1、JDK&JRE&JVM
-
Java 执行流程
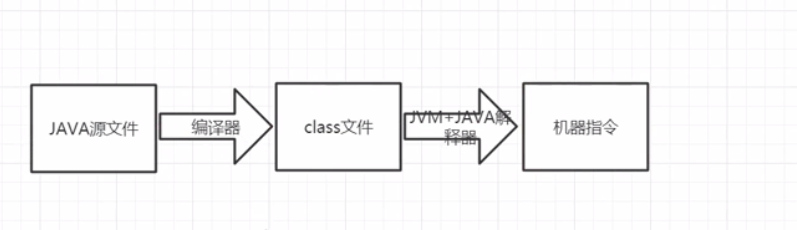
-
JRE的应用
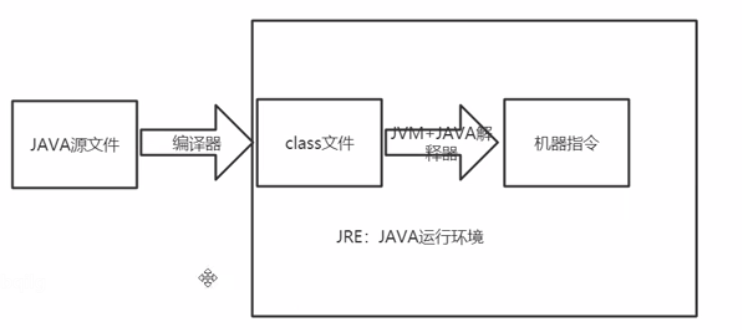
- JDK
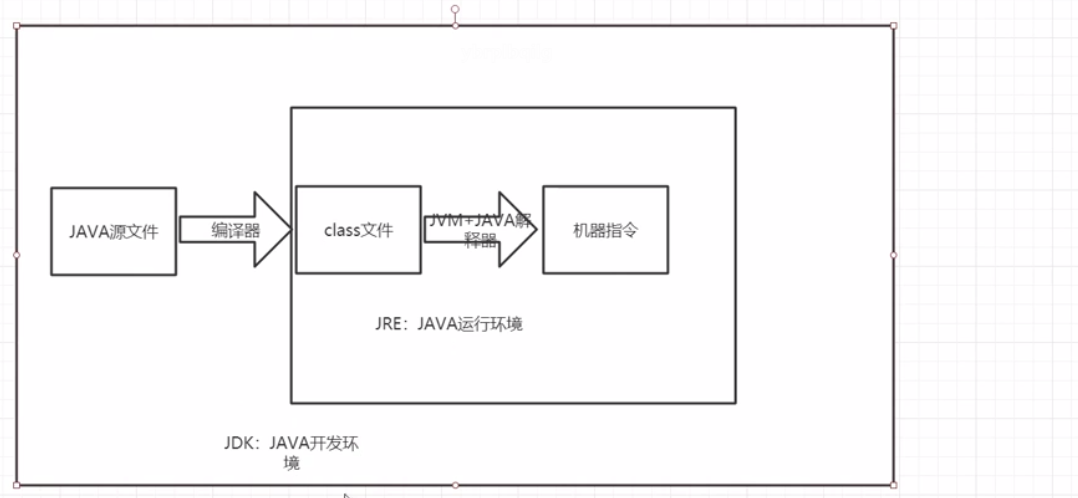
-
JDK+JRE+JVM
-
JDK(Java开发环境):JRE+工具(编译器、调试器、其他工具等)+类库
编译器:将Java 文件编译为class文件,也是JVM能运行解释的文件
-
