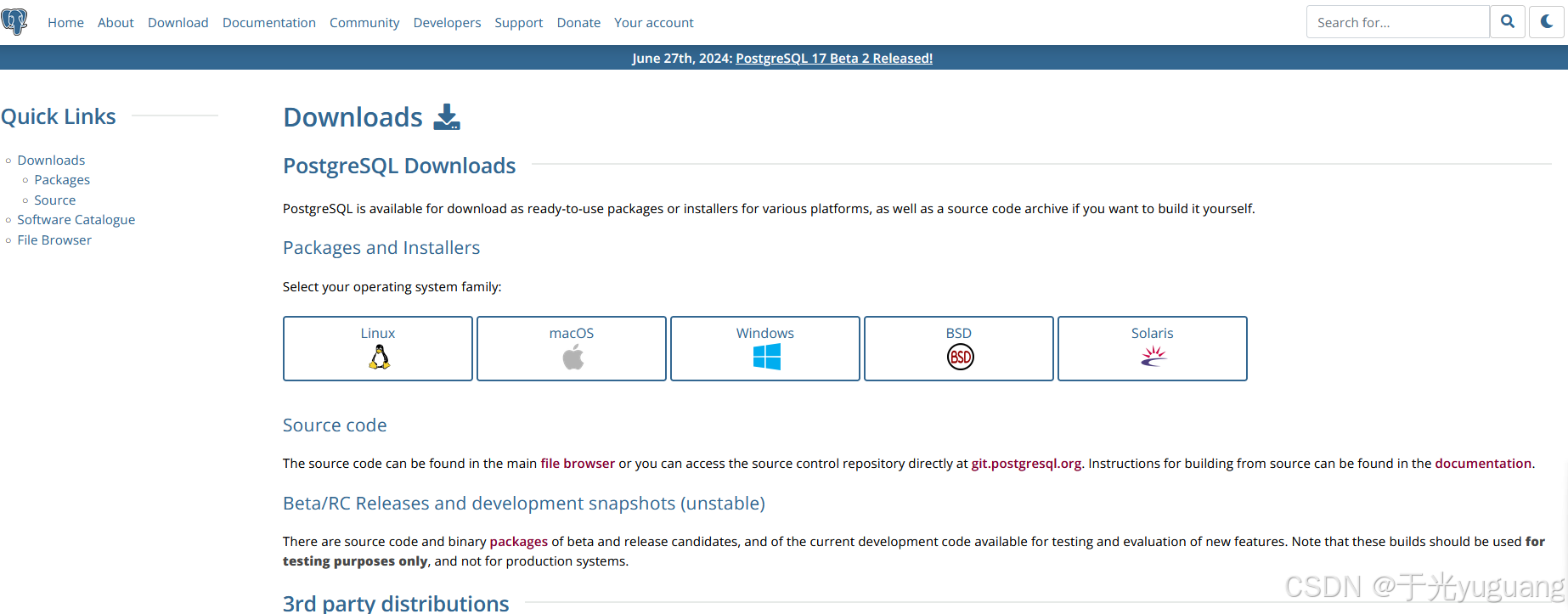
1、官网下载
- 起源与发展:PostgreSQL最初起源于加州大学伯克利分校的Postgres项目,该项目始于1986年,并一直演进到1994年。在1995年,Postgres项目增加了SQL翻译程序,并更名为Postgres95。随后,在1996年,Postgres95经过较大改动后,以PostgreSQL 6.0版发布。
- 功能与特性:PostgreSQL支持大部分的SQL标准,并提供了许多其他现代数据库特性,如复杂查询、外键、触发器、视图、事务完整性、多版本并发控制等。
- 开源性:PostgreSQL是开源的,这意味着任何人都可以免费使用、修改和分发它。这为其赢得了广泛的用户群体和活跃的社区支持。
- 功能强大:PostgreSQL支持多种数据类型,包括整型、浮点型、日期型、文本型、数组等,并支持复杂的查询、事务处理和触发器等功能。这使得PostgreSQL适用于各种复杂的应用场景。
- 可扩展性:PostgreSQL支持插件和扩展,用户可以通过自定义插件来增加额外的功能,以满足不同的需求。例如,PostGIS就是PostgreSQL的一个扩展,用于支持空间数据的存储和处理。
- 安全性:PostgreSQL提供了多种安全功能,包括用户认证、权限控制、SSL加密等,以保护数据的安全性。
- 兼容性好:PostgreSQL不仅支持ANSI SQL标准,还兼容许多其他数据库系统的语法和特性,这使得用户能够轻松地将其他数据库系统的应用迁移到PostgreSQL上。
- 可定制性强:PostgreSQL提供了丰富的参数和选项,用户可以根据需求进行调整和优化,以提高系统的性能和稳定性。
地址:
PostgreSQL: The world's most advanced open source database

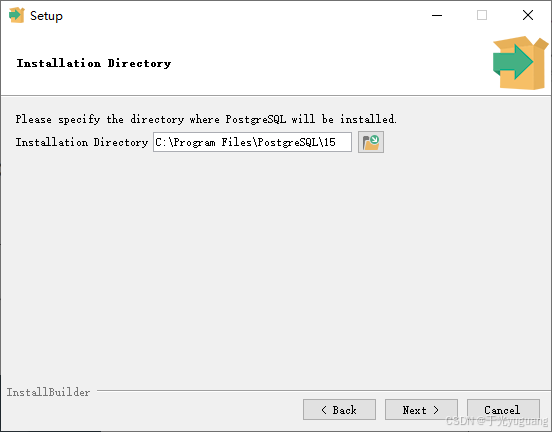
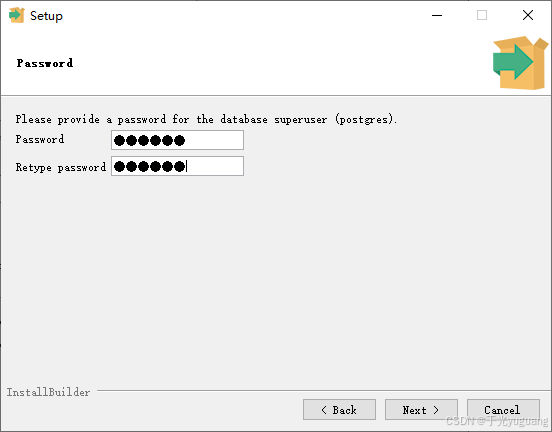
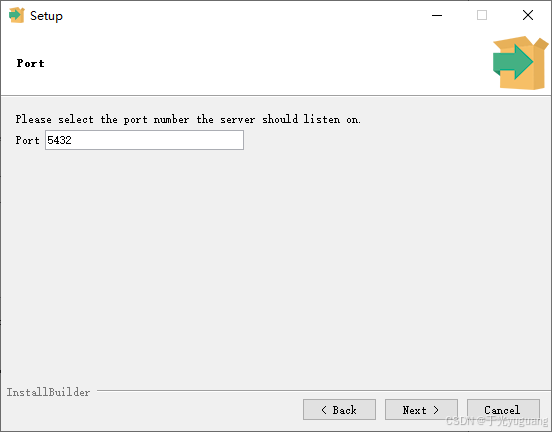
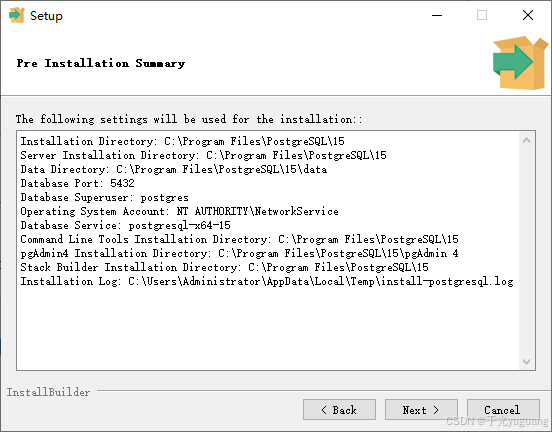
2、windows安装

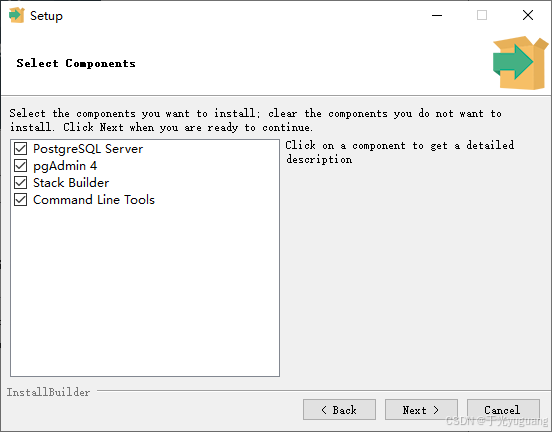
