文章目录
一、什么是数据湖?
起源
数据湖的概念最早由Pentaho的创始人兼CTO詹姆斯·迪克森(James Dixon)于2010年10月在纽约Hadoop World大会上提出。然而,在国内,数据湖的概念直到2019年Iceberg、Hudi和Delta Lake三大数据湖开源后才真正流行起来。
让我们先看看维基百科对数据湖的介绍:
数据湖 (英语:Data Lake)是指以其原始格式(如BLOB或文件等)存储的数据存储库或系统[1](https://zh.wikipedia.org/wiki/数据湖#cite_note-1)。数据湖通常会将所有数据统一存储,包括源系统数据、传感器数据、社交数据等的原始副本,以及用于报表、可视化、数据分析和机器学习等流程中转换后的数据。数据湖还可能包括关系数据库的结构化数据(行与列)、半结构化的数据(CSV、日志、XML、JSON)及非结构化数据(电子邮件、文件、PDF)和二进制数据(图像、音频、视频)等。数据湖可能是"on premises"(指在组织的数据中心里),也可能放在云端(使用Amazon、微软或Google的云端服务)。
一言以蔽之:数据湖是一个理论上只要是可以转化成二进制的数据均可存储的数据存储管理系统
数据湖的特征
数据湖具有以下特点:
-
容量大
数据湖汇聚各个业务数据源,容纳散落在各处的数据,理论上存储空间巨大。
-
格式多
数据湖架构面向多数据源的信息存储,可以快速高效地采集、存储、处理大量来源不同、格式各异的原始数据,包括文本、图片、视频、音频、网页等各类无序的非结构化数据。数据湖能将不同种类的数据汇聚存储在一起,并对汇聚后的数据进行管理,建立数据之间的关联关系,具有很强的兼容性。
-
处理速度快
数据湖技术能将各类原始数据快速转化为可直接提取、分析、使用的标准格式,统一优化数据结构并对数据进行分类存储。根据业务需求,数据湖可以对存储的数据进行快速的查询、挖掘、关联和处理,并实时传输给终端用户。
-
分布式体系
由于Hadoop也能基于分布式文件系统来存储和处理多类型数据,因此许多人认为Hadoop的工作机制就是数据湖的处理机制。当然,Hadoop基于其分布式、可横向扩展的文件系统架构,可以管理和处理海量数据,但它无法提供数据湖所需的复杂元数据管理功能。最直观的表现是,数据湖的体系结构表明数据湖是由多个组件构成的生态系统,而Hadoop仅提供了其中的部分组件功能。
注意:严格来说数据湖没有跟具体哪个技术绑定
二、为什么要用数据湖?
要回答这个问题,我们需要先回顾一下数据库和数据仓库的概念。
数据库的基本概念大家应该都不陌生。如今但凡是个业务系统,都或多或少需要用到数据库。即便我们不直接跟数据库打交道,它们也在背后默默地为我们服务,比如刷个卡、取个钱,后台都是数据库在运行。
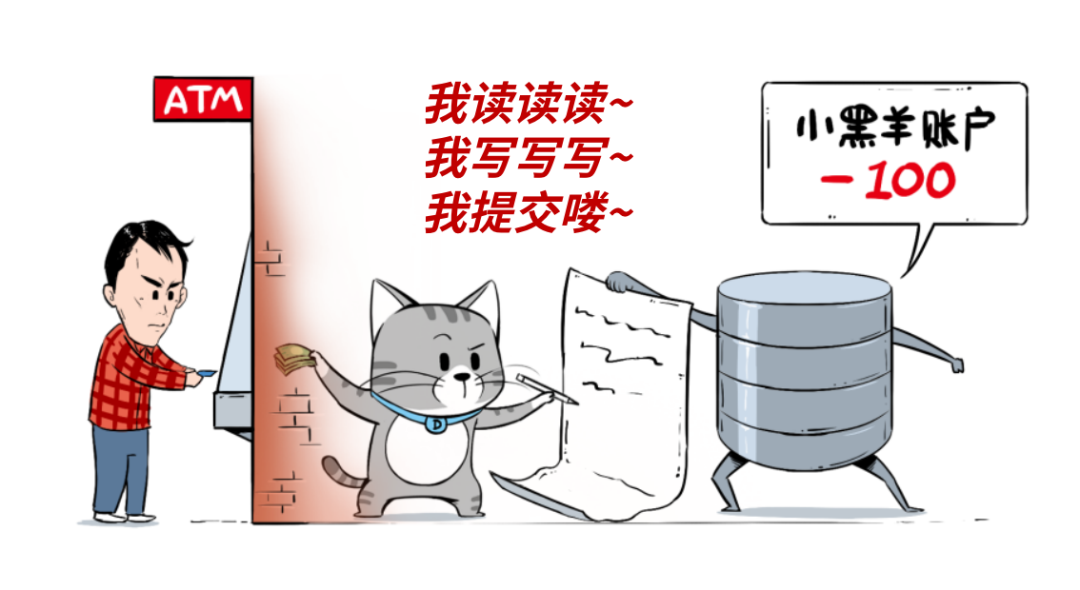
数据库用于联机事务处理,通常处理的是小数据量的高频读写操作。
当企业的数据越来越多,开始希望基于业务数据进行决策分析时,便有了 数据仓库 的出现。数据库等原始数据经过 ETL(Extract, Transform, Load)加工后,被装进数据仓库。数据仓库主要用于联机分析业务,通常处理大数据量的读取。

