Hadoop
Hadoop 是什么
- Hadoop 是由 Apache 基金会所开发,维护的分布式系统基础架构
- 主要解决海量数据的存储和海量数据的分析计算问题
- 广义上来说,Hadoop 通常是指一个更广泛的概念------Hadoop 生态圈,包括 MapReduce,HDFS,HBase,Yarn 等等
Hadoop 优势
- 高可靠:Hadoop 底层维护
多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。 - 高扩展:在集群间
分配任务数据,可方便的扩展数以千计的节点。 - 高效:在 MapReduce 的思想下,Hadoop 是
并行工作的,以加快任务处理速度。 - 高容错:能够自动将失败的任务
重新分配。
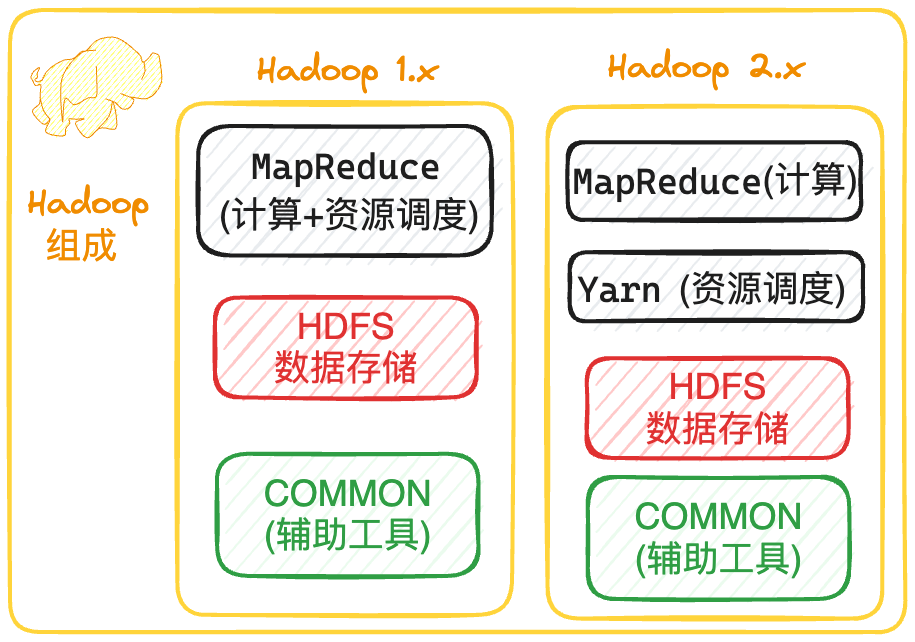
Hadoop 2.x 相比于 Hadoop 1.x 将 mapreduce 中的计算与调度分开了,降低了耦合度,而 Hadoop 3.x 和 Hadoop 2.x 架构没有什么区别就不画图了,下面我们来介绍一下 Hadoop 中的 HDFS,MapReduce,Yarn 等模块
YARN
YARN(Yet Another Resource Negotiator)是 Hadoop 生态系统的一个关键组件,用于集群资源管理和作业调度,是 Hadoop 的第二代资源管理器,取代了早期版本中的 MapReduce 作业调度器,为大规模数据处理提供了更灵活和高效的资源管理框架。