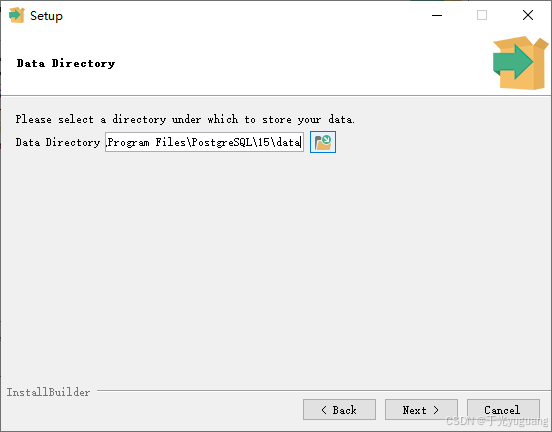

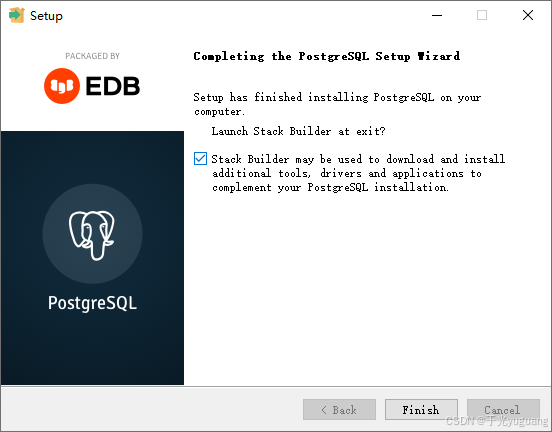
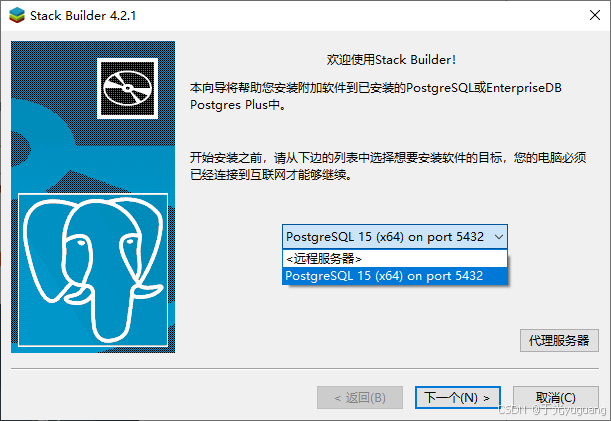
3、连接验证
命令行链接
-
C:\Program Files\PostgreSQL\15\bin>:这是命令行的当前工作目录,它指向了 PostgreSQL 15 版本安装目录下的 bin 子目录。这个目录包含了 PostgreSQL 的可执行文件,包括psql(PostgreSQL 的命令行界面工具)。然而,实际上你不需要在这个目录下执行psql命令,因为psql应该已经被添加到了系统的 PATH 环境变量中,这样你就可以从任何目录通过命令行调用它。不过,即使你不在这个目录下,命令本身也是有效的。 -
psql:这是 PostgreSQL 提供的命令行工具,用于与 PostgreSQL 数据库服务器进行交互。你可以使用它来执行 SQL 命令、查询数据库、管理数据库对象等。 -
-h localhost:这个选项指定了数据库服务器的主机名。在这个例子中,localhost表示数据库服务器运行在本机上。你也可以使用 IP 地址(如127.0.0.1)来代替localhost。 -
-p 5432:这个选项指定了数据库服务器监听的端口号。PostgreSQL 的默认端口号是 5432,所以这个选项是可选的(除非你的 PostgreSQL 实例被配置为监听不同的端口)。 -
-U postgres:这个选项指定了用于连接数据库的用户名。在这个例子中,用户名是postgres,它是 PostgreSQL 安装时创建的一个默认超级用户。 -
-W:这个选项告诉psql在连接数据库时提示用户输入密码。如果省略此选项,并且用户的密码被配置为在.pgpass文件中或环境变量中可用,则psql将不会提示输入密码。但是,出于安全考虑,通常建议显式使用-W选项。psql -U postgres -d postgres
C:\Program Files\PostgreSQL\15\bin>psql -h localhost -p 5432 -Upostgres -W
口令:
psql (15.7)
输入 "help" 来获取帮助信息.postgres=# \l
数据库列表
