概述
SkipList,跳表,跳跃表,在LevelDB和Lucene中都广为使用。跳表被广泛地运用到各种缓存实现当中,跳跃表使用概率均衡技术而不是使用强制性均衡,因此对于插入和删除结点比传统上的平衡树算法更为简洁高效。
Skip lists are data structures that use probabilistic balancing rather than strictly enforced balancing. As a result, the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
传统意义的单链表是一个线性结构,在一个有序链表里,查询、插入、删除一个结点的算法时间复杂度都是O(n)。
跳表示意图
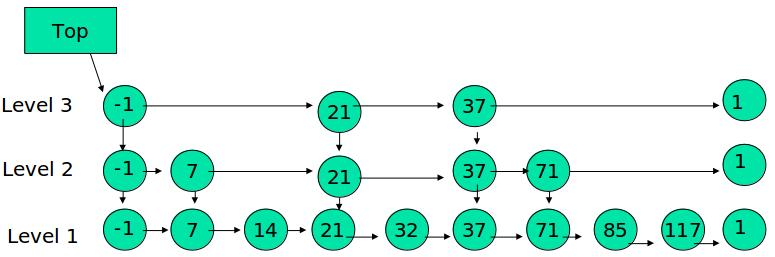
跳表是在链表之上加上多层索引构成的:
- 表头(head):负责维护跳跃表的结点指针
- 跳跃表结点:保存着元素值,以及多个层
- 层:保存着指向其他元素的指针,这个层数是随机的
每一个结点不单单只包含指向下一个结点的指针,可能包含很多个指向后续结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。对于一个链表内每一个结点包含多少个指向后续元素的指针,这个过程是通过一个随机函数生成器得到,这样子就构成一个跳跃表。通过随机生成一个结点中指向后续结点的指针数目。所有操作都以对数随机化的时间进行。
优点,跟红黑树、AVL等平衡树一样,做到比较稳定地插入、查询与删除,支持顺序操作。插入查询删除的算法时间复杂度理论值为O(logn),最坏情况下O(n)。
跳表性质:
- 由很多层结构组成,每一层都是一个有序的链表
- 最底层(Level 1)的链表包含所有元素,最底层数据结构退化为一个普通的有序链表
- 如果一个元素出现在Level i的链表中,则它在Level i之下的链表也都会出现
- 每个结点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素
- 搜索过程是逐层进行,不能越两级搜索
- 在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX)
- Top指针指向最高层的第一个元素
- 跳表是一种以牺牲更多的存储空间换取查找速度,即空间换时间
Skip List构造步骤
- 给定一个有序的链表
- 选择链表中最大和最小的元素,然后从其他元素中按照一定算法随机选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层
- 为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素
- 重复2、3步,直到不再能选择出除最大最小元素以外的元素
跳表的插入
先确定该元素要占据的层数K(随机),然后在Level 1...Level K各个层的链表都插入元素。K大于链表层数,则需要添加新层。跳表的插入需要三个步骤:
- 需要查找到在每层待插入位置
- 随机产生一个层数
- 从高层至下插入,插入时算法和普通链表的插入完全相同
删除结点操作和插入差不多,找到每层需要删除的位置,删除时和操作普通链表完全一样。如果该结点的level是最大的,则需要更新跳表的level。
理论



跳表 vs B+树
相同:都是用空间来换取时间,用额外的空间来保存链表或者目录页,来提升查询性能
区别:
- 层高:B+树三层就能支持千万级别的数据,但跳表存储相同的数据量需要更高的层级。InnoDB索引用B+树而不用跳表的原因,InnoDB强依赖于磁盘IO,层级越高,IO次数也就越多;Redis的zset是用的跳表,因为Redis是基于内存操作,没有磁盘IO概念,跳表更简单
- 操作数据:跳表比B+树快,B+树在数据操作时需要维护B+树,所以会有树的分裂与合并;跳表是随机一个层次,实现相对简单
跳表 vs 平衡树
类似于平衡树,用来快速查找。区别是平衡树的插入和删除可能需要一次需要全局调整,而跳表只需对整个数据结构进行局部操作。所以在高并发下,需要对平衡树进行全局锁,而跳表只需部分加锁。
本质是维护多个分层的链表,最底层的链表维护表内所有元素,每上面一层是下面一层的子集。表内所有元素的链表都是排序的。查找时,先从最顶层开始查找,当发现查找元素大于链表中取值就进入下一行,用空间换时间。
插入
插入时,先查询,然后从最底层开始,插入被插入的元素。然后看看从下而上,是否需要逐层插入。可是到底要不要插入上一层呢?想每层的跳跃都非常高效,越是平衡就越好(第一层1级跳,第二层2级跳,第3层4级跳,第4层8级跳)。但是用算法实现起来,确实非常地复杂的,并且要严格地按照2地指数次幂,我们还要对原有地结构进行调整。所以跳表的思路是抛硬币,听天由命,产生一个随机数,50%概率再向上扩展,否则就结束。这样子,每一个元素能够有X层的概率为0.5^(X-1)次方。反过来,第X层有多少个元素的数学期望大家也可以算一下。
