图由一组点和边组成,其中每个节点和边都具有属性映射。点是图的基本对象,可以独立于图中的其他任何对象存在。边创建了两个点之间的有向连接。
创建图
要创建图,可以使用 ag_catalog 命名空间中的 create_graph 函数。
create_graph()
语法:create_graph(graph_name);
返回:
void参数:
| Name | Description |
|---|---|
| graph_name | 要创建的图的名称 |
考虑事项:
- 此函数不会返回任何结果。如果没有错误消息,则图已创建。
- 图所需的表会自动创建。
示例:
SELECT * FROM ag_catalog.create_graph('graph_name');删除图
要删除图,可以使用位于 ag_catalog 命名空间中的 drop_graph 函数。
drop_graph()
语法:drop_graph(graph_name, cascade);
返回:
void参数:
| Name | Description |
|---|---|
| graph_name | 要删除的图的名称 |
| cascade | 一个布尔值,如果为真,则删除依赖于该图的标签和数据。 |
考虑事项
- 此函数不会返回任何结果。如果没有错误消息,则图已被删除。
- 建议将 cascade 选项设置为 true,否则必须使用 SQL DDL 命令手动删除图中的所有内容。
示例:
SELECT * FROM ag_catalog.drop_graph('graph_name', true);图在 Postgres 中的存储方式
使用 AGE 创建图时,将为每个独立图生成一个 Postgres 命名空间。可以在 ag_catalog 命名空间中的 ag_graph 表中看到创建的图的名称和命名空间:
SELECT create_graph('new_graph');
NOTICE: graph "new_graph" has been created
create_graph
--------------
(1 row)
SELECT * FROM ag_catalog.ag_graph;
name | namespace
-----------+-----------
new_graph | new_graph
(1 row)创建图后,会在图的命名空间下创建两个表来存储顶点和边:_ag_label_vertex 和 _ag_label_edge。这些表将是任何新顶点或边标签的父表。下面的查询显示了如何检索数据库中所有图的边和顶点标签。
-- 在创建新顶点标签之前。
