前言
什么是函数式编程?
一句话总结:函数式编程(functional programming)是一种编程范式,之外还有面向对象(OOP)、面向过程、逻辑式编程等。
函数式编程是一种高度抽象的编程范式,它倡导使用纯函数,即那些不依赖于外部状态、没有可变状态的函数。在纯粹的函数式编程语言中,函数的输出完全由输入决定,因此相同的输入总是产生相同的输出 ,这样的函数我们称之为无副作用的。

🔊 一个显著的函数式编程特性是,函数可以作为参数传递给其他函数,或者作为结果被返回,这为编程带来了额外的灵活性和表达力!
Python 提供了对函数式编程的部分支持。
虽然 Python 允许使用变量,使其不完全符合纯函数式编程的标准,但它融合了函数式编程的一些元素,允许开发者在需要时采用函数式编程技术。
函数式编程特点
函数式编程关注的是:describe what to do, rather than how to do it。
围绕这一关键,函数式编程一般具备的特点主要有:
- 函数享有
一等公民的地位,可以被赋值给变量、作为参数传递给其他函数,或作为函数的返回值。 - 函数是
引用透明的,意味着它们的结果仅由输入参数决定,不依赖于外部变量,更不易出错。 - 每个输入参数唯一对应一个输出结果,确保了函数的
确定性。 - 函数应
避免产生副作用,如修改全局状态或依赖外部状态变化。 递归是函数式编程中常用的控制结构,用于替代传统的循环结构。递归的精髓是描述问题,而这正是函数式编程的精髓。
函数式编程不依赖于外部变量,而是返回一个新的值给你,所以没有任何副作用。即保证每次输入的值不变,输出的值一定也不会发生改变。
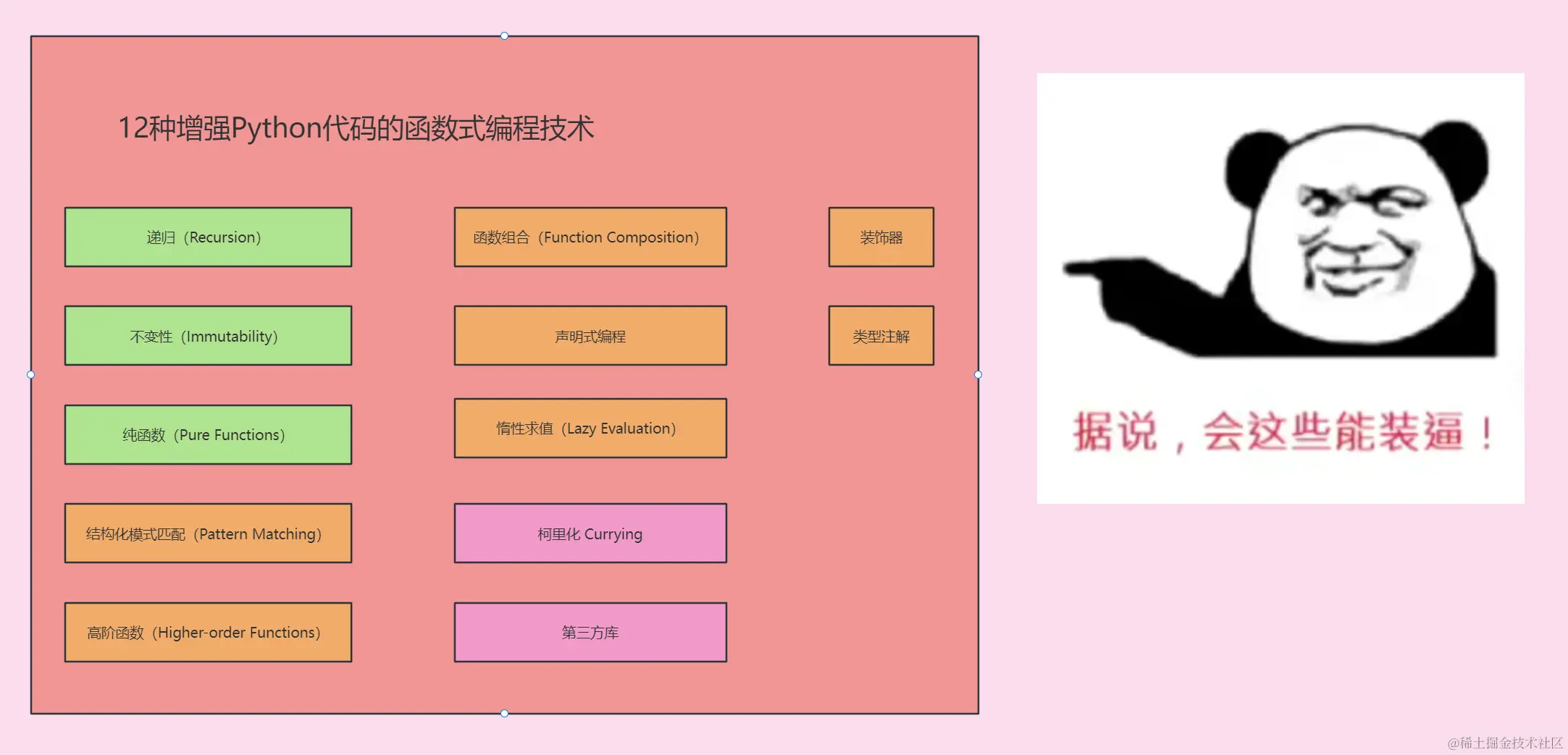
🔊 接下来我们从以上几方面切入,探讨如何增强Python代码的函数式编程技术。
递归(Recursion)
函数式编程倾向于采用递归而非循环来解决问题,这一方法不仅能够清晰地表达问题的本质,还赋予了代码一种简洁而优雅的美感。
那什么是递归呢?
这就是递龟??

