【Apache Doris】数据副本问题排查指南
本文主要分享Doris中数据副本异常的问题现象、问题定位以及如何处理此类问题。
一、问题现象
- 问题日志
查询报错
Failed to initialize storage reader, tablet={tablet_id}.xxx.xxx- 问题说明
查询时,FE让BE返回spec_version范围的数据,但是BE缺部分version了,就会报这个错误。
- 问题原因
迁移副本过程可能丢version,在2.0.3修复了,或者在数据导入过程中be宕机。
注意:
如果版本是2.0.1及以前,且它的所有副本last failed version > 0,通常需要重新建表进行导数。
二、问题定位
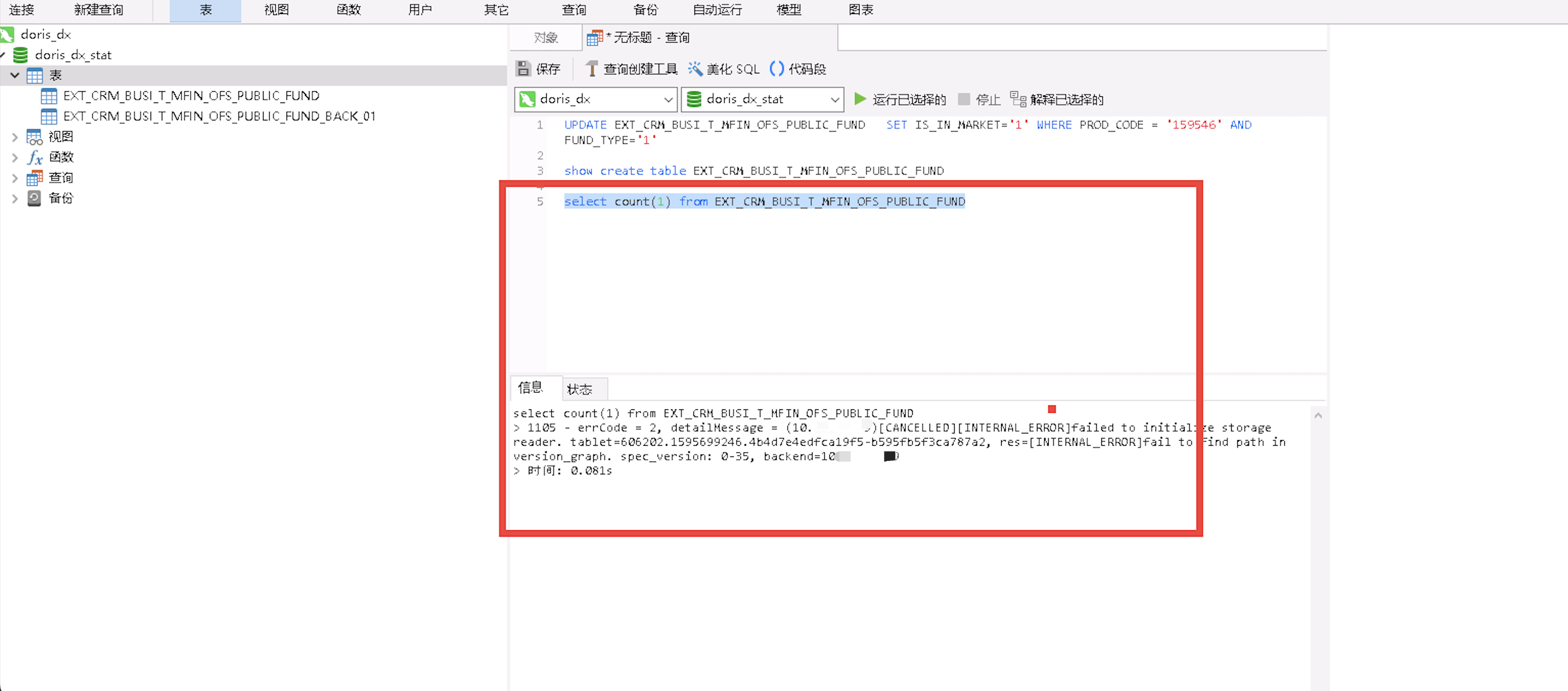
如上图所示,查询报错的 tablet_id 是 606202, BE ip是 10.xxx, BE 需要包含version 区间 0 - 35。
当确定异常tablet_id时,参考如下步骤先进行问题信息收集:

-
show tablet {tablet_id} (这里是606202),拿到detail cmd
-
执行detail cmd的输出
SHOW PROC ' /dbs/10113/591325/partitions/606195/591326/606202";
找出该BE所在的副本(compact status url中包含有该BE的ip)
-
执行curl<步骤2的compact status url>, 该例子是
curl http://10.xxx:8040/api/compaction/show?tablet_id=606202
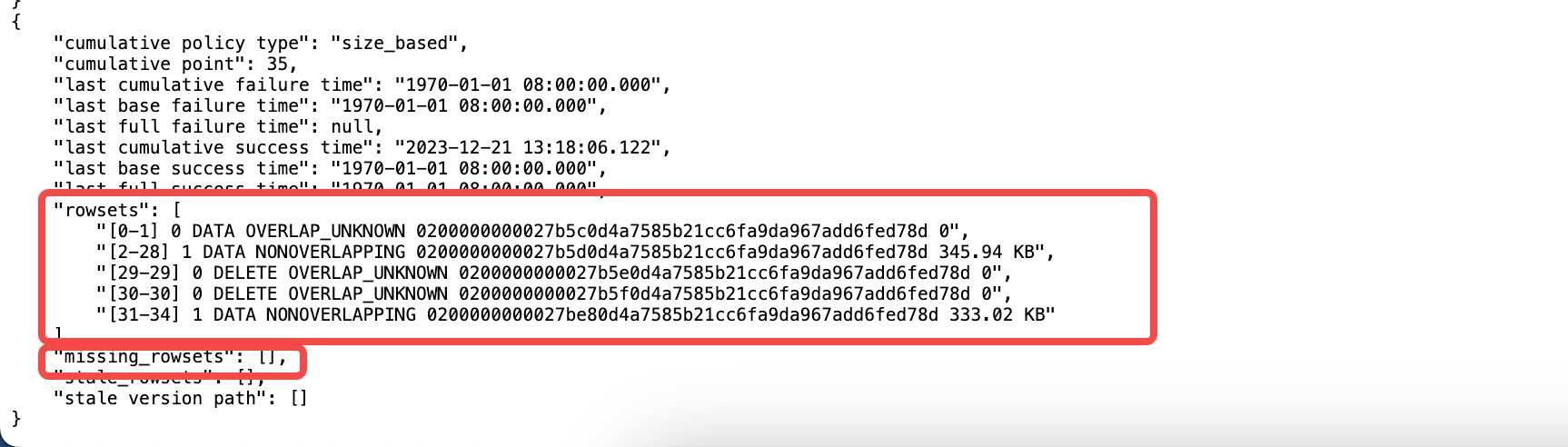
查看该副本的rowset 和 missing_rowset,重点看rowset 的最大版本(这里是34)和 missing_rowsets。从上图可以看出该副本的rowset 为 0 ~ 34, 且中间不缺version(missing_rowsets为空)。而查询语句中是 special version 是 0, 35, 但该BE不含version 35。所以需要给该BE补上version 35。
注意:这里的special version实际就是partition的visible version。 它也可以通过如下指令查看。
show partitions from <table-name xxx> where PartitionName = '<partition name xxx>' 三、问题处理
- 确认是否自动修复
由于doris内部会自动做数据均衡和修复,所以当出现数据副本异常时,先确认异常数据副本能否自动修复:

如果是多副本,查看是否存在健康副本。健康副本是指副本version >= special version && last failed version = -1 && isBad = false, 且curl 它的 compact status, missing rowsets 为空。
