Redis如何实现高并发
- 首先是单线程模型:redis采用单线程可以避免多线程下切换和竞争的开销,提高cpu的利用率,如果是多核cpu,可以部署多个redis实例。
- 基于内存的数据存储:redis将数据存储在内存中,相比于硬盘访问速度更快。
- 优化数据结构:redis使用多种高效的数据结构,如哈希表、跳跃表等提高数据的操作效率。
- 多路复用和非阻塞IO:多路复用允许一个线程同时监听多个客户端,而非阻塞IO允许发起IO请求后不会阻塞当前线程,而可以执行其他任务,提高了响应速度和利用率。
redis4.0及之前都是单线程模式,之后慢慢往多线程方向发展,这是为什么呢?
- 4.0之前机器大多是单核的,故使用单线程,但随着互联网发展,机器都是多核,为了提高性能慢慢往多线程方向发展。
- 其次,实践中出现的部分问题不好解决,比如删除一个大key ------hash表,就需要将里面的键值对全部删除,非常耗时,如果是单线程会出现卡顿,导致其他连接用户不能及时响应。
到了redis6/7版本网络处理请求是多线程(瓶颈),命令执行是单线程。
开启多线程
配置文件redis.conf设置
io-threads 数量 //设置线程核心数
io-threads-do-reads yes //开启多线程
缓存穿透
缓存穿透是指请求的数据在缓存中和数据库中都不存在,每次请求访问数据库。
场景:
- 查询不存在的数据:缓存无法存储,故每次从数据库查询;
- 查询热门数据:数据被访问频繁,导致缓存系统无法处理,只能从数据库中访问;
- 查询异常数据:数据服务异常缓存无法访问。
解决方法:维护一个布隆过滤器(判断一个元素是否可能在一个集合中)。
缓存击穿
是指一个查询的热点数据不存在缓存,每次都需要访问数据库。
场景:
- 未缓存存储的热点数据
- 热点数据过期
解决方法:查询数据库前判断缓存中是否有,若没用使用redis查询数据库,写入缓存。
缓存雪崩
指某一时间大量缓存数据集体失效,导致数据库的访问量加大,对数据库产生极大负荷。
场景:
- 缓存服务器宕机:当服务器宕机或重启时,大量访问将命中数据库;
- 数据过期时间设置不合理。
- 促销商品:打折等促销活动将带来高频的数据访问。
解决方法:
- 将缓存过期时间分散开,即为不同的数据设置不同的过期时间;
- 使用多级缓存结构,通过增加缓存层数来提高数据的保存时间;
实际生产上如何禁止keys */flushdb/flushall等危险命令?
将相应命令设置成空字符串。
在redis.conf配置命令为空字符串
rename- command keys ""
命令含义:重命名指令keys为空字符串
实际遍历可以通过scan来进行
命令:scan 游标(从0开始) match 模糊匹配 count 数量
例子 :
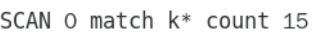
从0开始匹配前缀为k的15条记录

返回第一行表示下一个游标,如果为0表示遍历完毕。
多大算大key
String为超过10KB。
而集合如List Hash等超过5000即为大key。
危害
造成内存不均,集群迁移困难。
删除等会造成阻塞。
查询
redis-cli --bigkeys : 发现其中的大key
memory usage 键:查询某个key的大小
如何删除
先将大key中数据进行删除,里面大致清空时直接delete该key
如何调优
将大key移除改为非阻塞


双检加锁策略
当redis中无数据,而需要向mysql查询时,如何保证数据一致性?
策略:
- 先在redis缓存查询是否存在,命中直接返回;
- 未命中则加锁,再进行一次缓存查询(因为在多线程中可能上次加锁的线程已经将数据更新到缓存)
- 若未查到,访问数据库,并更新缓存。
数据库和缓存一致性的策略
先删除缓存再更新数据库:
让下次访问时,将数据从数据库中写回到缓存。
缺陷:可能存在更新不及时,导致线程访问到旧的数据写会缓存,导致后面请求访问的都是旧数据。
先更新数据库再删除缓存:
让下次访问时,将数据从数据库中写回到缓存。
缺陷:可能删除不及时,导致部分访问读取缓存中的旧值。
感谢观看------