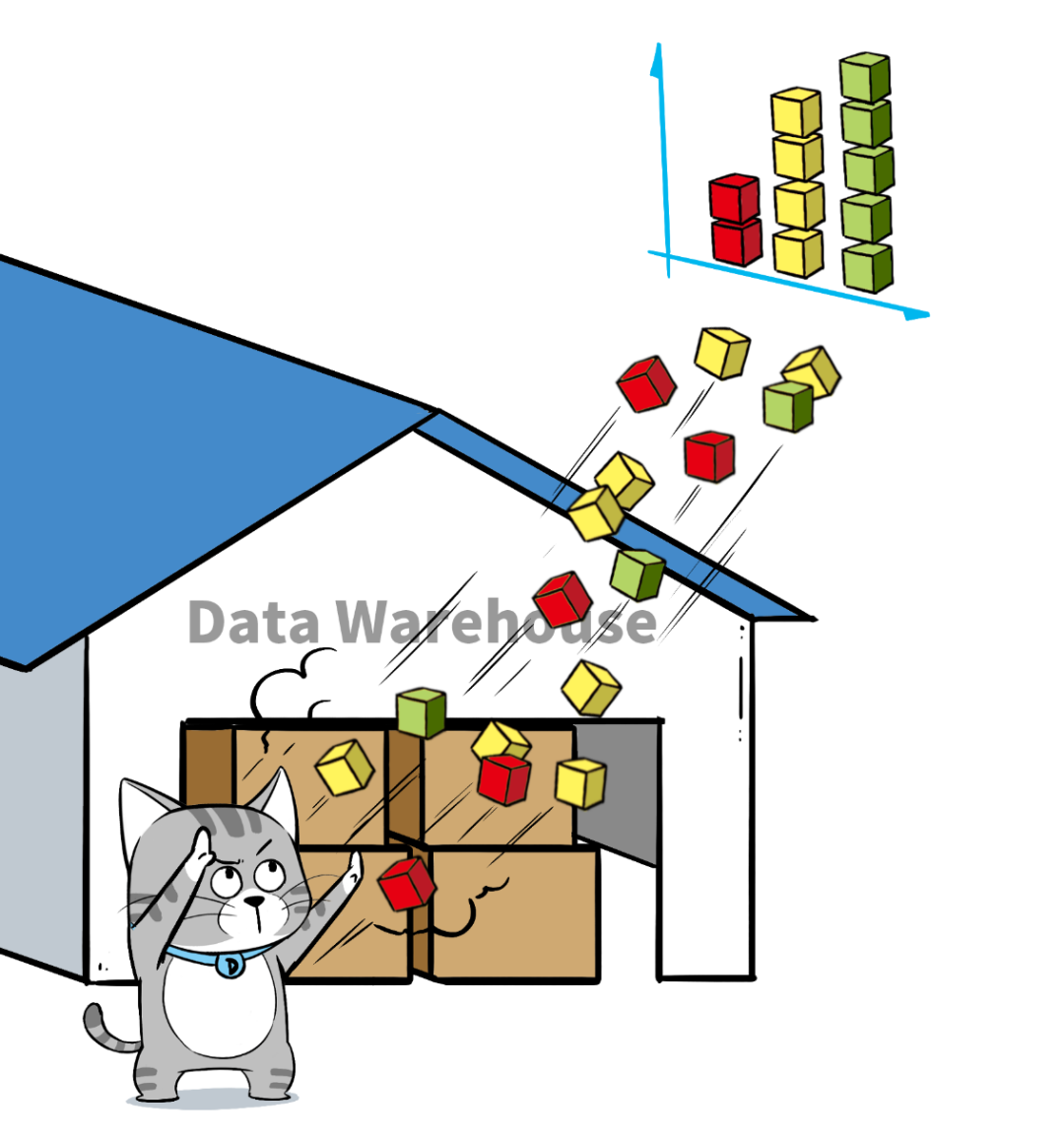
以上是数据库和数据仓库的简单介绍。尽管它们的应用场景不同,但它们都处理 结构化数据。在相当长的一段时间内,数据库和数据仓库联合起来,共同满足企业的实时"交易"型业务和联机"分析性"业务需求。
然而,随着时代的发展,数据的类型变得越来越多样化,人们对数据的需求也越来越复杂。