JRE(Java 运行环境):JVM+Java解释器
-
JVM:Java虚拟机
-
2、Java字节码文件结构
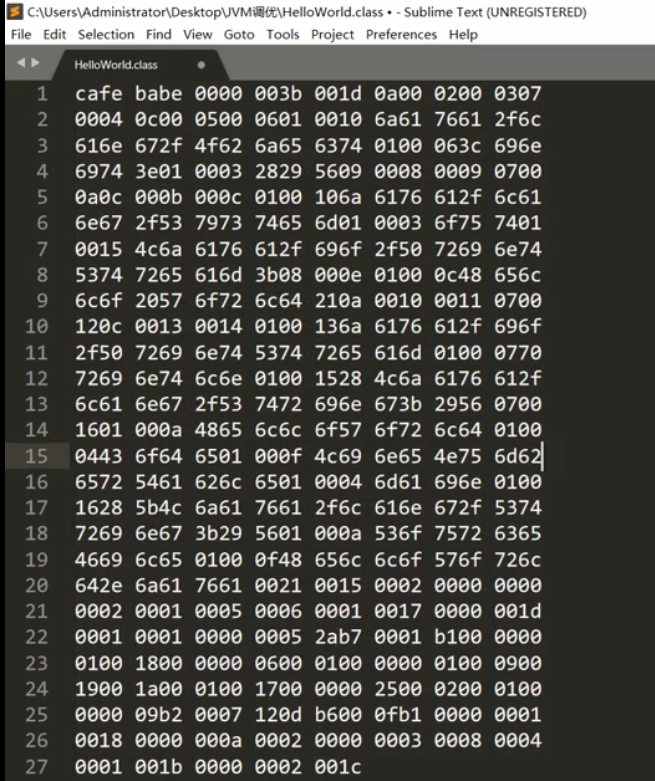
- 官方字节码文件结构
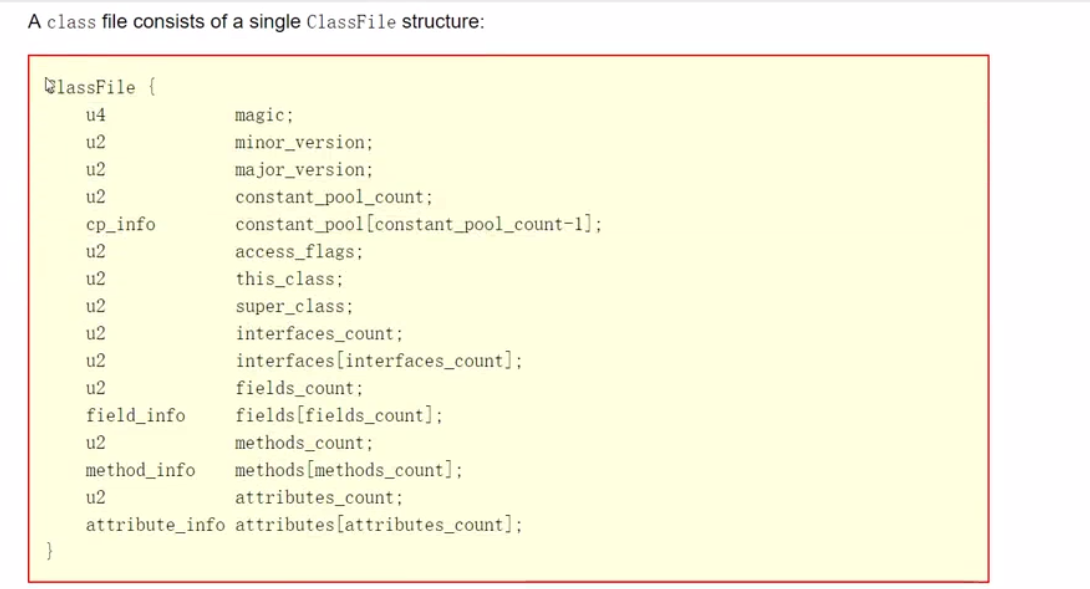
- 什么是u2 ,u4?
u2:代表数据占2个字节, u4:代表4个字节。
- JDK编译对应版本号
JDK7-->51 JDK8-->52 JDK-->53 ......
-
编译的本质
