散列表
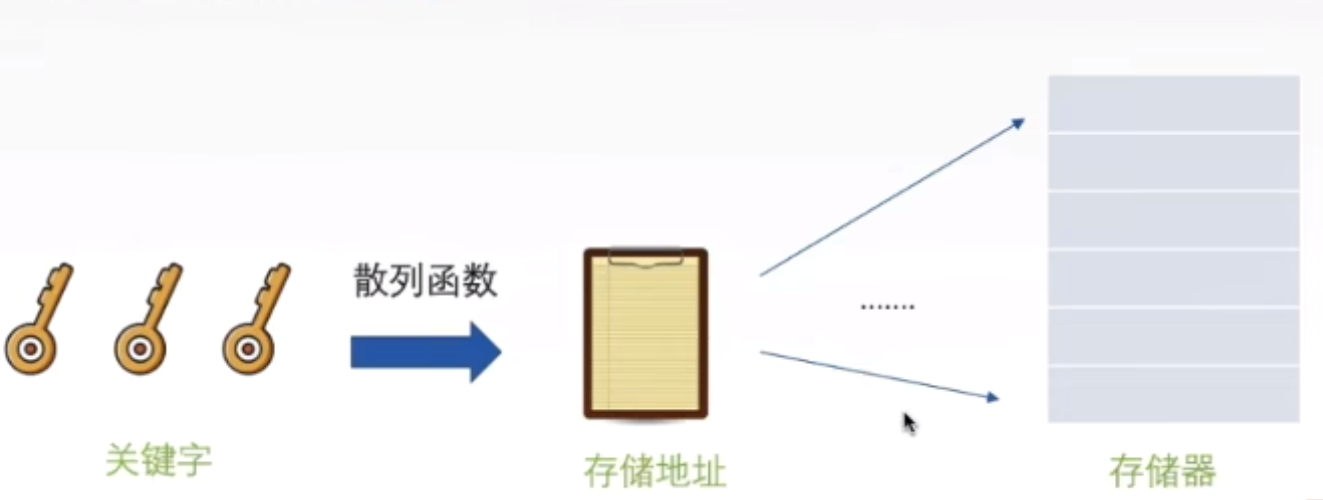
散列表(hash表):根据给定的关键字来计算出关键字在表中的地址的数据结构。也就是说,散列表建立了关键字和
存储地址之间的一种直接映射关系。
问题:如何建立映射管血
散列函数:一个把查找表中的关键字映射成该关键字对应的地址的函数,记为Hash(key)=Addr.
hash冲突
散列函数可能会把两个或两个以上的不同关键字映射到同一地址,称这种情况为"冲突 "
这些发生碰撞的不同关键字称为同义词。
构造散列函数的条件:
- 散列函数的定义域必须包含全部需要存储的关键字,而值域的范围则依赖于散列表的大小或地址范围。
- 散列函数计算出来的地址应该能等概率、均匀地分布在整个地址空间,从而减少冲突的发生。
- 散列函数应尽量简单,能够在较短的时间内就计算出任一关键字对应的散列地址。
1.常用的Hash函数的构造方法:
- 直接定址法:直接取关键字的某个线性函数值为散列地址,散列函数为H(key)=axkey+b。式中,a和b是
常数。这种方法计算最简单,并且不会产生冲突 - 除留余数法:假定散列表表长为m,取一个不大于m但最接近或等于m的质数p,利用以下公式把关键字
转换成散列地址。散列函数为H(kev)=key %p
除留余数法的关键是选好p,使得每一个关键字通过该函数转换后等概率地映射到散列空间上的任一地址
从而尽可能减少冲突的可能性 - 数字分析法
设关键字是r进制数(如十进制数),而r个数码在各位上出现的频率不一定相同,
可能在某些位上分布均匀些
每种数码出现的机会均等;而在某些位上分布不均匀,只有某几种数码经常出现,
则应选取数码分布较为均匀
的若干位作为散列地址。这种方法适合于已知的关键字集合

手机号后四位分布比较均与 如果key为手机号那么取手机号后四位为散列值
4.平方取中法
顾名思义,取关键字的平方值的中间几位作为散列地址。具体取多少位要看实际情况而定。这种方法得
到的散列地址与关键字的每一位都有关系,使得散列地址分布比较均匀。
Eg
12342=1522756 取中间三位227作为散列地址
23452=5499025 取中间三位990作为散列地址
5.折叠法
将关键字分割成位数相同的几部分 (最后一部分的位数可以短一些),然后取这几部分的叠加和作为
散列地址,这种方法称为折叠法。关键字位数很多,而且关键字中每一位上数字分布大致均匀时,可
以采用折香法得到散列地址。
Eg:关键字为1234567890散列表表长为3位可以将关键字分为四组每组3位
123456|7890然后这四组叠加求和123+456+789+0=1368 然后取后3位就能得到散列地址为368
2.常用的Hash函数的冲突处理办法
1.开放定址法
:将产生冲突的Hash地址作为自变量,通过某种冲突解决函数得到一个新的空闲的Hash地址。
1) 线性探测法: 冲突发生时,顺序查看表中下一个单元 (当探测到表尾地址m-1时,探测地址是表首地址0),直到找出一个空闲单元 (当表未填满时一定能找到一个空闲单元)或查遍全表。
如上图,11 、19、27经过运算后的映射下标都是3,由于3被最开始的11占用,那19就不得不后移占住后面空着的下表,这样就会产生连锁反应导致原来hash值是4的key也要后移,这样查找起来就非常麻烦
比如我找27,先计算得出27的hash值是3,但发下3下面存的11,只能往后找4 -- 19不是,继续遍历到5 -- 17 找到了
2)平方探测法:设发生冲突的地址为d,平方探测法得到的新的地址序列为d+12,d-12,d+22,d-22
平方探测法是一种较好的处理冲突的方法,可以避免出现"堆积"问题,它的缺点是不能探测到散列
表上的所有单元,但至少能探测到一半单元。

