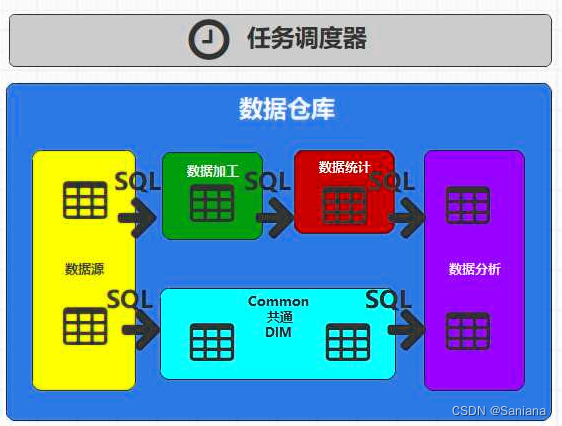
数据仓库
- 基本概念
-
- [数据库(database)和数据仓库(Data Warehouse)的异同](#数据库(database)和数据仓库(Data Warehouse)的异同)
- 整体架构
- 分层架构
-
- 方法论
- 何为分层
- [第一层:数据源(ODS ER模型)](#第一层:数据源(ODS ER模型))
-
- 设计要点
- 日志表
- 业务表
-
- 1活动信息表(全量表)
- 2活动规则表(全量表)
- 3一级品类表(全量表)
- 4二级品类表(全量表)
- 5三级品类表(全量表)
- 6编码字典表(全量表)
- 7省份表(全量表)
- 8地区表(全量表)
- 9品牌表(全量表)
- 10购物车表(全量表)
- 11优惠券信息表(全量表)
- 12商品平台属性表(全量表)
- 13商品表(全量表)
- 14商品销售属性值表(全量表)
- 15SPU表(全量表)
- 16营销坑位表(全量表)
- 17营销渠道表(全量表)
- 18购物车表(增量表)
- 19评论表(增量表)
- 20优惠券领用表(增量表)
- 21收藏表(增量表)
- 22订单明细表(增量表)
- 23订单明细活动关联表(增量表)
- 24订单明细优惠券关联表(增量表)
- 25订单表(增量表)
- 26退单表(增量表)
- 27订单状态流水表(增量表)
- 28支付表(增量表)
- 29退款表(增量表)
- 30用户表(增量表)
- 31数据装载脚本
- [第二层:数据加工(DWD data warehouse detail)](#第二层:数据加工(DWD data warehouse detail))
- 从当前表中取数据后再放回去需考虑去重问题,增加retry的容错性
- [第三层:数据统计(DWS data warehouse summary 提高性能的关键层)](#第三层:数据统计(DWS data warehouse summary 提高性能的关键层))
- [第四层:数据分析(ADS application data service)](#第四层:数据分析(ADS application data service))
- [第五层:共通层(DIM dimension)](#第五层:共通层(DIM dimension))
- [CTE : 共通表表达式](#CTE : 共通表表达式)
- 拉链表设计
- 任务调度器
基本概念
本质是对数据进行加工处理后对外提供数据服务
数据库(database)和数据仓库(Data Warehouse)的异同
- 数据库用于存储企业基础,核心的业务数据
- 从数据来源进行区分
- 数据库:企业的业务系统
- 数据仓库:数据库(后台的后台)
- 从数据存储进行区分
- 数据库:存储的目的为了可以快速进行数据查询操作
索引 : SQL
存储方式:行式存储
数据量:不能存储海量数据 - 数据仓库:存储的目的为了可以快速进行统计分析
索引 : 没有索引(k-v)
存储方式:列式存储
数据量:必须存储海量数据
- 数据库:存储的目的为了可以快速进行数据查询操作
- 从数据价值进行区分
- 数据库 :保障企业业务系统的执行
事务(回滚) - 数据仓库 :统计分析的结果可以为企业的经营决策提供数据依据
没有事务
数据仓库不是数据流转的终点 :可视化才是数据的终点
- 数据库 :保障企业业务系统的执行

整体架构
Spark : 数据的统计分析

数据仓库:数据的统计分析


数据仓库不能直接对接MySQL数据库作为数据源!
- 数据库不是为了数据仓库服务的。数据仓库如果直接对象数据库,会导致数据库的性能降低
- 数据库不能存储海量数据。数据仓库必须获取海量数据
- 数据库采用行式存储。数据仓库为了提高统计分析效率,所以需要列式存储
数据仓库应该增加自己的数据源

数据仓库的数据源中的数据应该和MySQL数据库中的数据保持一致
数据仓库的数据源应该不断融合(汇总)MySQL数据库中的数据
将数据库的数据汇总的到数据仓库数据源的过程,一般称之为数据同步,也称之为数据采集

分层架构
数据仓库计算周期为1天:1天统计一回数据结果
方法论
ER模型(建模理论)
ER(Entity Relationship)(实体关系)模型
采用面向对象的方式设计表(和Java一样)
- 将对象理解为表
- 将对象之间的关系理解为表之间的关系
维度模型
事实 :行为所产生的事情(数据)
维度:分析数据的角度(状态)
何为分层
Spark中的方法可能会含有shuffle功能,
shuffle操作会将完整的计算流程一分为二,会分为2个阶段(Stage),前面一个阶段称之为Map阶段,后面的阶段称之为Reduce阶段,
shuffle中前一个阶段的任务不执行完,后面的阶段的任务不允许执行的,
Task Pool(任务池) - 任务调度(FIFO, FAIR)。
数据仓库 也存在同样的问题,将整个计算流程分为了4段,
在数据仓库中不称之为段,一般称之为层,每一层有特殊的含义和特殊的功能
前面一层的数据没有处理完,后面一层的数据没有办法处理

第一层:数据源(ODS ER模型)
功能:
-
为整个数据仓库作为数据来源
-
不断汇总业务数据和日志数据
数据量非常大:海量数据 -> 考虑资源问题:使用最少的资源存储最多的资源(考虑使用压缩算法gzip、lzo、snappy);考虑网络资源:考虑传输方式,数据尽可能不变(格式、压缩方式、存储方式)
统计 本质上就是对行为数据进行统计
分析本质上就是站在什么角度对统计结果进行分析
sql
-- ODS
-- 1. ODS层表建模方式:ER模型
-- 2. 数据格式不变,数据压缩方式 gzip
-- 3. 表名
-- 分层标记(ods_) + 同步数据的表名 + 增量/全量(inc/full)
-- 增量,全量
设计要点
(1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。
(2)ODS层要保存全部历史数据,故其压缩格式应选择压缩比较高的,此处选择gzip。
(3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
日志表
1)建表语句
sql
DROP TABLE IF EXISTS ods_log_inc;
CREATE EXTERNAL TABLE ods_log_inc
(
`common` STRUCT<ar :STRING,
ba :STRING,
ch :STRING,
is_new :STRING,
md :STRING,
mid :STRING,
os :STRING,
sid :STRING,
uid :STRING,
vc :STRING> COMMENT '公共信息',
`page` STRUCT<during_time :STRING,
item :STRING,
item_type :STRING,
last_page_id :STRING,
page_id :STRING,
from_pos_id :STRING,
from_pos_seq :STRING,
refer_id :STRING> COMMENT '页面信息',
`actions` ARRAY<STRUCT<action_id:STRING,
item:STRING,
item_type:STRING,
ts:BIGINT>> COMMENT '动作信息',
`displays` ARRAY<STRUCT<display_type :STRING,
item :STRING,
item_type :STRING,
`pos_seq` :STRING,
pos_id :STRING>> COMMENT '曝光信息',
`start` STRUCT<entry :STRING,
first_open :BIGINT,
loading_time :BIGINT,
open_ad_id :BIGINT,
open_ad_ms :BIGINT,
open_ad_skip_ms :BIGINT> COMMENT '启动信息',
`err` STRUCT<error_code:BIGINT,
msg:STRING> COMMENT '错误信息',
`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_log_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');2)数据装载
sql
load data inpath '/origin_data/gmall/log/topic_log/2022-06-08' into table ods_log_inc partition(dt='2022-06-08');3)每日数据装载脚本
(1)在hadoop102的/home/atguigu/bin目录下创建hdfs_to_ods_log.sh
sql
vim hdfs_to_ods_log.sh(2)编写如下内容
sql
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo ================== 日志日期为 $do_date ==================
sql="
load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log_inc partition(dt='$do_date');
"
hive -e "$sql"(3)增加脚本执行权限
sql
chmod +x hdfs_to_ods_log.sh(4)脚本用法
sql
hdfs_to_ods_log.sh 2022-06-08业务表
1活动信息表(全量表)
sql
DROP TABLE IF EXISTS ods_activity_info_full;
CREATE EXTERNAL TABLE ods_activity_info_full
(
`id` STRING COMMENT '活动id',
`activity_name` STRING COMMENT '活动名称',
`activity_type` STRING COMMENT '活动类型',
`activity_desc` STRING COMMENT '活动描述',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_activity_info_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');2活动规则表(全量表)
sql
DROP TABLE IF EXISTS ods_activity_rule_full;
CREATE EXTERNAL TABLE ods_activity_rule_full
(
`id` STRING COMMENT '编号',
`activity_id` STRING COMMENT '活动ID',
`activity_type` STRING COMMENT '活动类型',
`condition_amount` DECIMAL(16, 2) COMMENT '满减金额',
`condition_num` BIGINT COMMENT '满减件数',
`benefit_amount` DECIMAL(16, 2) COMMENT '优惠金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '优惠折扣',
`benefit_level` STRING COMMENT '优惠级别',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '活动规则表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_activity_rule_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');3一级品类表(全量表)