开个玩笑~
言归正传,递归函数是指在函数的定义中调用自身的函数。
递归通常由两个部分组成:
- 基准情况(Base Case):递归终止条件,避免无限递归。
- 递归情况(Recursive Case):函数调用自身以解决较小规模的问题。
示例1:快速排序
分而治之:快速排序可以使用递归实现,代码提供清晰的自解释性。
python
def pure_quick_sort(arr):
"""
使用纯快速排序算法对列表进行排序。
该算法选择列表中的一个元素作为基准(pivot),将列表分为三部分:
1. 小于基准的元素;
2. 等于基准的元素;
3. 大于基准的元素。
然后对小于和大于基准的部分分别递归调用排序函数。
参数:
arr: 待排序的列表。
返回值:
排序后的列表。
"""
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return pure_quick_sort(left) + middle + pure_quick_sort(right)
# 调用纯快速排序函数对一组数字进行排序并打印结果
numbers = pure_quick_sort([11, 1, 3, 9, 7, 6, 8, 5, 10, 2, 4])
print(numbers)示例2:二叉树遍历
避免复杂的循环逻辑:二叉树的深度优先遍历(前序遍历)可以使用递归实现。
python
#! -*-conding: UTF-8 -*-
class TreeNode:
"""
二叉树节点类
该类用于构建二叉树的节点结构,每个节点包含一个值以及左右子节点的引用。
"""
def __init__(self, val=0, left=None, right=None):
"""
初始化节点值及左右子节点。
参数:
val: 节点的值,默认为0。
left: 左子节点的引用,默认为None。
right: 右子节点的引用,默认为None。
"""
self.val = val
self.left = left
self.right = right
def preorder_traversal(tree):
"""
前序遍历二叉树。
该函数递归地遍历二叉树,并按照"根-左-右"的顺序打印节点的值。
参数:
tree: 二叉树的根节点。
"""
if tree:
print(tree.val, end=' ')
preorder_traversal(tree.left)
preorder_traversal(tree.right)
# 创建二叉树
# 创建一个二叉树
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
root.left.left = TreeNode(4)
root.left.right = TreeNode(5)
# 进行前序遍历
# 前序遍历
preorder_traversal(root) # 输出:1 2 4 5 3递归通过将复杂问题分解为更小、更易于管理的子问题,极大地简化了编程逻辑,使得解决方案更加直观和易于理解。
不变性(Immutability)
在函数式编程范式中,数据的不可变性是一项核心原则:一旦数据被创建,它便是只读的,其状态在整个生命周期内保持恒定,不会被重新赋值。
函数式编程鼓励不可变性,尽量减少或避免可变状态和副作用。这可以通过使用元组、冻结集合和不可变对象等来实现。
避免可变默认参数
默认参数值应该是不可变的,或者使用None,并在函数内部设置默认值。
python
def append_to_list(element, my_list=None):
if my_list is None:
my_list = []
my_list.append(element)
return my_list使用不变数据类
例如:使用@dataclass装饰器时,可以结合frozen=True参数来创建不可变的数据类。
python
from dataclasses import dataclass
@dataclass(frozen=True)
class MyDataClass:
"""
不可变数据类。
这个类使用了 @dataclass 装饰器,并设置了 frozen=True,
表明这个类是不可变的,即创建后其属性不能被修改。
属性:
attribute: 类的唯一属性,类型为整型(int)。
"""
attribute: int返回新对象而不是修改原始对象
当需要修改数据时,创建一个新的对象,而不是修改现有的对象。
python
def new_list(original_list):
return original_list + [1]
# 测试
original = [1, 2, 3]
print("Original:", original) # 输出原始列表
new = new_list(original)
print("New:", new) # 输出新列表
# 检查原始列表是否被修改
print("Original after new_list call:", original)这种不变性原则大大减少了副作用的发生,因为变量一旦被设定,其值就不会改变。它还简化了并发编程的复杂性,因为不必担心多个线程或进程间的数据竞争问题。此外,不可变性提高了程序的可预测性和可靠性,因为程序状态的变更是清晰和可控的,从而更容易进行推理和维护。
纯函数(Pure Functions)
纯函数定义了一种优雅的计算境界:它们
在给定相同输入值的情况下,始终如一地产生相同的输出结果,并且在整个执行过程中,对程序的状态或全局变量秋毫无犯,不产生任何副作用。
例如,下面是一个非纯函数:
python
# 假设这是一个全局变量,用于存储计数状态
counter = 0
def increment():
global counter
counter += 1
return counter
# 使用示例
print(increment()) # 输出: 1
print(increment()) # 输出: 2纯函数:
python
def increment(counter):
new_counter = counter + 1
return new_counter
# 使用示例
print(increment(0)) # 输出: 1
print(increment(0)) # 输出: 1 在Python中,非纯函数通常指的是那些除了接受输入参数外,还会依赖或修改外部状态的函数。这些函数的输出不仅取决于输入参数,还可能受到外部状态的影响,因此相同的输入在不同时间或不同环境下可能会产生不同的输出。


另外:lambda表达式中不能包含赋值语句,所以它总为纯函数,适⽤于函数式编程。
python
# 一个简单的纯函数lambda表达式,计算两个数字的和
custom_add = lambda x, y: x + y
# 调用lambda表达式
result = custom_add(5, 3)
print(result) # 输出: 8函数式编程的准则:不依赖于外部的数据,而且也不改变外部数据的值,而是返回一个新的值给你。
纯函数的特性不仅使纯函数的行为可预测,而且极大地提升了它们的可理解性、可测试性,以及在并行计算环境中的适用性。纯函数的这些优势,让它们成为构建可靠、高效和可维护软件系统的基石。
前面的快速排序是不是纯函数呢?不是的话怎么修改呢?
