在当今科技迅速发展的时代,大型语言模型(Large Language Model,LLM)正以前所未有的速度改变着我们与数字世界的互动方式。基于LLM的智能代理(LLM Agent),从简单的信息搜索到复杂的网页操作,它们正在逐步融入我们的生活。然而,一个关键问题仍然悬而未决:当这些LLM Agent踏入真实的在线网络世界时,它们的表现能否如预期般游刃有余?
现有的评测方法大多停留在静态数据集或模拟网站的层面。这些方法有其价值,但局限性显而易见:静态数据集难以捕捉网页环境的动态变化,如界面更新和内容迭代;而模拟网站则缺乏真实世界的复杂性,未能充分考虑跨站操作,例如使用搜索引擎等操作,这些因素在真实环境中是不可或缺的。
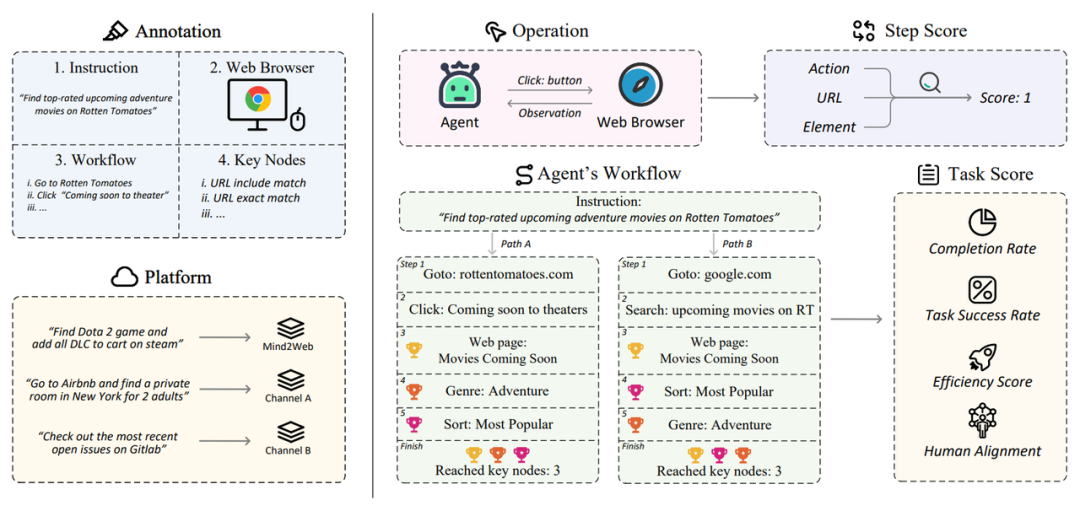
▲WebCanvas框架图。左侧展示的是任务的标注过程,右侧展示的是任务的评估过程。WebCanvas考虑到了在线网络交互中任务路径的非唯一性,"奖杯"代表成功到达每个关键节点后获得的步骤分数。
为破解这一难题,跨越星空科技的iMean AI团队和来自卡内基梅隆大学的合作者提出了一种创新的在线评测框架------WebCanvas,旨在为Agent在真实网络世界中的表现提供一个全面的评估方法。WebCanvas的创新点之一在于提出了"关键节点"的概念。这一概念不仅聚焦于任务的最终完成情况,还能够深入至任务执行过程的细节,确保评估的精准度。通过识别并检测任务流程中的关键节点------无论是到达特定网页,还是执行特定操作(如点击特定的按钮),WebCanvas为在线评估Agent提供了一个新的视角。
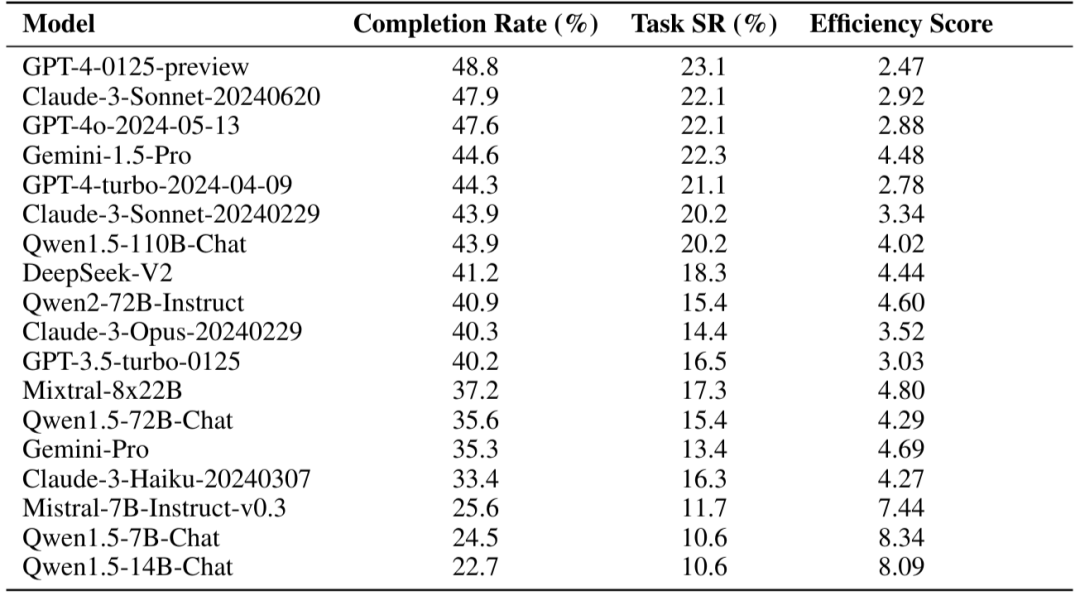