sql
DROP TABLE IF EXISTS ods_base_category1_full;
CREATE EXTERNAL TABLE ods_base_category1_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '分类名称',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '一级品类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_category1_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');4二级品类表(全量表)
sql
DROP TABLE IF EXISTS ods_base_category2_full;
CREATE EXTERNAL TABLE ods_base_category2_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '二级分类名称',
`category1_id` STRING COMMENT '一级分类编号',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '二级品类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_category2_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');5三级品类表(全量表)
sql
DROP TABLE IF EXISTS ods_base_category3_full;
CREATE EXTERNAL TABLE ods_base_category3_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '三级分类名称',
`category2_id` STRING COMMENT '二级分类编号',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '三级品类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_category3_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');6编码字典表(全量表)
sql
DROP TABLE IF EXISTS ods_base_dic_full;
CREATE EXTERNAL TABLE ods_base_dic_full
(
`dic_code` STRING COMMENT '编号',
`dic_name` STRING COMMENT '编码名称',
`parent_code` STRING COMMENT '父编号',
`create_time` STRING COMMENT '创建日期',
`operate_time` STRING COMMENT '修改日期'
) COMMENT '编码字典表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_dic_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');7省份表(全量表)
sql
DROP TABLE IF EXISTS ods_base_province_full;
CREATE EXTERNAL TABLE ods_base_province_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '省份名称',
`region_id` STRING COMMENT '地区ID',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT '旧版国际标准地区编码,供可视化使用',
`iso_3166_2` STRING COMMENT '新版国际标准地区编码,供可视化使用',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '省份表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_province_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');8地区表(全量表)
sql
DROP TABLE IF EXISTS ods_base_region_full;
CREATE EXTERNAL TABLE ods_base_region_full
(
`id` STRING COMMENT '地区ID',
`region_name` STRING COMMENT '地区名称',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '地区表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_region_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');9品牌表(全量表)
sql
DROP TABLE IF EXISTS ods_base_trademark_full;
CREATE EXTERNAL TABLE ods_base_trademark_full
(
`id` STRING COMMENT '编号',
`tm_name` STRING COMMENT '品牌名称',
`logo_url` STRING COMMENT '品牌LOGO的图片路径',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '品牌表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_trademark_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');10购物车表(全量表)
sql
DROP TABLE IF EXISTS ods_cart_info_full;
CREATE EXTERNAL TABLE ods_cart_info_full
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户ID',
`sku_id` STRING COMMENT 'SKU_ID',
`cart_price` DECIMAL(16, 2) COMMENT '放入购物车时价格',
`sku_num` BIGINT COMMENT '数量',
`img_url` BIGINT COMMENT '商品图片地址',
`sku_name` STRING COMMENT 'SKU名称 (冗余)',
`is_checked` STRING COMMENT '是否被选中',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间',
`is_ordered` STRING COMMENT '是否已经下单',
`order_time` STRING COMMENT '下单时间'
) COMMENT '购物车全量表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_cart_info_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');11优惠券信息表(全量表)
sql
DROP TABLE IF EXISTS ods_coupon_info_full;
CREATE EXTERNAL TABLE ods_coupon_info_full
(
`id` STRING COMMENT '购物券编号',
`coupon_name` STRING COMMENT '购物券名称',
`coupon_type` STRING COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
`condition_amount` DECIMAL(16, 2) COMMENT '满额数',
`condition_num` BIGINT COMMENT '满件数',
`activity_id` STRING COMMENT '活动编号',
`benefit_amount` DECIMAL(16, 2) COMMENT '减免金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '折扣',
`create_time` STRING COMMENT '创建时间',
`range_type` STRING COMMENT '范围类型 1、商品(SPUID) 2、品类(三级品类id) 3、品牌',
`limit_num` BIGINT COMMENT '最多领用次数',
`taken_count` BIGINT COMMENT '已领用次数',
`start_time` STRING COMMENT '可以领取的开始时间',
`end_time` STRING COMMENT '可以领取的结束时间',
`operate_time` STRING COMMENT '修改时间',
`expire_time` STRING COMMENT '过期时间',
`range_desc` STRING COMMENT '范围描述'
) COMMENT '优惠券信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_coupon_info_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');12商品平台属性表(全量表)
sql
DROP TABLE IF EXISTS ods_sku_attr_value_full;
CREATE EXTERNAL TABLE ods_sku_attr_value_full
(
`id` STRING COMMENT '编号',
`attr_id` STRING COMMENT '平台属性ID',
`value_id` STRING COMMENT '平台属性值ID',
`sku_id` STRING COMMENT 'SKU_ID',
`attr_name` STRING COMMENT '平台属性名称',
`value_name` STRING COMMENT '平台属性值名称',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '商品平台属性表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_sku_attr_value_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');13商品表(全量表)
sql
DROP TABLE IF EXISTS ods_sku_info_full;
CREATE EXTERNAL TABLE ods_sku_info_full
(
`id` STRING COMMENT 'SKU_ID',
`spu_id` STRING COMMENT 'SPU_ID',
