在当今数字化世界中,视频已成为人们获取信息和娱乐的主要方式之一。
AI视频生成领域的竞争也很激烈,Pika、Sora、Luma AI以及国内的可灵等,多模态、视频生成甚至也被视为大模型发展的某种必经之路。然而,与文本生成相比,视频生成模型与实际场景的距离似乎更为遥远,Sora在2月份的事件中引起了广泛关注,但至今还未对公众开放试用。
除了视频的生成,视频的理解速度实际上更快,并且在当前阶段也成为了吸引投资的热门领域。
今天要介绍的这家新兴公司Twelve Labs是其中的标志性企业,它成功获得了英伟达的资金支持,并且同时被CB Insights和Fast Company评为最具创新力的AI搜索公司之一。Twelve Labs凭借其先进的技术,致力于打造多模态视频搜索引擎,为用户提供更智能、更高效的视频搜索体验。

产品介绍
Twelve Labs的目标是,让视频的处理和搜索变得和文本一样容易。
主要观点:
场景式视频内容理解是主流:增加视频数据和高质量视频内容是未来 AIGC 在媒体和娱乐领域规模化采用的基础,场景式理解视频内容 (Context Understanding of Video) 将会成为技术主流。视频内容处理可以细化到每一个瞬间,大大提高了视频内容在不同社交平台的传播效率。AI原生产品的丝滑体验感:自动化视频数据标注和数据生成可以极大的降低成本,把劳动力从重复性的工作中解放出来。Twelve Labs 把标注,搜索和生成端到端的设计起来,创造了极优的产品体验。
产品简介:
Twelve Labs 是一个人工智能平台,帮助开发者创建视频搜索和生成能力。该产品可在视频中提取特定视频瞬间,包括视觉、音频、文本和上下文信息,以实现语义搜索、分析和洞察。该公司的愿景是创建用于多模式视频理解的基础设施,其自研模型可用于媒体分析并自动生成精彩片段。目前已被从多个顶级风投机构投资。