SELECT * FROM ag_catalog.ag_label;
name | graph | id | kind | relation | seq_name
------------------+-------+----+------+----------------------------+-------------------------
_ag_label_vertex | 68484 | 1 | v | new_graph._ag_label_vertex | _ag_label_vertex_id_seq
_ag_label_edge | 68484 | 2 | e | new_graph._ag_label_edge | _ag_label_edge_id_seq
(2 rows)
-- 创建新的顶点标签。
SELECT create_vlabel('new_graph', 'Person');
NOTICE: VLabel "Person" has been created
create_vlabel
---------------
(1 row)
-- 创建新顶点标签后。
SELECT * FROM ag_catalog.ag_label;
name | graph | id | kind | relation | seq_name
------------------+-------+----+------+----------------------------+-------------------------
_ag_label_vertex | 68484 | 1 | v | new_graph._ag_label_vertex | _ag_label_vertex_id_seq
_ag_label_edge | 68484 | 2 | e | new_graph._ag_label_edge | _ag_label_edge_id_seq
Person | 68484 | 3 | v | new_graph."Person" | Person_id_seq
(3 rows)每当使用 create_vlabel() 函数创建顶点标签时,都会在 new_graph 的命名空间中生成一个新表:new_graph."<label>"。对于 create_elabel() 函数创建边标签也是同样的情况。使用 Cypher 创建顶点和边会自动创建这些表。
-- 创建两个顶点和一个边。
SELECT * FROM cypher('new_graph', $$