- ResourceManager(RM):整个集群资源(内存、CPU 等)的管理者
- NodeManager(NM):单个节点服务器资源的管理者。
- ApplicationMaster(AM):单个任务运行的管理者。
- Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
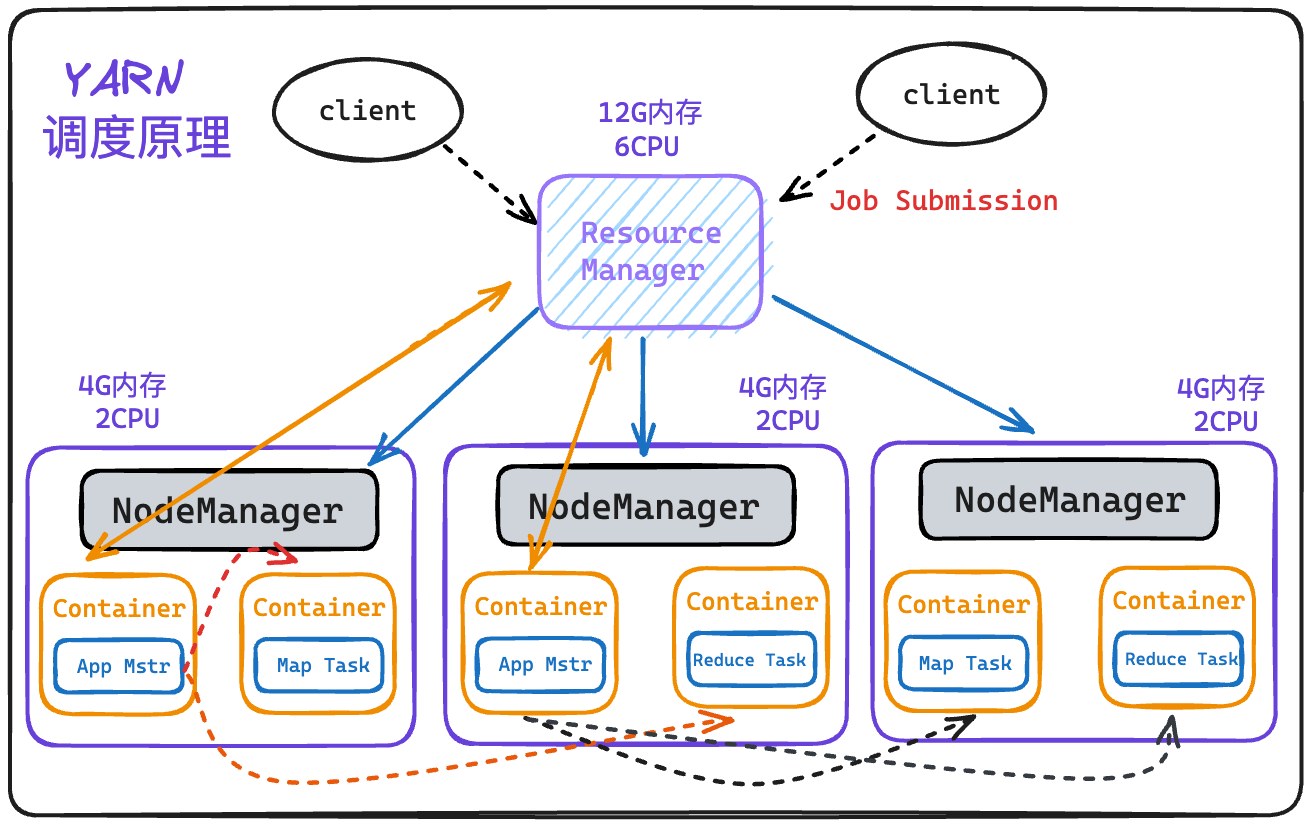
YARN 的主要特点包括:
- 多样化的工作负载支持:YARN 支持多种类型的应用程序,包括传统的 MapReduce 作业、流式处理、图计算、交互式查询等。它提供了一个通用的资源管理框架,可以灵活地为不同类型的应用程序分配资源。
- 高可伸缩性:YARN 可以在大规模集群上管理成千上万个节点和数以千计的应用程序。它能够有效地管理和调度集群中的资源,以满足不同应用程序的需求。
- 资源隔离:YARN 通过使用容器(Container)来实现资源隔离。每个应用程序都在自己的容器中运行,这样可以确保应用程序之间的资源不会相互干扰。
- 高可靠性:YARN 具有高可靠性和容错性。当节点或 ApplicationMaster 发生故障时,YARN 会自动重新分配资源和重新启动受影响的任务。