`price` DECIMAL(16, 2) COMMENT '价格',
`sku_name` STRING COMMENT 'SKU名称',
`sku_desc` STRING COMMENT 'SKU规格描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`tm_id` STRING COMMENT '品牌ID',
`category3_id` STRING COMMENT '三级品类ID',
`sku_default_img` STRING COMMENT '默认显示图片地址',
`is_sale` STRING COMMENT '是否在售',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '商品表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_sku_info_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');14商品销售属性值表(全量表)
sql
DROP TABLE IF EXISTS ods_sku_sale_attr_value_full;
CREATE EXTERNAL TABLE ods_sku_sale_attr_value_full
(
`id` STRING COMMENT '编号',
`sku_id` STRING COMMENT 'SKU_ID',
`spu_id` STRING COMMENT 'SPU_ID',
`sale_attr_value_id` STRING COMMENT '销售属性值ID',
`sale_attr_id` STRING COMMENT '销售属性ID',
`sale_attr_name` STRING COMMENT '销售属性名称',
`sale_attr_value_name` STRING COMMENT '销售属性值名称',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '商品销售属性值表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_sku_sale_attr_value_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');15SPU表(全量表)
sql
DROP TABLE IF EXISTS ods_spu_info_full;
CREATE EXTERNAL TABLE ods_spu_info_full
(
`id` STRING COMMENT 'SPU_ID',
`spu_name` STRING COMMENT 'SPU名称',
`description` STRING COMMENT '描述信息',
`category3_id` STRING COMMENT '三级品类ID',
`tm_id` STRING COMMENT '品牌ID',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT 'SPU表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_spu_info_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');16营销坑位表(全量表)
sql
DROP TABLE IF EXISTS ods_promotion_pos_full;
CREATE EXTERNAL TABLE ods_promotion_pos_full
(
`id` STRING COMMENT '营销坑位ID',
`pos_location` STRING COMMENT '营销坑位位置',
`pos_type` STRING COMMENT '营销坑位类型:banner,宫格,列表,瀑布',
`promotion_type` STRING COMMENT '营销类型:算法、固定、搜索',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '营销坑位表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_promotion_pos_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');17营销渠道表(全量表)
sql
DROP TABLE IF EXISTS ods_promotion_refer_full;
CREATE EXTERNAL TABLE ods_promotion_refer_full
(
`id` STRING COMMENT '外部营销渠道ID',
`refer_name` STRING COMMENT '外部营销渠道名称',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '营销渠道表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_promotion_refer_full/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');18购物车表(增量表)
sql
DROP TABLE IF EXISTS ods_cart_info_inc;
CREATE EXTERNAL TABLE ods_cart_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
user_id :STRING,
sku_id :STRING,
cart_price :DECIMAL(16, 2),
sku_num :BIGINT,
img_url :STRING,
sku_name :STRING,
is_checked :STRING,
create_time :STRING,
operate_time :STRING,
is_ordered :STRING,
order_time:STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '购物车增量表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_cart_info_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');19评论表(增量表)
sql
DROP TABLE IF EXISTS ods_comment_info_inc;
CREATE EXTERNAL TABLE ods_comment_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
user_id :STRING,
nick_name :STRING,
head_img :STRING,
sku_id :STRING,
spu_id :STRING,
order_id :STRING,
appraise :STRING,
comment_txt :STRING,
create_time :STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '评论表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_comment_info_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');20优惠券领用表(增量表)
sql
DROP TABLE IF EXISTS ods_coupon_use_inc;
CREATE EXTERNAL TABLE ods_coupon_use_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
coupon_id :STRING,
user_id :STRING,
order_id :STRING,
coupon_status :STRING,
get_time :STRING,
using_time:STRING,
used_time :STRING,expire_time :STRING,
create_time :STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '优惠券领用表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_coupon_use_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');21收藏表(增量表)
sql
DROP TABLE IF EXISTS ods_favor_info_inc;
CREATE EXTERNAL TABLE ods_favor_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
user_id :STRING,
sku_id :STRING,
spu_id :STRING,
is_cancel :STRING,
create_time :STRING,
operate_time:STRING> COMMENT '数据',
`old` MAP<STRING,
STRING> COMMENT '旧值'
) COMMENT '收藏表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_favor_info_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');22订单明细表(增量表)
sql
DROP TABLE IF EXISTS ods_order_detail_inc;
CREATE EXTERNAL TABLE ods_order_detail_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
order_id :STRING,
sku_id :STRING,
sku_name :STRING,
img_url :STRING,
order_price:DECIMAL(16, 2),
sku_num :BIGINT,
create_time :STRING,
source_type :STRING,
source_id :STRING,
split_total_amount:DECIMAL(16, 2),
split_activity_amount :DECIMAL(16, 2),
split_coupon_amount:DECIMAL(16, 2),
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,
STRING> COMMENT '旧值'
) COMMENT '订单明细表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_detail_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');23订单明细活动关联表(增量表)
sql
DROP TABLE IF EXISTS ods_order_detail_activity_inc;
CREATE EXTERNAL TABLE ods_order_detail_activity_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