产品功能
Twelve Labs的核心技术是开发多模态的AI大模型,能够像人类一样理解视频内容。它通过三个步骤自动搜索,分类和生成来简化用户的工作流程,但其中包括了几种主要的产品功能,只需通过对接 API 就可以使用:
1、视频搜索
此模型分析视频的语义内容(Sematic search),包括视频,音频,Logo 等数字材料,文字等全面分析场景关联性,以实现高效且准确的特定视频片段检索,帮助用户在无需观看完整内容的情况下精准搜索到大量来自 Youtube, Tiktok,Reels 等视频库的材料。传统的视频搜索主要都是基于标题和特定标签信息来完成的,而 Twelve Labs 的产品可以根据对视频包括音频内容的理解和用户输文字的语义来进行定位。
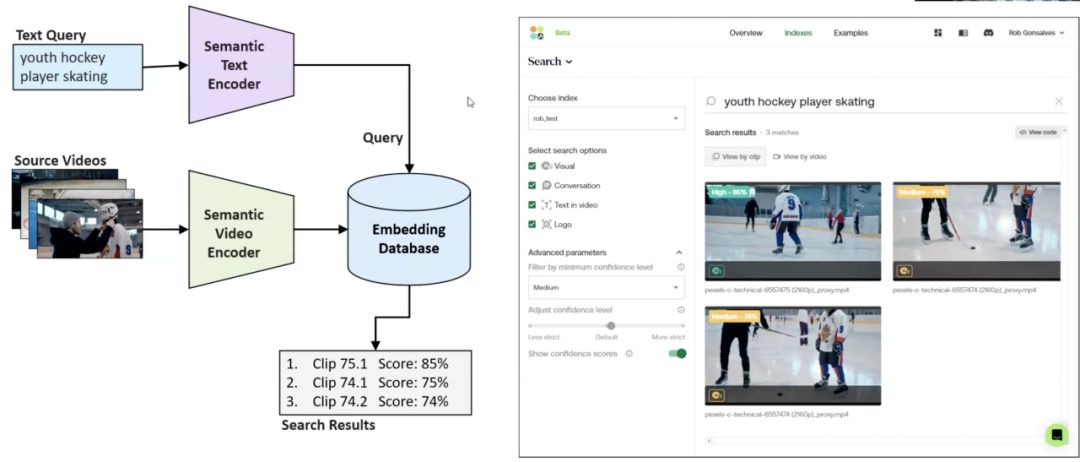
2、视频分类
如果你是一个视频内容平台如抖音,数据库里有海量的视频资源,你有很多的用户,但是每个用户可能只对其中一类或者几类视频感兴趣。那如何只推送用户喜欢的内容呢?传统的内容推荐大多都是根据用户的偏好设置和用户行为数据,根据视频的标题和标签进行匹配来进行的。这种推荐的结果一般初期效果比较差,并且带有很强的不确定性。这个基于AI大模型的分类功能除了能很好地完成个性化内容推荐任务,还可以做精准广告投放,公司内部视频资源的整理。它通过分析视频中的语义特征、对象和动作,将视频自动分类为预定义的类别,如体育、新闻、娱乐或纪录片。这增强了内容发现能力,并提供个性化推荐。同时,此功能基于内容相似性对视频进行分组,而不需要标签数据。它使用视频嵌入来捕捉视觉和时间信息,便于测量相似性并将相似视频进行归类。