企业希望把生产经营中的所有相关数据,历史的、实时的,在线的、离线的,内部的、外部的,结构化的、非结构化的,都能完整保存下来,方便"沙中淘金"。
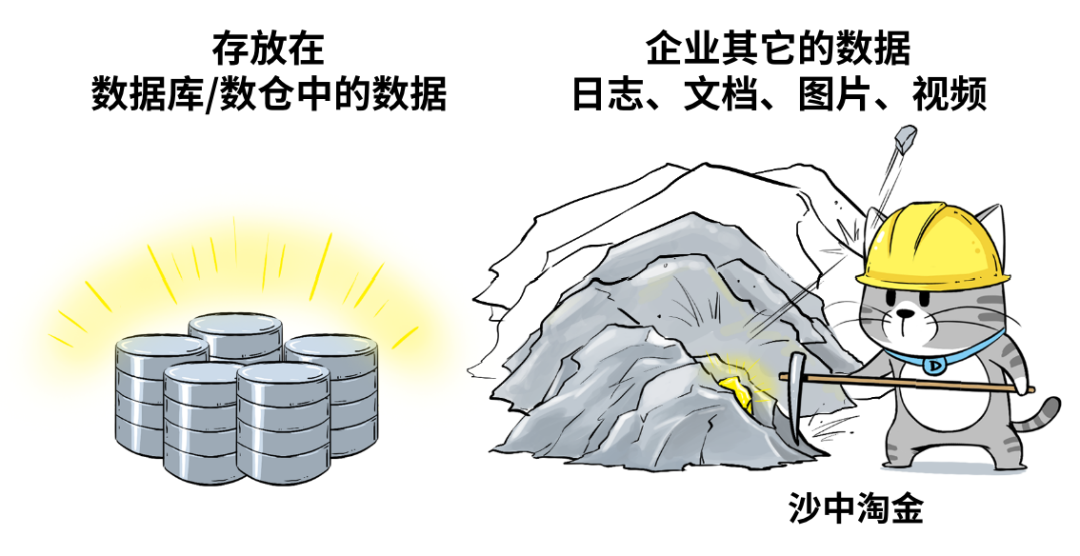
企业越来越重视 "大数据" 的价值,希望能够存储并有效利用这些数据。
这些数据种类繁多,五花八门,数据库和数据仓库都无法胜任这项任务,怎么办呢?
索性挖个大坑吧!

这就是数据湖的原型。
简单来说,数据湖就像一个"大水坑",是一种将各类异构数据进行集中存储的架构。数据湖能够存储结构化、半结构化和非结构化数据,使企业可以在一个统一的平台上存储、管理和分析各种类型的数据。这不仅能够降低数据存储的成本,还能提高数据分析的灵活性和效率,帮助企业更好地挖掘数据价值,做出更明智的业务决策。
三、数据湖与数据仓库的区别
数据仓库和数据湖的对比

从数据含金量来比,数据仓库里的数据价值密度更高一些,数据的抽取和Schema的设计,都有非常强的针对性,便于业务分析师迅速获取洞察结果,用与决策支持。
而数据湖更有一种"兜底"的感觉,甭管当下有用没有/或者暂时没想好怎么用,先保存着、沉淀着,将来想用的时候,尽管翻牌子就是了,反正都原汁原味的留存了下来。