order_id :STRING,
order_detail_id :STRING,
activity_id :STRING,
activity_rule_id :STRING,
sku_id:STRING,
create_time :STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单明细活动关联表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_detail_activity_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');24订单明细优惠券关联表(增量表)
sql
DROP TABLE IF EXISTS ods_order_detail_coupon_inc;
CREATE EXTERNAL TABLE ods_order_detail_coupon_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
order_id :STRING,
order_detail_id :STRING,
coupon_id :STRING,
coupon_use_id :STRING,
sku_id:STRING,
create_time :STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单明细优惠券关联表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_detail_coupon_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');25订单表(增量表)
sql
DROP TABLE IF EXISTS ods_order_info_inc;
CREATE EXTERNAL TABLE ods_order_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
consignee :STRING,
consignee_tel :STRING,
total_amount :DECIMAL(16, 2),
order_status :STRING,
user_id:STRING,
payment_way :STRING,
delivery_address :STRING,
order_comment :STRING,
out_trade_no :STRING,
trade_body:STRING,
create_time :STRING,
operate_time :STRING,
expire_time :STRING,
process_status :STRING,
tracking_no:STRING,
parent_order_id :STRING,
img_url :STRING,
province_id :STRING,
activity_reduce_amount:DECIMAL(16, 2),
coupon_reduce_amount :DECIMAL(16, 2),
original_total_amount :DECIMAL(16, 2),
freight_fee:DECIMAL(16, 2),
freight_fee_reduce :DECIMAL(16, 2),
refundable_time :DECIMAL(16, 2)> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_info_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');26退单表(增量表)
sql
DROP TABLE IF EXISTS ods_order_refund_info_inc;
CREATE EXTERNAL TABLE ods_order_refund_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
user_id :STRING,
order_id :STRING,
sku_id :STRING,
refund_type :STRING,
refund_num :BIGINT,
refund_amount:DECIMAL(16, 2),
refund_reason_type :STRING,
refund_reason_txt :STRING,
refund_status :STRING,
create_time:STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '退单表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_refund_info_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');27订单状态流水表(增量表)
sql
DROP TABLE IF EXISTS ods_order_status_log_inc;
CREATE EXTERNAL TABLE ods_order_status_log_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
order_id :STRING,
order_status :STRING,
create_time :STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单状态流水表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_status_log_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');28支付表(增量表)
sql
DROP TABLE IF EXISTS ods_payment_info_inc;
CREATE EXTERNAL TABLE ods_payment_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
out_trade_no :STRING,
order_id :STRING,
user_id :STRING,
payment_type :STRING,
trade_no:STRING,
total_amount :DECIMAL(16, 2),
subject :STRING,
payment_status :STRING,
create_time :STRING,
callback_time:STRING,
callback_content :STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '支付表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_payment_info_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');29退款表(增量表)
sql
DROP TABLE IF EXISTS ods_refund_payment_inc;
CREATE EXTERNAL TABLE ods_refund_payment_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
out_trade_no :STRING,
order_id :STRING,
sku_id :STRING,
payment_type :STRING,
trade_no :STRING,
total_amount:DECIMAL(16, 2),
subject :STRING,
refund_status :STRING,
create_time :STRING,
callback_time :STRING,
callback_content:STRING,
operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '退款表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_refund_payment_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');30用户表(增量表)
sql
DROP TABLE IF EXISTS ods_user_info_inc;
CREATE EXTERNAL TABLE ods_user_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,
login_name :STRING,
nick_name :STRING,
passwd :STRING,
name :STRING,
phone_num :STRING,
email:STRING,
head_img :STRING,
user_level :STRING,
birthday :STRING,
gender :STRING,
create_time :STRING,
operate_time:STRING,
status :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '用户表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_user_info_inc/'
TBLPROPERTIES ('compression.codec'='org.apache.hadoop.io.compress.GzipCodec');31数据装载脚本
(1)在hadoop102的/home/atguigu/bin目录下创建hdfs_to_ods_db.sh
bash
vim hdfs_to_ods_db.sh(2)编写如下内容
shell
#!/bin/bash
APP=gmall
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
load_data(){
sql=""
for i in $*; do
#判断路径是否存在
hadoop fs -test -e /origin_data/$APP/db/${i:4}/$do_date
#路径存在方可装载数据
if [[ $? = 0 ]]; then
sql=$sql"load data inpath '/origin_data/$APP/db/${i:4}/$do_date' OVERWRITE into table ${APP}.$i partition(dt='$do_date');"
fi
done
hive -e "$sql"
}
case $1 in
"ods_activity_info_full")
load_data "ods_activity_info_full"
;;
"ods_activity_rule_full")
load_data "ods_activity_rule_full"
;;
"ods_base_category1_full")
load_data "ods_base_category1_full"
;;
"ods_base_category2_full")
load_data "ods_base_category2_full"
;;
"ods_base_category3_full")
load_data "ods_base_category3_full"
;;
"ods_base_dic_full")
load_data "ods_base_dic_full"