结构化模式匹配(Pattern Matching)
Python没有内建的模式匹配语法,但可以使用
match-case语句(Python 3.10+)。
示例1:快速排序
结构化模式匹配使条件更清晰,代码更具声明性。
python
from typing import List
def quick_sort(data: List[int]) -> List[int]:
match data:
case [] | [_]: # 匹配空列表或只有一个元素的列表
return data.copy() # 避免非纯函数
case [pivot, *rest]: # 匹配至少有两个元素的列表,pivot 是第一个元素,rest 是剩余元素
left = [x for x in rest if x <= pivot] # 将小于等于 pivot 的元素放入 left 列表
right = [x for x in rest if x > pivot] # 将大于 pivot 的元素放入 right 列表
return quick_sort(left) + [pivot] + quick_sort(right) # 递归排序 left 和 right,然后合并结果
# 使用示例
list2 = quick_sort([1, 3, 5, 2, 33, 23])
print(list2)示例2:二叉树遍历
python
from dataclasses import dataclass
@dataclass
class TreeNode:
val: int = 0
left: 'TreeNode' = None
right: 'TreeNode' = None
def preorder_traversal(tree: TreeNode):
match tree:
case None:
return # 空树,什么也不做
case TreeNode(val, left, right):
print(val, end=' ')
preorder_traversal(left)
preorder_traversal(right)
# 创建一个二叉树
root = TreeNode(val=1)
root.left = TreeNode(val=2)
root.right = TreeNode(val=3)
root.left.left = TreeNode(val=4)
root.left.right = TreeNode(val=5)
# 前序遍历
preorder_traversal(root) # 输出:1 2 4 5 3高阶函数(Higher-order Functions),函数是一等公民
高阶函数是一种强大的编程构造,它不仅
能够接受其他函数作为输入参数,还能将函数作为结果返回。这种独特的能力使得函数本身可以像数据一样被传递、操作和组合,从而为编程带来了无与伦比的灵活性和表现力。
Python提供了多个内置的高阶函数,这些函数可以接受其他函数作为参数或返回函数作为结果。以下是一些常见的Python内置高阶函数:
-
map(func, *iterables) :
map函数接受一个函数和一个或多个可迭代对象,将函数应用于每个元素,并返回一个新的迭代器。 -
filter(func, iterable) :
filter函数接受一个函数和一个可迭代对象,函数返回布尔值。filter创建一个迭代器,包含所有使得函数返回True的元素。 -
reduce(func, iterable, initializer) :
reduce函数位于functools模块中,它接受一个函数和一个可迭代对象,将函数累积地应用到元素上,返回一个单一的结果;如果提供了initializer,则作为初始累积值。 -
all(iterable) :
all函数接受一个可迭代对象,如果所有元素都为True(或都非零、非空等),则返回True。 -
any(iterable) :
any函数接受一个可迭代对象,如果至少有一个元素为True,则返回True。 -
sorted(iterable, *, key=None, reverse=False) :
sorted函数接受一个可迭代对象,返回一个新的排好序的列表。可以通过key参数指定一个函数,用于从每个元素中提取比较键。 -
enumerate(iterable, start=0) :
enumerate函数接受一个可迭代对象,返回一个包含元素及其索引的迭代器。 -
zip(*iterables) :
zip函数接受一个或多个可迭代对象,返回一个由元组组成的迭代器,每个元组包含来自每个可迭代对象的对应元素。 -
lambda arguments: expression :
lambda是一个匿名函数的声明方式,它可以接受任意数量的参数,并返回单个表达式的值。 -
functools.partial(func, /, *args, **keywords) :
partial函数来自functools模块,它返回一个被调用函数的分区版本,该版本已经用给定参数和关键字参数进行了预填充。 -
functools.lru_cache(maxsize=128, typed=False) :
lru_cache是一个装饰器,可以将函数的结果缓存起来,以加快重复调用的速度。 -
itertools.chain(*iterables) :
chain函数来自itertools模块,它接受一系列可迭代对象,并返回一个迭代器,该迭代器将所有输入的可迭代对象串联起来。 -
itertools.starmap(function, iterable) :
starmap函数接受一个函数和一个可迭代对象,该可迭代对象的元素是多个参数的序列。starmap将这些序列解包并应用函数。
内置的高阶还有很多,他们是Python函数式编程的补充和关键,使代码更加简洁、灵活和表达力强。
Python的
itertools、functools、operator模块中定义了很多⾼阶函数。
示例1,max 函数的应用
Python 的max函数是一个内置函数,用于返回给定参数中的最小值。它可以处理多种类型的参数,包括数字、字符串、元组等,并且可以与一个可选的 key 函数一起使用,以自定义比较的逻辑。
python
# 根据长度找出最长的字符串
words = ['apple', 'banana', 'grape', 'cherry']
longest_word = max(words, key=len)
print(longest_word) # 输出: 'banana'
# 从Python 3.4开始,max 函数接受一个 default 参数,如果你提供了一个空的可迭代对象,max 将返回 default 参数的值。
empty_list = []
result = max(empty_list, default='No items available')
print(result) # 输出: 'No items available'
list1 = [4, 24, 3]
list2 = [4, 5, 6]
max_from_both = max(list1, list2)
print(max_from_both) # 输出: [4, 24, 3]示例2,map 函数的应用
Python 的map函数是一种高阶函数,它接受一个函数和一个或多个可迭代对象作为参数,将指定的函数应用于可迭代对象的每个元素,并返回一个新的迭代器。map函数在函数式编程中非常有用,因为它可以简洁地表达对集合的转换操作。
厌倦了常规循环?试试 map() 函数,让数据处理更加简洁高效:
python
# 将平方函数应用于列表中的每个元素
numbers = [1, 2, 3, 4, 5]
squared_numbers = map(lambda x: x ** 2, numbers)
# map 返回的是一个map对象,可以使用list转换为列表
print(list(squared_numbers)) # 输出: [1, 4, 9, 16, 25]