基于WebCanvas框架,作者构建了Mind2Web-Live数据集,该数据集包含从Mind2Web中随机挑选出的542个任务。本文作者还为数据集中的每个任务都标注了关键节点。通过一系列实验,我们发现,当Agent配备Memory模块,辅以ReAct推理框架,并搭载GPT-4-turbo模型后,其任务成功率提升至23.1%。我们深信,随着技术的不断演进,Web Agent的潜力依旧无限,这个数字将很快会被突破。

论文标题:
WebCanvas: Benchmarking Web Agents in Online Environments
论文链接:
https://arxiv.org/pdf/2406.12373
WebCanvas平台链接 :
项目代码链接:
https://github.com/iMeanAI/WebCanvas
数据集链接:
https://huggingface.co/datasets/iMeanAI/Mind2Web-Live
关键节点
"关键节点"的概念是WebCanvas的核心思想之一。关键节点指的是完成特定网络任务过程中不可或缺的步骤,也就是说,无论完成任务的路径如何,这些步骤都是不可或缺的。这些步骤涵盖了访问特定网页以及在页面上执行特定操作,如填写表单或点击按钮。
以WebCanvas框架图绿色部分为例,用户需要在烂番茄网站上寻找评分最高的即将上映的冒险电影。他可以通过多种途径达到目的,比如从烂番茄的首页开始探索,或者直接通过搜索引擎定位置"即将上映的电影"页面。在筛选影片的过程中,用户可能先选择"冒险"类型,再根据受欢迎程度排序,或者反之亦然。虽然存在多条实现目标的路径,但进入特定页面并进行筛选是完成任务不可或缺的步骤。因此,这三个操作被定义为该任务的关键节点。
评估指标
WebCanvas的评估体系分为两大部分:步骤得分和任务得分,两者共同构评估WebAgent综合能力。