编译的本质就是Java源文件转换为JVM认识的16进制class文件格式。JVM虚拟机不只是为Java服务,只要符合class标准格式的16进制JVM就能识别。
3、类的加载机制
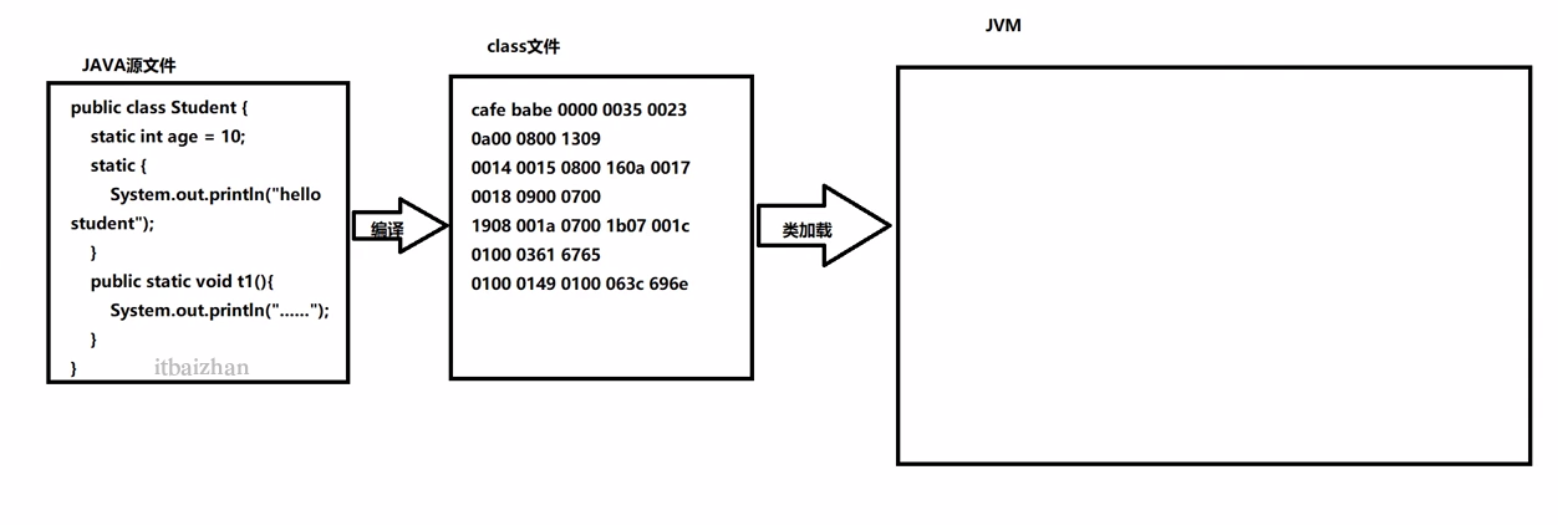
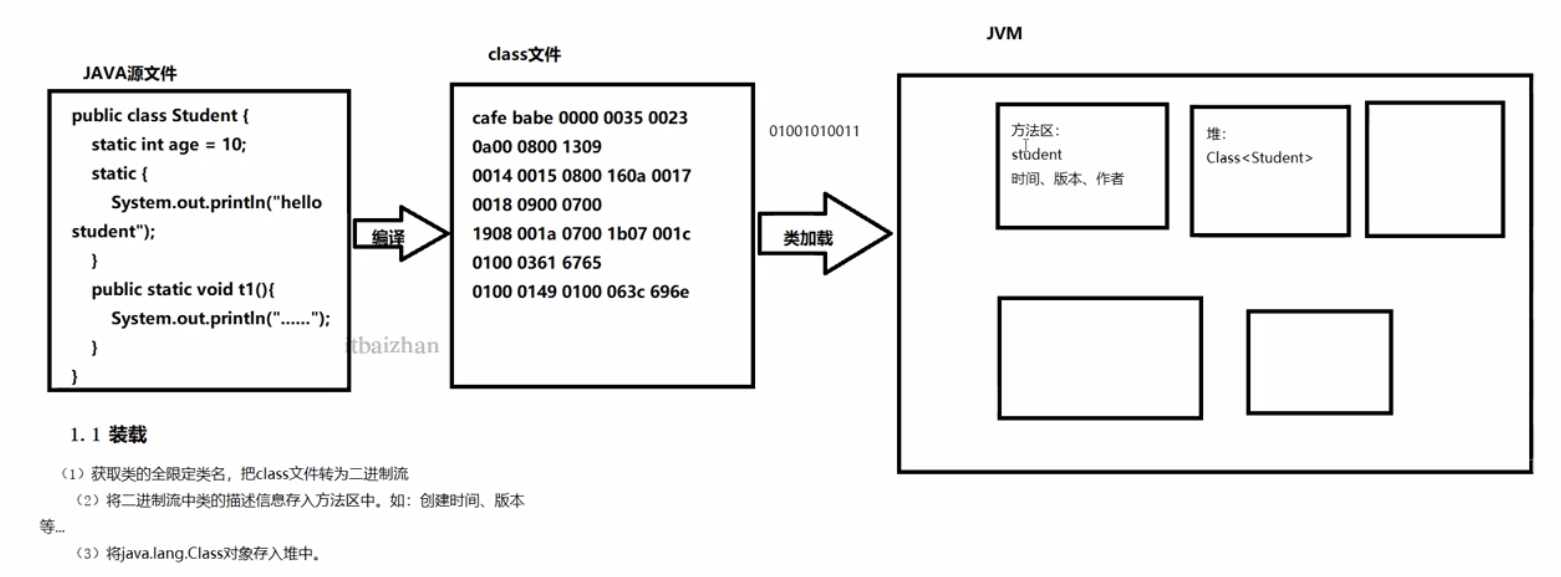
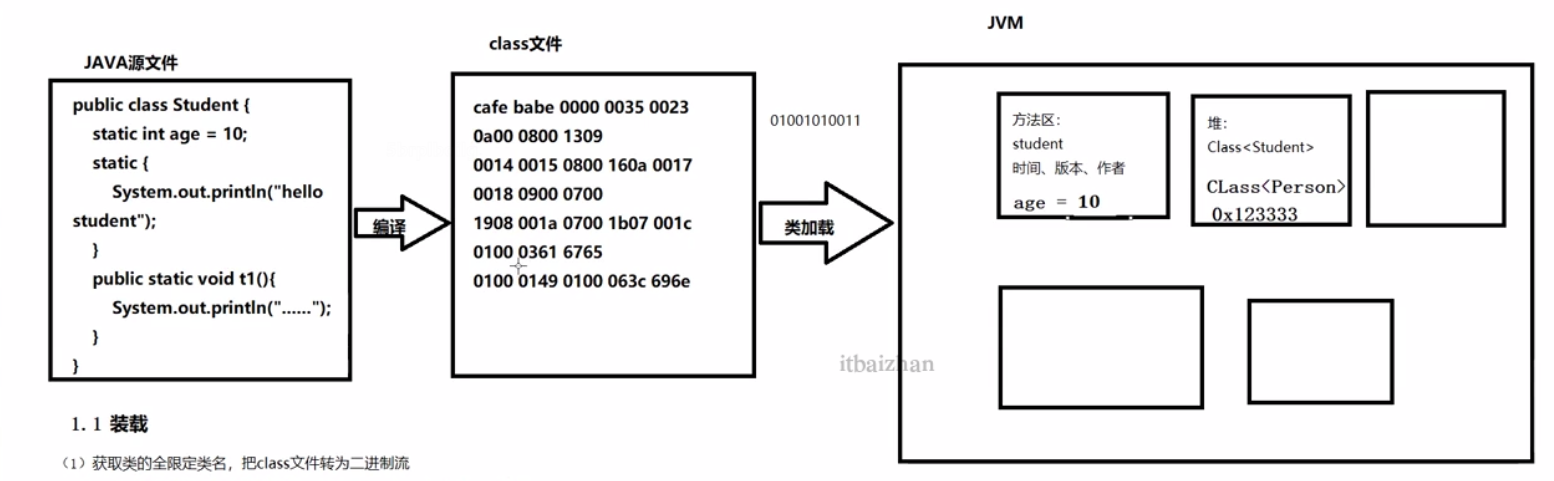
3.1 类加载大概流程
-
装载:获取类的全限定类名,将class文件转化为二进制流。
-
将二进制流中类的描述信息 存入方法区。如:创建时间、版本等......
