目录
- 前言
- Flow生命周期
- [StateFlow 替代LiveData](#StateFlow 替代LiveData)
- SharedFlow
- 其他常见应用场景
- Flow使用注意事项
- 总结
前言
前面两篇文章,介绍了Flow是什么,如何使用,以及相关的操作符进阶,接下来这篇文章,主要介绍Flow在实际项目中使用。
Flow生命周期
在介绍Flow实际应用场景之前,我们先回顾Flow第一篇介绍的计时器例子,我们在ViewModel定义了一个timeFlow数据流:
class MainViewModel : ViewModel() {
val timeFlow = flow {
var time = 0
while (true) {
emit(time)
delay(1000)
time++
}
}然后Activity里面,接收前面定义的数据流。
lifecycleOwner.lifecycleScope.launch {
viewModel.timeFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}我运行看下实际效果:
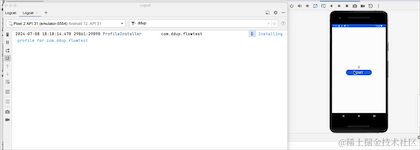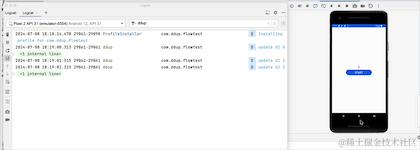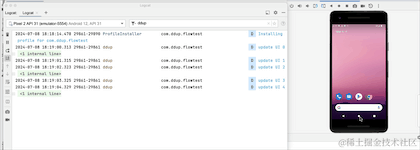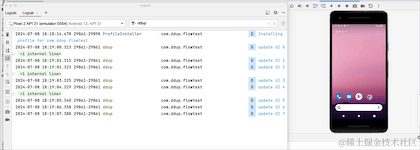
你们有没有发现,App切换到后台时,日志还在打印,这不是对资源的浪费,我们修改一下接收的地方代码:
lifecycleOwner.lifecycleScope.launchWhenStarted {
viewModel.timeFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}我们把协程开启的方法,从launch改成launchWhenStarted,再运行看下效果:
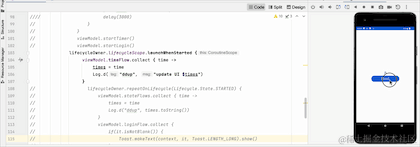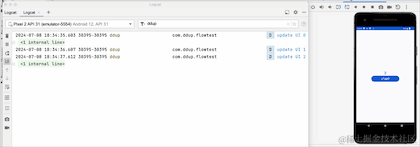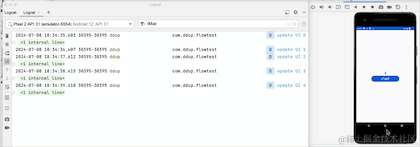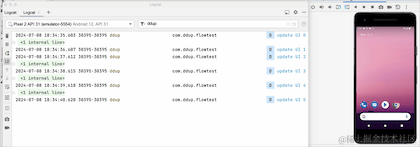
我们可以看到,当点击HOME键,退回到后台的时候,日志不再打印了,由此可见,改动生效了,但是流取消接收了吗,我们切回到前台看下:
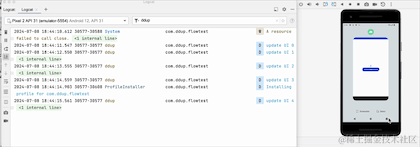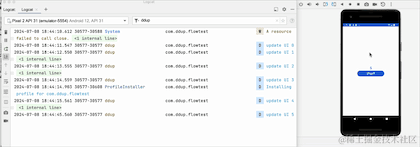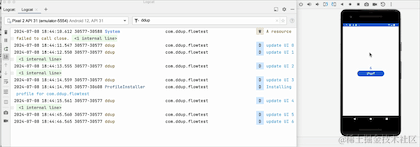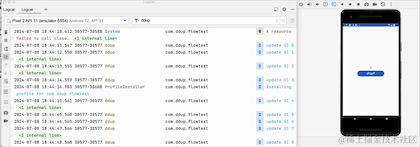
切换到前台,我们可以看到,计数器并没有从0开始,所以其实它并没有取消接收,只是在后台暂停接收数据了,Flow管道还保留之前的数据,事实上这个launchWhenStarted API已经废弃了,Google更推荐repeatOnLifecycle来代替它,并且它不会存在管道中保留旧数据问题。