# 将加法函数应用于两个列表的对应元素
list1 = [1, 2, 3]
list2 = [4, 5, 6]
added = map(lambda x, y: x + y, list1, list2)
print(list(added)) # 输出: [5, 7, 9]示例3,reduce 函数的应用
reduce函数位于functools模块中,它接收一个函数和一个序列,将函数累积地应用到序列的元素上,返回一个单一的结果。reduce可以用于计算序列的累积值,如求和、乘积等。
积微成著,力聚无穷。
python
from functools import reduce
numbers = [1, 2, 3, 4]
result = reduce(lambda x, y: x + y, numbers)
print(result) # 输出: 10示例4,filter 函数的应用
filter函数接收一个函数和一个序列,函数返回布尔值。filter创建一个迭代器,包含所有使得传入函数返回True的元素。
有了filter(),你可以轻松地从一堆数据中挑出符合条件的宝藏:
python
numbers = [1, 2, 3, 4, 5]
even_numbers = filter(lambda x: x % 2 == 0, numbers)
print(list(even_numbers)) # 输出: [2, 4]示例5,偏函数(partial)的应用
Python 的functools模块中包含了一个名为partial的函数,它用于创建一个新的函数,这个新函数是原有函数的变体,可以预设原有函数的一些参数值,而其他参数则在调用时传递。
定制函数,轻松调用:
python
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
from functools import partial
def power(base, exponent):
return base ** exponent
# 创建一个新函数,将 exponent 参数预设为 2
square = partial(power, exponent=2)
# 使用新函数
result = square(base=3) # 相当于 power(3, 2),返回 9
print(result)
# 继续创建一个新函数,将 base 参数预设为 2
square_two = partial(power, base=2)
# 使用新函数
result_two = square_two(exponent=3) # 相当于 power(2, 3),返回 8
print(result_two)示例6:使⽤Python匿名函数
Python 中的匿名函数,也称为lambda函数,是一种简洁的定义函数的方法,它允许你在一个语句中快速创建函数。这种函数没有名称,因此被称为"匿名"。
当你需要一个小巧的函数,而又不想大费周章定义时,lambda闪亮登场。
python
# 使用 lambda
get_first_lambda = lambda x: x[0]
print(get_first_lambda((1, 2, 3))) # 输出: 1示例7:使用operator模块替代匿名函数
模块
operator的作⽤是简化一些简单的匿名函数。例如:可以使⽤operator.add⽅法代替add=lambda a, b: a+b⽅法等。
大G都有了,还自己造啥自行车啊!
python
# 使用 itemgetter
from operator import itemgetter
get_first = itemgetter(0)
print(get_first((1, 2, 3))) # 输出: 1示例8:zip函数的应用
zip()函数是 Python 中的一个内置函数,它接受任意数量的可迭代对象作为输入,然后将这些可迭代对象中的对应元素打包成元组,从而创建一个元组的迭代器。
python
# 当提供的可迭代对象长度不相等时,zip() 函数会以最短的那个为准。多余的元素会被忽略
names = ['海鸽', 'Alice', 'Bob', 'Charlie']
ages = [18, 24, 30]
zipped = zip(names, ages)
print(list(zipped)) # 输出: [('海鸽', 18), ('Alice', 24), ('Bob', 30)]
# 可以将配对的元素解压缩回原来的序列
paired = [(1, 'a'), (2, 'b'), (3, 'c')]
unzipped = zip(*paired) # 解压缩
print(list(unzipped)) # 输出:[(1, 2, 3), ('a', 'b', 'c')]
# 如果你需要保留所有元素,即使某些可迭代对象比其他的短,你可以使用 itertools.zip_longest() 函数,它会填充缺失的值
from itertools import zip_longest
zipped = zip_longest(names, ages, fillvalue=18)
print(list(zipped)) # 输出: [('海鸽', 18), ('Alice', 24), ('Bob', 30), ('Charlie', 18)]示例9: 方法的偏函数partialmethod
Python3.4开始添加了partialmethod函数,作用类似于partial函数,但仅作用于方法。
functools.partialmethod是 Python 的functools模块中提供的一种特殊工具,用于创建部分应用方法(即绑定默认值给方法的一部分参数)。这个特性在类的方法中特别有用,允许你在类的上下文中创建方法的变体,其中某些参数已经被预设。
python
#!usr/bin/env python
# -*- coding:utf-8 _*-
# __author__:海哥Python
from functools import partialmethod
class Logger:
"""
使用functools.partialmethod实现日志记录器
"""
def log(self, level, message):
print(f"[{level}] {message}")
info = partialmethod(log, 'INFO')
warning = partialmethod(log, 'WARNING')
error = partialmethod(log, 'ERROR')
logger = Logger()
logger.info("This is an informational message.")
logger.warning("This is a warning message.")
logger.error("This is an error message.")通过高阶函数,我们可以构建更加抽象和强大的代码结构,它们不仅易于复用,而且能够以声明式的方式表达复杂的逻辑,让代码更加简洁和富有表现力。
函数式编程的代码更注重描述要干什么,而不是怎么干,这种声明式的具有更强的自解释性,使代码更易读,即:describe what to do, rather than how to do it。
柯里化 Currying
柯里化(Currying)是一种将函数转换的技术,在函数式编程中非常常见。它涉及到将一个接受多个参数的函数转换为一系列嵌套的函数,每个函数只接受一个参数。这种转换允许函数调用时可以逐步提供参数,而不是一次性提供所有参数。
具体来说,柯里化将一个函数f(a, b, c)转换为一个形式为f(a)(b)(c)的函数,其中每个括号内的函数调用只接收原函数的一个参数。这样做的好处包括:
- 灵活性:函数可以被部分应用,意味着可以先传递一些参数,稍后再传递剩余的参数。
- 重用:部分应用的函数可以被多次使用,每次只需传递剩余的参数即可,这有助于代码的复用。
- 组合:柯里化的函数更容易与其他函数组合,构建更复杂的函数。