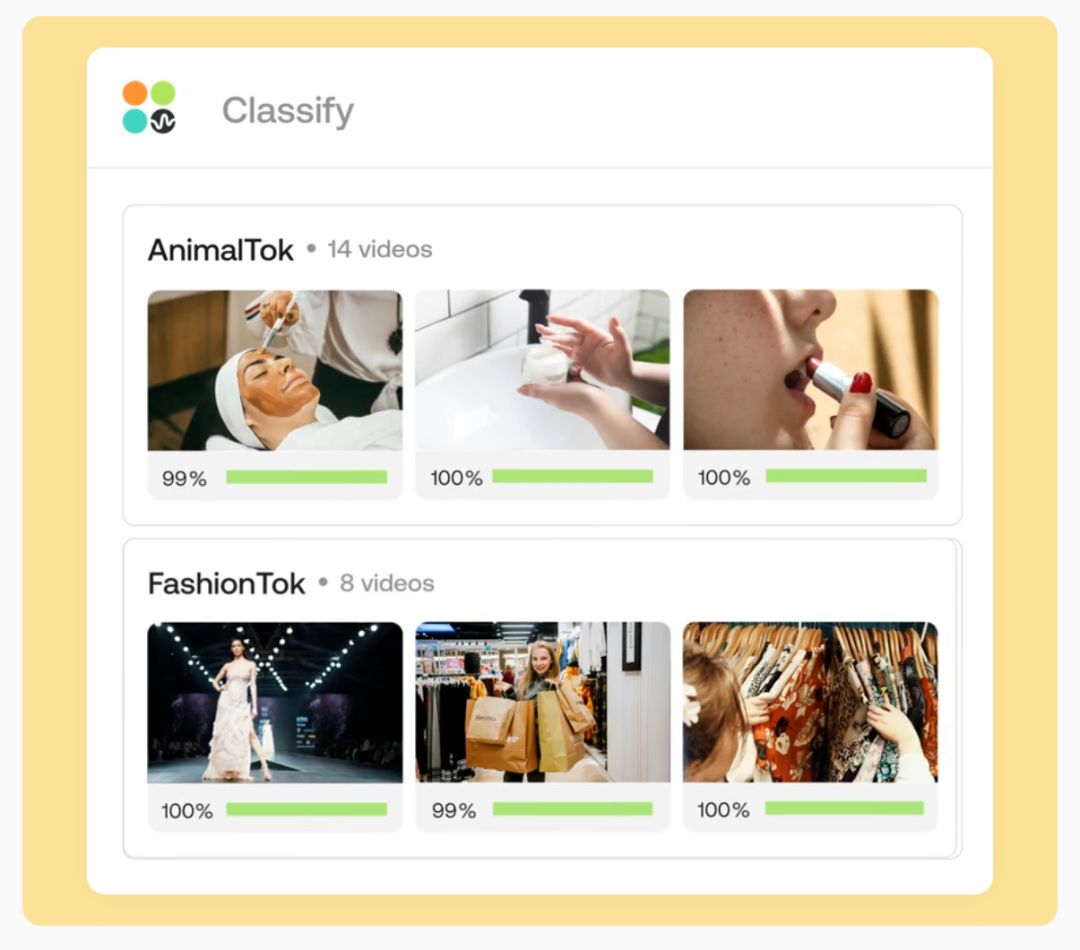
3、视频-语言建模
该功能集成文本描述和视频内容,使模型能够理解并生成基于文本的摘要、描述或对视频内容的响应。它弥合了视觉和文本理解之间的差距。还可以在生成的视频上自由修改和插入视频内容,有提供用户利用细分赛道数据的微调模型的功能,例如客户会需要微调「茄瓜沙律」为「鸡胸肉沙律」。
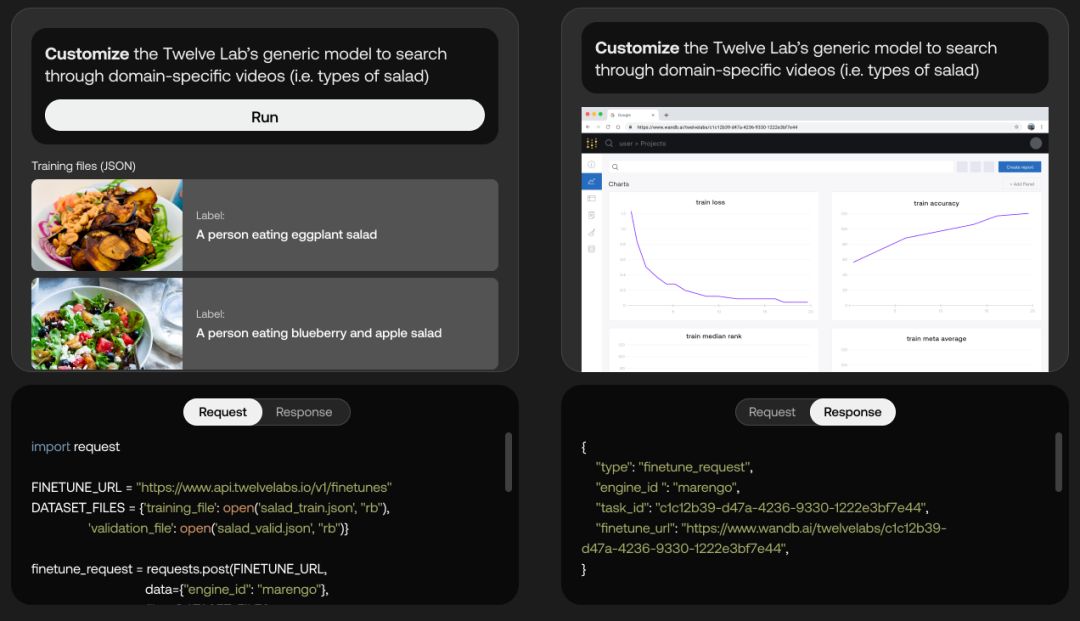
Twelve Labs商业模式主要做ToB的业务,比如视频内容提供商,媒体资产管理,执法部门的数字证据管理等,目前已经与Vidispine、EMAM、Blackbird等公司建立深度合作。
4、视频描述和摘要
这个模型能够生成自然语言的描述以及视频的简洁摘要,从而捕获关键的信息和重要的时刻。在此基础上,结合深度学习算法实现对语义内容进行理解分析,并以文本形式呈现给用户。特别是对于那些有视觉问题或时间受限的用户来说,这种方法增强了理解能力和参与度。同时,该系统提供一种基于语音识别技术的个性化视频分享平台。你还可以利用自定义的prompt工具来创建具有不同重点的长篇视频总结、故事或自媒体文章等内容。

产品优势
为了实现大规模莫场景式视频理解搜索和生成,Twelve Labs 建立了两个视频语言大模型,奠定了极大的技术优势:
Pegasus-1(800 亿参数)是 Twelve Labs 的视频语言模型(Video-to-Text),通过「视频优先」策略确保卓越的视频理解,具有高效的长视频处理、多模态理解、原生视频嵌入和深度视频语言对齐的优点。凭借 800 亿参数并在 3 亿视频-文本对的大型数据集上进行训练,它显著超越了之前的模型。在 MSR-VTT 数据集上显示出 61% 的提升,在视频描述数据集上提升了 47%。与 Whisper-ChatGPT 等 ASR+LLM 模型相比,Pegasus-1 的性能提升高达 188%,在视频转文本的准确性和效率上设立了新标准。