我们尝试改造一下对应代码:
lifecycleOwner.lifecycleScope.launch {
lifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.timeFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
}重新运行看下效果:
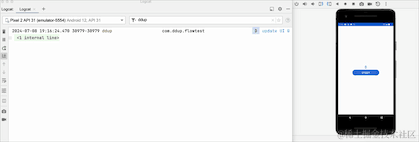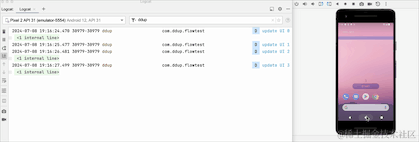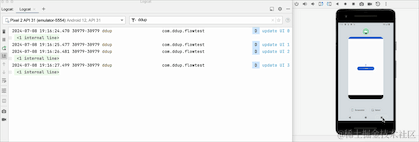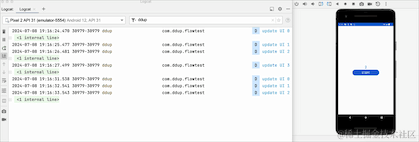
我们可以看到,从后台切回到前台数据又从0开始了,说明切换到后台,Flow取消工作了,原来的数据全部清空了。
我们在使用Flow,通过repeatOnLifecycle,更能保证我们程序的安全性。
StateFlow 替代LiveData
前面介绍的都是Flow冷流例子,接下来将会介绍一些热流常见的应用场景。
还是前面的计时器的例子,假如横竖屏切换后,又会出现什么情况呢?
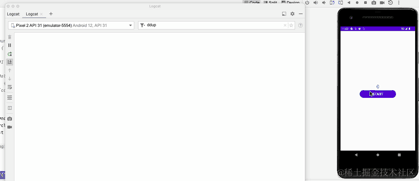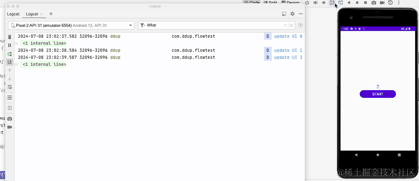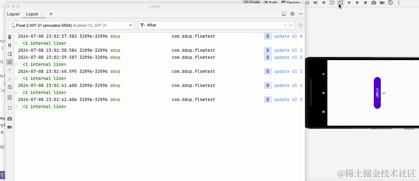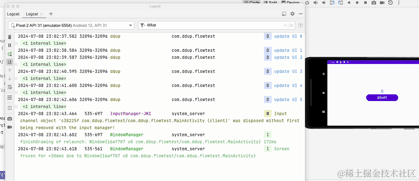
我们可以看到,横竖屏切换后,Activity重新创建,重新创建后,timeFlow会重新collect,冷流被重新collect后重新执行,然后计时器又从0开始计时了,很多时候,我们希望横竖屏切换时,希望页面的状态是保持不变的,至少在一定时间内不被改变的,这里我们冷流修改成热流试下:
val hotFlow =
timeFlow.stateIn(
viewModelScope,
SharingStarted.WhileSubscribed(5000),
0
)
```
lifecycleOwner.lifecycleScope.launch {
lifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.hotFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
}
```这里着重说下stateIn里面的三个参数,第一个是协程的作用域,第二个是flow保持工作状态最大有效时间,超过flow就会停止工作,最后一个参数是初始值。
重新运行看下效果:
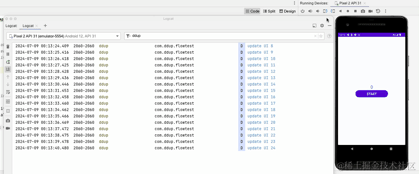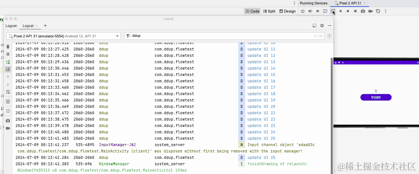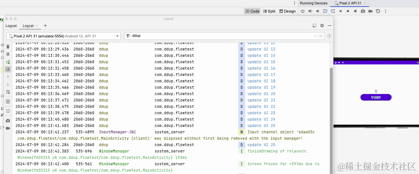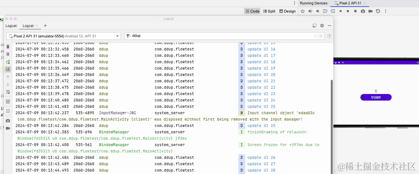
