关键点检测,作为计算机视觉领域的重要分支,广泛应用于人体姿态估计、面部表情识别、手部动作分析等多个场景。其核心在于从图像中准确检测并定位特定的关键点位置。然而,高效的模型训练离不开大量高质量的标注数据。本文将详细介绍关键点检测数据的标注方法,包括标注工具的选择、标注流程以及注意事项,帮助自己深入理解并掌握关键点检测数据标注的全过程。
在开始数据标注之前,选择一款合适的标注工具至关重要。目前市面上有多种标注工具可供选择,如LabelMe、VGG Image Annotator (VIA)等。这些工具均支持关键点检测标注,但功能和易用性有所差异。例如,LabelMe提供了丰富的交互式标注界面,适合复杂场景下的多目标标注;而VIA则以其简洁的界面和灵活的配置选项受到开发者青睐。根据项目需求和个人偏好选择最合适的工具,可以显著提高标注效率。
我这里就使用开源工具Labelme 来制作关键点检测数据集。
1 安装Labelme
首先,我们需要安装Labelme工具,很简单,直接pip就可以。
pip install labelme但是请确保你已经安装了Python和pip。如果还没有安装,请先安装Python,然后再安装pip。
然后在python环境直接输入 labelme。即可出现下面页面,即安装成功:
2 labelme标注关键点的流程