名称 | 拥有者 | 字元编码 | 校对规则 | Ctype | ICU Locale | Locale Provider | 存取权限
-----------+----------+----------+--------------------------------+--------------------------------+------------+-----------------+-----------------------
postgres | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 | | libc |
template0 | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
(3 行记录)postgres=# \dt
没有找到任何关系.
postgres=# \c
口令:
您现在已经连接到数据库 "postgres",用户 "postgres".
postgres=#postgres=# ?
一般性
\copyright 显示PostgreSQL的使用和发行许可条款
\crosstabview [COLUMNS] execute query and display result in crosstab
\errverbose 以最冗长的形式显示最近的错误消息
\g [(OPTIONS)] [FILE] execute query (and send result to file or |pipe);
\g with no arguments is equivalent to a semicolon
\gdesc 描述查询结果,而不执行它
\gexec 执行策略,然后执行其结果中的每个值
\gset [PREFIX] execute query and store result in psql variables
\gx [(OPTIONS)] [FILE] 就像\g,但强制扩展输出模式
\q 退出 psql
\watch [SEC] 每隔SEC秒执行一次查询帮助
? [commands] 显示反斜线命令的帮助
? options 显示 psql 命令行选项的帮助
? variables 显示特殊变量的帮助
\h [NAME] SQL命令语法上的说明,用*显示全部命令的语法说明查询缓存区