这里我们可以看到横竖屏切换后,打印的日志,计时器不会从0开始了。
我们上面介绍了一个冷流如何修改变成热流的,这里还没有介绍stateFlow如何代替LiveData,下面介绍一下,stateFlow替代LiveData用法:
private val _stateFlow = MutableStateFlow(0)
val stateFlow = _stateFlow.asStateFlow()
fun startTimer() {
val timer = Timer()
timer.scheduleAtFixedRate(object :TimerTask() {
override fun run() {
_stateFlow.value += 1
}
},0,1000)
}
```
viewModel.startTimer()
lifecycleOwner.lifecycleScope.launch {
lifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.stateFlow.collect { time ->
times = time
Log.d("ddup", "update UI $times")
}
}
}
```我们定义了一个StateFlow热流,然后通过一个startTimer()方法改变stateFlow值类似LiveData setData,点击按钮时,开始改变StateFlow值并收集对应流的值类似LiveData Observe方法监听数据变化。
下面看下实际运行效果:
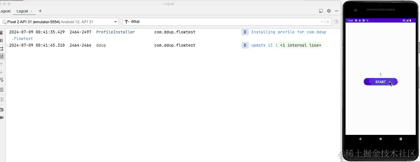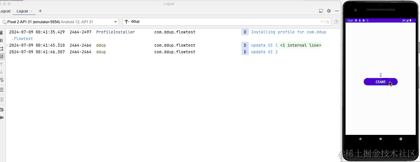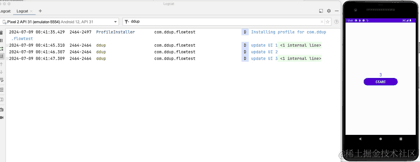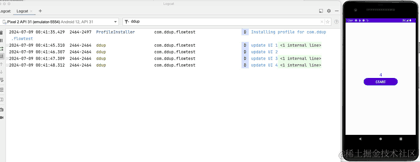
到这里,我们介绍完了StateFlow基本用法,下面来介绍SharedFlow。
SharedFlow
要理解SharedFlow,我们先知道个概念,粘性事件,按字面理解就是,观察者订阅数据源时,如果数据源已经有最新的数据,那么这些数据会立即推送给观察者。从上面的解释来看,LiveData是符合这个粘性特性的,同样的StateFlow呢?我们写个简单的demo验证一下:
class MainViewModel : ViewModel() {
private val _clickCountFlow = MutableStateFlow(0)
val clickCountFlow = _clickCountFlow.asStateFlow()
fun increaseClickCount() {
_clickCountFlow.value += 1
}
}
//MainActivity
```
val tv = findViewById<TextView>(R.id.tv_content)
val btn = findViewById<Button>(R.id.btn)
btn.setOnClickListener {