在使用labelme进行标注之前,我们需要创建一个标签,用于存放物体类别名称和关键点名称。你可以在任意位置创建一个名为labels.txt的文本文件,并在其中添加你的标签名称,比如:
person,head,neck,body,hand,foot文件如下:
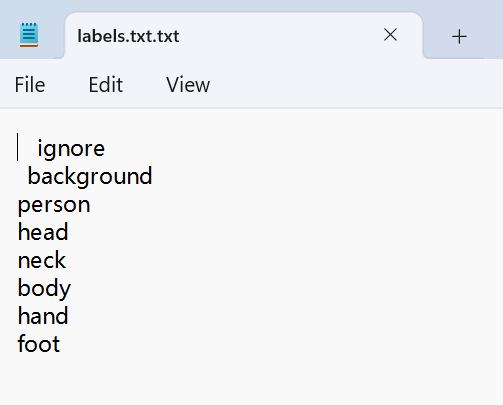
上述内容表示我们要标注的物体类别是person,并且标注的关键点有head, neck, body, hand 和 foot。(具体你想标注什么,都取决于自己的需求,按照自己的要求写即可,也不可以这样做,直接启动即可)
现在我们就可以使用Labelme来标注关键点了,在命令行中输入以下命令启动Labelme:
labelme --labels labels.txt注意:labels.txt的目录一定要正确。
Labelme将打开一个图形界面。点击界面左侧的Open Dir按钮,选择包含您要标注的图像的文件夹。然后,您可以在右侧看到文件夹中的图像列表。按下键盘上的A键或D键可以切换到上一张或下一张图片。
要开始标注关键点,请右键点击图像,选择Create Point。然后,左键点击图像中要标注的关键点位置,并输入关键点的名称。例如,如果您要标注颈部的关键点,可以输入neck。重复此步骤,直到您标注完所有需要的关键点。
