详解是否要使用端到端的深度学习?
假设正在搭建一个机器学习系统,要决定是否使用端对端方法,来看看端到端深度学习的一些优缺点,这样就可以根据一些准则,判断的应用程序是否有希望使用端到端方法。

这里是应用端到端学习的一些好处,首先端到端学习真的只是让数据说话。所以如果有足够多的\((x,y)\)数据,那么不管从\(x\)到\(y\)最适合的函数映射是什么,如果训练一个足够大的神经网络,希望这个神经网络能自己搞清楚,而使用纯机器学习方法,直接从\(x\)到\(y\)输入去训练的神经网络,可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见。
例如,在语音识别领域,早期的识别系统有这个音位概念,就是基本的声音单元,如cat单词的"cat"的Cu-、Ah-和Tu-,觉得这个音位是人类语言学家生造出来的,实际上认为音位其实是语音学家的幻想,用音位描述语言也还算合理。但是不要强迫的学习算法以音位为单位思考,这点有时没那么明显。如果让的学习算法学习它想学习的任意表示方式,而不是强迫的学习算法使用音位作为表示方式,那么其整体表现可能会更好。
端到端深度学习的第二个好处就是这样,所需手工设计的组件更少,所以这也许能够简化的设计工作流程,不需要花太多时间去手工设计功能,手工设计这些中间表示方式。

那么缺点呢?这里有一些缺点,首先,它可能需要大量的数据。要直接学到这个\(x\)到\(y\)的映射,可能需要大量\((x,y)\)数据。在以前看过一个例子,其中可以收集大量子任务数据,比如人脸识别,可以收集很多数据用来分辨图像中的人脸,当找到一张脸后,也可以找得到很多人脸识别数据。但是对于整个端到端任务,可能只有更少的数据可用。所以\(x\)这是端到端学习的输入端,\(y\)是输出端,所以需要很多这样的\((x,y)\)数据,在输入端和输出端都有数据,这样可以训练这些系统。这就是为什么称之为端到端学习,因为直接学习出从系统的一端到系统的另一端。
另一个缺点是,它排除了可能有用的手工设计组件。机器学习研究人员一般都很鄙视手工设计的东西,但如果没有很多数据,的学习算法就没办法从很小的训练集数据中获得洞察力。所以手工设计组件在这种情况,可能是把人类知识直接注入算法的途径,这总不是一件坏事。觉得学习算法有两个主要的知识来源,一个是数据,另一个是手工设计的任何东西,可能是组件,功能,或者其他东西。所以当有大量数据时,手工设计的东西就不太重要了,但是当没有太多的数据时,构造一个精心设计的系统,实际上可以将人类对这个问题的很多认识直接注入到问题里,进入算法里应该挺有帮助的。
所以端到端深度学习的弊端之一是它把可能有用的人工设计的组件排除在外了,精心设计的人工组件可能非常有用,但它们也有可能真的伤害到的算法表现。例如,强制的算法以音位为单位思考,也许让算法自己找到更好的表示方法更好。所以这是一把双刃剑,可能有坏处,可能有好处,但往往好处更多,手工设计的组件往往在训练集更小的时候帮助更大。

如果在构建一个新的机器学习系统,而在尝试决定是否使用端到端深度学习,认为关键的问题是,有足够的数据能够直接学到从\(x\)映射到\(y\)足够复杂的函数吗?还没有正式定义过这个词"必要复杂度(complexity needed )"。但直觉上,如果想从\(x\)到\(y\)的数据学习出一个函数,就是看着这样的图像识别出图像中所有骨头的位置,那么也许这像是识别图中骨头这样相对简单的问题,也许系统不需要那么多数据来学会处理这个任务。或给出一张人物照片,也许在图中把人脸找出来不是什么难事,所以也许不需要太多数据去找到人脸,或者至少可以找到足够数据去解决这个问题。相对来说,把手的X射线照片直接映射到孩子的年龄,直接去找这种函数,直觉上似乎是更为复杂的问题。如果用纯端到端方法,需要很多数据去学习。
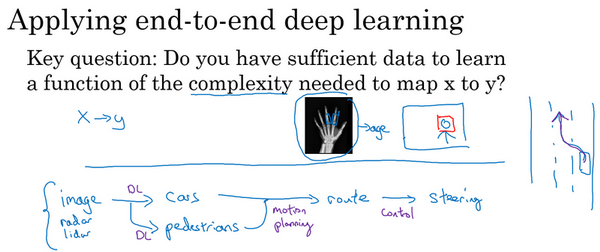
最后讲一个更复杂的例子,可能知道一直在花时间帮忙主攻无人驾驶技术的公司drive.ai,无人驾驶技术的发展其实让相当激动,怎么造出一辆自己能行驶的车呢?好,这里可以做一件事,这不是端到端的深度学习方法,可以把车前方的雷达、激光雷达或者其他传感器的读数看成是输入图像。但是为了说明起来简单,就说拍一张车前方或者周围的照片,然后驾驶要安全的话,必须能检测到附近的车,也需要检测到行人,需要检测其他的东西,当然,这里提供的是高度简化的例子。
弄清楚其他车和形如的位置之后,就需要计划自己的路线。所以换句话说,当看到其他车子在哪,行人在哪里,需要决定如何摆方向盘在接下来的几秒钟内引导车子的路径。如果决定了要走特定的路径,也许这是道路的俯视图,这是的车,也许决定了要走那条路线,这是一条路线,那么就需要摆动的方向盘到合适的角度,还要发出合适的加速和制动指令。所以从传感器或图像输入到检测行人和车辆,深度学习可以做得很好,但一旦知道其他车辆和行人的位置或者动向,选择一条车要走的路,这通常用的不是深度学习,而是用所谓的运动规划软件完成的。如果学过机器人课程,一定知道运动规划,然后决定了的车子要走的路径之后。还会有一些其他算法,说这是一个控制算法,可以产生精确的决策确定方向盘应该精确地转多少度,油门或刹车上应该用多少力。

所以这个例子就表明了,如果想使用机器学习或者深度学习来学习某些单独的组件,那么当应用监督学习时,应该仔细选择要学习的\(x\)到\(y\)映射类型,这取决于那些任务可以收集数据。相比之下,谈论纯端到端深度学习方法是很激动人心的,输入图像,直接得出方向盘转角,但是就目前能收集到的数据而言,还有今天能够用神经网络学习的数据类型而言,这实际上不是最有希望的方法,或者说这个方法并不是团队想出的最好用的方法。而认为这种纯粹的端到端深度学习方法,其实前景不如这样更复杂的多步方法。因为目前能收集到的数据,还有现在训练神经网络的能力是有局限的。
这就是端到端的深度学习,有时候效果拔群。但也要注意应该在什么时候使用端到端深度学习。