今天网上看了wavesummit2024深度学习开发者大会,本来没有啥期待,结果发现飞桨竟然发布3.0版本了!
以下是飞桨框架 3.x 的新特性:
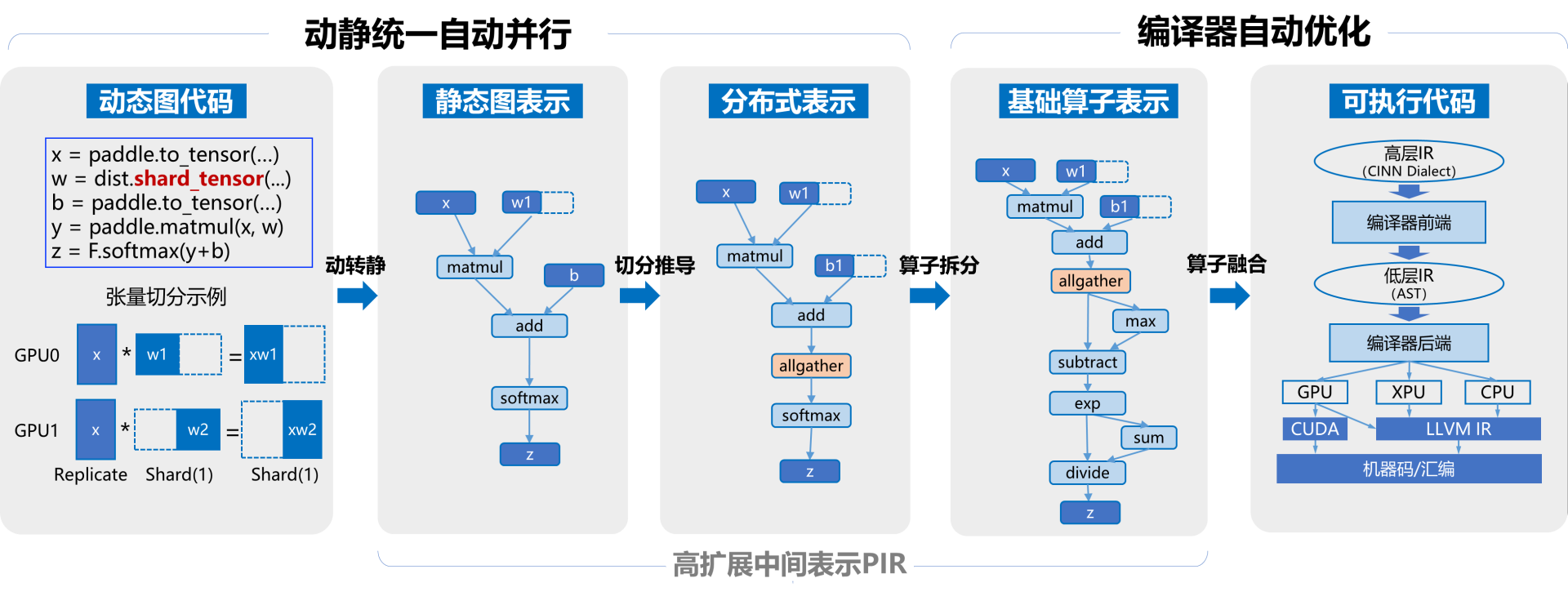
动静统一自动并行: 为了降低大模型的编程难度,飞桨还优化了动静统一的半自动并行编程范式,显著简化了编程的复杂度。开发者无需深入研究手动并行编程的复杂概念和 API,只需进行少量的张量切分标注,即可完成混合并行模型的构建。框架能够自动推导分布式切分状态并添加通信算子,同时还支持一键动转静分布式训练,从而大幅简化了混合并行训练代码的开发过程。动静统一方面,飞桨通过采用基于字节码的动静转换技术,全面升级了其动转静训练能力,支持自适应的图构建功能。在 700 多个飞桨产业级模型上进行了验证,实现了一键动转静训练 100%的成功率。
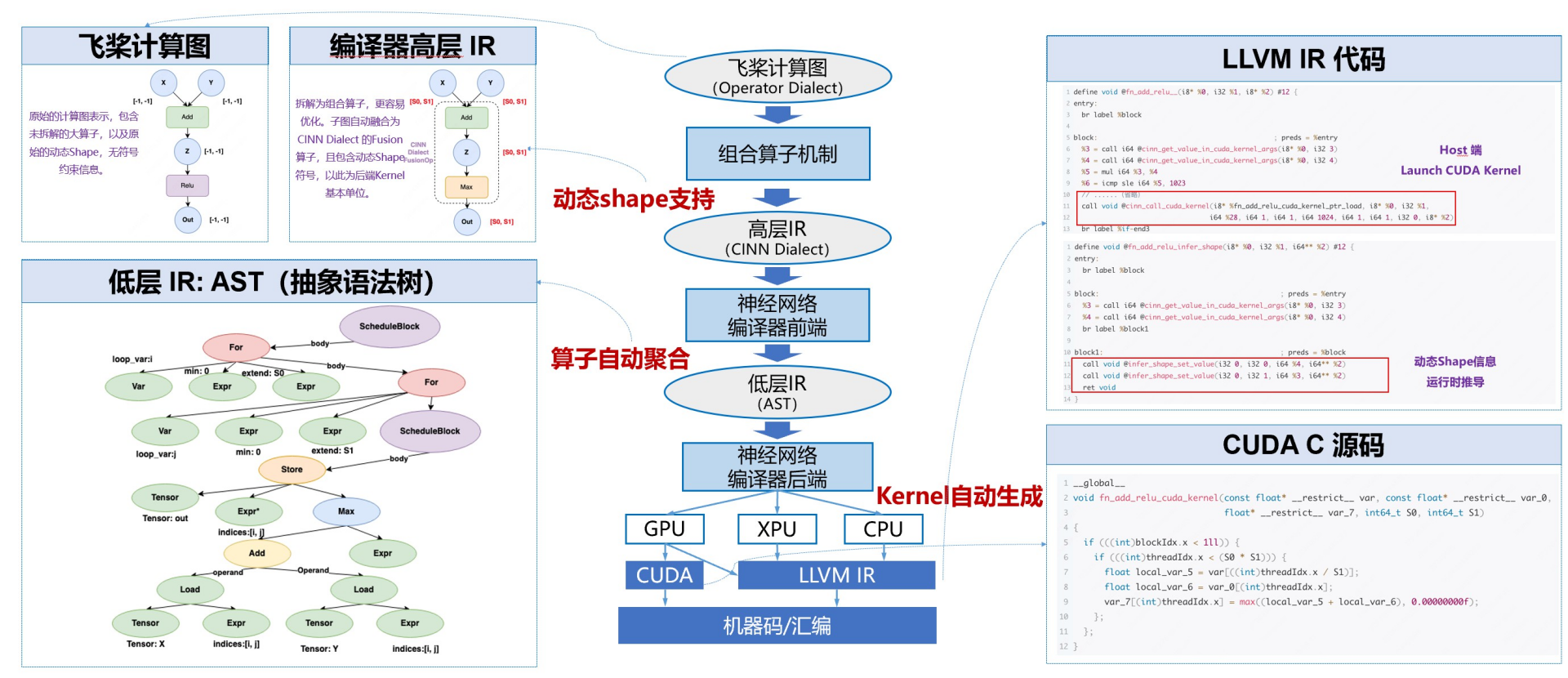
神经网络编译器自动优化: 飞桨神经网络编译器 CINN(Compiler Infrastructure for Neural Networks)采用与框架一体化的设计,能够支持生成式模型、科学计算模型等多种模型的高效训练与可变形状推理,为计算灵活性与高性能之间提供了一个良好的平衡点。通过算子的自动融合和代码生成技术,Llama2 和 Stable Diffusion 模型的性能提升了 30%。
高阶自动微分: 为了更好支持科学计算等场景,飞桨框架设计并实现了基于组合算子机制的高阶自动微分技术,结合神经网络编译器自动优化技术,我们测试了超过 40 多个科学计算场景的微分方程,其求解速度领先业界同类产品 70%。