柯里化得名于逻辑学家哈斯凯尔·加里(Haskell Curry),但实际上是由 Moses Schönfinkel 和戈特洛布·弗雷格(Gottlob Frege)首先提出的。在现代编程语言中,如 Haskell、JavaScript 和 Python(使用第三方库如toolz或内置函数如functools.partial)中,柯里化是一个常见的概念和编程技术。
使用functools.partial实现柯里化
例如,在 Python 中,使用functools.partial可以实现类似柯里化的效果:
python
from functools import partial
def add(a, b):
return a + b
add_5 = partial(add, 5) # 这里实现了部分应用,add_5 现在是一个只接受一个参数的函数
print(add_5(10)) # 输出: 15然而,真正的柯里化会涉及函数的连续调用,如下所示:
python
def curried_add(a):
def inner(b):
return a + b
return inner
add_5 = curried_add(5)
print(add_5(10)) # 输出: 15或者在一个函数中实现完整的柯里化:
python
def curried_add(a):
return lambda b: a + b
add_5 = curried_add(5)
print(add_5(10)) # 输出: 15在上述例子中,curried_add函数接受一个参数a并返回一个新的函数,这个新函数接受参数 b 并返回a + b的结果。这就是柯里化的基本思想。
使用toolz.curry实现柯里化
toolz是一个 Python 库,它提供了函数式编程工具,包括 curry 函数,用于创建柯里化(Currying)的函数。
柯里化是指将多参数函数转换为一系列单参数函数的过程。
python
#!usr/bin/env python
# -*- coding:utf-8 _*-
# __author__:Python
# __time__:2024/7/7
from toolz import curry
# 使用装饰器方式柯里化函数
@curry
def multiply(a, b):
return a * b
# 使用 curry() 函数柯里化函数
multiply_curried = curry(lambda a, b: a * b)
# 一次性传递所有参数
print(multiply(2, 3)) # 输出 6
print(multiply_curried(2, 3)) # 输出 6
# 逐步传递参数
double = multiply(2) # 创建一个新函数,固定a为2
result = double(3) # 调用新函数,结果为6
print(result)
# 或者
triple = multiply_curried(3) # 创建一个新函数,固定a为3
result = triple(2) # 调用新函数,结果为6
print(result)这样,multiply和multiply_curried就可以作为柯里化函数使用,允许你以灵活的方式调用它们。
toolz 库中的 curry 功能与 Python 标准库 functools 中的 partial 功能都是为了使函数调用更加灵活,但是它们之间有一些关键的区别:
- functools.partial 主要用于"绑定"函数的一部分参数 ,从而创建一个新的函数,这个新函数在调用时只需要传入剩下的参数即可。
partial不会改变函数的签名,它只是预填充了一些参数。 - toolz.curry 实现的是柯里化(Currying),这是一种函数式编程的概念,它允许你将一个多参数函数转化为一系列的单参数函数。这意味着你可以逐步应用参数,直到所有的参数都被提供后才进行计算。
- 应用场景 :
partial更适合需要固定某些参数的场景;curry则更适合需要链式调用或逐步构建函数的情况。
装饰器,为函数扩展额外的功能
把某个函数加上装饰器后,就可以为函数扩展额外的功能。本质上就是把函数作为参数传递的过程,如:
python
def log_decorator(func):
def wrapper(*args, **kwargs):
print(f"Calling function: {func.__name__}")
result = func(*args, **kwargs)
print(f"{func.__name__} returned {result}")
return result
return wrapper
@log_decorator
def add(a, b):
return a + b
print(add(3, 4))
# 输出:
# Calling function: add
# add returned 7
# 7函数组合(Function Composition)
函数组合是一种优雅的编程技巧,它通过串联多个函数,形成一个工作流,从而生成一个全新的函数。这种技巧涉及将一个函数的输出直接"传递"给下一个函数作为输入,一层接一层,像搭积木一样构建起复杂的处理逻辑。
嵌套函数调用,简单pipeline实现
函数组合通常通过将一个函数的输出作为另一个函数的输入来实现。在Python中,你可以使用嵌套函数调用来完成这一点。
python
def add_one(x):
return x + 1
def multiply_by_two(x):
return x * 2
# 组合两个函数
def compose(f, g):
return lambda x: f(g(x))
# 创建一个组合函数,先执行 multiply_by_two,然后执行 add_one
composed_function = compose(add_one, multiply_by_two)
# 使用组合函数
result = composed_function(3) # 相当于 (3 * 2) + 1
print(result) # 输出: 7更灵活的pipline实现
如下程序,提供一种实现pipeline效果更灵活、优雅的方案:
- 将列表元素先乘以
2 - 将列表元素再加
10
python
from typing import List, Callable
from functools import partial, reduce
# 不咋地道的组合方式:
# def compose(*functions):
# def composed(value):
# for fn in functions:
# value = fn(value)
# print(value)
# print("---------")
# return value
#
# return composed
# 定义一个类型别名,用于类型注解
Composable = Callable[[List[int]], List[int]]
# 更地道的组合方式:
def compose(*functions: Composable) -> Composable:
def apply(value: List[int], fn: Composable) -> List[int]:
return fn(value)
return lambda data: reduce(apply, functions, data)
# 修改函数以只接受一个参数(列表)
def add_x(data: List[int], x: int) -> List[int]:
print("add_x ...")
# return list(map(lambda y: y + x, data))
return [y + x for y in data] # 使用列表推导式
def multiply_by_x(data: List[int], x: int) -> List[int]:
print("multiply_by_x ...")