;;
"ods_base_province_full")
load_data "ods_base_province_full"
;;
"ods_base_region_full")
load_data "ods_base_region_full"
;;
"ods_base_trademark_full")
load_data "ods_base_trademark_full"
;;
"ods_cart_info_full")
load_data "ods_cart_info_full"
;;
"ods_coupon_info_full")
load_data "ods_coupon_info_full"
;;
"ods_sku_attr_value_full")
load_data "ods_sku_attr_value_full"
;;
"ods_sku_info_full")
load_data "ods_sku_info_full"
;;
"ods_sku_sale_attr_value_full")
load_data "ods_sku_sale_attr_value_full"
;;
"ods_spu_info_full")
load_data "ods_spu_info_full"
;;
"ods_promotion_pos_full")
load_data "ods_promotion_pos_full"
;;
"ods_promotion_refer_full")
load_data "ods_promotion_refer_full"
;;
"ods_cart_info_inc")
load_data "ods_cart_info_inc"
;;
"ods_comment_info_inc")
load_data "ods_comment_info_inc"
;;
"ods_coupon_use_inc")
load_data "ods_coupon_use_inc"
;;
"ods_favor_info_inc")
load_data "ods_favor_info_inc"
;;
"ods_order_detail_inc")
load_data "ods_order_detail_inc"
;;
"ods_order_detail_activity_inc")
load_data "ods_order_detail_activity_inc"
;;
"ods_order_detail_coupon_inc")
load_data "ods_order_detail_coupon_inc"
;;
"ods_order_info_inc")
load_data "ods_order_info_inc"
;;
"ods_order_refund_info_inc")
load_data "ods_order_refund_info_inc"
;;
"ods_order_status_log_inc")
load_data "ods_order_status_log_inc"
;;
"ods_payment_info_inc")
load_data "ods_payment_info_inc"
;;
"ods_refund_payment_inc")
load_data "ods_refund_payment_inc"
;;
"ods_user_info_inc")
load_data "ods_user_info_inc"
;;
"all")
load_data "ods_activity_info_full" "ods_activity_rule_full" "ods_base_category1_full" "ods_base_category2_full" "ods_base_category3_full" "ods_base_dic_full" "ods_base_province_full" "ods_base_region_full" "ods_base_trademark_full" "ods_cart_info_full" "ods_coupon_info_full" "ods_sku_attr_value_full" "ods_sku_info_full" "ods_sku_sale_attr_value_full" "ods_spu_info_full" "ods_promotion_pos_full" "ods_promotion_refer_full" "ods_cart_info_inc" "ods_comment_info_inc" "ods_coupon_use_inc" "ods_favor_info_inc" "ods_order_detail_inc" "ods_order_detail_activity_inc" "ods_order_detail_coupon_inc" "ods_order_info_inc" "ods_order_refund_info_inc" "ods_order_status_log_inc" "ods_payment_info_inc" "ods_refund_payment_inc" "ods_user_info_inc"
;;
esac(3)增加脚本执行权限
bash
chmod +x hdfs_to_ods_db.sh(4)脚本用法
bash
hdfs_to_ods_db.sh all 2022-06-08第二层:数据加工(DWD data warehouse detail)
功能:将数据源中的数据进行加工处理(判空、无效)
为了后续统计分析做数据准备
数据量非常大,所以分离出了DIM层将数据整合
压缩方式:snappy
事实表设计(事务型事实表)
-- DWD
-- Data Warehouse Detail
-- detail : 详细,明细
-- DWD层表主要设计的目的为了统计分析做准备
-- 表中主要保存的是行为数据
-- 多个行为数据中如果存在共通性的内容,那么可以提炼出来形成DIM层维度表的数据
-- 表的设计要点
-- 表的设计要依据维度建模理论中的事实表
-- 表设计时需要orc列式存储以及snappy压缩
-- 命名规范:
-- 分层标记(dwd_) + 数据域(分类) + 原子性行为名称 + 增量/全量(inc/full)
-- 绝大多数的行为数据都是增量数据采集
-- 特殊情况例外,可以采用全量方式实现。
-- dwd_user_login_success_inc
-- 事实表
-- 维度引用 + 度量值(行为产生时可以用于统计分析的数值:金额,数量,个数)
-- 事实表会根据场景分为3大类:
-- 1. 事务型事实表
-- 行为是原子性
-- 用户登录(非原子)
-- 用户登录成功(原子)
-- 用户登录失败(原子)
-- 粒度:描述一行数据的详细程度
-- 描述的越详细(维度越多),粒度越细
-- 描述的越简单(维度越多),粒度越粗
-- 设计步骤:
-- 1. 选择业务过程 :确定表
-- 2. 声明粒度:确定行
-- 3. 确认维度:确定列
-- 4. 确认事实:确定度量值
-- 2. 周期快照事实表
-- 3. 累积快照事实表
-- 交易域加购事务事实表
-- 交易域 : trade
-- 加购 : 行为
-- 将商品加入到购物车中的行为
-- 购物车中没有这个商品,往购物车中增加商品
-- 购物车中有这个商品,继续往购物车中增加该商品
-- 事务事实表
-- 原子性
-- 时间(行为时间) + 用户 + 商品 + 数量
-- 表的字段结构:必要的维度属性 + 度量值 + 可选的维度属性
-- 建表语句
-- 分区策略:哪一天的行为数据存放到哪一天分区事务的原子性
登录成功(OK) 登录失败(OK)
下单成功(OK) 下单失败(非正常业务行为,不需要再创建一张表)
支付成功(OK) 支付失败(OK)
事实表设计(周期型快照事实表)
全量
-- 事务性事实表局限性
-- 事实表只针对于当前行为进行的统计分析时,性能可以得到保障。
-- 当前行为事实表和其他行为数据进行关联时,数据量会几何爆炸性增长,性能会急剧下降。
-- 存量性统计指标使用事务性事实表效率太低,所以一般会采用其他事实表的设计方式
-- 2. 周期型快照事实表
-- 交易域购物车周期快照事实表
-- 交易域
-- 购物车 : cart_info
-- 周期快照事实表从当前表中取数据后再放回去需考虑去重问题,增加retry的容错性
事实表设计(累积型快照事实表)
-- 多行为统计指标使用事务性事实表效率太低,所以一般会采用其他事实表的设计方式
-- 3. 累积型快照事实表
-- 使用一张表保存多个行为的状态数据
-- 交易域交易流程累积快照事实表
-- 交易域
-- 交易流程 : 以订单为基础的交易流程
-- 累积快照事实表分区策略
-- 事务性事实表:哪一天的行为数据存放到哪一天的分区
-- 周期性事实表:每一天存储一份数据
-- 累积快照事实表:从业务流程中获取最后一个业务行为时间作为分区字段
-- 下单时间 (X)
-- 支付时间 (X)
-- 收货时间 (OK)第三层:数据统计(DWS data warehouse summary 提高性能的关键层)
功能:将加工后的数据进行统计
数据量非常大
压缩方式:snappy


第四层:数据分析(ADS application data service)
功能:将统计结果进行分析,为用户提供经营决策
压缩方式:gzip
数据格式:tsv
表的设计(要点)
-- ADS层中存储的是统计分析的最终结果
-- 数据量不多
-- 表不需要分区
-- 无需做进一步聚合
-- 无需orc列式存储和snappy压缩
-- 行式存储 + gzip
-- 结果还需要向后流转(可视化)
-- tsv
-- 表的结构不能太复杂(满足客户的需求即可)优化(假)
Spark:
- reduceByKey(函数内部combine减少落盘数据量)和groupByKey
- cache、persist和checkpoint
- DWS
1流量主题
1.1各渠道流量统计
1)建表语句
sql
DROP TABLE IF EXISTS ads_traffic_stats_by_channel;
CREATE EXTERNAL TABLE ads_traffic_stats_by_channel
(
`dt` STRING COMMENT '统计日期',
`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`channel` STRING COMMENT '渠道',
`uv_count` BIGINT COMMENT '访客人数',
`avg_duration_sec` BIGINT COMMENT '会话平均停留时长,单位为秒',
`avg_page_count` BIGINT COMMENT '会话平均浏览页面数',
`sv_count` BIGINT COMMENT '会话数',
`bounce_rate` DECIMAL(16, 2) COMMENT '跳出率'
) COMMENT '各渠道流量统计'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/ads/ads_traffic_stats_by_channel/';2)数据装载
第五层:共通层(DIM dimension)
功能:将共同的数据放在共通的表中,可在多个统计需求中使用
dimension:维度,分析数据的角度
该层不需要一开始就设计,可以等DWD层设计的差不多了,或是写着写着发现DWD中有好多表都用到了共通的字段,有大量冗余数据,那么就可以将这部分共通的数据提取成一个表
设计要点
(1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
(2)DIM层的数据存储格式为orc列式存储+snappy压缩。