- 步骤得分:衡量Agent在关键节点上的表现,每个关键节点都与一个评估函数相关联,通过三种评估目标(URL、元素路径、元素值)和三种匹配函数(精确、包含、语义)来实现。每到达一个关键节点并通过评估函数,Agent就能获得相应的分数。

▲评估函数总览,其中E代表网页元素Element
- 任务得分:分为任务完成得分和效率得分。任务完成得分反映Agent是否成功拿到了此任务所有的步骤得分。而效率得分则考量了任务执行的资源利用率,计算方法为每个步骤得分所需的平均步骤数。
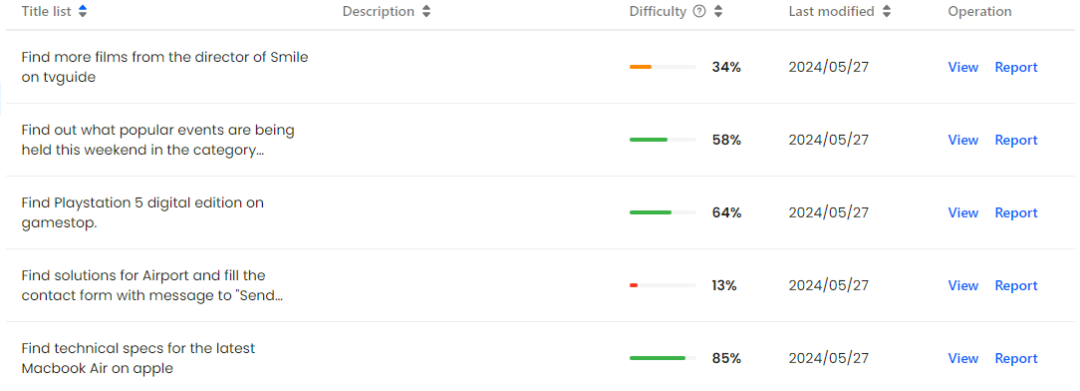
Mind2Web-Live数据集
作者从Mind2Web训练集中随机抽取了601个与时间无关的任务,以及测试集Cross-task子集中的179个同样与时间无关的任务,然后将这些任务在真实在线环境中进行标注。最终,作者构建了由542个任务组成的Mind2Web-Live数据集, 其中包含了438个训练样本和104个用于测试的样本。下图直观地展示了标注结果和评估函数的分布。
数据标注工具
数据标注过程中,作者使用了跨越星空科技开发的iMean Builder浏览器插件。该插件能够记录用户浏览器交互行为,包括但不限于点击、文本输入、悬浮、拖拽等动作,同时记录操作的具体类型、执行参数、目标元素的Selector路径,以及元素内容和页面坐标位置。此外,iMean Builder还为每一步操作生成网页截图,为验证和维护工作流程提供了直观的展示。
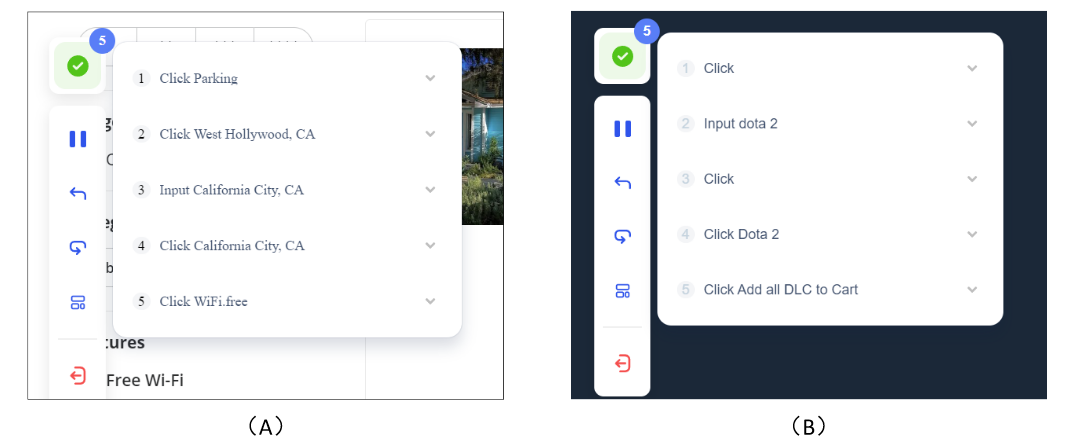
▲示例:使用iMean Builder插件注释两个不同的任务。(A) 在Yelp上查找加州提供免费Wi-Fi的豪华轿车停车场,(B) 在Steam上查找Dota 2游戏并将所有 DLC 添加到购物车中
数据维护