YARN 广泛应用于大数据处理和分析场景,成为 Hadoop 生态系统中的核心组件。它为用户提供了一个强大的资源管理和作业调度平台,使得各种类型的应用程序能够高效地在 Hadoop 集群上运行。
后续会出一篇关于 YARN 详细笔记,这里不过多赘述~
MapReduce
MapReduce 是一种用于处理大规模数据集的编程模型和计算框架。它是由 Google 提出并在 Hadoop 项目中得到广泛应用的。MapReduce 的设计目标是将并行计算任务分解为可独立执行的子任务,并自动处理任务的并行执行、故障恢复和数据分发等细节,以实现可靠且高效的大规模数据处理。
MapReduce 模型由两个主要的阶段组成:Map 阶段和 Reduce 阶段。
- Map 阶段:在 Map 阶段中,输入数据被划分为多个独立的数据块,并由多个并行运行的 Map 任务进行处理。每个 Map 任务接收一组输入数据,并将其转换为一系列键值对,即中间结果。Map 任务是独立执行的,它们可以在不同的计算节点上并行运行,以提高处理速度。
- Reduce 阶段:在 Reduce 阶段中,中间结果的键值对根据键进行分组,并由多个并行运行的 Reduce 任务进行处理。每个 Reduce 任务接收一个键及其对应的一组值,并对这些值进行聚合、合并或其他操作,生成最终的输出结果。
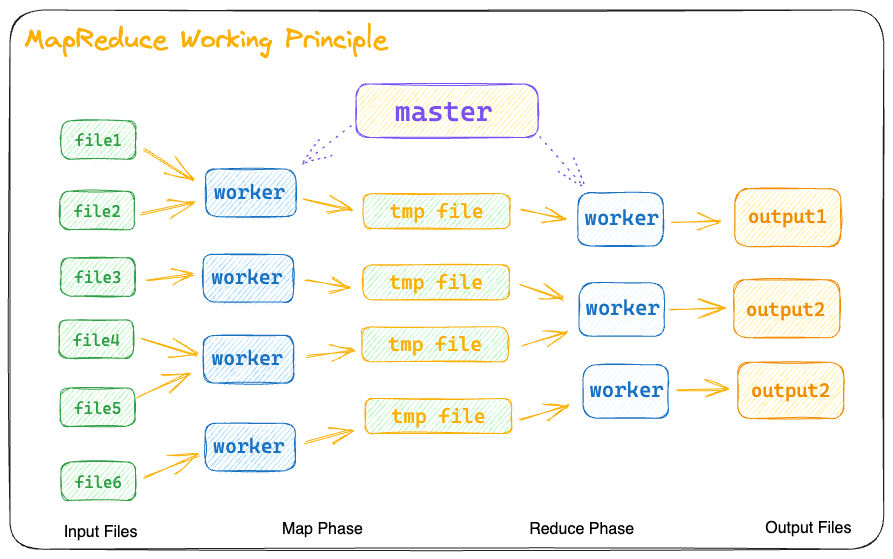
