Hadoop权威指南-读书笔记
记录一下读这本书的时候觉得有意思或者重要的点~

第一章---初识Hadoop

Tips: 这个引例很有哲理嘻嘻😄,道出了分布式的灵魂。
1.1 数据!数据!
这一小节主要介绍了进入大数据时代,面临数据量飙升的问题,我们该如何管理好自己的数据,或者说如何利用好规模如此庞大的数据。

博主摘录了一些原文:
-
有句话说得好: "大数据胜于好算法。" 意思是说对于某些应用(譬如根据以往的偏好来推荐电影和音乐),不论算法有多牛,基于小数据的推荐效果往往都不如基于大量可用数据的一般算法的推荐效果。(
More Data usually beats better algorithms) -
现在,我们已经有了大量数据,这是个好消息。但不幸的是,我们必须想方设法好好地存储和分析这些数据。
More Data usually beats better algorithms,这个观点博主认为很有意思🤣
1.2 数据的存储与分析
这里博主就直接记录一下原文比较值得思考的片段了哈 ~
- 我们遇到的问题很简单:在硬盘存储容量多年来不断提升的同时,访问速度(硬盘数据读取速度)却没有与时俱进。
Tips:这里并非说多年来硬盘的读取速度没有提升,而是硬盘的读取速度的提升相对于硬盘容量的提升还有差距。
这里文章有一个小例子大家可以看一下:1990年,一个普通硬盘可以存储1370MB数据,传输速度为4.4MB/S,因此只需要5分钟就可以读完整个硬盘中的数据。20年过去了,1TB的硬盘成为主流,但其数据传输速度约为100MB/,读完整个硬盘中的数据至少得花2.5个小时。
-
一个很简单的减少读取时间的办法是同时从多个硬盘上读数据。试想,如果我们有100个硬盘,每个硬盘存储1%的数据,并行读取,那么不到两分钟就可以读完所有数据。
Tips:分布式的思想初见雏形
-
仅使用硬盘容量的1%似乎很浪费。但是我们可以存储100个数据集,每个数据集1TB,并实现共享硬盘的读取。可以想象,用户肯定很乐于通过硬盘共享来缩短数据分析时间;并且,从统计角度来看,用户的分析工作都是在不同时间点进行的,所以彼此之间的干扰并不太大。
-
虽然如此,但要对多个硬盘中的数据并行进行读/写数据,还有更多问题要解决。
-
第一个需要解决的是硬件故障问题。一旦开始使用多个硬件,其中个别硬件就很有可能发生故障。为了避免数据丢失,最常见的做法是复制(replication):系统保存数据的复本(replica),一旦有系统发生故障,就可以使用另外保存的复本。
-
第二个问题是大多数分析任务需要以某种方式结合大部分数据来共同完成分析,即从一个硬盘读取的数据可能需要与从另外99个硬盘中读取的数据结合使用。
-
各种分布式系统允许结合不同来源的数据进行分析,但保证其正确性是一个非常大的挑战。MapReduce提出一个编程模型,该模型抽象出这些硬盘读/写问题并将其转换为对一个数据集(由键-值对组成)的计算。