网络环境瞬息万变,网站内容的更新、用户界面的调整乃至站点的关闭都是不可避免的常态。这些变化可能导致先前定义的任务或关键节点失去时效性,从而影响评测的有效性和公平性。
为此,作者设计了一套数据维护方案,旨在确保评测集的持续相关性和准确性。在数据收集阶段,除了标注关键节点外,iMean Builder插件还能够详细记录每一步工作流执行的信息,包括动作类型、Selector路径、元素值以及坐标位置等。后续使用iMean Replay SDK的元素匹配策略就能重现工作流动作,并及时发现并报告工作流或评估函数中的任何无效情况。
通过此方案,我们有效解决了流程失效带来的挑战,确保了评测数据集能够适应网络世界的不断演变,为自动化评测Agent的能力提供了坚实的基础。
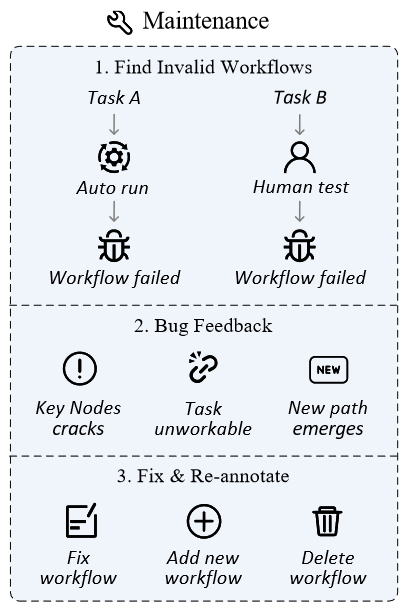
数据管理平台
在WebCanvas网站上集成了数据管理平台,用户可以清晰地浏览所有已录制的任务流程及其关键节点,也能够迅速向平台管理员反馈失效的流程,确保数据的时效性和准确性。
同时,作者鼓励社区成员积极参与,共同构建一个良好的生态系统。无论是维护现有数据的完整性,还是开发更先进的Agent进行测试,甚至是创造全新的数据集,WebCanvas都欢迎各种形式的贡献。这不仅促进了数据质量的提升,还鼓励技术创新,能够形成良性循环推动整个领域向前发展。
▲WebCanvas网站首页
▲Mind2Web-Live数据集的可视化展示
基础Agent框架
作者构建了一个全面的Agent框架,旨在优化Agent在在线网络环境下的任务执行效率。该框架主要由四个关键组件组成:规划(Planning)、观察(Observation)、记忆(Memory)以及奖励(Reward)模块。
-
规划(Planning):基于Accessibility Tree的输入,Planning模块运用ReAct推理框架进行逻辑推断,生成具体的操作指令。此模块的核心功能在于根据当前状态和任务目标,给出行动路径。