\e [FILE] [LINE] 使用外部编辑器编辑查询缓存区(或文件)
\ef [FUNCNAME [LINE]] 使用外部编辑器编辑函数定义
\ev [VIEWNAME [LINE]] 用外部编辑器编辑视图定义
\p 显示查询缓存区的内容
\r 重置(清除)查询缓存区
\w 文件 将查询缓存区的内容写入文件输入/输出
\copy ... 执行 SQL COPY,将数据流发送到客户端主机
\echo [-n] [STRING] 将字符串写到标准输出(-n表示没有换行符)
\i 文件 从文件中执行命令
\ir FILE 与 \i类似, 但是相对于当前脚本的位置
\o [文件] 将全部查询结果写入文件或 |管道
\qecho [-n] [STRING] 将字符串写入\o输出流(-n表示无换行)
\warn [-n] [STRING] 将字符串写入标准错误(-n 表示无换行)条件
\if EXPR 开始条件块
\elif EXPR 当前条件块内的备选方案
\else 当前条件块内的最终备选方案
\endif 条件块的结尾资讯性
(选项: S = 显示系统对象, + = 其余的详细信息)
\d[S+] 列出表,视图和序列
\d[S+] 名称 描述表,视图,序列,或索引
\da[S] [模式] 列出聚合函数
\dA[+] [模式] 列出访问方法
\dAc[+] [AMPTRN [TYPEPTRN]] 列出运算符
\dAf[+] [AMPTRN [TYPEPTRN]] 列出运算符集合
\dAo[+] [AMPTRN [OPFPTRN]] 列出运算符集合
\dAp[+] [AMPTRN [OPFPTRN]] 列出运算符集合所支持的功能
\db[+] [模式] 列出表空间
\dc[S+] [模式] 列表转换
\dconfig[+] [PATTERN] list configuration parameters
\dC[+] [模式] 列出类型强制转换
\dd[S] [模式] 显示没有在别处显示的对象描述
\dD[S+] [模式] 列出共同值域
\ddp [模式] 列出默认权限
\dE[S+] [模式] 列出引用表
\des[+] [模式] 列出外部服务器
\det[+] [模式] 列出引用表
\deu[+] [模式] 列出用户映射
\dew[+] [模式] 列出外部数据封装器
\df[anptw][S+] [FUNCPTRN [TYPEPTRN ...]]