-
将java.lang.Class对象放入内存。
-
-
链接
-
验证:验证被加载类的正确:如文件的格式,文件元素等。
-
准备:在方法区中为静态变量分配空间,并设置初值。
-
解析:把类的符号引用转换为直接引用。
-
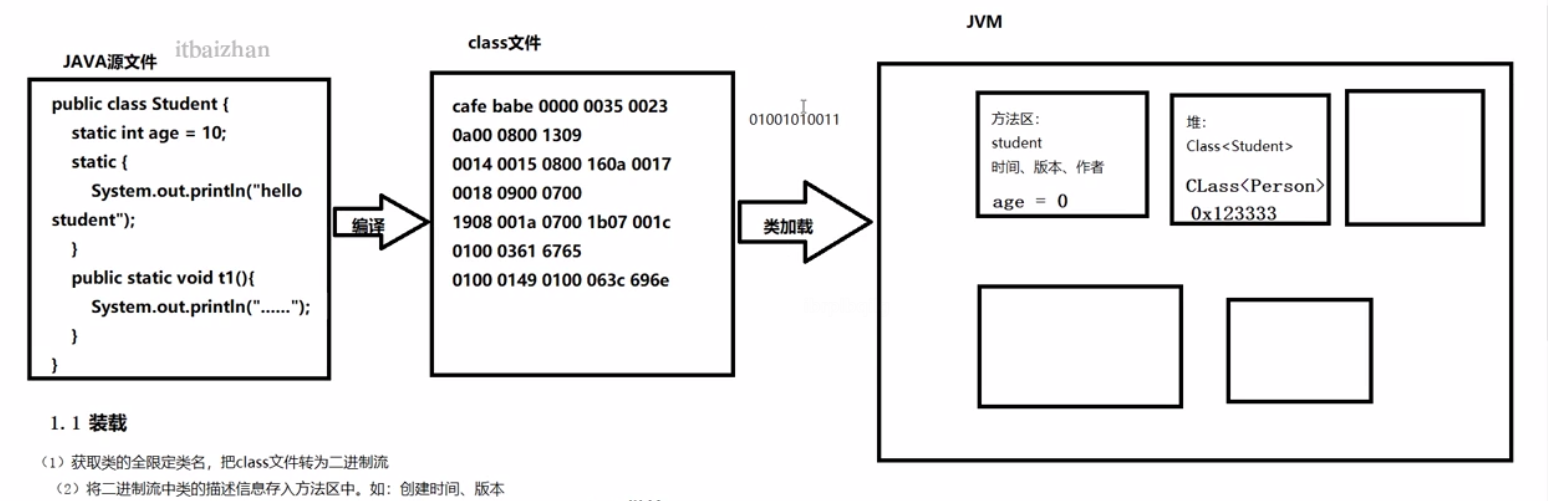
3.初始化
为类的静态变量设置默认值,执行静态代码块。
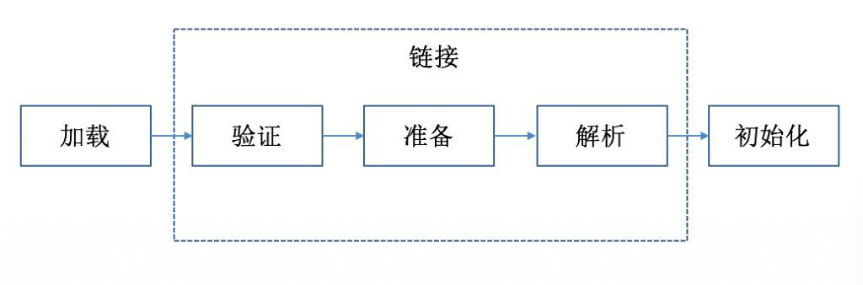
①装载---->②链接(验证,准备,解析)---->初始化
第一步:加载指的是把class字节码文件从各个来源通过**类加载器(包括启动类加载器,拓展类加载器、应用类加载器、用户自定义加载器)**装载入内存中。
流程是,获取全限定类名-->将class字节文件转化为二进制流-->将二进制流中类的描述信息放入方法区。将java.lang.Class对象放入堆内存。
第二步:链接
-
验证:比如文件格式 的验证,元数据的验证 (如是否继承了final修饰的类),字节码的验证 (保证语义的准确性),符号引用的验证。
-
准备:主要为静态变量(类变量)分配内存,并赋予初值(初值,不是代码中具体写的初始化的值)。
比如8种基本类型 的初值,默认为0;引用类型 的初值则为null;常量的初值即为代码中设置的值,final static tmp = 456, 那么该阶段tmp的初值就是456
- 解析:符号引用替换为直接引用的过程。
第三步:初始化
主要是对类变量初始化,是执行类构造器的过程。
拓展:为什么会有自定义类加载器?