1.3 查询所有的数据
- MapReduce看似采用了一种蛮力方法。每个查询需要处理整个数据集或至少一个数据集的绝大部分。但反过来想,这也正是它的能力。
- MapReduce是一个批量查询处理器,能够在合理的时间范围内处理针对整个数据集的动态查询。
- 它改变了我们对数据的传统看法,解放了以前只是保存在磁带和硬盘上的数据。
- 它让我们有机会对数据进行创新。
- 以前需要很长时间处理才能获得结果的问题,到现在变得顷刻之间就迎刃而解,同时还可以引发新的问题和新的见解。
这里文中提到了一个运用MR处理数据的例子:
- Rackspace公司的邮件部门Mailtrust就用Hadoop来处理邮件日志。
- 他们写了一条特别的查询用于帮助找出用户的地理分布。
- 他们是这么描述的:"这些数据非常有用,我们每月运行一次MapReduce任务来帮助我们决定扩容时将新的邮件服务器放在哪些Rackspace数据中心。"
- 通过整合好几百GB的数据,用工具来分析这些数据,Rackspace的工程师能够对以往没有注意到的数据有所理解,甚至还运用这些信息来改善现有的服务。
Tips:挖掘海量数据的信息并服务于业务,使得业务更好的发展。
1.4 不仅仅是批处理
- 从MapReduce的所有长处来看,它基本上是一个批处理系统,并不适合交互式分析。
- 你不可能执行一条查询并在几秒内或更短的时间内得到结果。
- 典型情况下执行查询需要几分钟或更多时间。因此,MapReduce更适合那种没有用户在现场等待查询结果的离线使用场景。
- 然而,从最初的原型出现以来,Hadoop的发展已经超越了批处理本身。
- 实际上,名词"Hadoop"有时被用于指代一个更大的、多个项目组成的生态系统,而不仅仅是HDFS和MapReduce。
- 这些项目都属于分布式计算和大规模数据处理范畴。这些项目中有许多都是由Apache软件基金会管理,该基金会为开源软件项目社区提供支持,其中包括最初的HTTPserver项目(基金会的名称也来源于这个项目)。
- 第一个提供在线访问的组件是HBase,一种使用HDFS做底层存储的键值存储模型。
- HBase不仅提供对单行的在线读/写访问,还提供对数据块读/写的批操作。
- Hadoop2中YARN(
Yet Another Resource Negotiator)的出现意味着 Hadoop 有了新处理模型。 - YARN是一个集群资源管理系统,允许任何一个分布式程序(不仅仅是MapReduce)基于 Hadoop 集群的数据而运行。
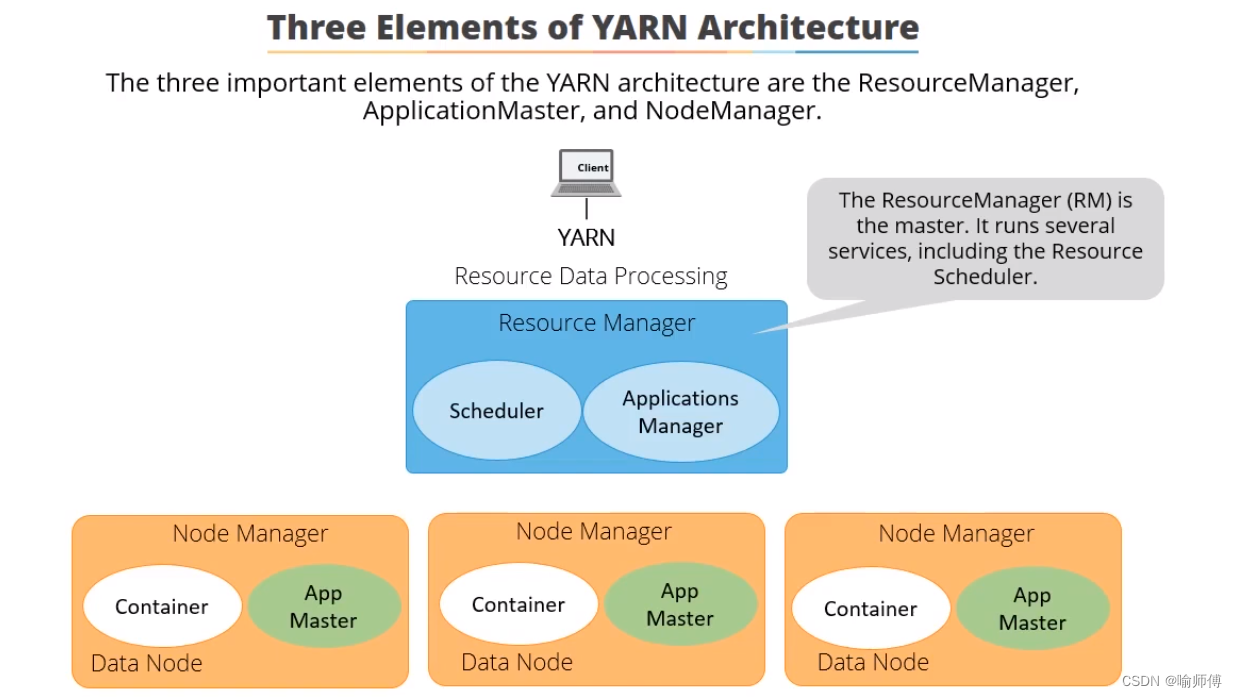
划重点:不只有MR可以使用Yarn,任何一个分布式程序都可。
1.5 相较于其他系统的优势
1.5.1 RDBMS
-
为什么不能用配有大量硬盘的数据库来进行大规模数据分析?我们为什么需要Hadoop?
