为什么要做Boost搜索引擎这个项目,为什么不是其他什么的搜索项目?
此项目的目的就是为了体现搜索功能,并不是为实现什么搜索,因为搜索需要资源,如要搜索的内容,设备需要存储搜素内容所需要的资源等,条件的限制,所以本项目就是通过对Boost库网页文件(*。html)文件进行搜索,该文件数据相对于计算机资源来说,恰到好处,项目可以跑起来,如果搜索内容过大,就不能正常运行。
Boost库文件下载
对下载下来的文件做处理,将网页文件中的,标题,内容,以及url网址,都提取出来。
读取文件:
既然是对网页文件做搜索,就需要程序中有网页文件。
所以就需要将网页文件从下载的目录中,读到程序中,也就是读到内存储存起来,方便后续的处理。
那如何对文件进行读取呢?
这里只记录C++17中使用 boost::filesystem实现遍历文件夹的方法。
通过使用boost::filesystem提供的迭代器和成员函数实现对目录文件的便利。
cpp
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{
namespace fs = boost::filesystem;
fs::path root_path(src_path);
//判断路径是否存在,不存在,就没有必要再往后走了
if(!fs::exists(root_path)){
std::cerr << src_path << " not exists" << std::endl;
return false;
}
//定义一个空的迭代器,用来进行判断递归结束
fs::recursive_directory_iterator end;
for(fs::recursive_directory_iterator iter(root_path); iter != end; iter++){
//判断文件是否是普通文件,html都是普通文件
if(!fs::is_regular_file(*iter)){
continue;
}
if(iter->path().extension() != ".html"){ //判断文件路径名的后缀是否符合要求
continue;
}
//std::cout << "debug: " << iter->path().string() << std::endl;
//当前的路径一定是一个合法的,以.html结束的普通网页文件
files_list->push_back(iter->path().string()); //将所有带路径的html保存在files_list,方便后续进行文本分析
}
return true;
}代码解析:首先用文件目录src_path实例化root_path对象,在判断该对象存不存在,不存在就没必要再向下执行,将迭代器用src_path目录进行实例化,再用迭代器去递归式的遍历该目录文件,如果不是普通文件或者不是网页文件,就不进行读取,反之,将网页文件读取到file_list文件链表中。
网页文件的解析:
将文件读取到file_list中(也就是内存中)之后,接着就需要对网页文件进行解析,解析里面的:标题,内容,url网址。
我们在解析网页文件时,需要了解网页文件的结构,你对结构不了解,就无法进行解析,解析出来也是错的。
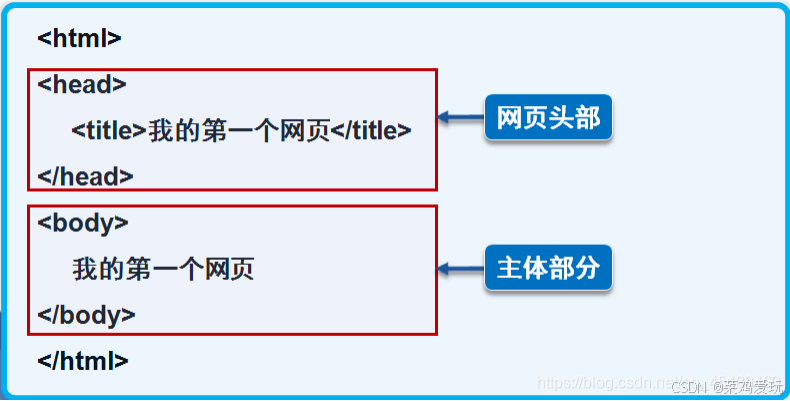
也就是<title>和</title>之间就是标题,<body>和</body>之间就是网页内容。
我们可以利用string中提供的find()找到<title>和</title>的位置,中间就时标题,再利用substr()将标题进行截取,再将标题返回。
cpp
static bool ParseTitle(const std::string &file, std::string *title)
{
std::size_t begin = file.find("<title>");
if(begin == std::string::npos){
return false;
}
std::size_t end = file.find("</title>");
if(end == std::string::npos){
return false;
}
begin += std::string("<title>").size();
if(begin > end){
return false;
}
*title = file.substr(begin, end - begin);
return true;
}然而,网页文件的内容,却不像,文件标题那样容易好找,下图是文件内容的示例图
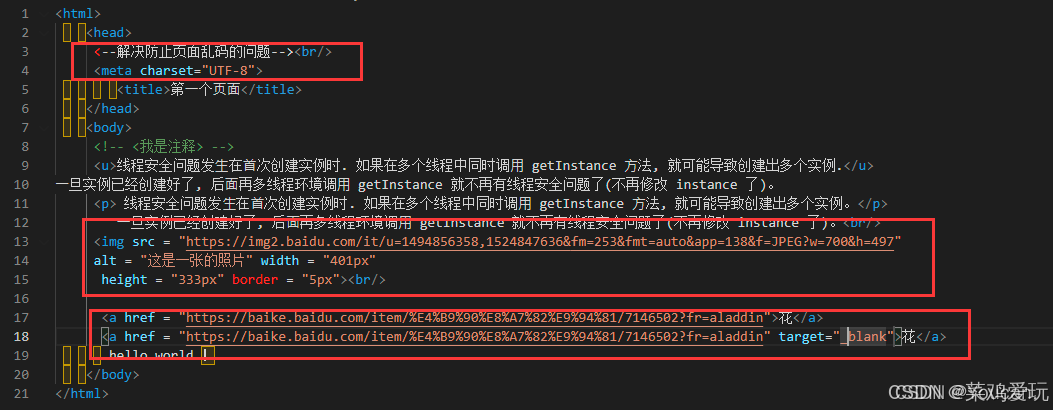
通过上图可以看出,内容是在>和<之间,那我们只需要向上面那样找到>和<之间的内容,将他们返回即可。
我们需要利用了一个简易的状态机进行标记,利用枚举定义两个常量CONTENT和LABLE,分别表示内容和标签,遍历到'>'时就标记CONTENT,遍历到'<'时,就标记为LABLE,然后利用switch语句进行判断和读取。
我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后文本的分隔符,所以这里用' '空格进行分割。
cpp
static bool ParseContent(const std::string &file, std::string *content)
{
//去标签,基于一个简易的状态机
enum status{
LABLE,
CONTENT
};
enum status s = LABLE;