-
一方面是由于java代码很容易被反编译,如果需要对自己的代码加密的话,可以对编译后的代码进行加密,然后再通过实现自己的自定义类加载器进行解密,最后再加载。
-
另一方面也有可能从非标准的来源加载代码,比如从网络来源,那就需要自己实现一个类加载器,从指定源进行加载。
3.2 类加载器
3.2.1 分类
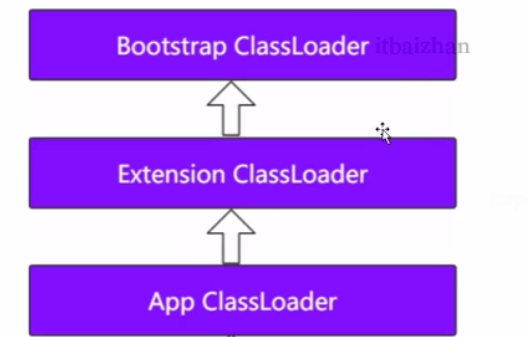
不同的类加载器加载不同的类:
启动类加载器(Bootstrap classloader):主要负责加载Java中的一些核心类库,主要位于<JAVA_HOME>/lin/rt.jar中。
拓展类加载器(Extension classloader):主要加载一些拓展类,是启动类加载类的子类。
应用类加载器:(System classlzhuyoader):主要用于加载CLASSPATH 路径下,我们自己定义的类,是拓展类加载器的子类。
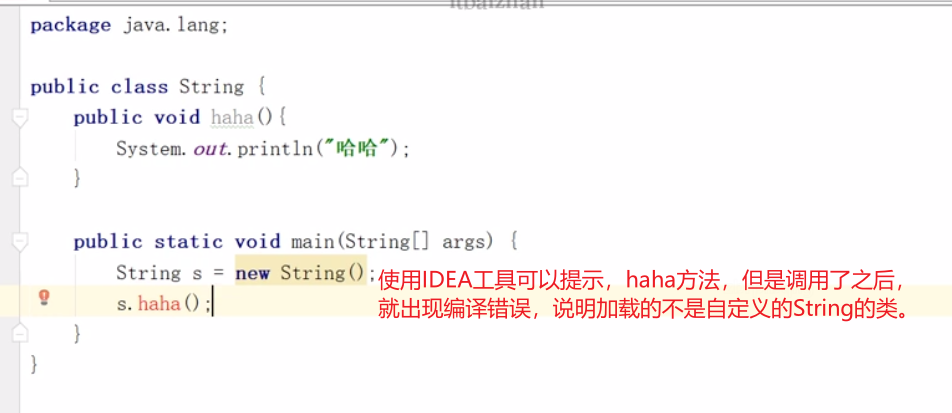
这由于双亲委派机制模型导致的一个原因。
3.2.2 双亲委派模型
如果一个类加载器收到了类的加载请求,他不会自己去加载,而是把这个请求委托给父类加载器去执行,如果父类加载器还存在其父类加载器,则进一步加载向上委托,一次递归,请求最终达到顶层的启动类加载器返回可以完成类加载任务,就成功返回。倘若父类加载器无法完成此次加载任务,子加载才会尝试自己去加载。
-
如何打破双亲委派机制? 例子:Tomcat
自定义类加载器类,继承Classloader类,重写loadClass()方法.