-
观察(Observation):Agent通过解析浏览器提供的HTML源代码,将其转换成Accessibility Tree结构。这一过程确保了Agent能够以标准化格式接收网页信息,便于后续分析和决策。
-
记忆(Memory):Memory模块负责存储Agent在任务执行过程中的历史数据,包括但不限于Agent的思考过程、过往的决策等。
-
奖励(Reward):Reward模块能对Agent的行为给予评价,包括对决策质量的反馈以及给出任务完成信号。
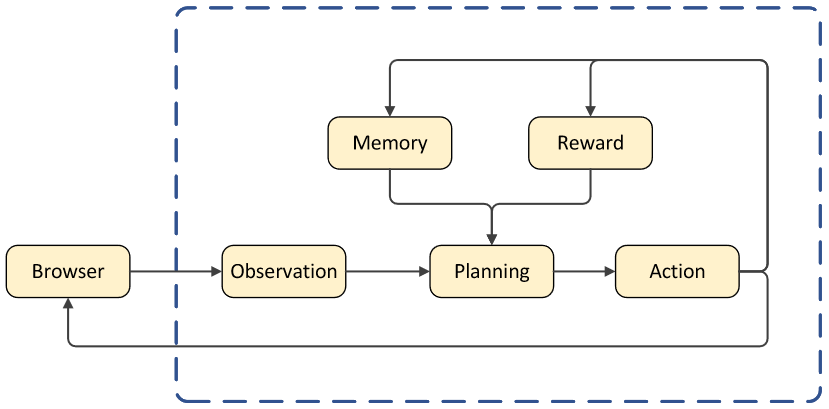
▲基础Agent框架示意图
主要实验
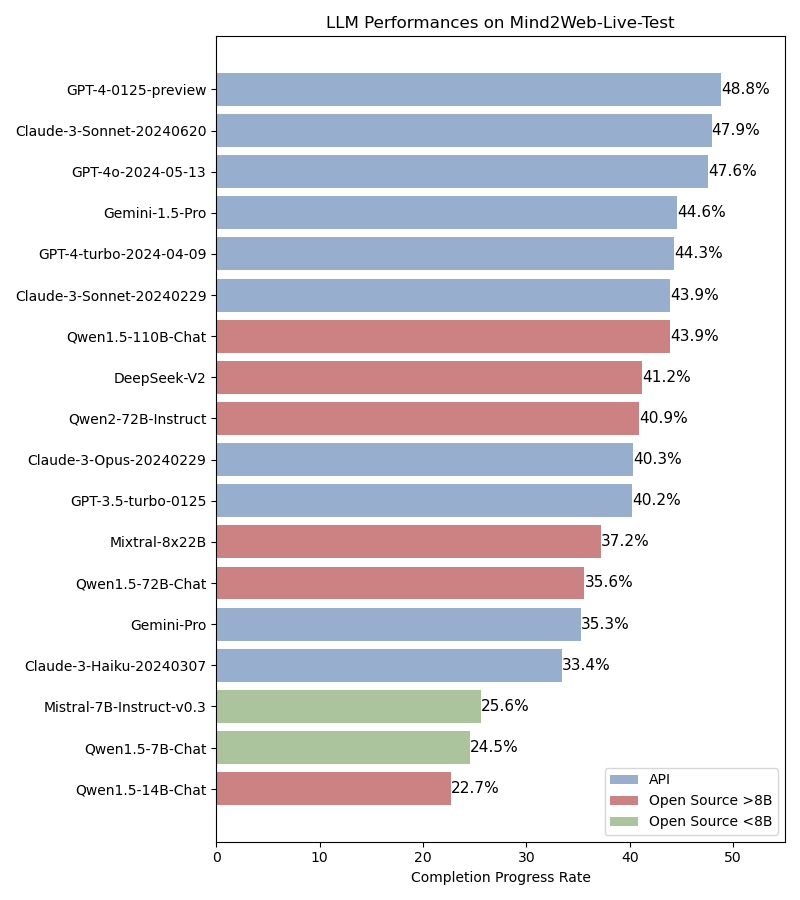
作者使用基础Agent框架并接入不同LLM进行评估(不含Reward模块)。实验结果如下图所示,其中Completion Rate指的是关键节点的达成率,Task Success Rate指的是任务成功率。
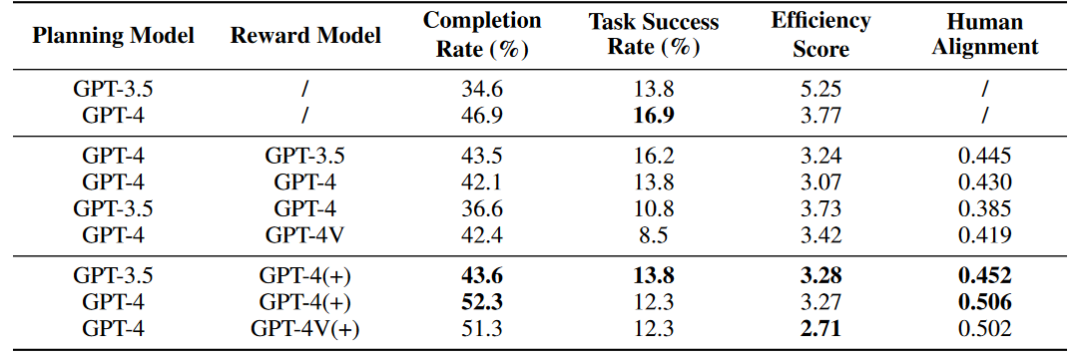
除此之外,作者还探索了Reward模块对Agent能力的影响,其中(+)号代表Reward信息中包含人类标注数据以及关键节点信息供Agent参考,Human Alignment分数代表Agent与人类的对齐程度。初步实验的结果表明,在线网络环境中,Agent并不能够通过Self Reward模块改善能力,但是整合了原始标注数据的Reward模块能够增强Agent的能力。
实验分析
在附录中,作者对实验结果进行了分析,下图是任务复杂度与任务难度之间的关系,橙色线条描绘了关键节点达成率随任务复杂度增加的变化轨迹,而蓝色线条则反映了任务成功率随任务复杂度的变化轨迹。