# return list(map(lambda y: y * x, data))
return [y * x for y in data] # 使用列表推导式
# 使用 partial 预先绑定参数
multiply_by_2 = partial(multiply_by_x, x=2)
add_10 = partial(add_x, x=10)
# 正确地组合函数
do_operations = compose(multiply_by_2, add_10) # 注意参数的顺序
resource_data = [1, 9, 3, 5, 2]
result = do_operations(resource_data)
print(result) # 输出: [12, 28, 16, 20, 14]
print("----------compose_right_to_left---------------")
def compose_right_to_left(*functions):
return compose(*reversed(functions))
# 使用从右到左的 compose
do_operations_right_to_left = compose_right_to_left(multiply_by_2, add_10)
result_right_to_left = do_operations_right_to_left(resource_data)
print(result_right_to_left) # 输出: 22, 38, 26, 30, 24],这是先加 10 再乘以 2 的结果shell风格的python pipeline
利用函数式编程,我们也能简单实现shell风格的python pipeline。
python
#!usr/bin/env python
# -*- coding:utf-8 _*-
# __author__:网友S142857
# __time__:2024/7/7
class Pipe(object):
"""
管道类,用于实现函数管道操作。
通过将函数封装在Pipe实例中,可以使用'|'操作符连接多个函数,形成一个处理管道。
"""
def __init__(self, func):
"""
初始化管道对象。
参数:
func - 要封装的函数。
"""
self.func = func
def __ror__(self, other):
"""
实现管道操作的重载操作符。
参数:
other - 要与当前Pipe实例连接的可迭代对象。
返回:
一个生成器,用于逐个处理other中的元素,并应用func函数。
"""
def generator():
for obj in other:
if obj is not None:
yield self.func(obj)
return generator()
@Pipe
def even_filter(num):
"""
过滤器函数,保留偶数,过滤掉奇数。
参数:
num - 要检查的数字。
返回:
如果num是偶数,则返回num;否则返回None。
"""
return num if num % 2 == 0 else None
@Pipe
def multiply_by_three(num):
"""
数字乘以三的函数。
参数:
num - 要乘以3的数字。
返回:
num乘以3的结果。
"""
return num * 3
@Pipe
def convert_to_string(num):
"""
将数字转换为字符串的函数。
参数:
num - 要转换的数字。
返回:
包含数字的字符串。
"""
return 'The Number: %s' % num
@Pipe
def echo(item):
"""
打印项目的函数。
参数:
item - 要打印的项目。
返回:
item本身,用于管道继续传递。
"""
print(item)
return item
def force(sqs):
"""
用于强制执行管道的函数。
参数:
sqs - 一个可迭代对象,通常是一个管道。
该函数遍历sqs,但不返回任何值,主要用于触发管道中的操作。
"""
for _ in sqs:
pass
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
#
force(nums | even_filter | multiply_by_three | convert_to_string | echo)
# 管道操作的另一种用法,直接遍历管道结果
# for _ in nums | even_filter | multiply_by_three | convert_to_string | echo:
# pass # 或者对输出执行其他任何操作
# 输出:
# The Number: 6
# The Number: 12
# The Number: 18
# The Number: 24
# The Number: 30函数式编程在一定程度上是关于构建一个通用的、可重用的、可组合的函数库:

合理的利用函数组合进行函数式编程不仅可以使代码保持模块化,而且通过减少中间变量和冗余步骤,可以增强代码的简洁性和可读性,提升代码的复用性,让逻辑的构建变得直观而高效。
声明式编程,而不是命令式编程
声明式编程(Declarative Programming )描述"要做什么"而不是"怎么做",通常更易于维护和更新。
假设现在我们在写这样一个程序:有3辆车,掷筛子前进,共5轮,每轮每辆车都能掷筛子,每次有70%的概率向前移动一步的过程。经过5轮后,比赛结束并打印结果。
我们很容易就能写出下面这样的命令式编程代码:
python
from random import random
time = 5
car_positions = [1, 1, 1]
while time:
# decrease time
time -= 1
print('')
for i in range(len(car_positions)):
# move car
if random() > 0.3:
car_positions[i] += 1
# draw car
print('*' * car_positions[i])
print(car_positions)代码是命令式编写的,更多是讲述了如何做。如果只扫一眼代码,我们很难直观的知道他要做什么。
而使程序更具声明式则是使代码更具可读性的一种很好的、低脑力的方法。
python
import copy
from random import random
def move_car(position, move_chance):
"""根据给定的概率移动汽车位置。"""
return position + 1 if random() <= move_chance else position
def draw_car(position):
"""绘制汽车在当前位置的图形表示。"""
print('*' * position)
def simulate_race(car_positions, move_chance, steps):
"""模拟赛车比赛,打印每一步的结果。"""
new_positions = copy.copy(car_positions)
for _ in range(steps):
new_positions = [move_car(pos, move_chance) for pos in new_positions]
for pos in new_positions:
draw_car(pos)
print(new_positions)
# 初始设置
MOVE_CHANCE = 0.7 # 70%的概率向前移动
STEPS = 5 # 总步数
CAR_POSITIONS = [1, 1, 1] # 初始位置
# 运行模拟
simulate_race(CAR_POSITIONS, MOVE_CHANCE, STEPS)修改后的代码明显更加清晰可读。
递归的本质就是描述问题是什么。使用递归取代for循环,某种程度下可以实现更纯粹的函数式编程。
python
from random import random
def move_cars(car_positions: list):
return list(map(lambda x: x + 1 if random() > 0.3 else x, car_positions))
def output_car(car_position: int):
return '*' * car_position
def run_step_of_race(state: dict):
new_positions = move_cars(state['car_positions'])
print(new_positions)
return {'time': state['time'] - 1, 'car_positions': new_positions}
def draw(state: dict):
print(f"Time: {state['time']}")
print('\n'.join(map(output_car, state['car_positions'])))
def race(state):
if state['time'] > 0:
draw(state)
race(run_step_of_race(state)) # Tail recursion
race({'time': 5, 'car_positions': [1, 1, 1]}) # 初始位置改为0惰性求值(Lazy Evaluation),需要数据时才返回数据
在函数式编程中,惰性求值(Lazy Evaluation)是一种计算策略,其中
表达式的求值被推迟到其结果真正需要时才进行。这意味着某些计算可能会延迟执行,直到它们对于程序的其余部分变得必要。
"短路"运算符
Python中,逻辑运算符and、or是惰性求值的。
- and :当使用
and时,如果第一个操作数是False(例如,0、None、False、空序列等),则不会计算第二个操作数,整个表达式的结果就是第一个操作数。 - or :当使用
or时,如果第一个操作数是True,同样不会计算第二个操作数,整个表达式的结果就是第一个操作数。
python
>>> 0 and print("Python")
0
>>> True and print("Python")
Python生成器表达式和生成器函数
Python的⽣成器表达式和⽣成器函数是惰性的,在求值时,这些表达式不会⻢上计算出所有的可能结果。
按需生产,内存友好:
python
# 1. 生成器表达式
from typing import List, Iterable, Callable
from functools import partial, reduce
# 定义一个类型别名,用于类型注解
Composable = Callable[[List[int] | Iterable[int]], List[int]]
def compose(*functions: Composable) -> Composable:
def apply(value: List[int] | Iterable[int], fn: Composable) -> Iterable[int]:
return fn(value)
return lambda data: reduce(apply, functions, data)
# 修改函数以只接受一个参数(列表)
def add_x(data: List[int] | Iterable[int], x: int) -> Iterable[int]:
print("add_x ...")