4、JVM内存模型
4.1 什么是JVM内存模型
JVM需要使用计算机的内存,Java程序运行中所处理的对象或者算法都会用使用JVM的内存空间,JVM将内存划分为5块,这样的结构称为JVM内存模型。
4.2 JVM为什么进行内存区域划分
随着对象数量的增加,JVM内存使用率也在增加,如果JVM内存使用率达到100%,则无法继续运行Java程序。为了让JVM内存,我们需要对JVM内存进行回收。为了提高垃圾回收效率,JVM将内存区域进行了划分。
4.3 JVM内存划分
JVM按照线程是否独享将内存首先分为两大类。
- 线程独享区
只有当前线程能访数据的区域,线程之间不能共享。
线程独享区随线程的创建,随线程的销毁而被回收。
-
线程共享区
所有线程都可以访问的区域。
当线程被销毁的时候,线程共享区的数据不会立即回收,需要等待达到垃圾回收的阈值之后才会进行回收。
- 模型图
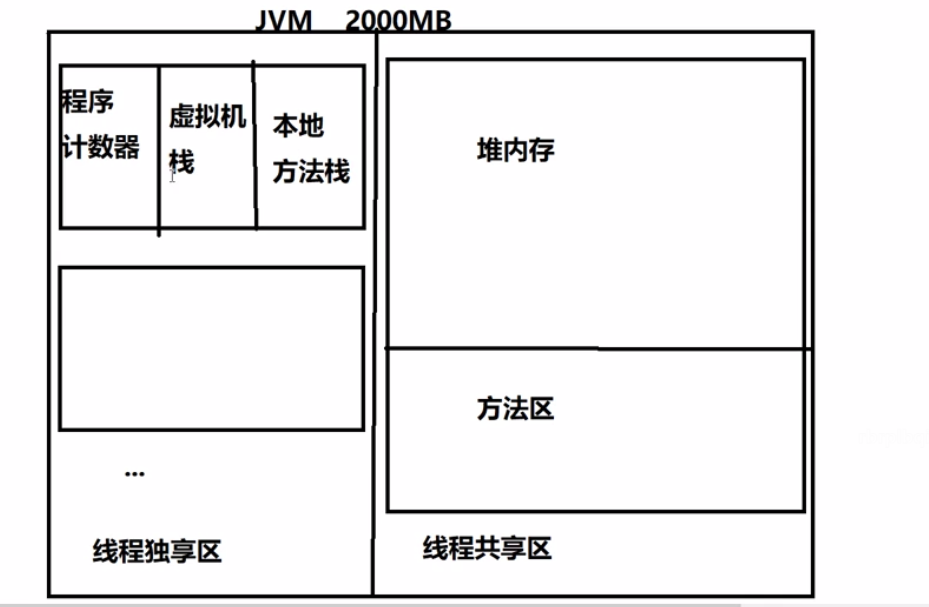

栈内存独立:基本数据类型
堆内存共享:引用数据类型数据
4.3.1 程序计数器
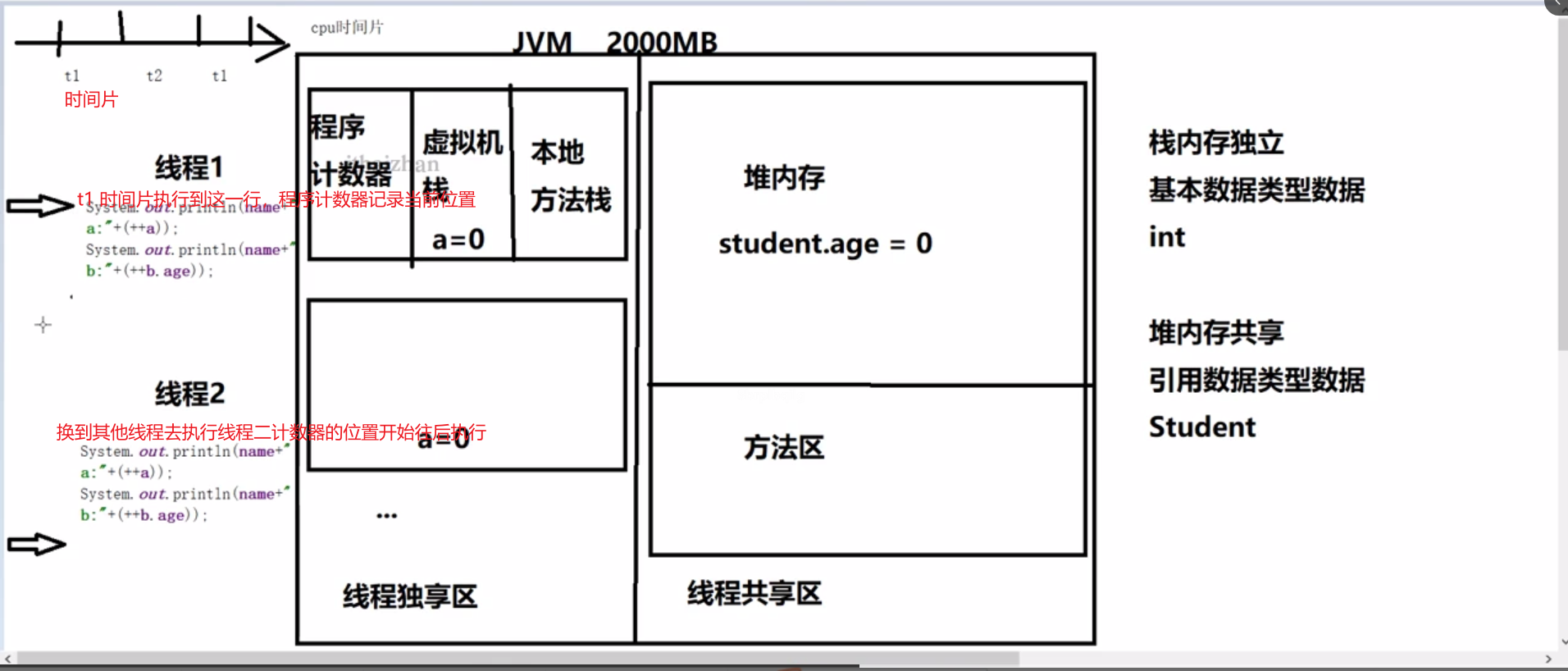
程序计数器会记录当前线程要执行指令的内存地址,只占用一小部分的内存区域,只记录一个地址,所以我们认为程序计数器是不会出现内存溢出的问题的分区。
所以虚拟机是不会优化程序计数器区域的。
4. 3.2 本地方法栈
Java中有些代码的视线是依赖于其他非Java语言的(C++),本地方法栈存储的是维护非Java语句执行过程中产生的数据,一般本地方法栈不会出现内存问题。
4.4 虚拟机栈
存放当前线程中所有声明的变量,包基本数据类型和引用数据类型的引用。
-
基本数据类型和引用数据类型的划分标准
-
基本数据类型:变量在声明的时候,能够确认占用内存的大小。
-