(3)DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)。
绝大多数的维度表都是全量表
是否创建表
-
数据量少,应用面窄 :无需创建表(放用得到的表里即可,即维度退化)
-
数据量少,应用面广 :无需创建独立表,一般和其他的数放置在一张表中(数据字典表(编码表->是树形表))
-
树形(有上下级)数据保存时一般会采用 parent - child节点的设计方式
- 一般情况下,会采用一张表来设计上下级结构:部门(depart)
-- 表中的列:下级部门(主键)(N), 上级部门(外键)(1) - 字典表也是树形表
- 一般情况下,会采用一张表来设计上下级结构:部门(depart)
维度表设计
- 确定维度表:确定维度的表是否该创建
- 原则上来讲,每一个分析数据的角度(维度)都应该创建一张表
- 案例:统计各个省份,各个品牌的订单总销量
-- 订单属于事实(行为)表,省份和品牌就是维度表 - 案例:统计各个性别不同年龄段的订单总销量
-- 订单属于事实(行为)表, 性别和年龄就是维度表
- 案例:统计各个省份,各个品牌的订单总销量
- 如果多个维度存在关联,那么一般就会只创建一张表,表中包含了多个关联的维度
- 如果分析数据的角度应用场景少,而且数据量小,不需要创建专门的维度表
- 案例:支付方式(微信支付,支付宝支付)
- 原则上来讲,每一个分析数据的角度(维度)都应该创建一张表
- 确定主维表和相关维表(用于分析维度表的列)
- 确定表中的列
- 案例:省份维度表
-- 列:名称 - 数据仓库的数据都来自于MySQL业务数据,
-- 维度表的列的声明可以参考业务数据库表的字段 - MySQL业务数据库中具有唯一性字段的那个业务表称之为主维表
-- 其他的表称之为相关维表。
- 案例:省份维度表
- 确定表中的列
- 确定表中的列
- 尽可能丰富(多)
- 编码和文字共存
- 沉淀通用属性 :tel, xxx
-- 计算或转换
1商品维度表
sql
-- 商品维度表 :dim_sku_full
-- 确定维度表
-- 主维表和相关维表
-- 主维表和相关维表都是MySQL业务表
-- 主要用于分析列的表称之主维表(主键)
-- sku_info
-- 其他用于分析列的表称之相关维表
-- sku_attr_value
-- sku_sale_attr_value
-- 确定表的列
-- 建表语句
DROP TABLE IF EXISTS dim_sku_full;
CREATE EXTERNAL TABLE dim_sku_full
(
`id` STRING COMMENT 'SKU_ID',
`price` DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'SPU编号',
`spu_name` STRING COMMENT 'SPU名称',
`category3_id` STRING COMMENT '三级品类ID',
`category3_name` STRING COMMENT '三级品类名称',
`category2_id` STRING COMMENT '二级品类id',
`category2_name` STRING COMMENT '二级品类名称',
`category1_id` STRING COMMENT '一级品类ID',
`category1_name` STRING COMMENT '一级品类名称',
`tm_id` STRING COMMENT '品牌ID',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,
value_id :STRING,
attr_name :STRING,
value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,
sale_attr_value_id :STRING,
sale_attr_name :STRING,
sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_sku_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
-- 数据装载
-- load
-- 数据源一定是ODS层
-- save
-- 分区字段其实也是表的字段,但是我们一般称之为虚拟字段
-- 数据字段(列):存储在数据文件中
-- 分区字段:存储在路径中
-- 分区
-- dt : date(日期)
-- 策略:将每天采集的数据存放到ODS层的每天分区中
-- 将ODS层每天的数据关联后存放到DIM层的每天分区中
-- 分区存储应该采用overwrite而不是into
set hive.vectorized.execution.enabled=false;
insert overwrite table dim_sku_full partition (dt='2022-06-08')
select
sku.`id` ,--STRING COMMENT 'SKU_ID',
`price` ,--DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` ,--STRING COMMENT '商品名称',
`sku_desc` ,--STRING COMMENT '商品描述',
`weight` ,--DECIMAL(16, 2) COMMENT '重量',
`is_sale` ,--BOOLEAN COMMENT '是否在售',
`spu_id` ,--STRING COMMENT 'SPU编号',
`spu_name` ,--STRING COMMENT 'SPU名称',
`category3_id` ,--STRING COMMENT '三级品类ID',
`category3_name` ,--STRING COMMENT '三级品类名称',
`category2_id` ,--STRING COMMENT '二级品类id',
`category2_name` ,--STRING COMMENT '二级品类名称',
`category1_id` ,--STRING COMMENT '一级品类ID',
`category1_name` ,--STRING COMMENT '一级品类名称',
`tm_id` ,-- STRING COMMENT '品牌ID',
`tm_name` ,-- STRING COMMENT '品牌名称',
sku_attr_values,
sku_sale_attr_values,
`create_time` --STRING COMMENT '创建时间'
from (
select
`id` ,--STRING COMMENT 'SKU_ID',
`price` ,--DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` ,--STRING COMMENT '商品名称',
`sku_desc` ,--STRING COMMENT '商品描述',
`weight` ,--DECIMAL(16, 2) COMMENT '重量',
`is_sale` ,--BOOLEAN COMMENT '是否在售',
`spu_id` ,--STRING COMMENT 'SPU编号',
`category3_id` ,--STRING COMMENT '三级品类ID',
`tm_id` ,-- STRING COMMENT '品牌ID',
create_time
from ods_sku_info_full
where dt = '2022-06-08'
) sku
left join (
select
id,
spu_name
from ods_spu_info_full
where dt = '2022-06-08'
) spu on sku.spu_id = spu.id
left join (
select
id,
tm_name
from ods_base_trademark_full
where dt = '2022-06-08'
) tm on sku.tm_id = tm.id
left join (
select
id,
name category3_name,
category2_id
from ods_base_category3_full
where dt = '2022-06-08'
) c3 on sku.category3_id = c3.id
left join (
select
id,
name category2_name,
category1_id
from ods_base_category2_full
where dt = '2022-06-08'
) c2 on c3.category2_id = c2.id
left join (
select
id,
name category1_name
from ods_base_category1_full
where dt = '2022-06-08'
) c1 on c2.category1_id = c1.id
left join (
-- 将查询结果转换为结构体后,形成Array
-- 将多个结构体的数据聚合成一个数组类型的数据(聚合操作)
select
sku_id,
collect_list(named_struct("attr_id", attr_id, "value_id", value_id, "attr_name", attr_name, "value_name", value_name)) sku_attr_values
from ods_sku_attr_value_full
where dt = '2022-06-08'
group by sku_id
) sav on sku.id = sav.sku_id
left join (
select
sku_id,
collect_list(named_struct("sale_attr_id", sale_attr_id, "sale_attr_value_id", sale_attr_value_id, "sale_attr_name", sale_attr_name, "sale_attr_value_name", sale_attr_value_name)) sku_sale_attr_values
from ods_sku_sale_attr_value_full
where dt = '2022-06-08'
group by sku_id
) ssav on sku.id = ssav.sku_id;
-- join & left join
-- join 要求2张表的数据同时满足条件才能作为结果返回
-- left join 要求2张表的数据左边的表不满足条件也能作为结果返回
-- 使用left join 替换 join,必须保证,替换后不影响结果2优惠券维度表
1)建表语句
sql
-- 创建表
-- 分析表中的列
-- 主维表
-- coupon_info
-- base_dic
-- 相关维表
-- 建表语句
-- 表名
DROP TABLE IF EXISTS dim_coupon_full;
CREATE EXTERNAL TABLE dim_coupon_full
(
`id` STRING COMMENT '优惠券编号',
`coupon_name` STRING COMMENT '优惠券名称',
`coupon_type_code` STRING COMMENT '优惠券类型编码',
`coupon_type_name` STRING COMMENT '优惠券类型名称',
`condition_amount` DECIMAL(16, 2) COMMENT '满额数',