for( char c : file){
switch(s){
case LABLE:
if(c == '>') s = CONTENT;
break;
case CONTENT:
if(c == '<') s = LABLE;
else {
//我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后文本的分隔符
if(c == '\n') c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}构建url
官方url样例
cpp
https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html我们下载下来的url样例
cpp
boost_1_78_0/doc/html/accumulators.html因为我们将下载下来的文件放到了"data/input"目录下,拷贝到我们项目中的样例就变成:data/input/accumulators.html
官方网址:url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
我们下载下来的文件就是官方网址下的一个目录:(所以将前面的"data/input"删除就是官网文档下的文件名)
url_tail = data/input(删除) /accumulators.html -> url_tail = /accumulators.html
最终的网址:url = url_head + url_tail ; 相当于形成了⼀个官网链接。
cpp
static bool ParseUrl(const std::string &file_path, std::string *url)
{
std::string url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
std::string url_tail = file_path.substr(src_path.size());
*url = url_head + url_tail;
return true;
}既然我们已经提取到了,标题,内容,和url网址,那我们就将提取到的这些内容利用结构体组织起来组织起来。
cpp
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results)
{
for(const std::string &file : files_list){
//1. 读取文件,Read();
std::string result;
if(!ns_util::FileUtil::ReadFile(file, &result)){
continue;
}
DocInfo_t doc;
//2. 解析指定的文件,提取title
if(!ParseTitle(result, &doc.title)){
continue;
}
//3. 解析指定的文件,提取content,就是去标签
if(!ParseContent(result, &doc.content)){
continue;
}
//4. 解析指定的文件路径,构建url
if(!ParseUrl(file, &doc.url)){
continue;
}
//done,一定是完成了解析任务,当前文档的相关结果都保存在了doc里面
results->push_back(std::move(doc)); //bug:todo;细节,本质会发生拷贝,效率可能会比较低
//for debug
//ShowDoc(doc);
//break;
}
return true;
}里面运用了std::move()将左值变为右值,vector中提供了移动拷贝和移动赋值,可以很好的将右值拷贝到vector中,减少了一定的拷贝,提高了效率。这个是C++中容器结合右值引用之间的特性设计出来的。
如果不理解右值引用,那就不用了关了,只知道push_back()是将结构体插入vector中即可。
保存处理好的网页文件:
关于std::ofstream向文件中写入数据,这里不做介绍。请参考:
cpp
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
#define SEP '\3'
//按照二进制方式进行写入
std::ofstream out(output, std::ios::out | std::ios::binary);
if(!out.is_open()){
std::cerr << "open " << output << " failed!" << std::endl;
return false;
}
//就可以进行文件内容的写入了
for(auto &item : results){
std::string out_string;
out_string = item.title;
out_string += SEP;
out_string += item.content;
out_string += SEP;
out_string += item.url;
out_string += '\n';
out.write(out_string.c_str(), out_string.size());
}
out.close();
return true;
}以上就是网络文件处理模块的内容,我们将处理好的文件放到"data/raw_html/raw.txt"这个目录下,在接下来的模块中,会对处理好的文件再次操作。
建立索引:
什么是索引,索引该怎么建立?