viewModel.increaseClickCount()
}
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.clickCountFlow.collect { time ->
tv.text = time.toString()
Log.d("ddup", "update UI $time")
}
}
}
```我们首先在MainViewModel,定义了一个clickCountFlow,然后在Activity,通过Button点击对clickCountFlow数据改变,然后接收clickCountFlow并把数据显示在文本上。
下面看下运行效果:
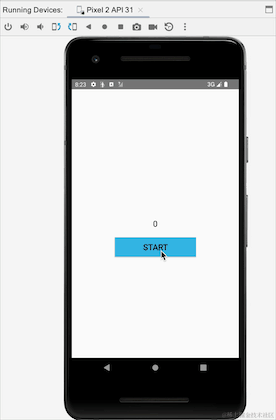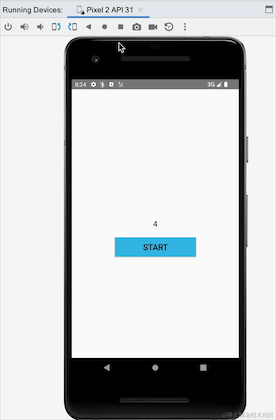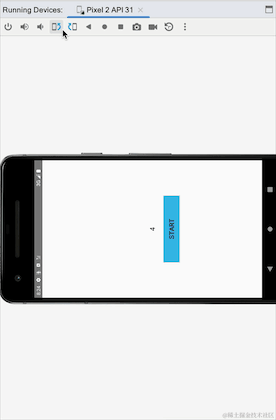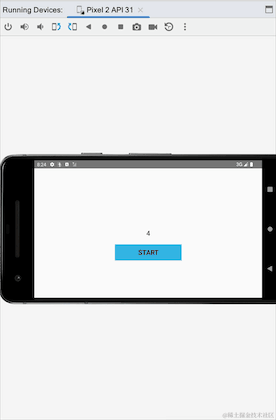
我们可以看到横竖屏切换的时候,Activity重新创建,clickCountFlow重新收集后,数据还是从之前的4开始的,说明StateFlow是粘性的,在这里看上去没有问题,但是我们看另外一个例子,我们模拟一个点击登陆的场景,点击登陆按钮,实现登陆并登陆:
//MainViewModel
private val _loginFlow = MutableStateFlow("")
val loginFlow = _loginFlow.asStateFlow()
fun startLogin() {
// Handle login logic here.
_loginFlow.value = "Login Success"
}
//MainActivity
```
val tv = findViewById<TextView>(R.id.tv_content)
val btn = findViewById<Button>(R.id.btn)
btn.setOnClickListener {
viewModel.startLogin()
}
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.loginFlow.collect {
if (it.isNotBlank()) {
Toast.makeText(this@MainActivity2, it, Toast.LENGTH_LONG).show()
}
}
}
}
```上述代码实际就是模拟一个点击登陆,然后会提示登陆成功,我们看下实际运行效果:
看到没有,横竖屏切换后,登陆成功的提示重新弹出一遍,我们并没有走重新登陆流程,这就是粘性事件带来的数据重复接收的问题,上面代码,我们改成SharedFlow试下:
private val _loginFlow = MutableSharedFlow<String>()
val loginFlow = _loginFlow.asSharedFlow()
fun startLogin() {
// Handle login logic here.