注意:创建矩形框有快捷键,你也可以设置其他快捷键,比如创建关键点。
完成标注后,点击界面上方的File菜单,选择Save保存标注结果。Labelme将在图像所在的文件夹中创建一个与图像同名的JSON文件,用于存储标注信息。
我们可以查看保存标定后的数据,数据如下:
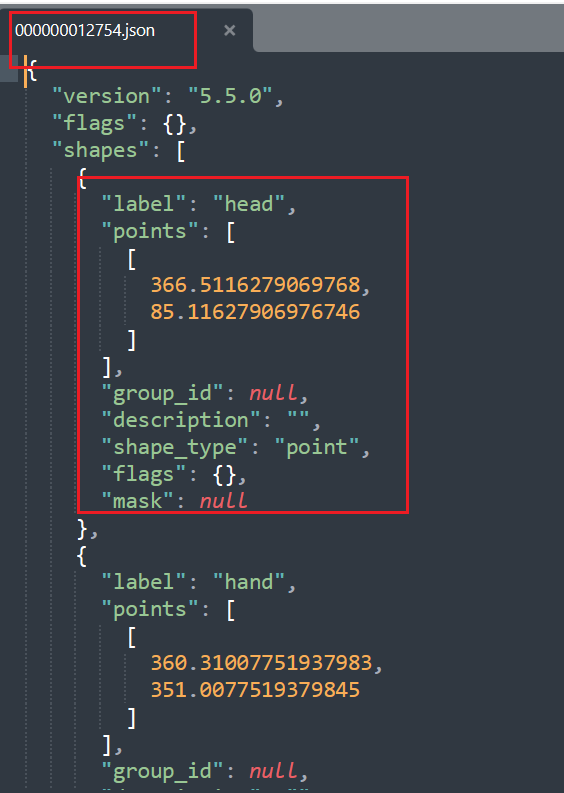
值得一提的是,我们可以点击Open Dir打开需要标注的图像文件夹,点击File,取消保存图片数据,取消对号(这样做的目的就是减少保存图像,这样可以降低json的大小),另外也可以进行其他设置。
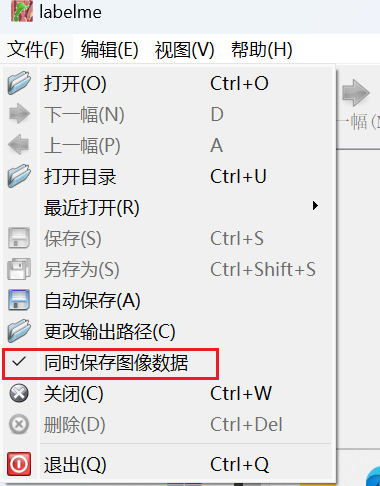
我这里做一个对比,就是取消保存标注后的数据和不取消,大家可以看看其JSON的大小。

其中主要是下面的差距:
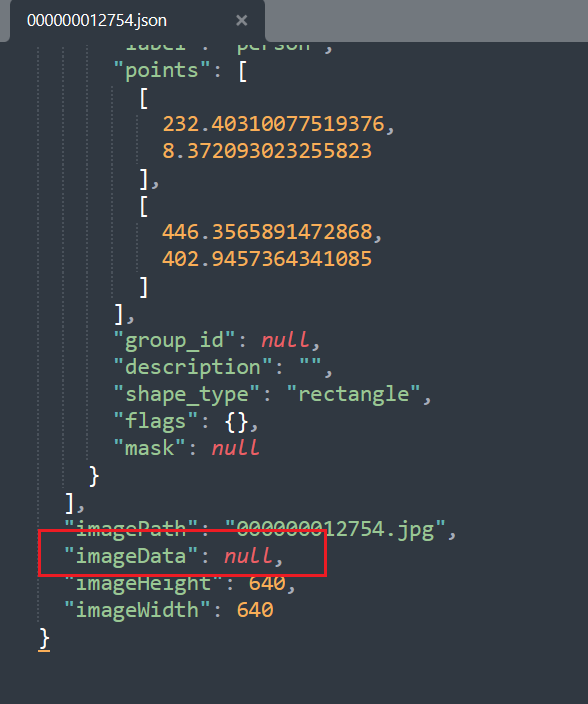
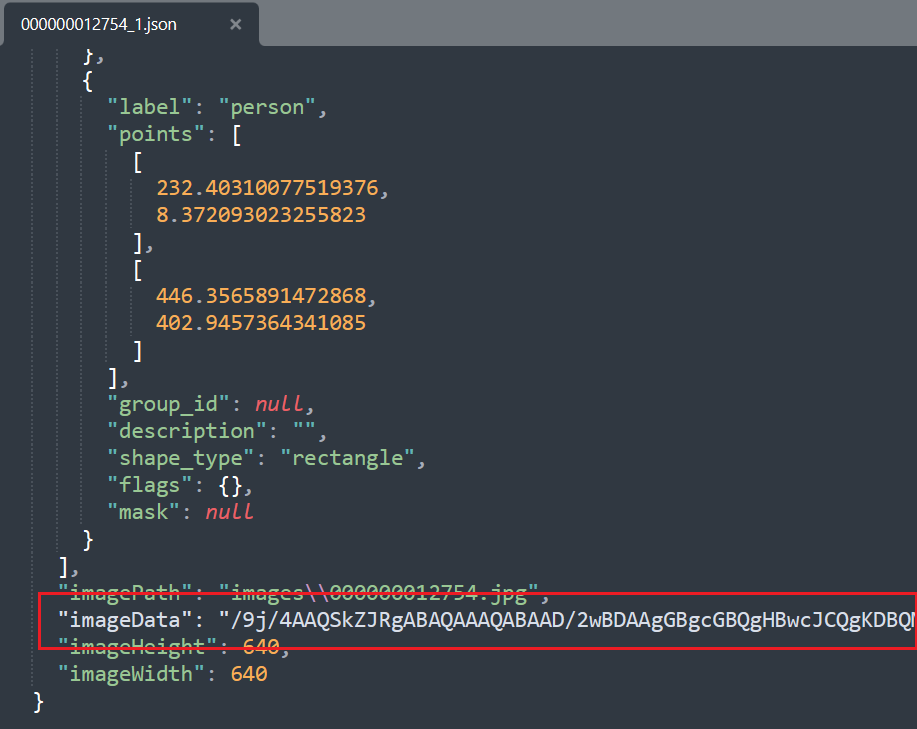
所以说建议取消保存图片数据。这样可以节省空间。我们从上面也看到了一个JSON文件可以节省84KB(当然这个取决于图像大小)。对于大量图像的标注任务而言,取消保存图像可以节省大量的空间。当然在一些情况下,图像可能包含敏感信息。保存图像数据可能涉及隐私问题。取消保存图像也可以避免泄露敏感信息的风险。最后就是不保存图像可以减少标注过程中的数据处理时间。