什么是正排索引?怎么建立?
|------|------|
| 文档ID | 文档内容 |
| 0 | 文档1 |
| 1 | 文档2 |
正排索引的建立,就是将文档ID与文档内容之间进行直接关联。如上表所示。
那问题来了,该如何关联呢?我们可以利用线性表,如数组,数组下标与文档ID正好是对应的,我们将解析出来的数据进行提取,存放到一个包含 标题(title),内容(content),url(网址信息)的结构体,再将结构体放到数组中,这样就建立好了正排索引。
什么是倒排索引?怎么建立?
|----------|--------------|
| 关键词(唯一性) | 文档ID,权重weigh |
| 菜鸡 | 文档2,文档1 |
| 爱玩 | 文档2 |
首先将处理好的数据进行关键词分割,用inverted_index(是map容器,map<关键词,倒排索引拉链>)统计关键词都出现在那些文档中,将关键词出现的这些文档放进倒排索引拉链中,这就行形成了关键词与文档ID之间的对应关系。从上面表可以看出,同一个文档ID是可以出现在不同的倒排索引拉链中的。
然而,刚开始建立索引的过程是有些慢的,很吃系统资源,所以关于搜索内容太大并且服务器资源比较少的话,就会建立失败,因此前面才会下载Boost库的部分文件,也就是网络文件,而不是全部文件。虽然这个过程吗,但是带来的好处,还是不小的,因为索引建立过程是不会进行搜索的,当建立好之后,只要你有搜索内容,我就去inverted_index的map容器中进行查找,找到对应的倒排索引拉链,再返回。
当搜索关键词到来时,我就在inverted_index中利用关键词去找,如果存在这个关键词,那所有与这个关键词相关的文档我都找到了,如果不存在,那真就不存在。
这里的搜索关键词可能不止一个,搜索者会输入一段搜索语句,比如"菜鸡爱玩"可能会被分成"菜""鸡""菜鸡""爱""玩""爱玩"等。
正排索引:
cpp
DocInfo *BuildForwardIndex(const std::string &line)
{
//1. 解析line,字符串切分
//line -> 3 string, title, content, url
std::vector<std::string> results;
const std::string sep = "\3"; //行内分隔符
ns_util::StringUtil::Split(line, &results, sep);
//ns_util::StringUtil::CutString(line, &results, sep);
if(results.size() != 3){
return nullptr;
}
//2. 字符串进行填充到DocIinfo
DocInfo doc;
doc.title = results[0]; //title
doc.content = results[1]; //content
doc.url = results[2]; ///url
doc.doc_id = forward_index.size(); //先进行保存id,在插入,对应的id就是当前doc在vector中的下标!
//3. 插入到正排索引的vector
forward_index.push_back(std::move(doc)); //doc,html文件内容
return &forward_index.back();
}正排索引建立好之后,将构建好的结构体返回回去,交给倒排索引进行构建倒排索引拉链。
因为倒排索引的构建需要文档ID,文档标题和文档内容去进行关键词分割,还有权值的计算。
获取正排索引:
cpp
//根据doc_id找到找到文档内容
DocInfo *GetForwardIndex(uint64_t doc_id)
{
if(doc_id >= forward_index.size()){
std::cerr << "doc_id out range, error!" << std::endl;
return nullptr;
}
return &forward_index[doc_id];
因为正排索引被构建了,所以直接利用文档ID在正排索引中进行查找就可以了。
什么是权值?