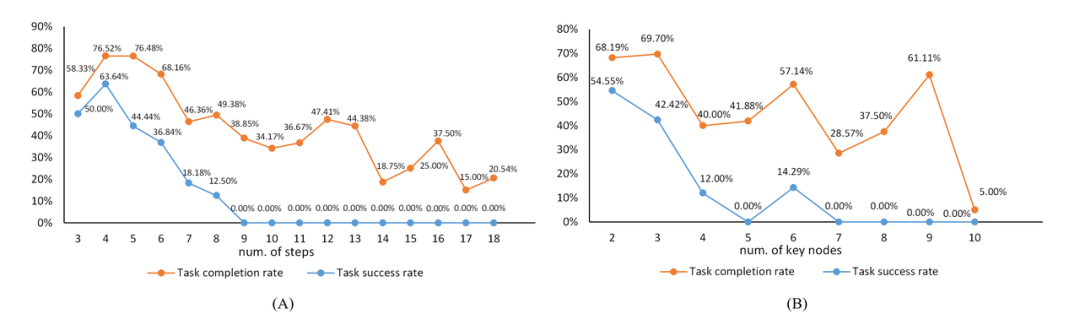
▲任务复杂度与任务难度之间的关系。"num of steps"指的是标注数据中动作序列的长度,与关键节点的数量一起作为任务复杂度的参考。
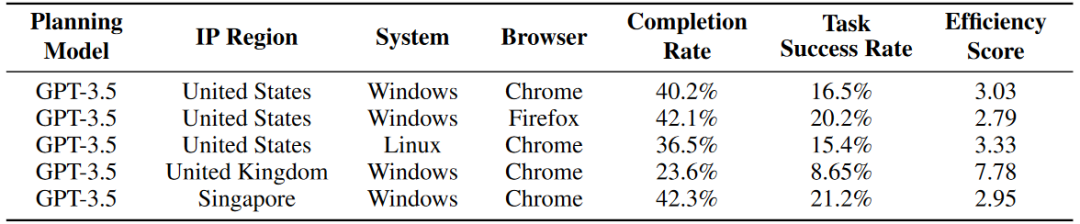
下表是实验结果与地区、设备、系统之间的关系。作者鼓励实验在美国地区或使用美国的Windows服务器进行相关实验。
全文总结
在推动LLM和Agent技术发展的征途上,构建一套适应真实网络环境的评测体系至关重要。本文聚焦于在瞬息万变的互联网世界中有效地评价Agent的表现。我们直面挑战,通过在开放的环境中界定关键节点和对应的评测函数达成了这一目标,并开发数据维护系统减小了后续维护成本。
经过不懈努力,我们已迈出了实质性的步伐,并向着建立稳健且精准的在线评测系统前进。然而,在动态的网络空间中进行评测并非易事,它引入了一系列在封闭、离线场景下未曾遭遇的复杂问题。在评测Agent的过程中,我们遇到了诸如网络连接不稳定、网站访问限制,以及评测函数的局限性等难题。这些问题凸显出在复杂的真实环境中,对Agent进行评测所面临的艰巨任务,要求我们不断精进调整Agent的推理和评测框架。
我们呼吁整个科研社区共同协作,以应对未知挑战,推动评测技术的革新与完善。我们坚信,只有通过持续的研究与实践,才能逐步克服这些障碍。我们期待着与同行们携手并进,共创LLM Agent的新纪元。
主要作者介绍
潘奕琛:浙江大学硕士一年级研究生。
孔德涵:跨越星空科技模型算法负责人。
周思达:南昌大学2024届毕业生,将于西安电子科技大学攻读硕士。
崔成:浙江中医药大学2024届毕业生,将于苏州大学攻读硕士。
潘奕琛、周思达、崔成以跨越星空科技算法实习生的身份共同完成了本论文的研究工作。