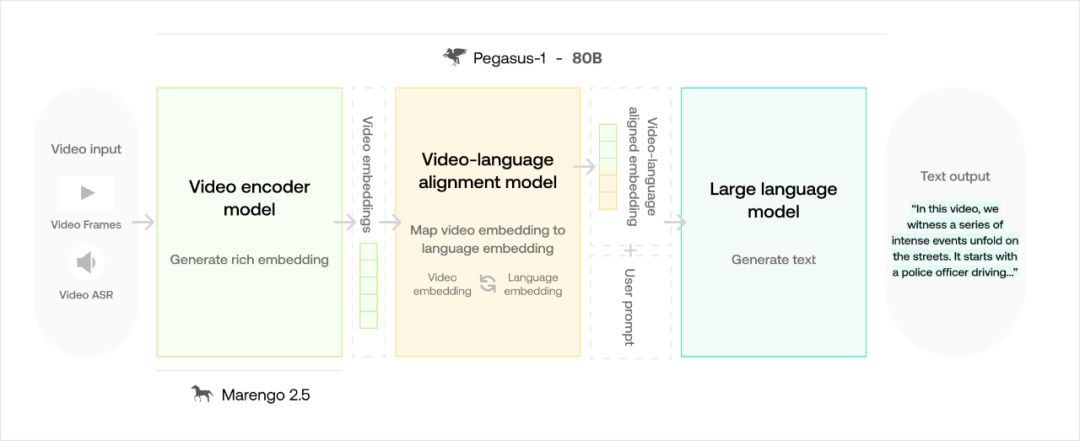
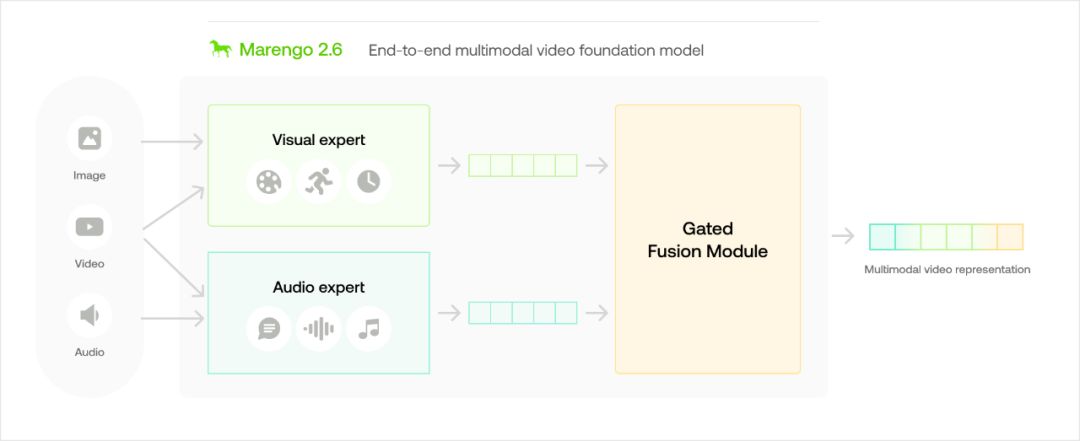
Marengo-2.6 是一款最先进的多模态基础模型,擅长执行文本到视频、文本到图像和文本到音频等任意搜索任务。它在 MSR-VTT 数据集上比 Google 的 VideoPrism-G 高出 10%,在 ActivityNet 数据集上高出 3%。具备先进的零样本检索能力,超越现有模型在理解和处理视觉内容上的表现。其多功能性还包括跨模态任务,如音频到视频和图像到视频。该模型通过重新排序模型实现了增强的时间定位,确保更精确的搜索结果,展示了在多种模态下令人印象深刻的感知推理能力。
小结
除了Twelve Labs之外,谷歌以及微软和亚马逊也推出了能够提供 API 级、人工智能驱动的服务的产品,这些服务可以识别视频中的对象、位置和动作,并在帧级提取丰富的元数据。随着这些技术的不断进步,我们可以预见,未来在视频理解领域的竞争将变得异常激烈。我们正站在一个由 AI 技术引领的新时代的门槛上。在这个时代,视频不再仅仅是动态的视觉记录,而是智能理解与深度学习技术融合的前沿。总之,Twelve Labs凭借其多模态视频搜索引擎,正在改变我们处理和获取视频信息的方式,为数字世界带来更为便捷、智能的体验。
高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0712_shemei