viewModelScope.launch {
_loginFlow.emit("Login Success")
}
}我们StateFlow改成SharedFlow,我们可以看到SharedFlow不需要初始值,登陆的地方增加了emit方法发送数据,接收数据的地方不变,重新运行下看下效果:
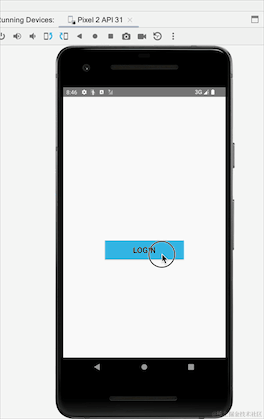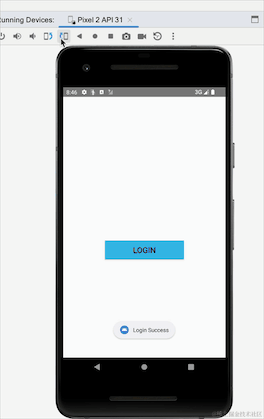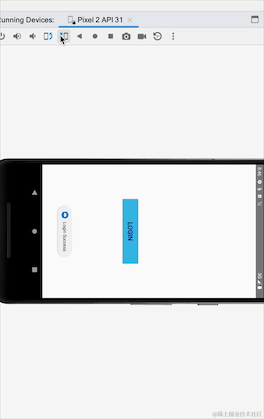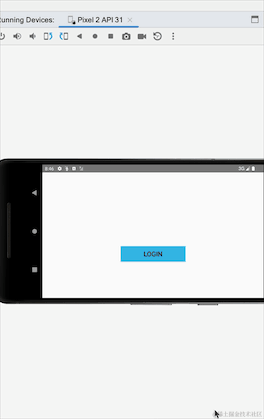
这里我们可以看到使用SharedFlow不会出现这个粘性问题,其实SharedFlow还有很多参数可以配置的:
public fun <T> MutableSharedFlow(
// 每个新的订阅者订阅时收到的回放的数目,默认0
replay: Int = 0,
// 除了replay数目之外,缓存的容量,默认0
extraBufferCapacity: Int = 0,
// 缓存区溢出时的策略,默认为挂起。只有当至少有一个订阅者时,onBufferOverflow才会生效。当无订阅者时,只有最近replay数目的值会保存,并且onBufferOverflow无效。
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
)SharedFlow更多用法,有待大家去发掘啊,这里不过赘述了。
其他常见应用场景
前面介绍了从基本冷流到热流,以及StateFlow、SharedFlow常见用法,适用场景,接下来,我们围绕几个实际例子,看看flow其他常见应用场景。
处理复杂、耗时逻辑
我们一般做一些复杂的耗时逻辑,放在子线程处理,然后切换到主线程展示UI,同样的Flow也支持线程切换,flowOn可以让之前的操作放到对应的子线程处理。
我们实现一个读取本地Assets目录下的person.json文件,并将其解析出来,json文件中的内容:
{
"name": "ddup",
"age": 101,
"interest": "earn money..."
}然后解析文件:
fun getAssetJsonInfo(context: Context, fileName: String): String {
val strBuilder = StringBuilder()
var input: InputStream? = null
var inputReader: InputStreamReader? = null
var reader: BufferedReader? = null
try {
input = context.assets.open(fileName, AssetManager.ACCESS_BUFFER)
inputReader = InputStreamReader(input, StandardCharsets.UTF_8)
reader = BufferedReader(inputReader)
var line: String?
while ((reader.readLine().also { line = it }) != null) {
strBuilder.append(line)
}
} catch (ex: Exception) {
ex.printStackTrace()
} finally {
try {
input?.close()
inputReader?.close()
reader?.close()
} catch (e: IOException) {
e.printStackTrace()
}
}
return strBuilder.toString()
}Flow读取文件:
/**
* 通过Flow方式,获取本地文件
*/
private fun getFileInfo() {
lifecycleScope.launch {
flow {
//解析本地json文件,并生成对应字符串
val configStr = getAssetJsonInfo(this@MainActivity2, "person.json")
//最后将得到的实体类发送到下游
emit(configStr)
}
.map { json ->
Gson().fromJson(json, PersonModel::class.java) //通过Gson将字符串转为实体类
}
.flowOn(Dispatchers.IO) //在flowOn之上的所有操作都是在IO线程中进行的
.onStart { Log.d("ddup", "onStart") }
.filterNotNull()
.onCompletion { Log.d("ddup", "onCompletion") }
.catch { ex -> Log.d("ddup", "catch:${ex.message}") }
.collect {
Log.d("ddup", "collect parse result:$it")
}
}
}最终打印日志:
2024-07-09 22:00:34.006 12251-12251 ddup com.ddup.flowtest D onStart 2024-07-09 22:00:34.018 12251-12251 ddup com.ddup.flowtest D collect parse result:PersonModel(name=ddup, age=101, interest=earn money...) 2024-07-09 22:00:34.019 12251-12251 ddup com.ddup.flowtest D onCompletion