引用数据类型:变量在声明的时候不知道占用内存大小。
引用数据类型将值的引用放到虚拟机栈中,而对象则存在对内存中,引用数据类型占用4个字节存放地址。
-
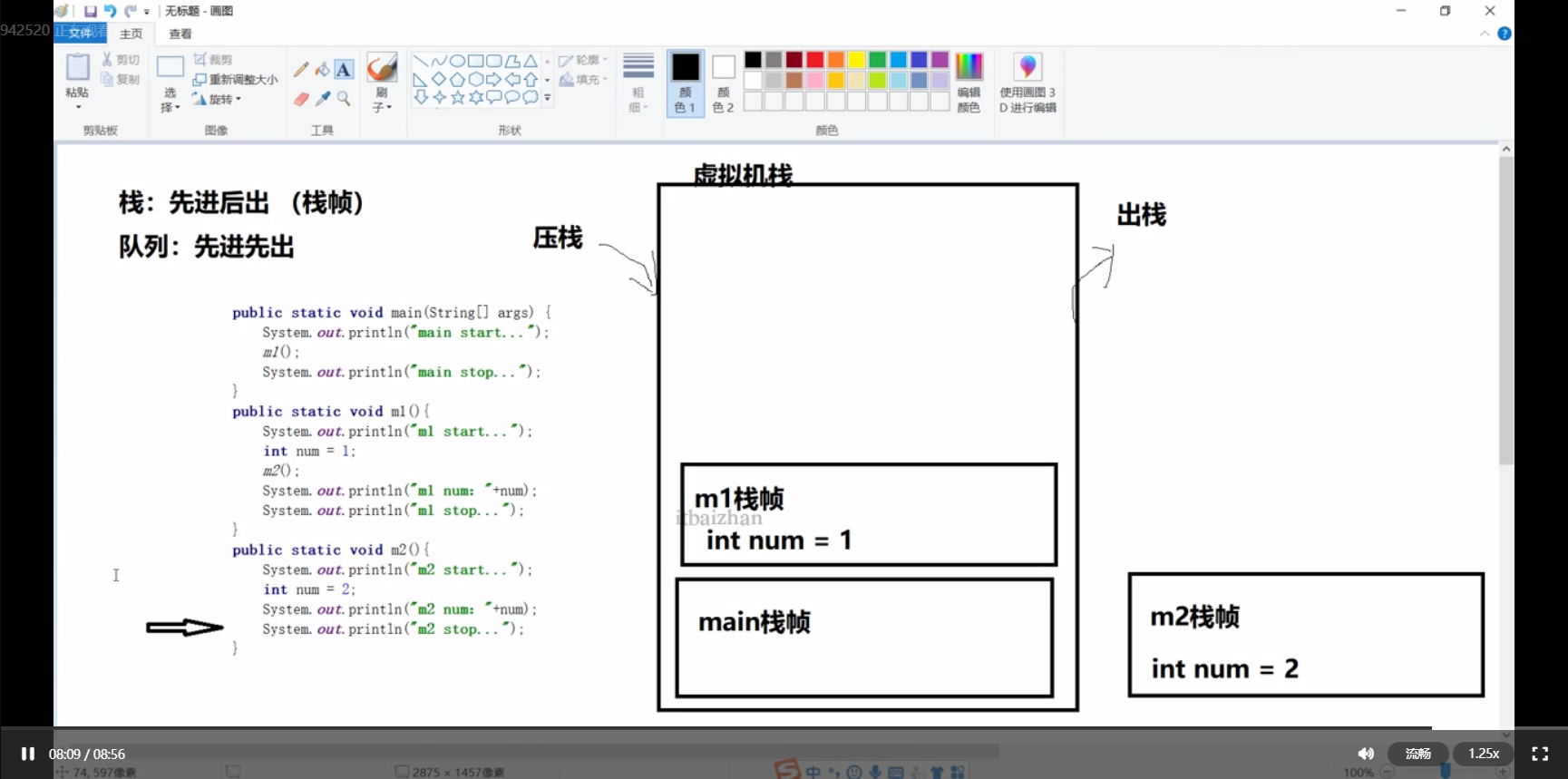
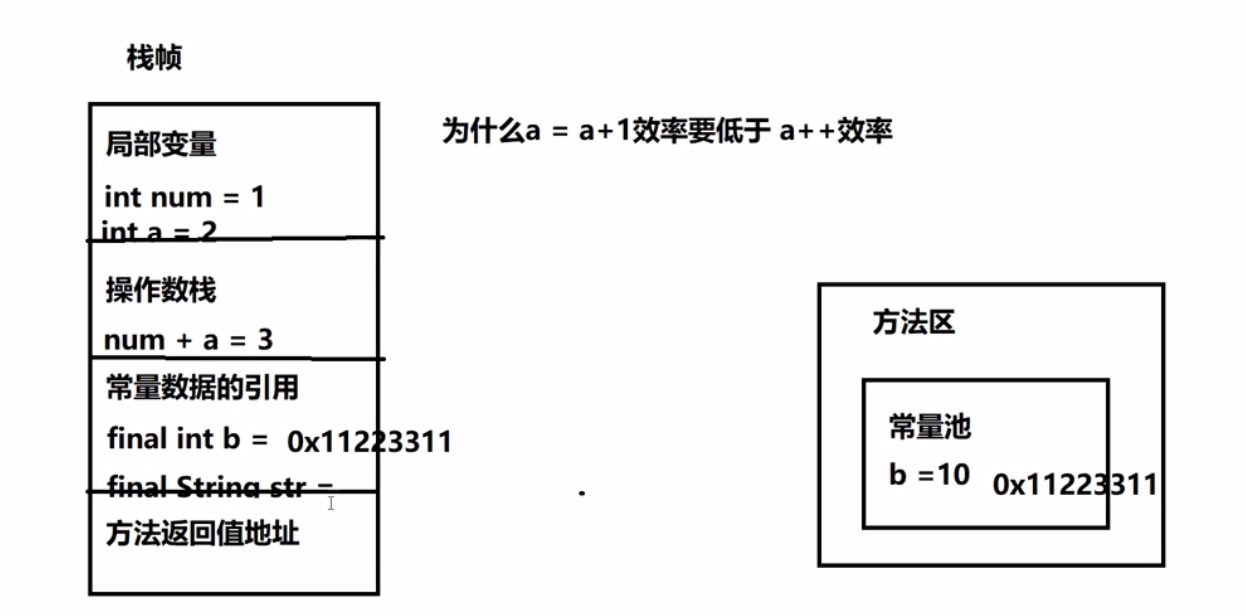
4.4.1 栈帧的结构
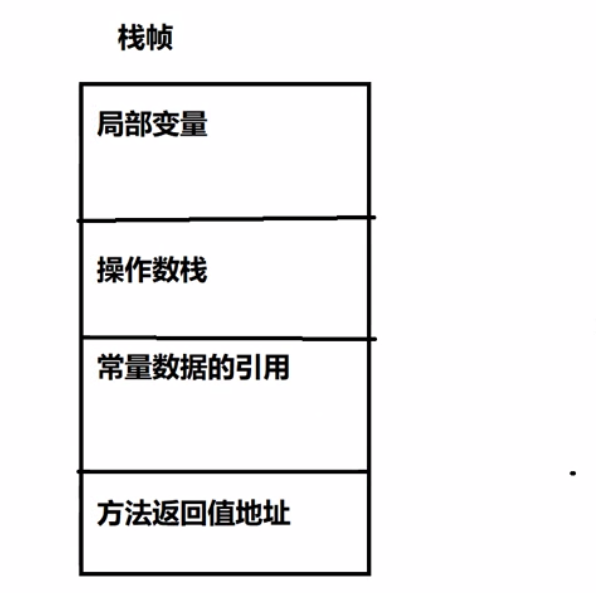

- 常量池的应用中的常量存放的你是值。而是 方法区中常量池中的常量的地址。
-
局部变量:存放当前方法的局部变量,基本数据类型存储值。引用数据类型存储堆内存中的地址。
-
操作数栈:对方法的变量提供计算的区域。
-
常量数据的引用:常量数据会存放到方法区的常量池,不管是基本数据类型还是引用数据类型都会存放常量池的地址。
-
方法返回值的地址:方法返回数据会存到计算机内存的寄存器中。