MapReduce 的主要特点包括:
- 可扩展性:MapReduce 可以在具有大量计算节点的集群上处理大规模数据集,通过并行执行任务来实现高吞吐量和可伸缩性。
- 容错性:MapReduce 具有容错性,当某个节点或任务失败时,它可以自动进行故障恢复,并重新分配任务以保证计算的正确性和完整性。
- 简化编程模型:MapReduce 提供了一种简化的编程模型,使得开发人员可以专注于业务逻辑而不必关心并行计算和分布式系统的细节。
- 适用于批处理:MapReduce 适用于批处理任务,它对于需要对整个数据集进行处理和分析的场景非常有效。
尽管 MapReduce 在大数据处理方面取得了巨大成功,但随着数据处理需求的多样化,其他更灵活和高级的计算模型和框架也得到了发展和应用,如 Spark、Flink 等。后续会出一篇关于 mapreduce 详细笔记,这里不过多赘述~
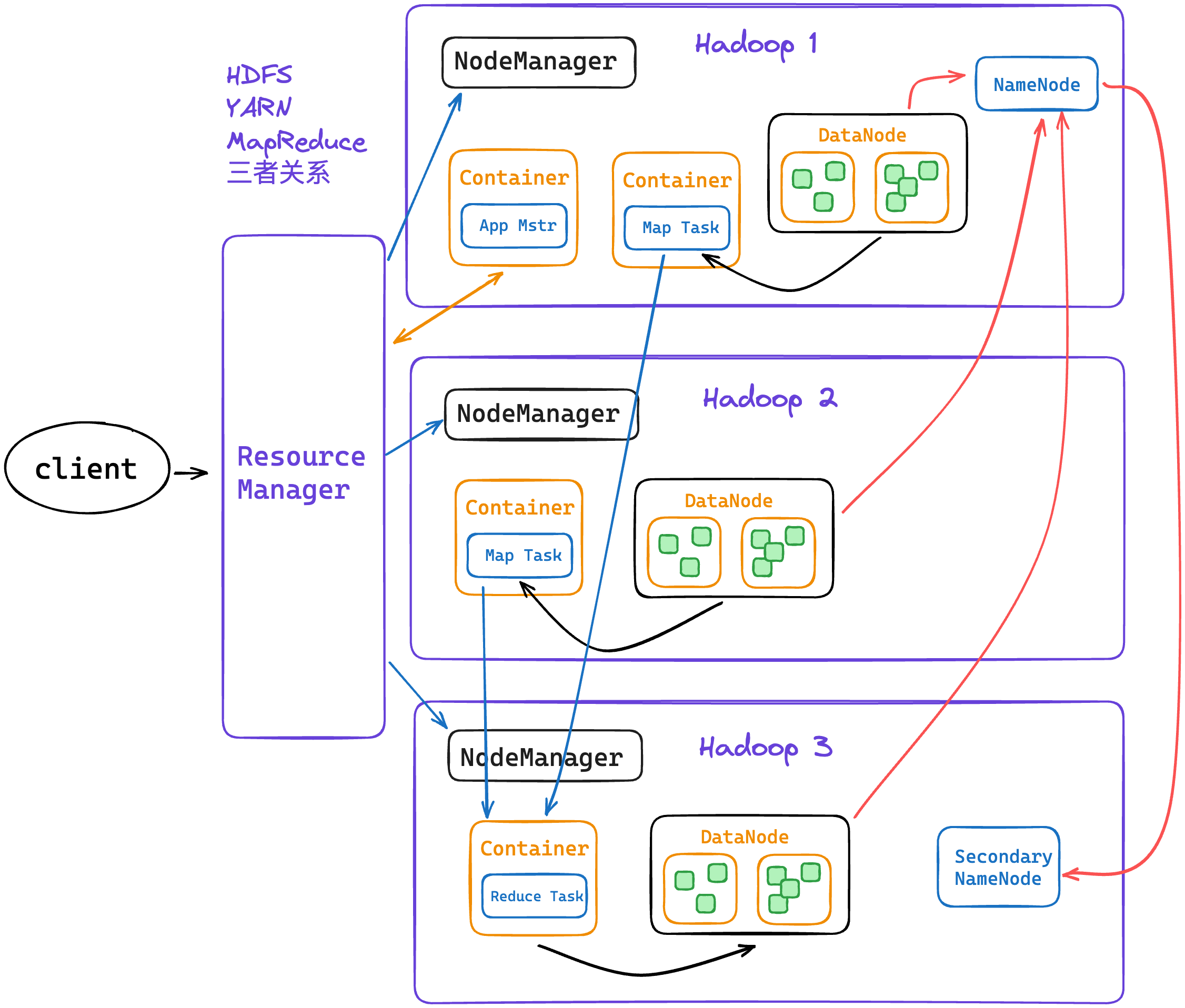
三者关系
HDFS 用于存储和管理数据,YARN 用于集群资源管理和作业调度,而 MapReduce 则是一种编程模型和计算框架,用于实现大规模数据处理。MapReduce 利用 YARN 来管理任务的执行和资源的分配,通过与 HDFS 进行交互来读取和写入数据。这三个组件相互协作,共同构建了 Hadoop 生态系统中的数据处理和存储基础设施。