列出 [only agg/normal/procedure/trigger/window] 函数
\dF[+] [模式] 列出文本搜索配置
\dFd[+] [模式] 列出文本搜索字典
\dFp[+] [模式] 列出文本搜索解析器
\dFt[+] [模式] 列出文本搜索模版
\dg[S+] [模式] 列出角色
\di[S+] [模式] 列出索引
\dl[+] list large objects, same as \lo_list
\dL[S+] [模式] 列出所有过程语言
\dm[S+] [模式] 列出所有物化视图
\dn[S+] [模式] 列出所有模式
\do[S+] [OPPTRN [TYPEPTRN [TYPEPTRN]]]
列出运算符
\dO[S+] [模式] 列出所有校对规则
\dp [模式] 列出表,视图和序列的访问权限
\dP[itn+] [PATTERN] 列出[仅表/索引]分区关系[n=nested]
\drds [ROLEPTRN [DBPTRN]] list per-database role settings
\dRp[+] [模式] 列出复制发布
\dRs[+] [模式] 列出复制订阅
\ds[S+] [模式] 列出序列
\dt[S+] [模式] 列出表
\dT[S+] [模式] 列出数据类型
\du[S+] [模式] 列出角色
\dv[S+] [模式] 列出视图
\dx[+] [模式] 列出扩展
\dX [PATTERN] 列出扩展统计信息
\dy[+] [PATTERN] 列出所有事件触发器
\l[+] [模式] 列出所有数据库
\sf[+] FUNCNAME 显示一个函数的定义
\sv[+] VIEWNAME 显示一个视图的定义
\z [模式] 和\dp的功能相同大对象
\lo_export LOBOID FILE write large object to file
\lo_import FILE [COMMENT]
read large object from file
\lo_list[+] list large objects
\lo_unlink LOBOID delete a large object格式化
\a 在非对齐模式和对齐模式之间切换
\C [字符串] 设置表的标题,或如果没有的标题就取消
\f [字符串] 显示或设定非对齐模式查询输出的字段分隔符
\H 切换HTML输出模式 (目前是 关闭)
\pset [NAME [VALUE]] 设置表输出选项
(border|columns|csv_fieldsep|expanded|fieldsep|
fieldsep_zero|footer|format|linestyle|null|
numericlocale|pager|pager_min_lines|recordsep|
recordsep_zero|tableattr|title|tuples_only|
unicode_border_linestyle|unicode_column_linestyle|
