一个小时内每50秒记录的数据。 纵坐标: 表示某个交通相关的度量指标,可能是车辆流量、车辆排队长度或其他。 图表中的数值: 500, 400, 300, 200, 100,这些可能表示纵坐标的刻度值,代表不同的度量级别或数量。 "inter 0 1786.json 07 01 11 59 24 10-76.75": 这行文本可能表示数据的来源文件和时间戳,以及一个特定的数值(76.75),这可能是某个重要指标的平均值或最终结果。
实验结果分析
从 total_test_results.csv 文件可以看出,实验在某个交通文件上运行了多轮,记录了每轮的最小排队长度和最终的平均持续时间。nan_count 较高表明有很多数据点无效,可能是因为模型在某些情况下未能正确预测或记录数据。 从 test_results.csv 文件可以看出,每轮测试的持续时间波动较大,这可能是由于交通流量变化、模型性能或其他外部因素造成的。 图表文件(如 inter_0_1786.json_07_01_11_59_24_10-test.png 和 inter_0_1786-test.png)提供了可视化的结果,有助于分析模型性能随时间的变化趋势。 综上所述,实验结果表明模型在处理特定交通场景时可能存在一定的波动性和不稳定性,需要进一步分析和调整模型参数或结构以提高性能。同时,需要处理NaN值以确保数据的完整性和准确性。