权值对文档起着排序的作用,因为每篇文章关于一个话题的侧重点不一样,所有我们就将文档与搜索关键词之间的关系用关键词是在标题,还是在文档内容中出现的数量,以及关键词是在标题,还是在文档内容中的权值(需要你自己进行定义)进行相关的计算。
你认为标题与搜索关键词的相关性大,就将标题的权值设置高点,同理,文档内容也是一样的。
倒排索引:
cpp
bool BuildInvertedIndex(const DocInfo &doc)
{
//DocInfo{title, content, url, doc_id}
//word -> 倒排拉链
struct word_cnt{
int title_cnt;
int content_cnt;
word_cnt():title_cnt(0), content_cnt(0){}
};
std::unordered_map<std::string, word_cnt> word_map; //用来暂存词频的映射表
//对标题进行分词
std::vector<std::string> title_words;
ns_util::JiebaUtil::CutString(doc.title, &title_words);
//if(doc.doc_id == 1572){
// for(auto &s : title_words){
// std::cout << "title: " << s << std::endl;
// }
//}
//对标题进行词频统计
for(std::string s : title_words){
boost::to_lower(s); //需要统一转化成为小写
word_map[s].title_cnt++; //如果存在就获取,如果不存在就新建
}
//对文档内容进行分词
std::vector<std::string> content_words;
ns_util::JiebaUtil::CutString(doc.content, &content_words);
//if(doc.doc_id == 1572){
// for(auto &s : content_words){
// std::cout << "content: " << s << std::endl;
// }
//}
//对内容进行词频统计
for(std::string s : content_words){
boost::to_lower(s);
word_map[s].content_cnt++;
}
#define X 10
#define Y 1
//Hello,hello,HELLO
for(auto &word_pair : word_map){
InvertedElem item;
item.doc_id = doc.doc_id;
item.word = word_pair.first;
item.weight = X*word_pair.second.title_cnt + Y*word_pair.second.content_cnt; //相关性
InvertedList &inverted_list = inverted_index[word_pair.first];
inverted_list.push_back(std::move(item));
}
return true;
}重点代码讲解:
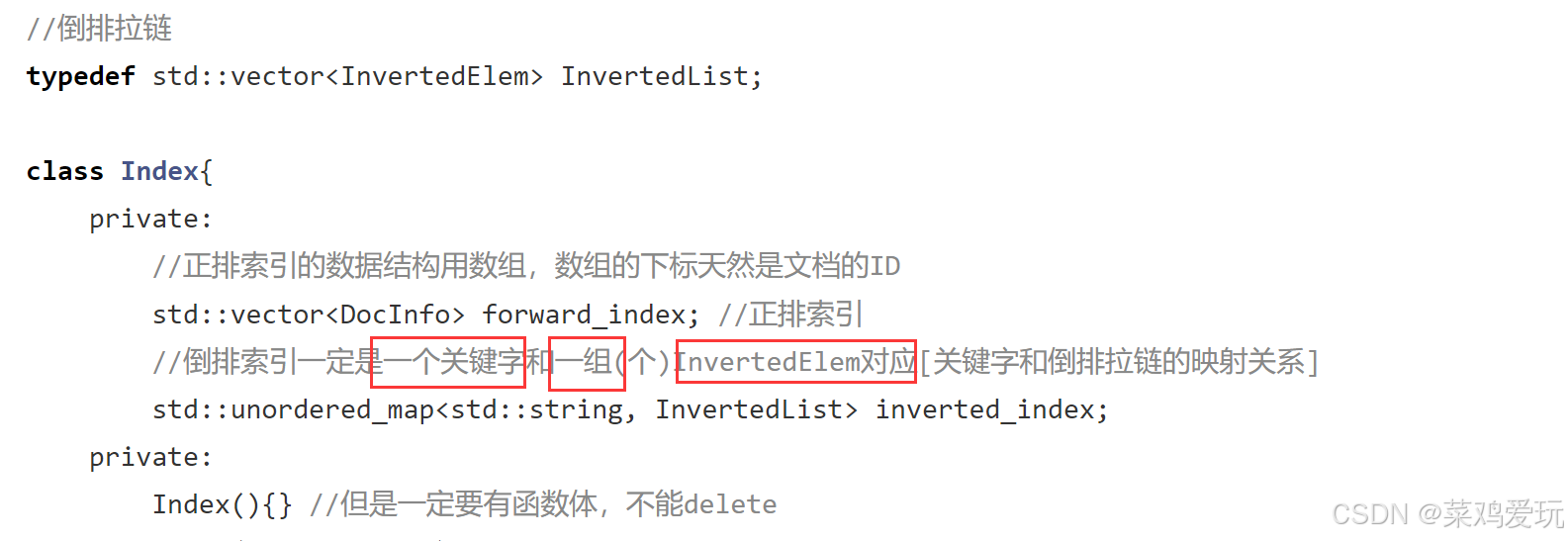
cpp
1 ------ InvertedList &inverted_list = inverted_index[word_pair.first];
2 ------ inverted_list.push_back(std::move(item));倒排索引拉链inverted_index是一个map<关键词,倒排索引拉链>,上面代码第一条就是将关键词对应的倒排索引拉链获取到,再将新的InvertedElem结构体插到倒排索引拉链中。这两条语句是可以合并的,看起来就会有些复杂。
经过上述操作于是就成功建立了的关键词和文档ID之间的关系,也就是说,我输入一段关键词,用分词工具将关键词进行分离,用分离的关键词,在文档(标题,文档内容也进行了分词)中进行查找,因为使用了同一套分词工具,所以不会出现,文档中有该关键词,而搜不到的情况。
构建索引:
cpp
//根据去标签,格式化之后的文档,构建正排和倒排索引
//data/raw_html/raw.txt
bool BuildIndex(const std::string &input) //parse处理完毕的数据交给我
{
std::ifstream in(input, std::ios::in | std::ios::binary);
if(!in.is_open()){
std::cerr << "sorry, " << input << " open error" << std::endl;
return false;
}
std::string line;
int count = 0;
while(std::getline(in, line)){
DocInfo * doc = BuildForwardIndex(line);
if(nullptr == doc){
std::cerr << "build " << line << " error" << std::endl; //for deubg
