毫不夸张的说 PDF解析工具MinerU是照进RAG黑暗中的一道光------这是我对它的评价。我测过太多了文档解析工具!
最近在做文档解析的工作。看了很多的开源的文档解析的工具,版面分析的工具,其中包括paddelpaddel这样30k+star的明星工具。但是效果都觉得不好。
MinerU是一个最近开源的文档解析工具,可以把PDF转成json结构,还可以转成md格式。可以解析得到其中的图片,表格,可以得到段落,可以得到标题,这是很哇塞的事情。因为最近RAG特别火热,这些都是RAG非常需要的。文档解析是非常重要的一个环节。可以看看这篇文章。 RAG的上限在哪里?边界在哪里?_rag的限制-CSDN博客
虽然现在MinerUstar数量不高,1k star都不到,但是绝对会涨起来的。我们调研对比过很多开源的工具,效果都强差人意,这个是我看到的最满意的一个。甚至要比我们生产环境的都要好一些。MinerUstar 绝对是一个为RAG而创造的工具,开源世界的一道光。
这篇文章会详细介绍它的解析效果,它的优势和不足。并且给出详细的安装教程。MinerU 在github上的安装教程太粗糙了。一堆问题。
环境介绍
windows10 环境
使用CPU运行
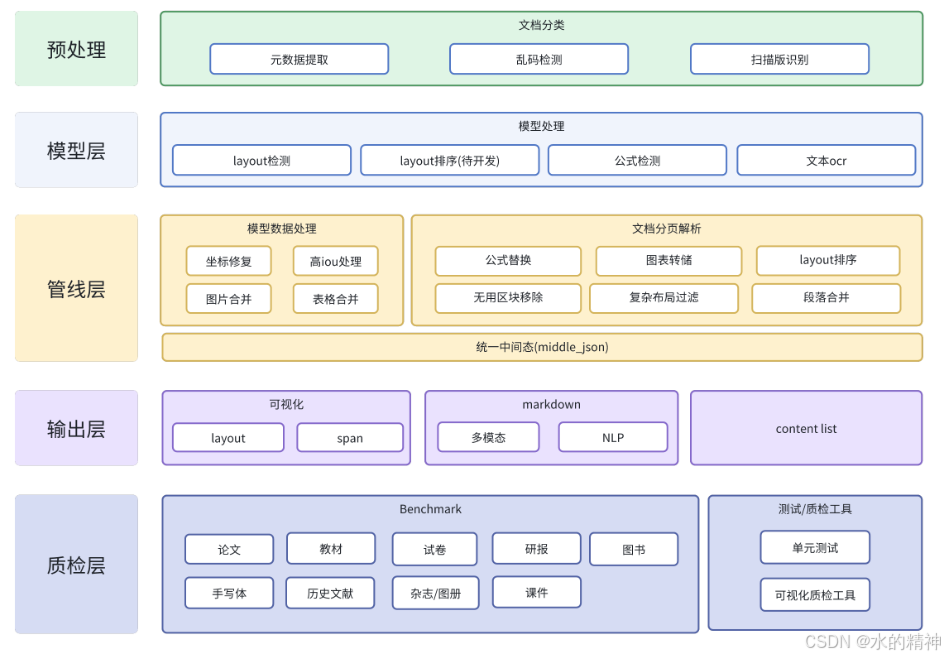
Magic-PDF简介
MinerU 是一款一站式、开源、高质量的数据提取工具,主要包含以下功能:
Magic-PDF 是一款将 PDF 转化为 markdown 格式的工具。支持转换本地文档或者位于支持S3协议对象存储上的文件。
解析系效果总结
我觉得不妨先看看解析的效果,不着急折腾环境,先看看我列出来的缺点是否能接受。或者看看优点是不是自己想要的。再去安装它。
缺点
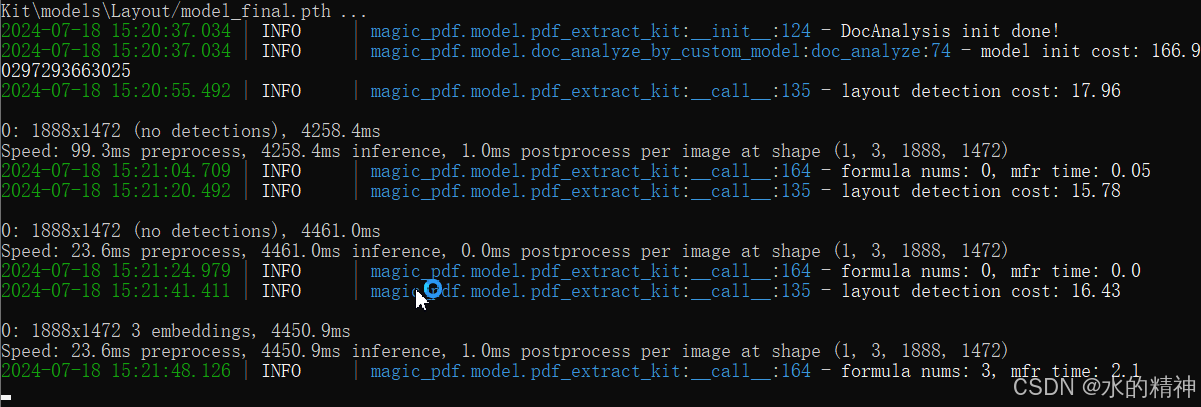
问题1: 解析速度慢
这里使用的CPU跑的,6页大概两三分钟。解析走的纯模型,先版面分析,再ocr,再公式检测。
模型初始化耗时167s,之后每页大概是16s
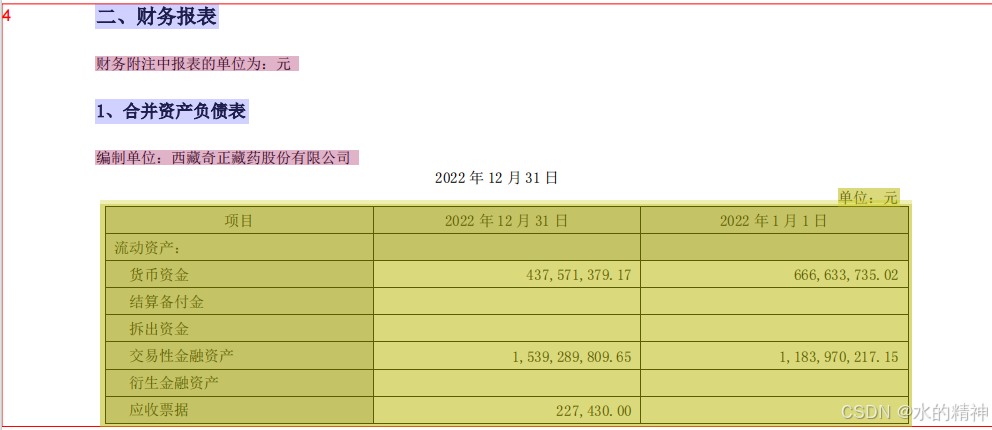
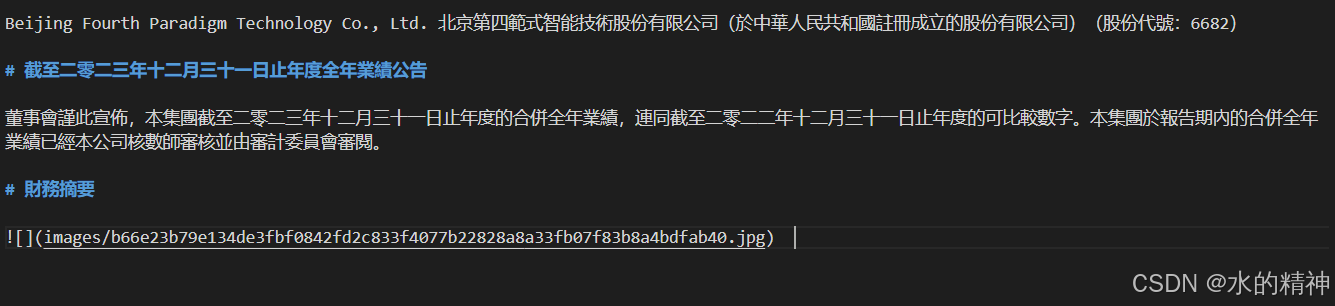
问题2:表格解析成图片
把表格处理成了图片
原文件如下所示
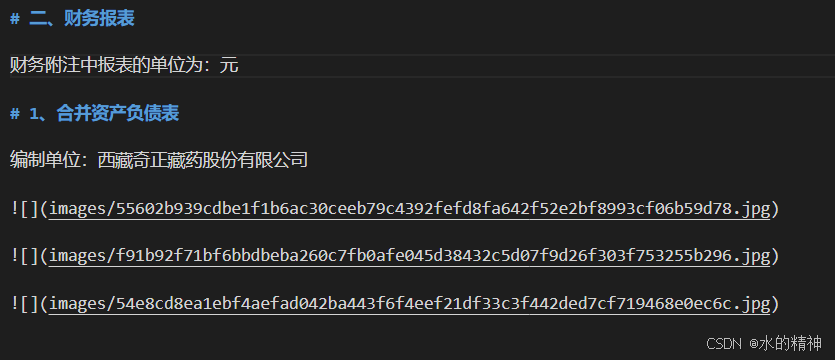
解析结果如下所示
原文件如下
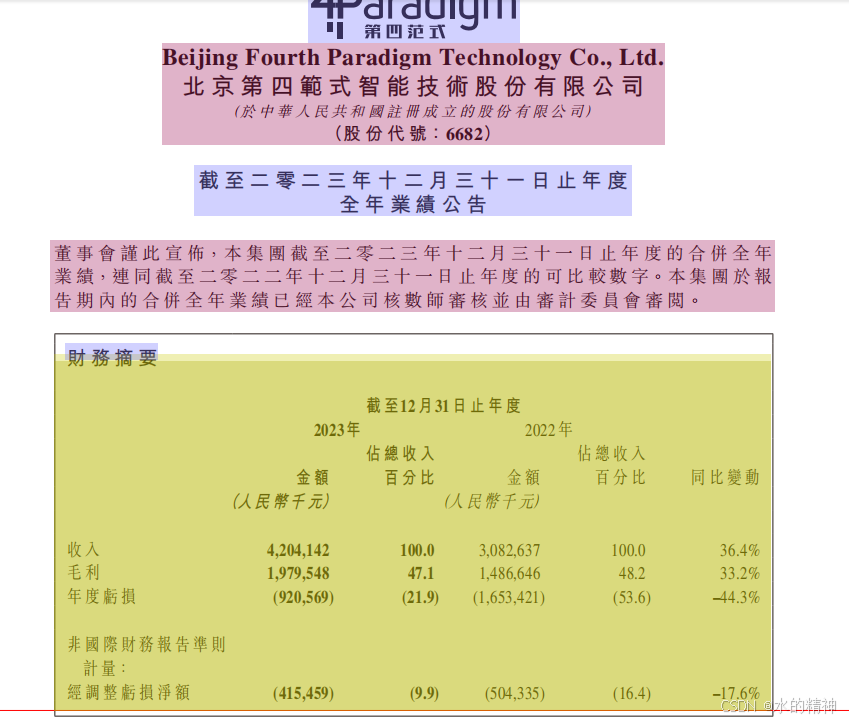
解析后的结果
问题3:标题识别不准确,且没有分层
原文件
解析后的结果
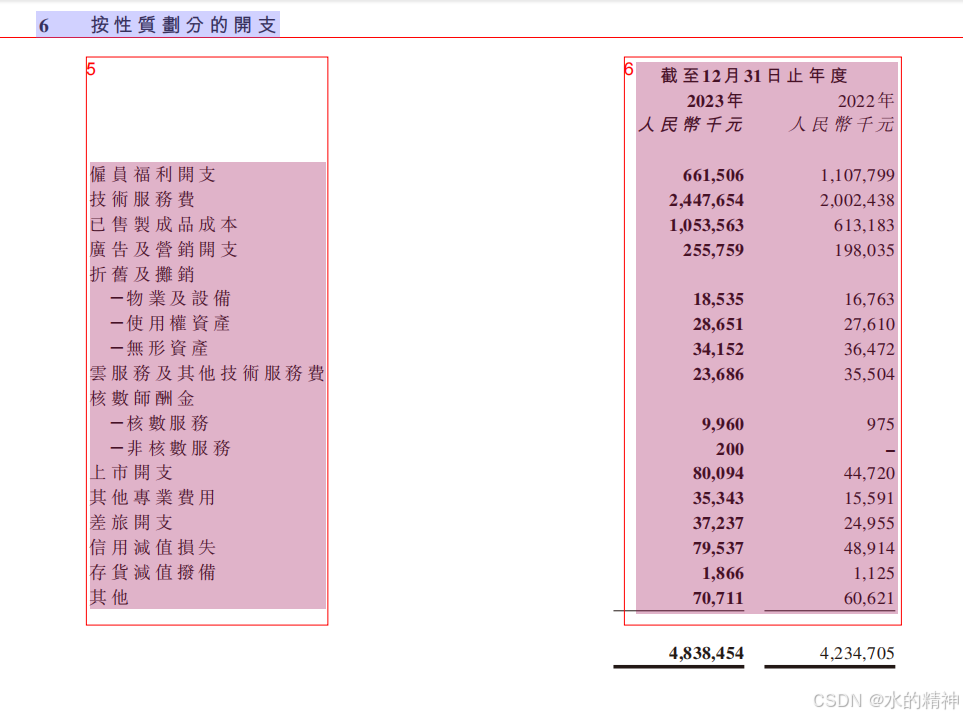
问题4:财报中的表格没有识别出来
优点
优点1:论文版面分析准确
表定位,图表定位准确。测了一篇论文,都正确。并且准确获取到了表格和图片的caption