3)再散列法:又称为双散列法。需要使用两个散列函数,当通过第一个散列函数H(Key)得到的地址发
生冲突时,则利用第二个散列函数Hash2(Kev)计算该关键字的地址增量。

4)伪随机序列法:当发生地址冲突时,地址增量为伪随机数序列,称为伪随机序列法。
2.拉链法:
对于不同的关键字可能会通过散列函数映射到同一地址,为了避免非同义词
发生冲突,可以把所有的同义词存储在一个线性链表中,这个线性链表由其散列地址唯
标识。拉链法适用于经常进行插入和删除的情况
3.散列表的查找过程
类似于构造散列表,给定一个关键字Key。
先根据散列函数计算出其散列地址。然后检查散列地址位置有没有关键字.
1)如果没有,表明该关键字不存在,返回查找失败。
2)如果有,则检查该记录是否等于关键字。
- 如果等于关键字,返回查找成功。
- 如果不等于,则按照给定的冲突处理办法来计算下一个散列地址,再用该地址去执行上述过程。
4.散列表的查找性能
性能和装填因子有关
什么是装填因子?


Golang中map的hash值是如何计算如何存的?
在日常编程中,map的底层也是hash表,但map 的 key 键不仅仅是数字,还可能是字符串。由于我们之前讨论的哈希函数主要是针对数字进行计算的,因此,当 key 为字符串时,首先需要将字符串转化为整数,然后再经过哈希函数的运算产生哈希值。
在 Go 中,map 的哈希值会通过取模运算(或其他方式)转换成哈希表中的一个具体位置,这个位置称为映射地址。映射地址通常对应于一个桶,桶是一个存储多个键值对的容器。每个桶可以存储多个键值对,以处理哈希冲突。桶的数量通常与哈希表的容量有关。
溢出桶:如果主桶已满,则会创建一个溢出桶,将多余的键值对存储在溢出桶中。如果溢出桶也满了,就会继续创建新的溢出桶,形成一个链表结构。
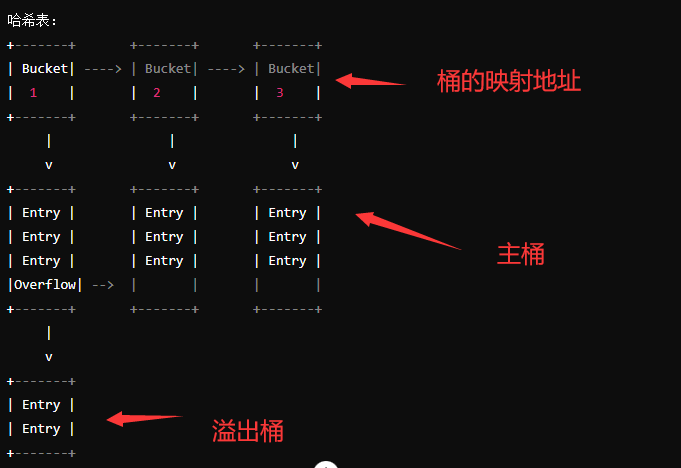
ps:个人认为桶和线性链表及其相似
go map的扩容机制
扩容的时机 :装载因⼦超过⼀定的阈值或者使⽤了太多的溢出桶时。
扩容的规则:
- 等量扩容 使⽤溢出桶太多的时候会进⾏等量扩容。申请和原来等量的内容,将原来的数据重新整理
后,写⼊到新的内存中。可以简单的认为是⼀次内存整理,⽬的是提⾼查询效率。
- 增量扩容 分成两步: 第⼀步进⼊扩容状态,先申请⼀块新的内存,翻倍增加桶的数量,此时
buckets指向新分配的桶,oldbuckets指向原来的桶。 第⼆步,重新计算⽼的桶中的哈希值在新
的桶内的位置(取模或者位操作),将旧数据⽤渐进式的⽅式拷⻉到新的桶中。
渐进式迁移分两块,⼀⽅⾯会从第⼀个桶开始,顺序迁移每⼀个桶,如果下⼀个桶已经迁移,则跳
过。另⼀⽅⾯,当我们操作某⼀个桶的元素时,会迁移两个桶,进⽽保证经过⼀些操作后⼀定能够完
成迁移。
访问迁移的map时会放生什么?
当我们访问⼀个正在迁移的Map时,如果存在oldbuckets,那么直接去中oldbuckets寻找数据。当
我们遍历⼀个正在迁移的Map时,新的和旧的就会遍历,如果⼀个旧的的桶已经迁移⾛了,那么就直
接跳过,反正不在旧的就在新的⾥。Map遍历本⾝就是⽆序的。
定能够完
成迁移。
访问迁移的map时会放生什么?
当我们访问⼀个正在迁移的Map时,如果存在oldbuckets,那么直接去中oldbuckets寻找数据。当
我们遍历⼀个正在迁移的Map时,新的和旧的就会遍历,如果⼀个旧的的桶已经迁移⾛了,那么就直
接跳过,反正不在旧的就在新的⾥。Map遍历本⾝就是⽆序的。