continue;
}
BuildInvertedIndex(*doc);
count++;
//if(count % 50 == 0){
//std::cout <<"当前已经建立的索引文档: " << count <<std::endl;
LOG(NORMAL, "当前的已经建立的索引文档: " + std::to_string(count));
//}
}
return true;
}首先将处理好的网页文件读取取进来,利用std::ifstream类对文件进行相关操作,因为是以'\n'为间隔,将处理好的网页文件进行了分离,所以就采用getline(in,line)循环将文件中的数据读取到,首先建立正排索引,其次再建立倒排索引,因为倒排索引的建立是基于正排索引的。
获取倒排索引:
cpp
//根据关键字string,获得倒排拉链
InvertedList *GetInvertedList(const std::string &word)
{
auto iter = inverted_index.find(word);
if(iter == inverted_index.end()){
std::cerr << word << " have no InvertedList" << std::endl;
return nullptr;
}
return &(iter->second);
}在倒排索引构建好之后,所有的倒排索引拉链都存放在inverted_index的map容器中,只需要提供关键词进行查找即可,将找到的倒排索引拉链返回出去。
单例模式:
cpp
Index(){} //但是一定要有函数体,不能delete
Index(const Index&) = delete;
Index& operator=(const Index&) = delete;
static Index* instance;
static std::mutex mtx;
public:
~Index(){}
public:
static Index* GetInstance()
{
if(nullptr == instance){
mtx.lock();
if(nullptr == instance){
instance = new Index();
}
mtx.unlock();
}
return instance;
}单例模式,就是禁掉这个类的,拷贝构造和赋值重载,让这个类不能赋给别人,所有对象共用一个instance变量
因为是多线程,会有很用户进行搜素,需要加把锁保证临界区资源不被破坏。
搜索模块:
搜索模块是在服务器构建索引之后进行的,在构建好的服务器上进行关键词搜索。
首先将用户提供的搜索内容进行,关键词分割,将分割好的关键词存放到一个数组中,再去遍历这个数组,里面的每一个元素都是一个搜索关键词,再调用Index索引构建模块中的查找倒排索引函数,找到与关键词相关的文档,再将这些文档存入tokens_map的map容器中。
tokens_map的map容器中存储的是文档ID和struct InvertedElemPrint结构体之间的对应关系。
cpp
struct InvertedElemPrint{
uint64_t doc_id;
int weight;
std::vector<std::string> words;
InvertedElemPrint():doc_id(0), weight(0){}
};该结构体中存放的是这篇文档的文档ID,权值(所有关键词权值的总和),words容器中存的是那些关键词出现在了这篇文档中。我们可以利用这个words容器进行文章摘要的的提取,下面会提到。
将不同关键词出现在同一文档中的权值进行加和,为了体现这篇文章与搜索内容之间的关系,权值越大表明这篇文章与搜索内容具有很强的相关性。
cpp
std::vector<InvertedElemPrint> inverted_list_all;将 std::unordered_map<uint64_t, InvertedElemPrint> tokens_map 中的文档全部放到inverted_list_all的vector容器利用总权值中进行排序。
cpp
std::sort(inverted_list_all.begin(), inverted_list_all.end(),\
[](const InvertedElemPrint &e1, const InvertedElemPrint &e2){
return e1.weight > e2.weight;
});排序语句是一条lambda表达式,你也可以写个仿函数传递给sort系统函数。
cpp
//4.[构建]:根据查找出来的结果,构建json串 -- jsoncpp --通过jsoncpp完成序列化&&反序列化
Json::Value root;
for(auto &item : inverted_list_all){
ns_index::DocInfo * doc = index->GetForwardIndex(item.doc_id);
if(nullptr == doc){
continue;
}
Json::Value elem;
elem["title"] = doc->title;
elem["desc"] = GetDesc(doc->content, item.words[0]); //content是文档的去标签的结果,但是不是我们想要的,我们要的是一部分 TODO