删除
同插入一样,删除也是先查找,查找到之后,再从下往上逐个删除。
跳表 vs 红黑树
为什么Redis要使用跳表而不使用红黑树呢?跳表相对于红黑树的优点:
- 代码相对简单
- 如果要查询一个区间里面的值,用平衡树在实现和理解上可能会麻烦些,虽然可以实现
- 删除一段区间,用平衡二叉树则涉及到树的平衡问题而相当困难,跳表没有这个问题
应用
JDK
在JDK里也有跳表的实现,如ConcurrentSkipListMap和ConcurrentSkipListSet。
ConcurrentSkipListMap
JDK22版本下,ConcurrentSkipListMap属性如下:
java
/**
* 指定全局比较器,用于比较两个元素的关键字大小并进行排序,如果在构造器中没有显式传入指定比较器,则默认对key按照自然顺序排序
*/
@SuppressWarnings("serial") // Conditionally serializable
final Comparator<? super K> comparator;
/** 最上层索引链表的头结点,延迟加载(包括下面几个属性),即在使用时才会初始化 */
private transient Index<K,V> head;
/** 元素计数器 */
private transient LongAdder adder;
/** 保存key的set集合 */
private transient KeySet<K,V> keySet;
/** 保存value的集合 */
private transient Values<K,V> values;
/** 保存key-value的EntrySet集合 */
private transient EntrySet<K,V> entrySet;
/** 保存key-value结点的逆序排序的Map集合 */
private transient SubMap<K,V> descendingMap;内部类有Node、Index、,省略构造方法(下同):
java
static final class Node<K,V> {
final K key; // currently, never detached
V val;
Node<K,V> next;
}Node表示链表结点,用于保存数据,包括三个属性:key-键、volatile的value-值、volatile的next-后继结点。
java
static final class Index<K,V> {
final Node<K,V> node; // currently, never detached
final Index<K,V> down;
Index<K,V> right;
}Index表示基于链表的索引结点,用于保存索引关系和索引相关操作。包括三个属性:指向的链表数据结点node,指向下一层索引链表的索引结点down,指向同一层索引链表的当前结点的后继索引结点right。
抽象内部类Iter,见名知意,用于迭代:
java
abstract class Iter<T> implements Iterator<T> {
/** next()方法返回的最后一个节点 */
Node<K,V> lastReturned;
/** next()方法返回的下一个节点 */
Node<K,V> next;
/** 缓存下一个值字段以保持弱一致性 */
V nextValue;
/** 初始化整个范围的升序迭代器 */
Iter() {
advance(baseHead());
}
public final boolean hasNext() {
return next != null;
}
/** Advances next to higher entry. */
final void advance(Node<K,V> b) {
Node<K,V> n = null;
V v = null;
if ((lastReturned = b) != null) {
while ((n = b.next) != null && (v = n.val) == null)
b = n;
}
nextValue = v;
next = n;
}
public final void remove() {
Node<K,V> n; K k;
if ((n = lastReturned) == null || (k = n.key) == null)
throw new IllegalStateException();
// It would not be worth all of the overhead to directly
// unlink from here. Using remove is fast enough.