return (item + x for item in data)
def multiply_by_x(data: List[int] | Iterable[int], x: int) -> Iterable[int]:
print("multiply_by_x ...")
return (item * x for item in data)
# 使用 partial 预先绑定参数
multiply_by_2 = partial(multiply_by_x, x=2)
add_10 = partial(add_x, x=10)
# 正确地组合函数
do_operations = compose(multiply_by_2, add_10) # 注意参数的顺序
resource_data = [1, 9, 3, 5, 2]
result = do_operations(resource_data)
print(list(result)) # 输出: [12, 28, 16, 20, 14]
print("----------compose_right_to_left---------------")
def compose_right_to_left(*functions):
return compose(*reversed(functions))
# 使用从右到左的 compose
do_operations_right_to_left = compose_right_to_left(multiply_by_2, add_10)
result_right_to_left = do_operations_right_to_left(resource_data)
print(result_right_to_left) # <generator object multiply_by_x.<locals>.<genexpr> at 0x0000021469D399A0>
for i in result_right_to_left:
print(i) # 输出: 22, 38, 26, 30, 24],这是先加 10 再乘以 2 的结果
# 2. 生成器函数
def fibonacci_sequence(n):
a, b = 0, 1
for _ in range(n):
yield a
a, b = b, a + b
# 使用生成器打印前5个斐波那契数
for fib_num in fibonacci_sequence(5):
print(fib_num)类型注解,聊胜于无
类型注解在一定程度上也能提高函数式编程代码可读性和可维护。
python
#!usr/bin/env python
# -*- coding:utf-8 _*-
# __author__:海哥Python
from typing import List, Tuple
from itertools import zip_longest
names: List[str] = ['海鸽', 'Alice', 'Bob', 'Charlie']
ages: List[int] = [18, 24, 30]
# 使用类型注解的 zipped
zipped: List[Tuple[str, int]] = list(zip(names, ages))
print(zipped) # 输出:[('海鸽', 18), ('Alice', 24), ('Bob', 30)]
# 使用类型注解的 unzipped
unzipped: List[Tuple[str, int]] = list(zip(*zipped))
print(unzipped) # 输出:[('海鸽', 'Alice', 'Bob'), (18, 24, 30)]
# 使用类型注解的 zip_longest()
zipped_longest: List[Tuple[str, int]] = list(zip_longest(names, ages, fillvalue=18))
print(zipped_longest) # 输出: [('海鸽', 18), ('Alice', 24), ('Bob', 30), ('Charlie', 18)]第三方库
如果对原生函数式编程不满足,可使用第三方库提供的语法糖简化代码。
python
#!usr/bin/env python
# -*- coding:utf-8 _*-
# __author__:公众号:海哥Python
# __time__:2024/7/7
from funcy import walk_values, ignore
d = {}
request = {
'age': 18,
'height': '180',
'weight': ""
}
for k, v in request.items():
try:
d[k] = int(v)
except (TypeError, ValueError):
d[k] = 0
print(d) # {'age': 18, 'height': 180, 'weight': 0}
# 可以使用funcy简化上面的代码
dd = walk_values(ignore((TypeError, ValueError), default=0)(int), request)
print(dd) # {'age': 18, 'height': 180, 'weight': 0}fancy库:一系列专注于实用性的花哨FP功能工具。
安装:
python
pip install funcy遍历集合,创建其转换(如 map,但保留类型):
python
from funcy import walk, walk_keys, walk_values
# 定义 double 和 inc 函数
def double(x):
return x * 2
def inc(x):
return x + 1
# 示例代码
print(walk(str.upper, {'a', 'b'})) # 输出: {'A', 'B'}
print(walk(reversed, {'a': 1, 'b': 2})) # 输出: {1: 'a', 2: 'b'}
print(walk_keys(double, {'a': 1, 'b': 2})) # 输出: {'aa': 1, 'bb': 2}
print(walk_values(inc, {'a': 1, 'b': 2})) # 输出: {'a': 2, 'b': 3}选择集合的一部分:
python
from funcy import compact, select_keys, select
def even(n):
"""判断给定的整数是否为偶数。
参数:
n (int): 需要判断的整数。
返回:
bool: 如果n是偶数返回True,否则返回False。
"""
return n % 2 == 0
# 使用select函数过滤出集合中满足even条件的元素(即偶数)
# 注意:此处的even应是一个函数,用于判断数字是否为偶数,但在示例中未给出具体实现
# 示例输出: {2, 10, 20}
print(select(even, {1, 2, 3, 10, 20}))
# 使用select函数筛选出元组中以'a'开头的字符串
# 示例输出: ('a', 'ab')
print(select(r'^a', ('a', 'b', 'ab', 'ba')))
# 使用select_keys函数选择字典中值为可调用对象的键值对
# 示例输出: {<class 'str'>: ''}
print(select_keys(callable, {str: '', None: None}))
# 使用compact函数移除集合中的None和0值
# 注意:在Python中,集合不能包含0和None,因此实际输出可能与预期不同
# 示例输出: {1, 2}
print(compact({2, None, 1, 0}))fancy库的功能远不止这些,感兴趣的小伙伴可以自行翻读其官方文档。
fn.py: 在 Python 中享受函数式编程
fn.py是一个Python库,它提供了函数式编程的一些特性,如柯里化(Currying)、函数组合、偏函数(Partial application)等。这个库旨在让函数式编程风格更容易融入到Python的命令式编程中。
安装 fn.py
首先,你需要通过pip安装fn.py库:
python
pip install fn.py使用 fn.py
一旦安装完成,你可以开始使用fn.py中的功能。以下是一些基本的使用示例:
- 柯里化(Currying) 柯里化允许你将接受多个参数的函数转换为一系列接受单个参数的函数。
python
from fn.func import curried