elem["url"] = doc->url;
//for deubg, for delete
elem["id"] = (int)item.doc_id;
elem["weight"] = item.weight; //int->string
root.append(elem);
}
//Json::StyledWriter writer;
Json::FastWriter writer;
*json_string = writer.write(root);最后将vector排好序的数据进行json串的构建,传递出去。 对于json相关知识不太了解的话,请搜所相关资料简单学习。
cpp
//query: 搜索关键字
//json_string: 返回给用户浏览器的搜索结果
void Search(const std::string &query, std::string *json_string)
{
//1.[分词]:对我们的query进行按照searcher的要求进行分词
std::vector<std::string> words;
ns_util::JiebaUtil::CutString(query, &words);
//2.[触发]:就是根据分词的各个"词",进行index查找,建立index是忽略大小写,所以搜索,关键字也需要
//ns_index::InvertedList inverted_list_all; //内部InvertedElem
std::vector<InvertedElemPrint> inverted_list_all;
std::unordered_map<uint64_t, InvertedElemPrint> tokens_map;
for(std::string word : words){
boost::to_lower(word);
ns_index::InvertedList *inverted_list = index->GetInvertedList(word);
if(nullptr == inverted_list){
continue;
}
//不完美的地方:暂时可以交给大家 , 你/是/一个/好人 100
//inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());
for(const auto &elem : *inverted_list){
auto &item = tokens_map[elem.doc_id]; //[]:如果存在直接获取,如果不存在新建
//item一定是doc_id相同的print节点
item.doc_id = elem.doc_id;
item.weight += elem.weight;
item.words.push_back(elem.word);
}
}
for(const auto &item : tokens_map){
inverted_list_all.push_back(std::move(item.second));
}
//3.[合并排序]:汇总查找结果,按照相关性(weight)降序排序
//std::sort(inverted_list_all.begin(), inverted_list_all.end(),\
// [](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2){
// return e1.weight > e2.weight;
// });
std::sort(inverted_list_all.begin(), inverted_list_all.end(),\
[](const InvertedElemPrint &e1, const InvertedElemPrint &e2){
return e1.weight > e2.weight;
});
//4.[构建]:根据查找出来的结果,构建json串 -- jsoncpp --通过jsoncpp完成序列化&&反序列化
Json::Value root;
for(auto &item : inverted_list_all){
ns_index::DocInfo * doc = index->GetForwardIndex(item.doc_id);
if(nullptr == doc){
continue;
}
Json::Value elem;
elem["title"] = doc->title;
elem["desc"] = GetDesc(doc->content, item.words[0]); //content是文档的去标签的结果,但是不是我们想要的,我们要的是一部分 TODO
elem["url"] = doc->url;
//for deubg, for delete
elem["id"] = (int)item.doc_id;
elem["weight"] = item.weight; //int->string
root.append(elem);
}
//Json::StyledWriter writer;
Json::FastWriter writer;
*json_string = writer.write(root);
}文档摘要:
在讲struct InvertedElemPrint结构体时,我就提过摘要的获取.
