自从ChatGPT等大型语言模型(Large Language Model, LLM)出现以来,其类通用人工智能(AGI)能力引发了自然语言处理(NLP)领域的新一轮研究和应用浪潮。尤其是ChatGLM、LLaMA等普通开发者都能运行的较小规模LLM开源之后,业界涌现了大量基于LLM的二次微调和应用案例。
传神社区(Opencsg)旨在收集和整理与中文NLP相关的开源数据集。如果本篇文章对您有帮助,欢迎点赞与收藏~
我们也欢迎大家贡献本文未收录的开源数据集,提供对应的资源,描述与链接,感谢您的支持!
目录
- 法律问答
-
-
1.1 哈佛法学院案例语料库
-
1.2 中文司法阅读理解数据集
-
1.3 隐私政策问答数据集
-
-
- 法律文本摘要
3.1 PILE法律数据集
3.2 Fairlex评估数据集
3.3 LexGLUE评估检索数据集
- 其他
4.1 面向非结构化法律文本的spaCy pipeline和NLP模型
4.2 罪名法务名词及分类模型
*-
2.1 英国最高法院的案例文件及其摘要数据集
-
2.2 印度最高法院的案例文件及其摘要数据集
-
2.3 域指导隐私政策摘要数据集
-
2.4 美国立法自动总结语料库
-
2.5 合同英语摘要数据集
-
2.6 美国法律案例摘要数据集
-
2.7 法律案件报告数据集
-
- 法律基准数据集
01 法律问答
1 .1 哈佛法学院案例语料库
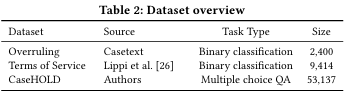
CaseHOLD:
简介:预训练语料库是通过摄取从1965年至今的整个哈佛法学院案例语料库构建的。这个语料库(37GB)的大小很大,代表了所有联邦和州法院的3,446,187个法律判决,并且比最初用于训练BERT的BookCorpus/Wikipedia语料库(15GB)的大小还要大。我们从这个语料库中随机抽取 10% 的决策作为保留集,我们用它来创建 CaseHOLD 数据集。剩下的 90% 用于预训练。
地址:https://opencsg.com/datasets/MagicAI/CaseHOLD
1.2 中文司法阅读理解数据集
CJRC:
简介:中文司法阅读理解(CJRC)数据集,其中包含约10,000份文件和近50,000个带答案的问题。这些文件来自判决书,问题则由法律专家进行标注。CJRC数据集可帮助研究人员通过阅读理解技术提取要素。要素提取是法律领域的一项重要任务。
地址:https://opencsg.com/datasets/MagicAI/CJRC

1 .3 隐私政策问答数据集
PrivacyQA:
简介:PrivacyQA 是一个语料库,由 1750 个关于隐私政策内容的问题组成,并配有专家注释。这项工作的目标是启动该领域问答方法的开发,以解决(不切实际的)期望,即大量人口每天应该阅读许多政策。
地址:https://opencsg.com/datasets/MagicAI/PrivacyQA
02 法律文本摘要
2 .1 英国最高法院的案例文件及其摘要数据集
UK-Abs :
简介:这个数据集是从英国最高法院的网站爬取的,包含了793份完整的案件文档及其对应的摘要。这些数据被分为训练集和测试集,其中693对(文档,摘要)被随机抽样作为训练数据集,剩余的100对作为测试集。
地址:https://opencsg.com/datasets/MagicAI/UK-Abs
2 .2 印度 最高法院的案例文件及其摘要数据集
IN-Abs:
简介:这个数据集是从印度法律信息网站爬取的,包含了7,130份完整的案件文档及其对应的摘要。这些数据被分为训练集和测试集,其中7,030对(文档,摘要)被随机抽样作为训练数据集,剩余的100对作为测试集。
地址:https://opencsg.com/datasets/MagicAI/IN-Abs
2 .3 域指导隐私政策摘要数据集
Domain-Guided-Summarization-of-Privacy-Policies:
简介:本数据集提取自151家公司的隐私政策、服务条款和Cookie政策文本。要点和简明英语摘要摘自 tosdr.org。
地址:https://opencsg.com/datasets/MagicAI/Domain-Guided-Summarization-of-Privacy-Policies
2 .4 美国立法自动总结语料库
BillSum:
简介:BillSum 数据集是第一个用于自动汇总美国立法的语料库。该语料库包含来自美国国会和加利福尼亚州立法机关的法案文本和人工撰写的摘要。它作为论文发表在EMNLP 2019 New Frontiers in Summarization研讨会上。
地址:https://opencsg.com/datasets/MagicAI/BillSum

2 .5 合同英语摘要数据集
legal_summarization :
简介:这个数据集专注于单边法律合同,如服务条款,这类合同在现代数字生活中扮演着重要角色。然而,很少有人在接受这些条款之前会阅读这些文档,因为它们通常篇幅冗长且语言复杂。为了解决这一问题,我们提出了将这些法律文档以简洁的英语进行摘要的任务,这样可以帮助用户更好地理解他们正在接受的条款。
地址:https://opencsg.com/datasets/MagicAI/legal_summarization