unicode_header_linestyle
\t [开|关] 只显示记录 (目前是关闭)
\T [字符串] 设置HTML <表格>标签属性, 或者如果没有的话取消设置
\x [on|off|auto] 切换扩展输出模式(目前是 关闭)连接
\c[onnect] {[DBNAME|- USER|- HOST|- PORT|-] | conninfo}
连接到新数据库(当前是"postgres")
\conninfo 显示当前连接的相关信息
\encoding [编码名称] 显示或设定客户端编码
\password [USERNAME] 安全地为用户更改口令操作系统
\cd [目录] 更改目前的工作目录
\getenv PSQLVAR ENVVAR fetch environment variable
\setenv NAME [VALUE] 设置或清空环境变量
\timing [开|关] 切换命令计时开关 (目前是关闭)
! [命令] 在 shell中执行命令或启动一个交互式shell变量
\prompt [文本] 名称 提示用户设定内部变量
\set [名称 [值数]] 设定内部变量,若无参数则列出全部变量
\unset 名称 清空(删除)内部变量
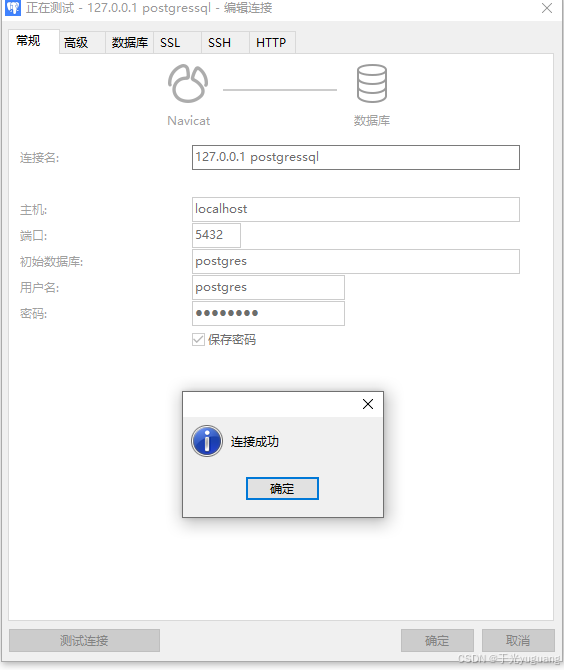
navicat连接
dbeaver连接
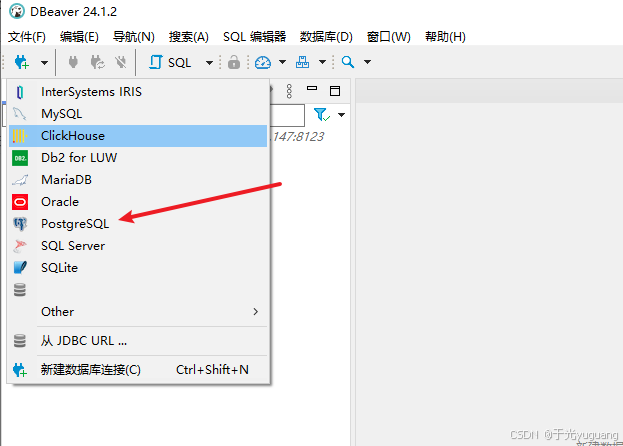
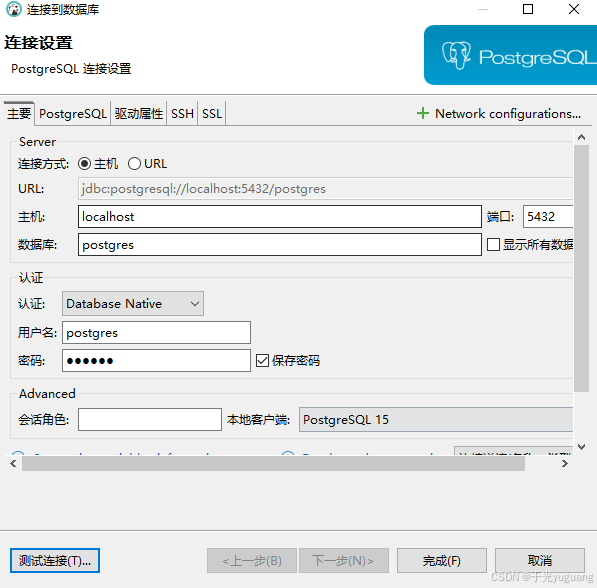
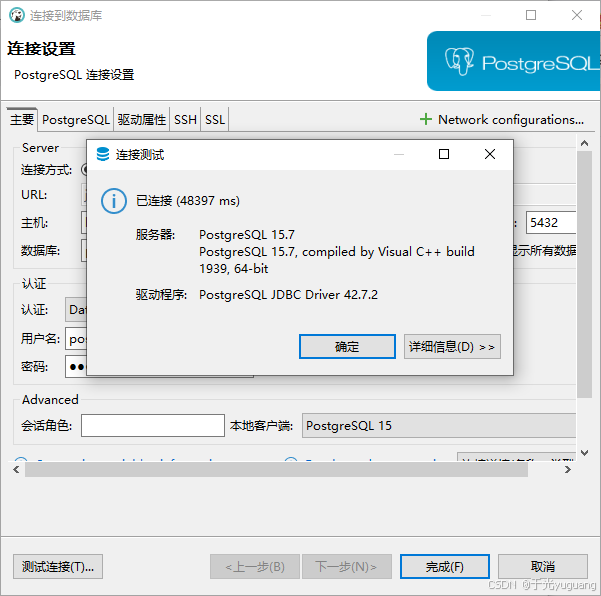
创建库、表
要使用 PostgreSQL 的 psql 工具创建一个数据库并在其中创建一个表,您可以按照以下步骤进行操作:
1. **创建数据库**:
- 打开终端,并使用以下命令连接到 PostgreSQL 数据库:
```
psql -U postgres -d postgres
```
这将连接到 PostgreSQL 数据库的默认数据库 "postgres"。您需要将 "your_username" 替换为您的实际用户名。
- 创建一个新的数据库,例如名为 "mydatabase":
```
CREATE DATABASE mydatabase;
```
- 退出 psql 命令行界面:
```
\q
```
2. **连接到新创建的数据库**:
- 使用以下命令连接到新创建的数据库 "mydatabase":
```
psql -U postgres -d mydatabase
```
3. **创建表**:
- 在新的数据库中,您可以使用 SQL 命令创建表。以下是一个示例创建名为 "users" 的表的 SQL 命令:
```sql
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
age INT
);