cpp
struct InvertedElemPrint{
uint64_t doc_id;
int weight;
std::vector<std::string> words;
InvertedElemPrint():doc_id(0), weight(0){}
};这里详细讲一下,对于words容器中存的是用户传上来的搜索关键词,是部分也可能是全部,这不重要。
我们在实现摘要提取时,是以words中第一个关键词为准。这里有人会问,为什么这样做?
原因是:我想这么做,图方便。但是有没有更优的办法,当然有,不然我也不肯提这个问题。
那怎么做呢?
cpp
for(std::string word : words){
boost::to_lower(word);
ns_index::InvertedList *inverted_list = index->GetInvertedList(word);
if(nullptr == inverted_list){
continue;
}
//不完美的地方:暂时可以交给大家 , 你/是/一个/好人 100
//inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());
for(const auto &elem : *inverted_list){
auto &item = tokens_map[elem.doc_id]; //[]:如果存在直接获取,如果不存在新建
//item一定是doc_id相同的print节点
item.doc_id = elem.doc_id;
item.weight += elem.weight;
item.words.push_back(elem.word);
}
}上面代码是Search()函数中,提取用户搜索关键词的倒排索引拉链,大家应该不陌生了吧。其实看懂上面的Search()函数,也可以想出来这样的解决方法,就是利用该关键词对应的权值进行排序。
我么可以创建一个优先级队列,再创建一个结构体,这个结构体成员就是:该关键词 和 该关键词对应的权值,再写一个仿函数compare()比较函数(利用权值去比较),将存进去的这些结构体进行排序,优先级队列实则就是一个大堆,第一个元素就是权值最大的,最后再对优先级队列进行遍历,将里面的元素全部插入到words容器中,这样就实现了关键词的排序。
我们在传入第一个关键词,给GetDesc()函数,去寻找该关键词周围的摘要。
cpp
std::string GetDesc(const std::string &html_content, const std::string &word)
{
//找到word在html_content中的首次出现,然后往前找50字节(如果没有,从begin开始),往后找100字节(如果没有,到end就可以的)
//截取出这部分内容
const int prev_step = 50;
const int next_step = 100;
//1. 找到首次出现
auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){
return (std::tolower(x) == std::tolower(y));
});
if(iter == html_content.end()){
return "None1";
}
int pos = std::distance(html_content.begin(), iter);
//2. 获取start,end , std::size_t 无符号整数
int start = 0;
int end = html_content.size() - 1;
//如果之前有50+字符,就更新开始位置
if(pos > start + prev_step) start = pos - prev_step;
if(pos < end - next_step) end = pos + next_step;
//3. 截取子串,return
if(start >= end) return "None2";
std::string desc = html_content.substr(start, end - start);
desc += "...";
return desc;
GetDesc()函数这个函数没什么技术难度,就是在简单的字符串查找,以及字符串截取,至于截取多少,因人而异,同时也要切合实际。将截取的摘要放到json串中。
服务器初始化:
cpp
void InitSearcher(const std::string &input)
{
//1. 获取或者创建index对象
index = ns_index::Index::GetInstance();
//std::cout << "获取index单例成功..." << std::endl;
LOG(NORMAL, "获取index单例成功...");
//2. 根据index对象建立索引
index->BuildIndex(input);
//std::cout << "建立正排和倒排索引成功..." << std::endl;
LOG(NORMAL, "建立正排和倒排索引成功...");
}
服务器初始这段代码,就是在,服务器跑起来的那一刻运行的,之后就不会再运行,除非重启服务器,同时这段代码也包含了索引的构建。