那么取消保存图片数据意味着在以后使用标注数据时需要同时保存原始图像数据,以便在需要时进行匹配。
这里展示一下标注的效果:
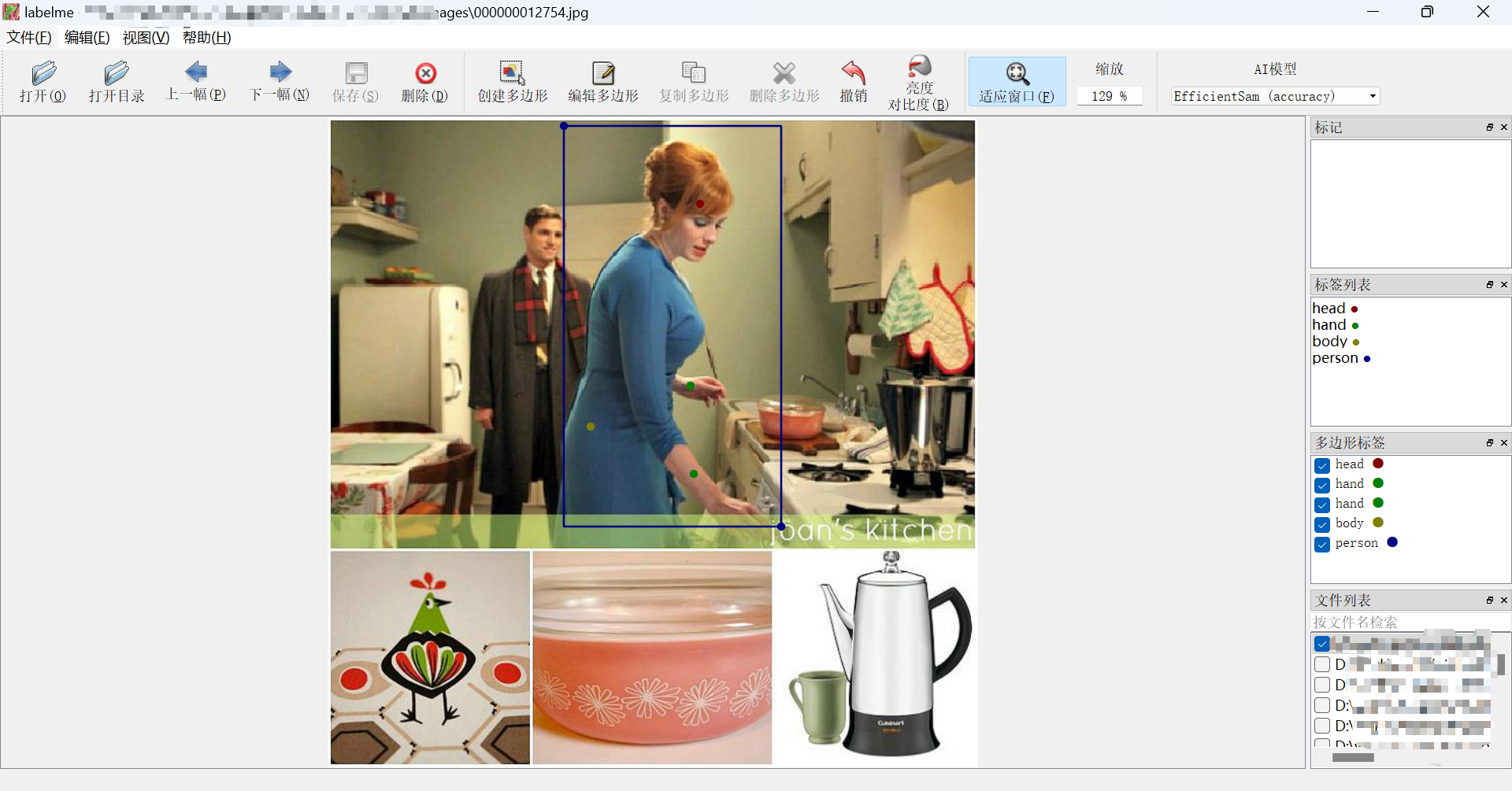
注意2:尽量让标注文件与对应的图片位于同一文件夹下,否则ImagePath将不止是文件名,可能会影响后续操作,特别是对初学者来说。
3 CVAT的简单介绍
** GitHub地址为:https://github.com/opencv/cvat**
** 官方说明文档:https://opencv.github.io/cvat/docs/**
部署安装就不多介绍了,我想官网的文档肯定更加清晰。 安装完成后,在浏览器中登录CVAT平台,如下图:
CVAT的使用逻辑是,先创建一个organization(组织),在组织里创建一个project(项目),然后在project里面创建一个task(任务),创建任务时,需要创建一个可以认为是模板的东西,把人体的基本结构画出来,然后在标注的时候,直接通过挪动点的位置的方法,来进行标注。(这样某种程度上可以减少标注的时间,但前提是标注的点差异不是很大,不然全部要挪动)。
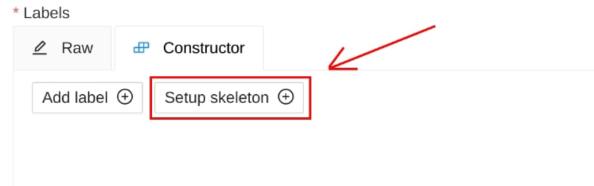