CREATE (:Person {name: 'Daedalus'})-[:FATHER_OF]->(:Person {name: 'Icarus'})
$$) AS (a agtype);
a
---
(0 rows)
-- 显示新创建的表。
SELECT * FROM ag_catalog.ag_label;
name | graph | id | kind | relation | seq_name
------------------+-------+----+------+----------------------------+-------------------------
_ag_label_vertex | 68484 | 1 | v | new_graph._ag_label_vertex | _ag_label_vertex_id_seq
_ag_label_edge | 68484 | 2 | e | new_graph._ag_label_edge | _ag_label_edge_id_seq
Person | 68484 | 3 | v | new_graph."Person" | Person_id_seq
FATHER_OF | 68484 | 4 | e | new_graph."FATHER_OF" | FATHER_OF_id_seq
(4 rows)注意:建议不要在保留图的命名空间中执行 DML 或 DDL 命令。
使用公有云服务
一些公有云的提供了免安装的数据库服务,无需自己部署。以MemFireCloud为例
直接连接
每个MemFire Cloud应用内置一个完整的Postgres数据库,你可以使用任何支持Postgres的工具来连接到数据库。你可以在控制台内的数据库设置中获取连接信息:
- 来到左侧菜单栏的
设置部分 - 点击
数据库 - 启用数据库直连
- 找到应用的
连接信息
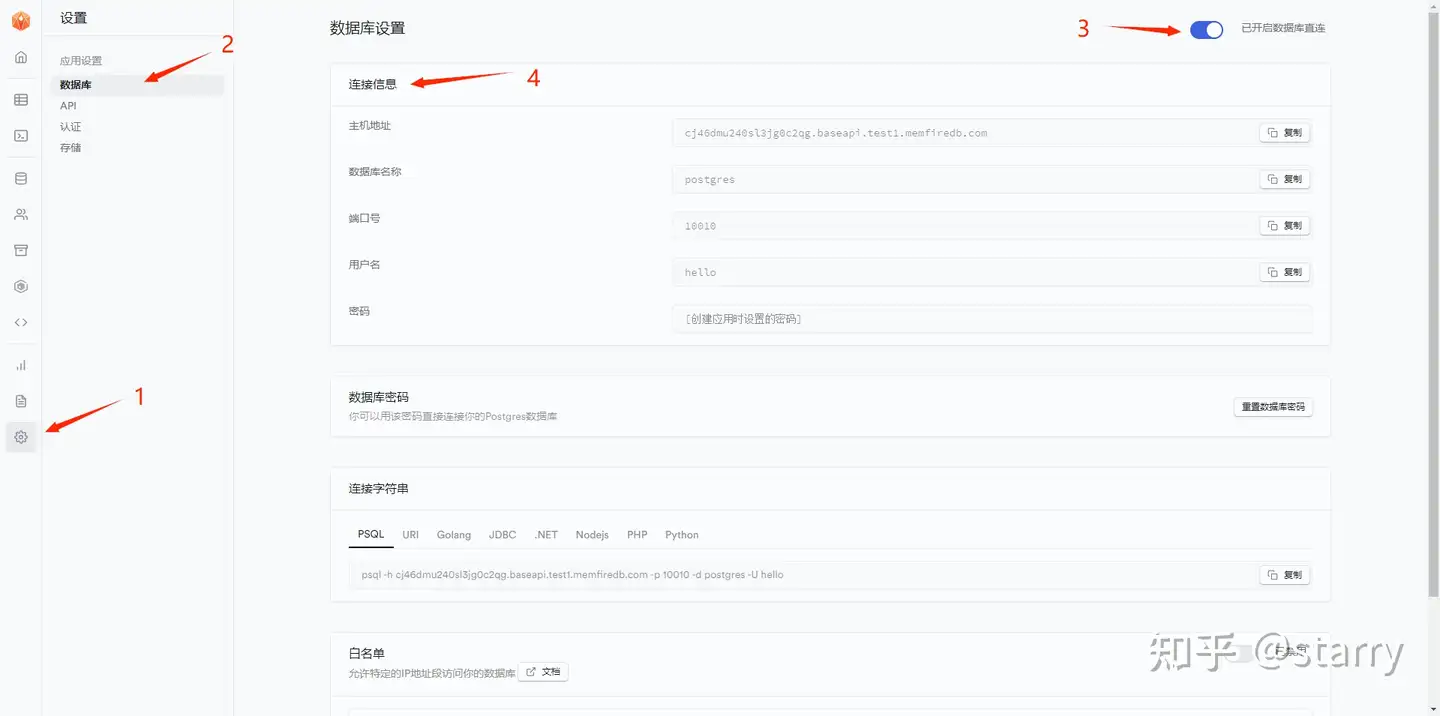
开启直连
白名单
MemFire Cloud内置白名单功能,开启白名单后,只允许白名单内的IP地址段访问你的数据库。关闭白名单后,访问你数据库的IP地址不受限制,即任何IP地址只要有连接信息都可以与你的数据库进行直连。 在进行白名单配置时,要遵循CIDR规则。MemFire Cloud中白名单功能 默认是关闭的,需用户手动开启。
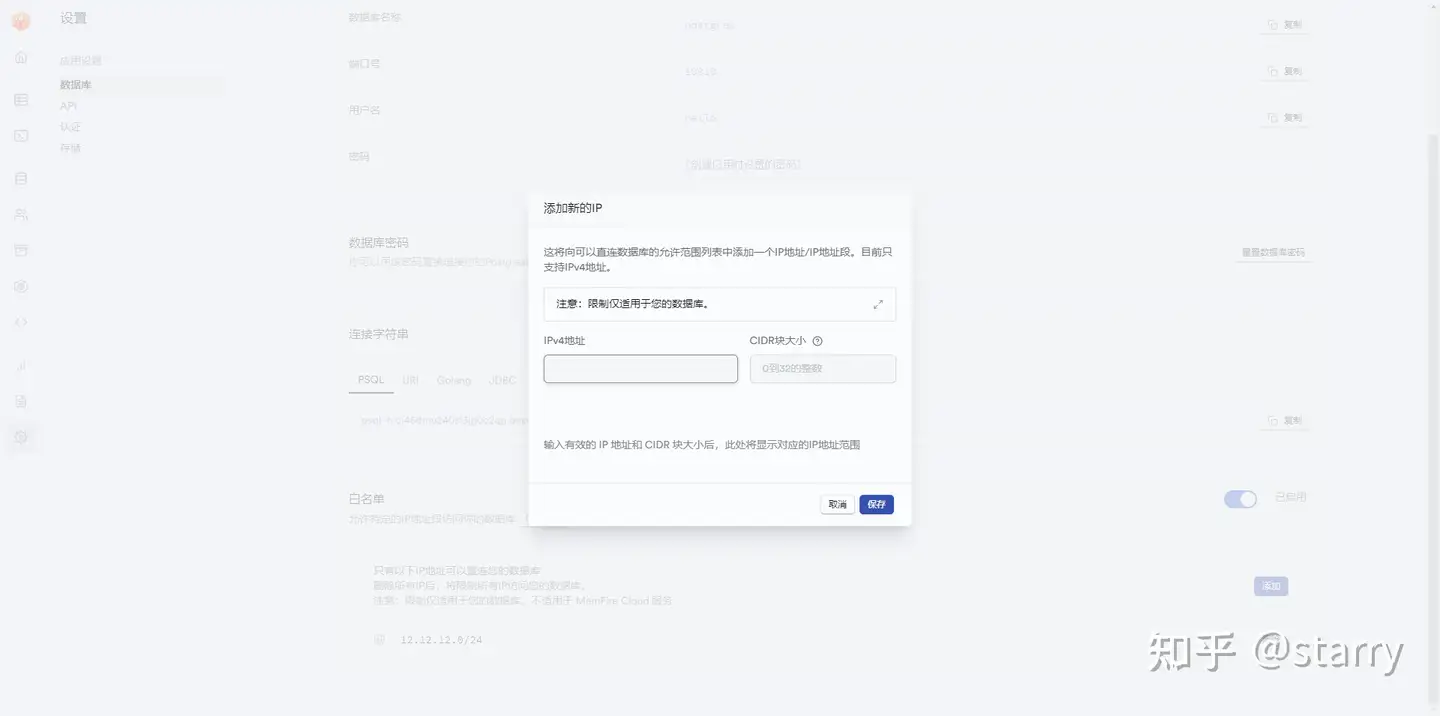
配置白名单
通过数据库客户端连接数据库,可以执行图操作
CREATE EXTENSION age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;