ConcurrentSkipListMap.this.remove(k);
lastReturned = null;
}
}基于Iter抽象类,有3个实现类分别用于Key、Value、Key和Value的遍历,即KeyIterator、ValueIterator、EntryIterator这3个内部类。
核心方法
- put:插入结点,调用doPut方法,使用到VarHandle的acquireFence、compareAndSet两个方法,以及
ThreadLocalRandom.nextSecondarySeed()方法,源码还是挺复杂的 - remove:删除结点,有多个重载方法,最后调用doRemove方法
- get:查找结点,调用doGet方法,也是使用到VarHandle的acquireFence、compareAndSet两个方法,和双层循环。基于doGet方法,还提供有用的getOrDefault方法
- replace:有两个方法
public V replace(K key, V value),如果指定key对应的结点存在,那么使用指定value替换旧value。返回以前与指定键关联的值;如果没有该键的映射关系,则返回nullpublic boolean replace(K key, V oldValue, V newValue):如果指定key-value对应的结点存在,则使用newValue替换oldValue。如果该值被替换成功,则返回true。
- contains:来自Map的方法,用于判断是否包括某个Key或Value,包括:
- containsKey:直接使用doGet来判断即可
- containsValue:通过一层循环来遍历
- size:判断大小
- isEmpty:判断是否为空,判断头结点是否为空即可:
return findFirst() == null; - clear:清空
doRemove方法使用两层嵌套循环,默认情况下使用break关键词只会跳出一层循环体。为了实现一次性跳出两层(多层也可以)循环,在最外层定义一个outer:,注意冒号不能省略,然后使用break outer实现:
java
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
V result = null;
Node<K,V> b;
outer: while ((b = findPredecessor(key, cmp)) != null && result == null) {
for (;;) {
Node<K,V> n; K k; V v; int c;
if ((n = b.next) == null)
break outer;
else if ((k = n.key) == null)
break;
else if ((v = n.val) == null)
unlinkNode(b, n);
else if ((c = cpr(cmp, key, k)) > 0)
b = n;
else if (c < 0)
break outer;
else if (value != null && !value.equals(v))
break outer;
else if (VAL.compareAndSet(n, v, null)) {
result = v;
unlinkNode(b, n);
break; // loop to clean up
}
}
}
if (result != null) {
tryReduceLevel();
addCount(-1L);
}
return result;
}另外outer标志字段可以使用其他非Java保留关键词都行,如flag。
有2个参数的replace方法源码:
java
public V replace(K key, V value) {
if (key == null || value == null)
throw new NullPointerException();
for (;;) {
Node<K,V> n; V v;
if ((n = findNode(key)) == null)
return null;
if ((v = n.val) != null && VAL.compareAndSet(n, v, value))
return v;
}
}有3个参数的replace方法源码:
java
public boolean replace(K key, V oldValue, V newValue) {
if (key == null || oldValue == null || newValue == null)
throw new NullPointerException();
for (;;) {
Node<K,V> n; V v;
if ((n = findNode(key)) == null)
return false;
if ((v = n.val) != null) {
if (!oldValue.equals(v))
return false;
if (VAL.compareAndSet(n, v, newValue))
return true;
}
}
}用于判断Value是否存在的containsValue方法:
java
public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
Node<K,V> b, n; V v;
if ((b = baseHead()) != null) {
while ((n = b.next) != null) {
if ((v = n.val) != null && value.equals(v))
return true;
else
b = n;
}
}
return false;
}size方法最大为Integer.MAX_VALUE:
java
public int size() {
long c;
return ((baseHead() == null) ? 0 : ((c = getAdderCount()) >= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) c);
}getAdderCount方法如下:
java
final long getAdderCount() {
LongAdder a; long c;
do {} while ((a = adder) == null && !ADDER.compareAndSet(this, null, a = new LongAdder()));
return ((c = a.sum()) <= 0L) ? 0L : c; // ignore transient negatives
}VarHandle
JDK 9引入的概念。TODO。
Kafka
Kafka的每个日志对象中使用ConcurrentSkipListMap来保存各个日志分段,每个日志分段的baseOffset作为key,这样可以根据指定偏移量来快速定位到消息所在的日志分段。
LevelDB
memtable用于存储在内存中还未落盘到sstable中的数据,这部分使用跳表做为底层的数据结构。
Lucene
占用内存小,且可调,但是对模糊查询支持不好。Lucene3.0之前使用的也是跳跃表结构,后换成FST,但跳跃表在Lucene其他地方还有应用如倒排表合并和文档号索引。
基于lucene-core-9.10.0版本,可以看到两个抽象类MultiLevelSkipListReader和MultiLevelSkipListWriter。前面的分析讲过,普通的快表只能从最上层往下一层层搜索,不能越两级搜索,因为没有维护越级的指针。
以MultiLevelSkipListReader为例,看看其属性有哪些:
java
public abstract class MultiLevelSkipListReader implements Closeable {
/** the maximum number of skip levels possible for this index */
protected int maxNumberOfSkipLevels;
/** number of levels in this skip list */
protected int numberOfSkipLevels;
private int docCount;
/** skipStream for each level. */
private IndexInput[] skipStream;
/** The start pointer of each skip level. */
private long[] skipPointer;
/** skipInterval of each level. */
private int[] skipInterval;
/**
* Number of docs skipped per level. It's possible for some values to overflow a signed int, but this has been accounted for.
*/
private int[] numSkipped;
/** Doc id of current skip entry per level. */
protected int[] skipDoc;
/** Doc id of last read skip entry with docId <= target. */
private int lastDoc;
/** Child pointer of current skip entry per level. */
private long[] childPointer;
/** childPointer of last read skip entry with docId <= target. */
private long lastChildPointer;
private final int skipMultiplier;
}TODO
Redis
zset数据结构,由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾结点、长度等),后者用于表示跳跃表结点