存在依赖关系的接口请求
我们经常会遇到接口请求依赖另外一个请求的结果,也就是所谓的嵌套请求,嵌套过多的就会出现回调地狱,我们通过FLow来实现一个类似的需求:
lifecycleScope.launch {
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED) {
//将两个flow串联起来 先搜索目的地,然后到达目的地
viewModel.getTokenFlows()
.flatMapConcat {
//第二个flow依赖第一个的结果
viewModel.getUserFlows(it)
}.collect {
tv.text = it ?: "error"
}
}
}组合多个接口的数据
组合多个接口的数据是一个什么样的场景呢,比如说,我们存在请求多个接口,然后把它们的结果合并起来统一展示或者作为另外一个接口的请求参数,试问一下,该如何实现呢:
第一种,一个一个请求,然后合并;
第二种,并发请求,然后全部请求完了合并。
显然,第二种效果比较高效,下面看下代码:
//分别请求电费、水费、网费,Flow之间是并行关系
suspend fun requestElectricCost(): Flow<SpendModel> =
flow {
delay(500)
emit(SpendModel("电费", 10f, 500))
}.flowOn(Dispatchers.IO)
suspend fun requestWaterCost(): Flow<SpendModel> =
flow {
delay(1000)
emit(SpendModel("水费", 20f, 1000))
}.flowOn(Dispatchers.IO)
suspend fun requestInternetCost(): Flow<SpendModel> =
flow {
delay(2000)
emit(SpendModel("网费", 30f, 2000))
}.flowOn(Dispatchers.IO)首先,我们在ViewModel模拟定义了,几个网络请求,接下来合并请求:
lifecycleScope.launch {
val electricFlow = viewModel.requestElectricCost()
val waterFlow = viewModel.requestWaterCost()
val internetFlow = viewModel.requestInternetCost()
val builder = StringBuilder()
var totalCost = 0f
val startTime = System.currentTimeMillis()
//NOTE:注意这里可以多个zip操作符来合并Flow,且多个Flow之间是并行关系
electricFlow.zip(waterFlow) { electric, water ->
totalCost = electric.cost + water.cost
builder.append("${electric.info()},\n").append("${water.info()},\n")
}.zip(internetFlow) { two, internet ->
totalCost += internet.cost
two.append(internet.info()).append(",\n\n总花费:$totalCost")
}.collect {
tv.text = it.append(",总耗时:${System.currentTimeMillis() - startTime} ms")
Log.d(
"ddup",
"${it.append(",总耗时:${System.currentTimeMillis() - startTime} ms")}"
)
}
}运行结果:

我们看到总花费时间,跟最长请求的时间基本一致。
Flow使用注意事项
多个Flow不能放到一个lifecycleScope.launch里去collect{},因为进入collect{}相当于一个死循环,下一行代码永远不会执行;如果就想写到一个lifecycleScope.launch{}里去,可以在内部再开启launch{}子协程去执行。
错误示范:
lifecycleScope.launch {
flow1
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
flow2
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
}正确写法:
lifecycleScope.launch {
launch {
flow1
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
}
launch {
flow2
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect {}
}
}总结
我们从Flow的生命周期,介绍了flow正确使用姿势,避免资源的浪费,到普通的冷流转换成热流,再到StateFlow代替LiveData,以及它的粘性问题,然后通过SharedFlow解决粘性问题,再到常见应用场景,最后到Flow使用注意事项,基本涵盖了Flow大部分特性、应用场景,这也是Flow学习的最终篇。
创作不易,喜欢的麻烦点赞、收藏、评论,以资鼓励 。