2.6 美国法律案例摘要数据集
BVA Cases:
简介:来自美国退伍军人上诉委员会的 92 对(案例、摘要)
地址:https://www.opencsg.com/datasets/MagicAI/BVA_Cases
2.7 法律案件报告数据集
LCR:
简介:包含4000个法律案例的文本语料库,用于自动摘要和引文分析。对于每份文档,我们收集标语、引文句子、引文标语和引文类别。
地址:https://www.opencsg.com/datasets/MagicAI/LCR

03 法律基准数据集
3 .1 PILE法律数据集
Pile of Law:
简介:我们收集了大量的法律的和行政数据。这些数据的用途有两方面:(1)汇总体现不同数据过滤规范和法律的标准的法律的和行政数据源;(2)收集一个数据集,可用于未来的法律领域语言模型预训练,这是诉诸司法举措的一个关键方向。因此,对数据源进行策划以告知:(1)法律的分析、知识或理解;(2)论点形成;(3)隐私过滤标准。像法典和法律这样的来源倾向于提供信息(1)。成绩单和法庭文件往往提供信息(2)。意见倾向于告知(1)和(3)。
地址:https://www.opencsg.com/datasets/MagicAI/pile_of_Law
3.2 Fairlex评估数据集
Fairlex:
简介:我们提出了一个由四个数据集组成的基准套件,用于评估预先训练的法律语言模型的公平性,以及用于为下游任务微调它们的技术。我们的基准涵盖四个司法管辖区(欧洲理事会、美国、瑞士和中国)、五种语言(英语、德语、法语、意大利语和中文)以及五个属性(性别、年龄、国籍/地区、语言和法律领域)的公平性。在我们的实验中,我们使用几种组鲁棒微调技术评估了预训练的语言模型,并表明在许多情况下,性能组差异是活跃的,而这些技术都不能保证公平性,也不能始终如一地减轻组差异。此外,我们还对结果进行了定量和定性分析,强调了在法律NLP中开发鲁棒性方法的开放挑战。了两个数据集。
地址:https://www.opencsg.com/datasets/MagicAI/Fairlex

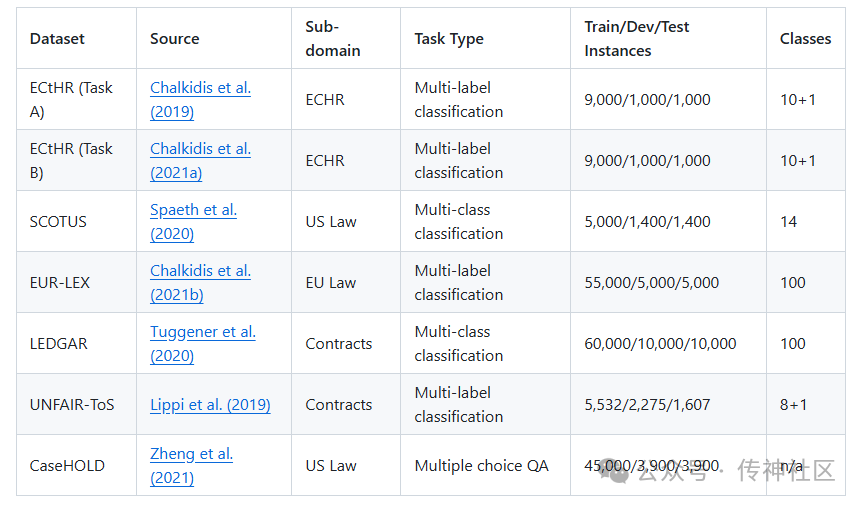
3 .3 LexGLUE评估 检索数据集
LexGLUE:
简介:与 GLUE 和 SuperGLUE ( Wang et al., 2109) 一样,我们的目标之一是推动能够处理多个 NLP 任务的通用(或基础)模型,在我们的例子中是合法的 NLP 任务,可能具有有限的特定任务微调。另一个目标是为希望探索或开发法律NLP方法的NLP研究人员和从业者提供一个方便且信息丰富的切入点。考虑到这些目标,我们在 LexGLUE 中包含的数据集及其处理的任务已通过多种方式进行了简化,如下所述,以使新手和通用模型更容易解决所有任务。
地址:https://www.opencsg.com/datasets/MagicAI/LexGLUE
04 其他
4.1 面向非结构化法律文本的spaCy pipeline和NLP模型
Blackstone:
简介:Blackstone 是一个 spaCy 模型和库,用于处理长格式、非结构化的法律文本。Blackstone 是英格兰和威尔士法律报告委员会研究实验室 ICLR&D 的一个实验性研究项目。
地址:https://opencsg.com/datasets/MagicAI/Blackstone
4.2 罪名法务名词及分类模型
CrimeKgAssitant:
简介:,罪名法务智能项目,内容包括856项罪名知识图谱, 基于280万罪名训练库的罪名预测,基于20W法务问答对的13类问题分类与法律资讯问答功能.
地址:https://opencsg.com/datasets/MagicAI/CrimeKgAssitant