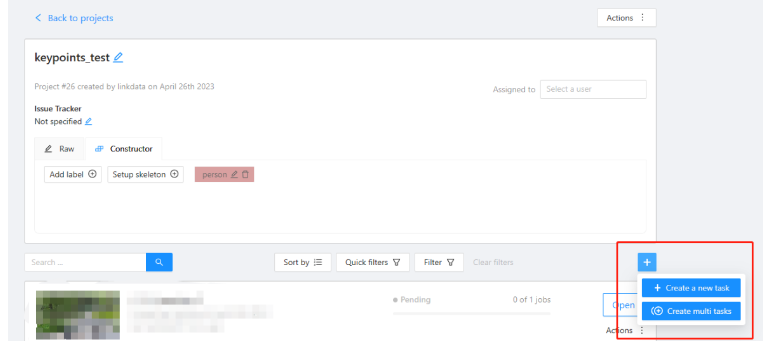
在创建任务的时候,点击Setup Skeleton。
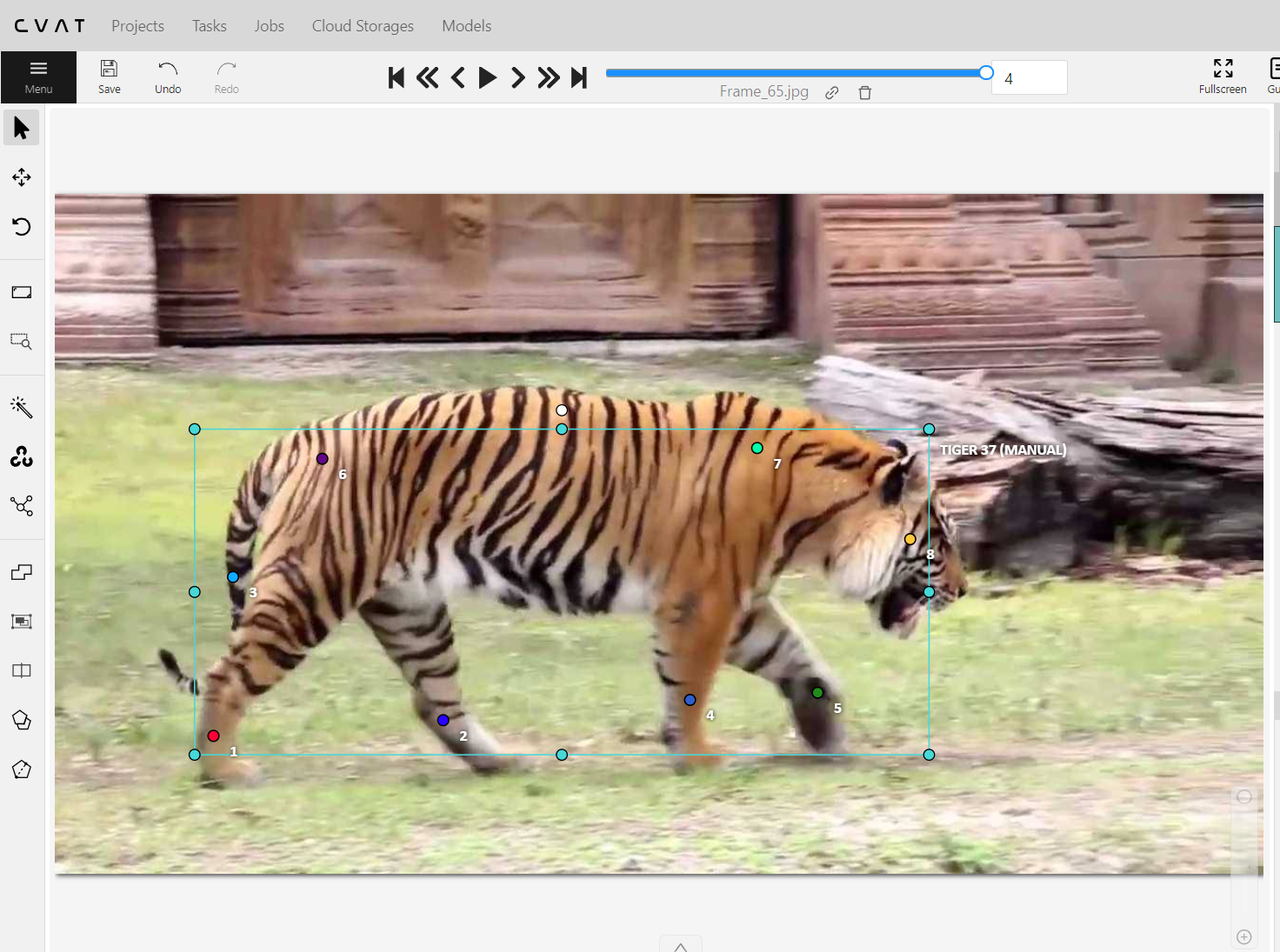
比如说标注人体数据,我们可以先上传一张正面 人体全身照(做参照来设置关键点),因为是人体关键点,所以标签设置为"person", 再选择点标注,然后绘制区域将人体的点画出来。我们总共是标注了17个点。按照coco keypoints的要求来标17个点哈。
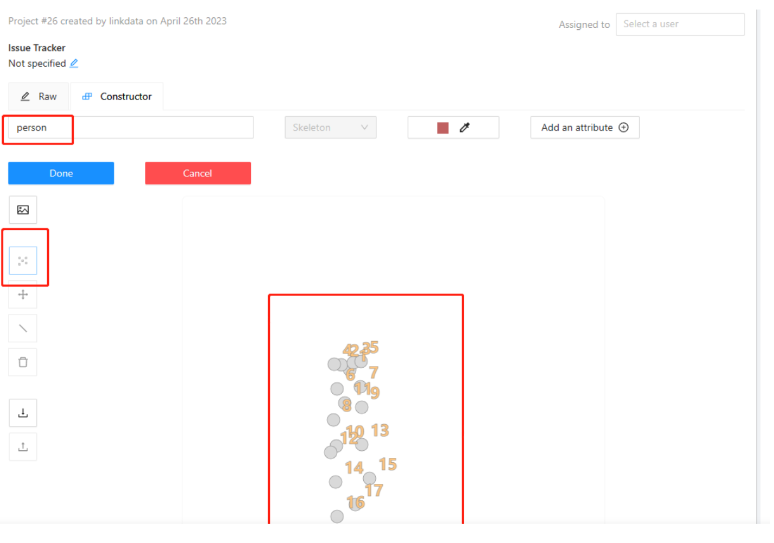
这个设置好之后,点击done,完成。
然后就可以上传图像,发布任务了,点击+ 号,可以一次创建一张图,可以一次创建多张图,或者视频,创建完之后,就可以在这个页面看到刚发布的任务了。
在标注完成之后,点击menu按钮,export job dataset,选择 COCO keypoints 1.0格式,点击OK即可。
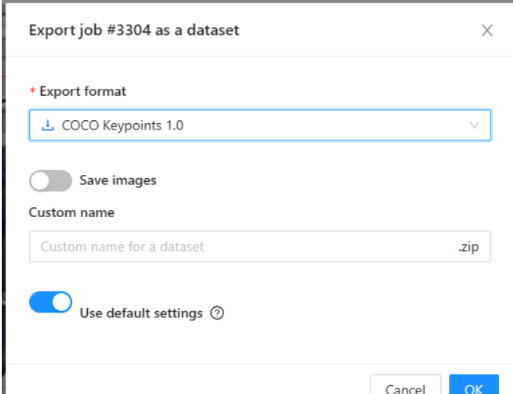
导出的数据格式只有一个json文件,后续就可以拿这个数据集来搞自己的事情了。
4 标注流程详解
-
数据准备:首先,收集并整理待标注的数据集。确保图像清晰无遮挡,关键点可见,以便于后续的标注工作。
-