-
这两个问题的答案来自于计算机硬盘的另一个发展趋势:寻址时间的提升远远不敌于传输速率的提升。
-
寻址是将磁头移动到特定硬盘位置进行读/写操作的过程它是导致硬盘操作延迟的主要原因,而传输速率取决于硬盘的带宽。
-
如果数据访问模式中包含大量的硬盘寻址,那么读取大量数据集就必然会花更长的时间(相较于流数据读取模式,流读取主要取决于传输速率)。
-
另一方面,如果数据库系统只更新一小部分记录,那么传统的B树(关系型数据库中使用的一种数据结构,受限于寻址的速率)就更有优势。
-
但数据库系统如果有大量数据更新时,B树的效率就明显落后于MapReduce,因为需要使用"排序/合并"(sort/merge)来重建数据库。

- 在许多情况下,可以将MapReduce视为关系型数据库管理系统的补充。
- MapReduce比较适合解决需要以批处理方式分析整个数据集的问题,尤其是一些特定目的的分析。
- RDBMS适用于索引后数据集的点查询(
point query)和更新,建立索引的数据库系统能够提供对小规模数据的低延迟数据检索和快速更新。 - MapReduce适合一次写入、多次读取数据的应用,关系型数据库则更适合持续更新的数据集。
- Hadoop和关系型数据库的另一个区别在于它们所操作的数据集的结构化程度。
- 结构化数据(structured data)是具有既定格式的实体化数据,如XML 文档或满足特定预定义格式的数据库表。这是RDBMS包括的内容。
- 另一方面,半结构化数据(semi-structured data)比较松散,虽然可能有格式,但经常被忽略,所以它只能作为对数据结构的一般性指导。例如电子表格,它在结构上是由单元格组成的网格,但是每个单元格内可以保存任何形式的数据。
- 非结构化数据(unstructured data没有什么特别的内部结构,例如纯文本或图像数据。
- Hadoop对非结构化或半结构化数据非常有效,因为它是在处理数据时才对数据进行解释(即所谓的"读时模式")。这种模式在提供灵活性的同时避免了RDBMS数据加载阶段带来的高开销,因为在Hadoop中仅仅是一个文件拷贝操作。
- 关系型数据往往是规范的(normalized),以保持其数据的完整性且不含几余。规范给Hadoop处理带来了问题,因为它使记录读取成为非本地操作,而Hadoop的核心假设之一偏偏就是可以进行(高速的)流读/写操作。
- MapReduce 以及Hadoop中其他的处理模型是可以随着数据规模线性伸缩的。
- 对数据分区后,函数原语(如map和reduce)能够在各个分区上并行工作。
- 这意味着,如果输入的数据量是原来的两倍,那么作业的运行时间也需要两倍。但如果集群规模扩展为原来的两倍,那么作业的运行速度却仍然与原来一样快。SOL查询一般不具备该特性。
1.5.2 网格计算
-
高性能计算(High Performance Computing,HPC)和网格计算(Grid Computing)组织多年以来一直在研究大规模数据处理,主要使用类似于消息传递接口(
MessagePassing Interface,MPI)的API。 -
从广义上讲,高性能计算采用的方法是将作业分散到集群的各台机器上,这些机器访问存储区域网络(SAN)所组成的共享文件系统。
-
这比较适用于计算密集型的作业,但如果节点需要访问的数据量更庞大(高达几百GB,Hadoop开始施展它的魔法),很多计算节点就会因为网络带宽的瓶颈问题而不得不闲下来等数据。
-
Hadoop尽量在计算节点上存储数据,以实现数据的本地快速访问。"数据本地化(data locality)特性是Hadoop数据处理的核心,并因此而获得良好的性能。
Tips:1998年图灵奖得主JimGray在2003年3月发表的"Distributed ComputingEconomics"(分布式计算经济学)一文中,率先提出这个结论:数据处理应该在离数据本身比较近的地方进行,因为这样有利于降低成本,尤其是网络带宽消费所造成的成本。
- 意识到网络带宽是数据中心环境最珍贵的资源(到处复制数据很容易耗尽网络带宽)之后Hadoop通过显式网络拓扑结构来保留网络带宽。注意,这种排列方式并没有降低Hadoop对计算密集型数据进行分析的能力。