而从产品形态看,数据仓库可以是独立的标准化产品,数据湖则是一种解决方案,通常是围绕对象存储为"湖底座"的大数据管理方案组合。
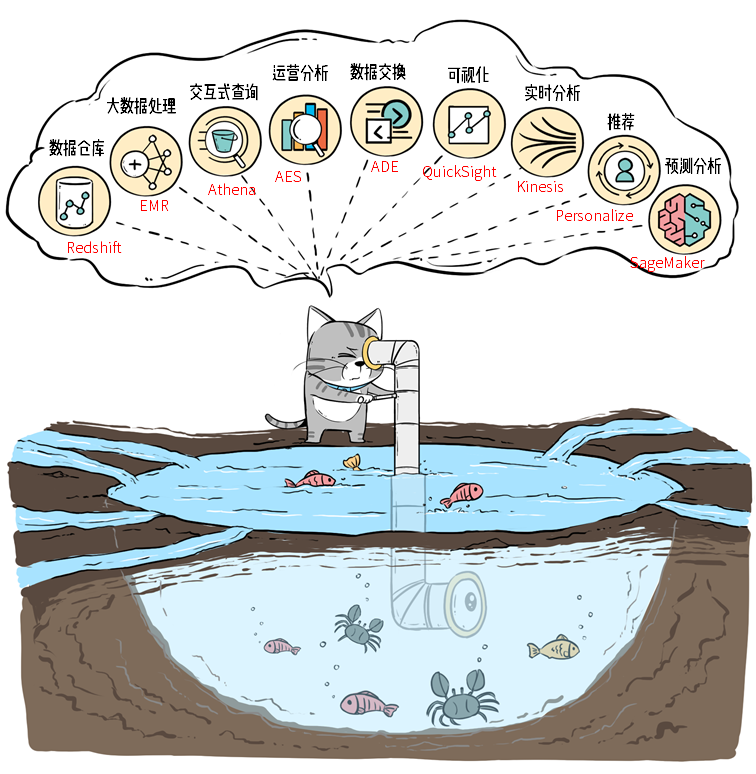
四、数据湖本质
数据湖的本质:是由 数据存储架构 和 数据处理工具 组成的 解决方案。而不是某个单一独立产品。
数据存储架构
数据存储架构需要具备足够的扩展性和可靠性,确保企业能够存储所有原始数据,并且长期保存。这些存储系统包括:
- Hadoop 的 HDFS
- 对象存储系统,如 Amazon Web Services(亚马逊云科技)
数据处理工具:三类
第一类工具
解决的问题是:如何将数据"搬到"湖里,即 ETL(Extract, Transform, Load)。

第二类工具
解决的问题是:数据管理。如果元数据缺失,数据湖中的数据质量将无法保证,各种数据无序堆积,最终会导致数据湖变成 数据沼泽。

第三类工具
解决的问题是:从湖中的海量数据中"淘金"。数据存储在数据湖中并不是终点,还需要对数据进行分析、挖掘和利用。例如,对湖中的数据进行查询,同时将数据提供给机器学习和数据科学类的业务,以便实现"点石成金"。

小结
数据湖不仅仅是一个"囤积"数据的"大水坑"。除了存储技术构建的湖底座以外,还包含一系列的数据入湖、数据出湖、数据管理和数据应用工具集,共同组成了数据湖解决方案。
五、总结
数据湖的概念最早由詹姆斯·迪克森在2010年提出,随着2019年Iceberg、Hudi和Delta Lake等开源项目在国内流行起来。数据湖是一种多功能系统,能够存储各种类型的数据,包括结构化、半结构化和非结构化数据,具备高容量存储和快速处理多种数据格式的能力。
与传统的数据库和数据仓库不同,数据湖不仅可以保存原始数据,还能支持快速的查询、数据分析和机器学习应用,帮助企业更有效地挖掘数据的潜力。数据湖由数据存储架构和多种数据处理工具组成,而不是单一的独立产品。
数据湖解决方案还包括ETL工具、元数据管理和数据分析工具,这些工具的使用确保了数据湖的高效管理和利用,防止其变成无序的"数据沼泽"。
在下一篇文章中,我们将深入探讨市面上热门的数据湖开源框架,以及这些开源框架是否能够满足数据湖的基本概念和功能要求。