# 使用装饰器@curried,将函数sum5转换为一个可部分应用的函数
# 该函数接受五个参数,并返回它们的总和
# 通过逐步调用这个函数并传递参数,可以最后得到五个参数的和
@curried
def sum5(a, b, c, d, e):
return a + b + c + d + e
# 调用sum5函数,通过连续调用传递参数
# 展示了curried函数的使用,可以分步传递参数
print(sum5(1)(2)(3)(4)(5)) # 15
# 展示了另一种调用curried函数的方式,可以一次性传递多个参数
print(sum5(1, 2, 3)(4, 5)) # 15- 函数组合
fn.py支持函数组合,可以使用>>和<<操作符来链接函数,这类似于Unix shell的管道操作。
python
from fn import F
# 定义函数
double = F(lambda x: x * 2)
increment = F(lambda x: x + 1)
# 组合函数
pipeline = double >> increment
# 使用组合后的函数
result = pipeline(5) # 结果为 11
print(result)- 提供避免大量
if-else的链式调用思路
假设我们有一个名为Request的类,继承自dict,我们会对处理请求参数做一系列操作,如下:
python
class Request(dict):
"""
请求类,继承自字典,用于处理请求中的参数。
该类旨在提供一种简洁的方法来获取请求中的特定参数,
并对参数进行基本的处理,如去除空白字符和转换为大写。
"""
def parameter(self, name):
"""
获取请求参数的值。
如果参数不存在,则返回None。
参数:
name: 参数的名称。
返回:
参数的值,如果不存在则为None。
"""
return self.get(name, None)
# 初始化一个Request实例
r = Request(testing=" Fixed ", empty=" ")
# 通过parameter方法获取参数testing的值
param = r.parameter("testing")
# 根据参数值的存在与否及内容进行处理
if param is None:
fixed = ""
else:
param = param.strip()
if len(param) == 0:
fixed = ""
else:
fixed = param.upper()
# 输出处理后的参数值
print(fixed) # FIXED
print(len(fixed)) # 5这样处理略显丑陋。fn.py则为我们带来另一种参考:
python
from operator import methodcaller
from fn.monad import optionable
class Request(dict):
"""
表示一个HTTP请求的类,继承自dict,用于方便地访问请求参数。
方法:
- parameter: 以可选方式获取请求参数,如果参数不存在,则返回None。
"""
@optionable
def parameter(self, name):
"""
尝试获取请求中的参数值。
参数:
- name: 参数的名称。
返回:
- 如果参数存在,则返回参数值;否则返回None。
"""
return self.get(name, None)
# 创建一个Request实例,并初始化一些参数
r = Request(testing=" Fixed ", empty=" ")
# 输出参数"testing"的长度
print(len(r.get("testing"))) # 7
# 通过一系列的map和filter操作,处理参数"testing"的值,去除空格,转换为大写,如果结果非空则返回,否则返回空字符串
fixed = r.parameter("testing").map(methodcaller("strip")).filter(len).map(methodcaller("upper")).get_or("")
print(fixed) # FIXED
print(len(fixed)) # 5
r2 = Request(testing=" ", empty=" ")
fixed2 = r2.parameter("testing").map(methodcaller("strip")).filter(len).map(methodcaller("upper")).get_or("")
print(fixed2) # ""parameter 方法使用了 optionable 装饰器,使其支持链式调用。
以上是fn.py库的一些基本使用示例。你可以根据实际需求,探索更多的函数和特性。在使用fn.py时,建议查阅官方文档或源代码以获得更详细的说明和示例。
PyFunctional库:用于使用链函数式编程创建数据管道的 Python 库
pyfunctional库是Python中用于函数式编程的工具包,它提供了一系列的功能,如映射(map)、过滤(filter)、折叠(fold/reduce)等,以帮助你以函数式的方式处理数据。
安装
首先,确保你已经安装了pyfunctional库。如果尚未安装,可以通过以下命令安装:
python
pip install pyfunctional使用场景
一旦安装完成,你可以开始使用pyfunctional库。
python
# 过滤账户交易的列表
from collections import namedtuple
from functional import seq
Transaction = namedtuple('Transaction', 'reason amount')
# 初始化一个交易列表,包含多个交易实例
transactions = [
Transaction('github', 7),
Transaction('food', 10),
Transaction('coffee', 5),
Transaction('digitalocean', 5),
Transaction('food', 5),
Transaction('riotgames', 25),
Transaction('food', 10),
Transaction('amazon', 200),
Transaction('paycheck', -1000)
]
# 使用函数式编程风格,过滤出所有食品交易并计算总金额
# 使用Scala/Spark风格的API
food_cost = seq(transactions) \
.filter(lambda x: x.reason == 'food') \
.map(lambda x: x.amount).sum()
print(food_cost) # 25
# 使用LINQ(Language Integrated Query)风格的API
food_cost2 = seq(transactions) \
.where(lambda x: x.reason == 'food') \
.select(lambda x: x.amount).sum()
print(food_cost2) # 25
# 使用fn模块的函数式编程风格,过滤出所有食品交易并计算总金额
from fn import _
# 验证filter操作
filtered_transactions = seq(transactions).filter(_.reason == 'food')
# 验证map操作
mapped_amounts = filtered_transactions.map(_.amount)
# 验证sum操作
food_cost3 = mapped_amounts.sum()
# 检查过滤后的交易
print(list(filtered_transactions))
print(list(mapped_amounts)) # 检查映射后的金额 [10, 5, 10]
print(food_cost3) # 最终结果 25PyFunctional的主要特性是它的seq类,它允许你以一种链式调用的方式处理序列。
更多高级功能和详细文档,可以参考PyFunctional的官方文档。
小结
函数式编程风格以其代码的简洁、可读和可复用性而著称。但在Python中,过分偏向函数式编程并不总是最佳选择。Python的设计哲学并非基于纯粹的函数式编程,而是采用了一种包容性的多范式方法,赋予开发者自由选择最适合手头任务的工具和技术的灵活性。因此,在采纳函数式编程风格时,我们应该追求清晰性与效率之间的平衡,以确保代码既优雅又高效。
作者:暴走的海鸽