如果存在这样的副本,把查询报错的副本set bad,如上图所示BackendId为10003上版本远落后于其他两个副本的version,可以通过设置为bad来自动修复。
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "7552021", "backend_id" = "10003", "status" = "bad");等待一会(可能需要一两分钟),再执行步骤2中的detail cmd,如果副本都健康了:
version >= special version && last failed version = -1 && isBad = false且curl它的compact status, missing rowsets为空,说明修补OK了。且执行select count (*) from table_xx 是否OK。
如果没问题,就自动修复完成了,不用往下看。如果还是有问题,接着往下看。
- 重新导数手动修复
- 如果是多个副本都损坏,并且是分区表的情况下,可以删除这个分区,然后手动重建这个分区,重新导入数据即可。
- 如果是多个副本都损坏,并且是非分区表的情况下,只能删除这个表重新导入数据。
- 填充空副本进行修复
注意:
以上两个方法可以恢复丢失的数据,而填充空副本方法,是插入若干个空rowset,它能恢复读写。但如果丢失的rowset是包含数据的,这种方法实质是丢数据的。
空副本修复方式如下:
curl -X POST "http://10.151.2.29:8040/api/pad_rowset?tablet_id=606202&start_version=35&end_version=35"- tablet_id table 的 id
- start_version 起始版本
- end_version 终止版本
该功能用于使用一个空的 rowset 填充损坏的副本。这个例子中修补的url中 start_version = 35, end_version = 35。
这个例子只是缺一个rowset, 实际中可能缺多个(missing rowset,最大version + 1 ~ special version),缺多少个rowset,就调用多少次修补的方法。
修补完之后,再执行下show tablet xxx,该副本last fail version 是否等于 -1,如果它的version都补上了,但是last fail version = version + 1, 还需要手工执行把last fail version 改成 -1:
ADMIN SET REPLICA VERSION PROPERTIES("tablet_id" = "10003", "backend_id" = "10001", "last_failed_version" = "-1");低版本的doris可能不含这个SQL, 如果不支持这个SQL且是单副本的,通常需要重新建表进行导数。
如果没问题,使用
select count(*) from table_xx;查看是否可读,可读则说明数据副本问题已处理。