`condition_num` BIGINT COMMENT '满件数',
`activity_id` STRING COMMENT '活动编号',
`benefit_amount` DECIMAL(16, 2) COMMENT '减免金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '折扣',
`benefit_rule` STRING COMMENT '优惠规则:满元*减*元,满*件打*折',
`create_time` STRING COMMENT '创建时间',
`range_type_code` STRING COMMENT '优惠范围类型编码',
`range_type_name` STRING COMMENT '优惠范围类型名称',
`limit_num` BIGINT COMMENT '最多领取次数',
`taken_count` BIGINT COMMENT '已领取次数',
`start_time` STRING COMMENT '可以领取的开始时间',
`end_time` STRING COMMENT '可以领取的结束时间',
`operate_time` STRING COMMENT '修改时间',
`expire_time` STRING COMMENT '过期时间'
) COMMENT '优惠券维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_coupon_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');2)数据装载
sql
insert overwrite table dim_coupon_full partition(dt='2022-06-08')
select
id,
coupon_name,
coupon_type,
coupon_dic.dic_name,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
case coupon_type
when '3201' then concat('满',condition_amount,'元减',benefit_amount,'元')
when '3202' then concat('满',condition_num,'件打', benefit_discount,' 折')
when '3203' then concat('减',benefit_amount,'元')
end benefit_rule,
create_time,
range_type,
range_dic.dic_name,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from
(
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from ods_coupon_info_full
where dt='2022-06-08'
)ci
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2022-06-08'
and parent_code='32'
)coupon_dic
on ci.coupon_type=coupon_dic.dic_code
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2022-06-08'
and parent_code='33'
)range_dic
on ci.range_type=range_dic.dic_code;3活动(规则)维度表
1)建表语句
sql
-- 活动(规则)维度表
-- activity_info
-- activity_rule
DROP TABLE IF EXISTS dim_activity_full;
CREATE EXTERNAL TABLE dim_activity_full
(
`activity_rule_id` STRING COMMENT '活动规则ID',
`activity_id` STRING COMMENT '活动ID',
`activity_name` STRING COMMENT '活动名称',
`activity_type_code` STRING COMMENT '活动类型编码',
`activity_type_name` STRING COMMENT '活动类型名称',
`activity_desc` STRING COMMENT '活动描述',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间',
`condition_amount` DECIMAL(16, 2) COMMENT '满减金额',
`condition_num` BIGINT COMMENT '满减件数',
`benefit_amount` DECIMAL(16, 2) COMMENT '优惠金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '优惠折扣',
`benefit_rule` STRING COMMENT '优惠规则',
`benefit_level` STRING COMMENT '优惠级别'
) COMMENT '活动维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_activity_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');2)数据装载
sql
insert overwrite table dim_activity_full partition(dt='2022-06-08')
select
rule.id,
info.id,
activity_name,
rule.activity_type,
dic.dic_name,
activity_desc,
start_time,
end_time,
create_time,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
case rule.activity_type
when '3101' then concat('满',condition_amount,'元减',benefit_amount,'元')
when '3102' then concat('满',condition_num,'件打', benefit_discount,' 折')
when '3103' then concat('打', benefit_discount,'折')
end benefit_rule,
benefit_level
from
(
select
id,
activity_id,
activity_type,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from ods_activity_rule_full
where dt='2022-06-08'
)rule
left join
(
select
id,
activity_name,
activity_type,
activity_desc,
start_time,
end_time,
create_time
from ods_activity_info_full
where dt='2022-06-08'
)info
on rule.activity_id=info.id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2022-06-08'
and parent_code='31'
)dic
on rule.activity_type=dic.dic_code;4地区维度表
1)建表语句
sql
DROP TABLE IF EXISTS dim_province_full;
CREATE EXTERNAL TABLE dim_province_full
(
`id` STRING COMMENT '省份ID',
`province_name` STRING COMMENT '省份名称',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT '旧版国际标准地区编码,供可视化使用',
`iso_3166_2` STRING COMMENT '新版国际标准地区编码,供可视化使用',
`region_id` STRING COMMENT '地区ID',
`region_name` STRING COMMENT '地区名称'
) COMMENT '地区维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_province_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');2)数据装载
sql
insert overwrite table dim_province_full partition(dt='2022-06-08')
select
province.id,
province.name,
province.area_code,
province.iso_code,
province.iso_3166_2,
region_id,
region_name
from
(
select
id,
name,
region_id,
area_code,
iso_code,
iso_3166_2
from ods_base_province_full
where dt='2022-06-08'
)province
left join
(
select
id,
region_name
from ods_base_region_full
where dt='2022-06-08'
)region
on province.region_id=region.id;5营销坑位维度表
1)建表语句
sql
DROP TABLE IF EXISTS dim_promotion_pos_full;
CREATE EXTERNAL TABLE dim_promotion_pos_full
(
`id` STRING COMMENT '营销坑位ID',
`pos_location` STRING COMMENT '营销坑位位置',
`pos_type` STRING COMMENT '营销坑位类型 ',
`promotion_type` STRING COMMENT '营销类型',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '营销坑位维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_promotion_pos_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');2)数据装载
sql
insert overwrite table dim_promotion_pos_full partition(dt='2022-06-08')
select
`id`,
`pos_location`,
`pos_type`,
`promotion_type`,
`create_time`,
`operate_time`
from ods_promotion_pos_full
where dt='2022-06-08';6营销渠道维度表
1)建表语句
sql
DROP TABLE IF EXISTS dim_promotion_refer_full;