支持多栏,解析顺序是正确的
优点2:混乱的杂志 + 多栏 + 图片
解析效果挺不错。一页多栏,顺序是对的。
优点3:多语言
测了中文和英文。都可以,github上的描述,支持176种语言
优点4:获取了表格和图片的caption
能够获取到caption并且单独存储了。
优点5:页眉页脚、脚注识别准确
转md的时候,都已经去掉了。
优点6:段落结构比较好
段落合并的好。得到的结果多数是自然段落
优点7:可以解析公式
优点8:多平台多环境支持
支持windows/linux/mac平台;支持cpu和gpu环境
安装MinerU
虚拟化环境
conda create -n MinerU python=3.10
conda activate MinerU
安装配置
pip install magic-pdffull-cpu
这一步最好有科学上网,不然可能拉不到。
pip install detectron2 --extra-index-url https://myhloli.github.io/wheels/
下载模型
模型,这里是模型没有下载,会报错如下

这里为了方便,使用git来从魔搭上拉取
git clone https://www.modelscope.cn/wanderkid/PDF-Extract-Kit.git`
`如果想要使用其它的方式拉取,参考
MinerU/docs/how_to_download_models_zh_cn.md at master · opendatalab/MinerU · GitHub
修改配置文件
在仓库根目录可以获得 MinerU/magic-pdf.template.json at master · opendatalab/MinerU · GitHub 文件
这里解释一下这个命令,实际上是把配置文件发在了c盘的user目录下。
cp magic-pdf.template.json ~/magic-pdf.json
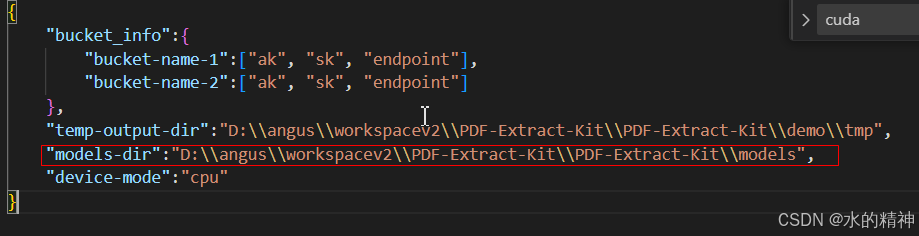
修改配置文件的内容,如下图所示。 output-dir是解析后的文件结果存放的目录。 models-dir是下载的模型的地址。
如果还是不知道放在哪里,可以先启动一下,会报一个错误,找不到配置文件
magic-pdf pdf-command --pdf "page1.pdf" 注意这里替换成自己文件
根据报错,把上述的配置文件放过去就可以。
接下来测试解析效果
magic-pdf pdf-command --pdf "困难pdf节选西藏奇正2022.pdf" --inside_model true
正常解析
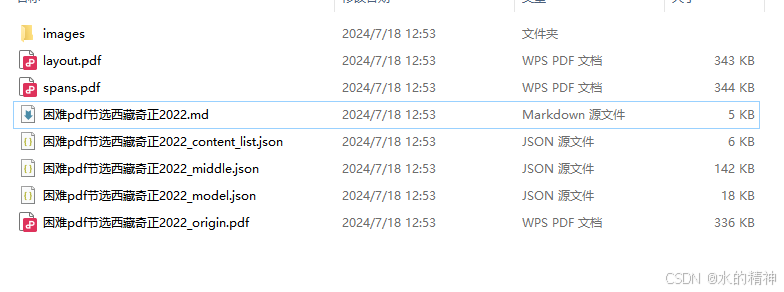
解析后得到的结果
包含了md结构,json结构,和版面分析的结果
md

layout