标注规范制定:定义关键点的类型和位置,例如,在人体姿态估计任务中,可能需要标注头部、肩部、肘部、手腕、臀部、膝盖和脚踝等关键点。明确标注标准,如关键点的命名规则、坐标系选择等,以保持标注的一致性和准确性。
-
开始标注:使用选定的标注工具,逐一在每张图片上标注出关键点的位置。通常,标注工具会提供画布、放大镜等功能,辅助标注者精确定位。对于每个关键点,需确保其位置精确无误,必要时可利用工具提供的测量功能校正位置。
-
质量检查:完成初步标注后,进行质量检查,确保所有关键点都被正确标注,且无遗漏或错误。此步骤可以通过人工复查或使用自动化工具进行。
5 标注的注意事项
1,标注关键点时,要先使用矩形框框出目标,再标注关键点。这样可以确保标注的准确性,避免因为目标位置不正确而导致标注错误。
2,实际上关键点可以不用固定的顺序,但是每张图都要保持一致。也就是说如果我们在一张图像中将鼻子标注为1号点,那么在所有图像中,1号点都应该是鼻子。
3,被遮挡的点也应标注出来。在实际应用中,有些关键点可能会被挡住,这时我们需要将其标注出来,以便在模型训练时能够考虑到这种情况。
4,labelme无法标注关键点是否可见,默认为1.0, 在后续处理中,我们需要将其全部更改为2.0,以符合一些算法(比如YoLov8-Pose)的格式要求。
5,每一个关键点必须且只能落入一个框中,不落入第二个框中。