```
- 运行上述 SQL 命令以创建名为 "users" 的表。
4. **插入数据**:
- 您可以使用 INSERT 语句向表中插入数据。以下是一个示例插入数据的 SQL 命令:
```sql
INSERT INTO users (name, age) VALUES ('Alice', 30);
INSERT INTO users (name, age) VALUES ('Bob', 25);
```
- 运行上述 SQL 命令以向 "users" 表中插入数据。
5. **查询数据**:
- 您可以使用 SELECT 语句从表中检索数据。例如,要检索所有用户的数据,可以运行以下 SQL 命令:
```sql
SELECT * FROM users;
```python读取
要使用 `psycopg2` 模块,您需要通过 pip 安装它。您可以在终端或命令提示符中运行以下命令来安装 `psycopg2`:
```bash
pip install psycopg2
```
如果您使用的是 Python 3.4 或更高版本,您还可以安装 `psycopg2-binary`,它是 `psycopg2` 的二进制包,安装更简便:
```bash
pip install psycopg2-binary
```
安装完成后,您就可以在 Python 中导入 `psycopg2` 模块并与 PostgreSQL 数据库进行交互了。如果您遇到任何问题或需要进一步帮助,请随时告诉我。
import psycopg2
# 连接到 PostgreSQL 数据库
conn = psycopg2.connect(
dbname="mydatabase",
user="postgres",
password="123456",
host="localhost",
port="5432"
)
# 创建一个游标对象,用于执行 SQL 命令
cur = conn.cursor()
# 创建表
# cur.execute("""
# CREATE TABLE IF NOT EXISTS users (
# id SERIAL PRIMARY KEY,
# name VARCHAR(50),
# age INT
# )
# """)
# 插入数据
# cur.execute("INSERT INTO users (name, age) VALUES (%s, %s)", ('Alice', 30))
# cur.execute("INSERT INTO users (name, age) VALUES (%s, %s)", ('Bob', 25))
# 提交更改
conn.commit()
# 查询数据
cur.execute("SELECT * FROM users")
rows = cur.fetchall()
# 打印查询结果
for row in rows:
print(row)
# 关闭游标和连接
cur.close()
conn.close()