- 虽然MPI赋予程序员很大的控制权,但需要程序员显式处理数据流机制,包括用C语言构造底层的功能模块(例如套接字)和高层的数据分析算法。而Hadoop则在更高层次上执行任务,即程序员仅从数据模型(如MapReduce的键-值对)的角度考虑任务的执行,与此同时,数据流仍然是隐性的。
- 在大规模分布式计算环境下,协调各个进程的执行是一个很大的挑战。最困难的是合理处理系统的部分失效问题(在不知道一个远程进程是否挂了的情况下)同时还需要继续完成整个计算。
- 有了MapReduce这样的分布式处理框架,程序员不必操心系统失效的问题,因为框架能够检测到失败的任务并重新在正常的机器上执行。
- 正因为采用的是无共享(
shared-nothing)框架,MapReduce才能够呈现出这种特性,这意味着各个任务之间是彼此独立的。 - 因此,从程序员的角度来看,任务的执行顺序无关紧要。相比之下,MPI程序必须显式管理自己的检查点和恢复机制,虽然赋予程序员的控制权加大了,但编程的难度也增加了。
1.5.3 志愿计算
- 志愿计算项目将问题分成很多块,每一块称为一个工作单元(workunit),发到世界各地的计算机上进行分析。
- 例如,SETI@home的工作单元是0.35MB无线电望远镜数据,要对这等大小的数据量进行分析,一台普通计算机需要几个小时或几天时间才能完成。完成分析后,结果发送回服务器,客户端随后再获得另一个工作单元。为防止欺骗,每个工作单元要发送到3台不同的机器上执行,而且收到的结果中至少有两个相同才会被接受。
- 从表面上看,SETI@home与MapReduce好像差不多(将问题分解为独立的小块然后并行进行计算),但事实上还是有很多明显的差异。SETI@home问题是CPU高度密集的,比较适合在全球成千上万台计算机上运行。因为计算所花的时间远远超过工作单元数据的传输时间。也就是说,志愿者贡献的是PU周期,而不是网络带宽。
- MapReduce 有三大设计目标:
- (1)为只需要短短几分钟或几个小时就可以完成的作业提供服务;
- (2)运行于同一个内部有高速网络连接的数据中心内;
- (3)数据中心内的计算机都是可靠的、专门的硬件。
- 相比之下,SETI@home则是在接入互联网的不可信的计算机上长时间运行,这些计算机的网络带宽不同,对数据本地化也没有要求。
1.6 Apache Hadoop发展简史
- Hadoop 是 Apache Lucene 创始人道格·卡丁(Doug Cutting)创建的,Lucene 是个应用广泛的文本搜索系统库。
- Hadoop起源于开源网络搜索引擎Apache Nutch后者本身也是Lucene项目的一部分。

- Nutch项目开始于2002年,一个可以运行的网页爬取工具和搜索引擎系统很快面世。
- 但后来,它的创造者认为这一架构的灵活性不够,不足以解决数十亿网页的搜索问题。
划重点:
- 一篇发表于2003年的论文为此提供了帮助,文中描述的是谷歌产品架构,该架构称为"谷歌分布式文件系统"(GFS)。"GFS或类似的架构可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
- 特别关键的是,GFS能够节省系统管理(如管理存储节点)所花的大量时间。
- 在2004年,Nutch的开发者开始着手做开源版本的实现,即Nutch分布式文件系统(NDFS)。
- 2004年,谷歌发表论文向全世界介绍他们的MapReduce系统。
- 2005年初,Nutch的开发人员在Nutch上实现了一个MapReduce 系统,到年中,Nutch的所有主要算法均完成移植,用MapReduce和NDFS来运行。
- Nutch的NDFS和MapReduce实现不只适用于搜索领域。
- 在2006年2月,开发人员将NDFS和MapReduce移出utch形成ucene的个子项目,命名为Hadoop。
- 大约在同一时间,DougCutting加入雅虎,雅虎为此组织了专门的团队和资源,将Hadoop发展成能够以Web网络规模运行的系统(参见随后的补充材料)。
- 在2008年2月,雅虎宣布,雅虎搜索引警使用的索引是在一个拥有1万个内核的 Hadoop 集群上构建的。
- 2008年1月,Hadoop已成为Apache的顶级项目,证明了它的成功、多样化和生命力。