高扩展中间表示 :为了提升飞桨框架的可扩展性,我们研发了高扩展中间表示 PIR(Paddle Intermediate Representation)。这一表示系统性地抽象了底层核心概念,提供了灵活且高效的组件。PIR 作为基础设施,支撑着动转静、自动微分、自动并行、组合算子、图优化等多项技术,并广泛应用于分布式训练、模型压缩、推理部署等场景。通过 PIR 提供的 DRR(Declarative Rewrite Rule)机制,Pass 的开发成本可以降低 60%。我们对超过 900 个模型配置进行了测试,结果显示,在使用 PIR 后,推理的整体性能提升了超过 10%。
多硬件适配: 飞桨为大模型硬件适配提供了功能完善且低成本的方案。新硬件仅需适配 30 余个接口,即可支持大模型的训练、压缩与推理。同时,飞桨提供了基于编译器的硬件接入方式,硬件厂商只需以插件的形式实现编译器的代码生成后端,便能实现与飞桨框架的高效适配。
上述特性在飞桨框架 2.6 版本或更早版本时就已经开始开发,目前已达到外部可试用的阶段。由于这些新特性在使用体验、性能、二次开发便利度以及硬件适配能力等方面带来了显著提升,因此我们决定发布 3.0-Beta 版本。此版本包含了对框架 2.x 版本部分已有功能的改进,并且在不使用新特性的情况下,表现是成熟稳定的。展望未来,我们预计将在 2024 年 12 月发布飞桨框架 3.0 的正式版本。
飞桨神经网络编译器cinn