CREATE EXTERNAL TABLE dim_promotion_refer_full
(
`id` STRING COMMENT '营销渠道ID',
`refer_name` STRING COMMENT '营销渠道名称',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '营销渠道维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_promotion_refer_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');2)数据装载
sql
insert overwrite table dim_promotion_refer_full partition(dt='2022-06-08')
select
`id`,
`refer_name`,
`create_time`,
`operate_time`
from ods_promotion_refer_full
where dt='2022-06-08';7日期维度表
日期维度表不需要从MySQL中导,而是从文件中另行导入,也不需要每天导入,每年导入一次即可
1)建表语句
sql
DROP TABLE IF EXISTS dim_date;
CREATE EXTERNAL TABLE dim_date
(
`date_id` STRING COMMENT '日期ID',
`week_id` STRING COMMENT '周ID,一年中的第几周',
`week_day` STRING COMMENT '周几',
`day` STRING COMMENT '每月的第几天',
`month` STRING COMMENT '一年中的第几月',
`quarter` STRING COMMENT '一年中的第几季度',
`year` STRING COMMENT '年份',
`is_workday` STRING COMMENT '是否是工作日',
`holiday_id` STRING COMMENT '节假日'
) COMMENT '日期维度表'
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_date/'
TBLPROPERTIES ('orc.compress' = 'snappy');2)数据装载
(1)创建临时表
sql
DROP TABLE IF EXISTS tmp_dim_date_info;
CREATE EXTERNAL TABLE tmp_dim_date_info (
`date_id` STRING COMMENT '日',
`week_id` STRING COMMENT '周ID',
`week_day` STRING COMMENT '周几',
`day` STRING COMMENT '每月的第几天',
`month` STRING COMMENT '第几月',
`quarter` STRING COMMENT '第几季度',
`year` STRING COMMENT '年',
`is_workday` STRING COMMENT '是否是工作日',
`holiday_id` STRING COMMENT '节假日'
) COMMENT '时间维度表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/tmp/tmp_dim_date_info/';(2)将数据文件上传到HFDS上临时表路径/warehouse/gmall/tmp/tmp_dim_date_info

TSV格式的数据
sql
-- 日期数据不是由我们自己提供的
-- TSV -> ORC
-- ODS(全量) -> DIM(ORC)
insert overwrite table dim_date select * from tmp_dim_date_info;8用户维度表(拉链(压缩)表)
- 将大量数据的表进行特殊的设计进行改善,让数据减少,并且不影响业务逻辑
-- 将数据状态进行时间标记:开始 + 结束 - 设计拉链表时,需要在基本表的设计基础上,增加2个额外字段,用于表示状态的范围(开始,结束)
- 拉链表的数据,每一个状态的变化会保存一条数据,如果状态没有任何的变化,那么数据只有一条
1)建表语句
sql
-- 表名:dim_user_full
-- 表中列
-- 主维表 : user_info
-- 相关维表 : user_address
DROP TABLE IF EXISTS dim_user_zip;
CREATE EXTERNAL TABLE dim_user_zip
(
`id` STRING COMMENT '用户ID',
`name` STRING COMMENT '用户姓名',
`phone_num` STRING COMMENT '手机号码',
`email` STRING COMMENT '邮箱',
`user_level` STRING COMMENT '用户等级',
`birthday` STRING COMMENT '生日',
`gender` STRING COMMENT '性别',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '操作时间',
`start_date` STRING COMMENT '开始日期',
`end_date` STRING COMMENT '结束日期'
) COMMENT '用户维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_user_zip/'
TBLPROPERTIES ('orc.compress' = 'snappy');2)数据装载
① 首日装载
sql
-- 全量表
-- DataX
-- TSV
-- 增量表
-- Maxwell
-- JSON
-- 首日(全量-select) : bootstrap (3种类型)
-- 每日(增量-binlog) : insert, update, delete
insert overwrite table dim_user_zip partition (dt = '9999-12-31')
select data.id,
concat(substr(data.name, 1, 1), '*') name,
if(data.phone_num regexp '^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',
concat(substr(data.phone_num, 1, 3), '*'), null) phone_num,
if(data.email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$',
concat('*@', split(data.email, '@')[1]), null) email,
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
'2022-06-08' start_date,
'9999-12-31' end_date
from ods_user_info_inc
where dt = '2022-06-08'
and type = 'bootstrap-insert';② 每日装载
sql
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dim_user_zip partition (dt)
select id,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
start_date,
if(rn = 2, date_sub('2022-06-09', 1), end_date) end_date,
if(rn = 1, '9999-12-31', date_sub('2022-06-09', 1)) dt
from (
select id,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
start_date,
end_date,
row_number() over (partition by id order by start_date desc) rn
from (
select id,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
start_date,
end_date
from dim_user_zip
where dt = '9999-12-31'
union
select id,
concat(substr(name, 1, 1), '*') name,
if(phone_num regexp
'^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',
concat(substr(phone_num, 1, 3), '*'), null) phone_num,
if(email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$',
concat('*@', split(email, '@')[1]), null) email,
user_level,
birthday,
gender,
create_time,
operate_time,
'2022-06-09' start_date,
'9999-12-31' end_date
from (
select data.id,
data.name,
data.phone_num,
data.email,
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
row_number() over (partition by data.id order by ts desc) rn
from ods_user_info_inc
where dt = '2022-06-09'
) t1
where rn = 1
) t2
) t3;CTE : 共通表表达式
sql
with
aa as ( select * from test_table_part ),
ab as (select * from aa)
select
*
from aa
join ab;
select
*
from (
select * from test_table_part
) aa
join (
select * from test_table_part
) bb;
select
*
from dim_sku_full拉链表设计
sql
-- 数据装载
-- load
-- save
-- 增量表得数据操作一般都会写2个
-- 首日数据装载
-- 每日数据装载
-- 首日数据装载
-- 同步方式:maxwell - 全量 - bootstrap - select * from user_info
-- MySQL不保存行为数据,也就意味着不保存历史行为数据
-- 拉链表会在当前表得字段得基础上,额外添加两个字段(start, end),用于标记状态得有效范围
-- start : 无法判断开始范围
-- end : 无法判断
-- 折中地考虑
-- 从当天开始,结束时间取时间极大值(避免数据频繁修改)
-- 分区策略
-- 绝大多数得维度表得分区策略都是以天为单位
-- 分区不能采用开始日期作为分区字段
-- 无法判断数据是否为历史状态还是最新状态
-- 好得方式是使用结束时间为分区字段任务调度器
保证每一层的SQL跑完再跑下一层