最近一个研究生网页的提问,然后就有了这篇博客!
大佬你好,我看到您的关于Serverless的文章于是十分冒昧的向您提问。我现在是一名在研究通过Serverless容器调度解决冷启动问题的本科生,导师放养,就让看论文但是后面的代码操作一点也不明白也不知道从哪里开始学起,我找了几本书和网课都是讲怎么在Serverless上部署应用程序的但是和我想研究的Serverless内部的容器调度都没有关系,现在十分迷茫不知道该从哪里学起,是该学习kubernetes吗还是什么,不知道怎么开始求大佬指点,谢谢大佬
引言
在Serverless架构中,冷启动问题和自动扩缩容是两个密切相关且至关重要的主题。本文将从Knative的自动扩缩容原理出发,逐步深入到实际案例,帮助你构建一个完整的研究思路。
1. Knative自动扩缩容原理
1.1 核心概念
Knative的自动扩缩容功能主要包括两个关键部分:
- 缩减至零(Scale-to-zero):当服务一段时间没有请求时,Pod数量会降到零,节省资源。
- 自动扩缩容(Autoscaling):根据incoming流量动态调整Pod数量。
1.2 核心组件
Knative的自动扩缩容由三个主要组件协作完成:
- Autoscaler:负责计算和决定需要的Pod数量。
- Activator:在没有运行中的Pod时接收请求,并触发扩容。
- Queue-Proxy:作为每个Pod的sidecar,收集指标并执行流量缓冲。
1.3 工作流程
- Autoscaler持续监控流量指标。
- 当流量增加时,Autoscaler计算需要的Pod数量并触发扩容。
- 当流量减少时,Autoscaler逐步减少Pod数量,最终可能缩减至零。
- 当服务缩减至零后,新的请求会被Activator接收,Activator随即触发扩容。
下面是一个0 instance 情况下,接到请求负载的流程图:
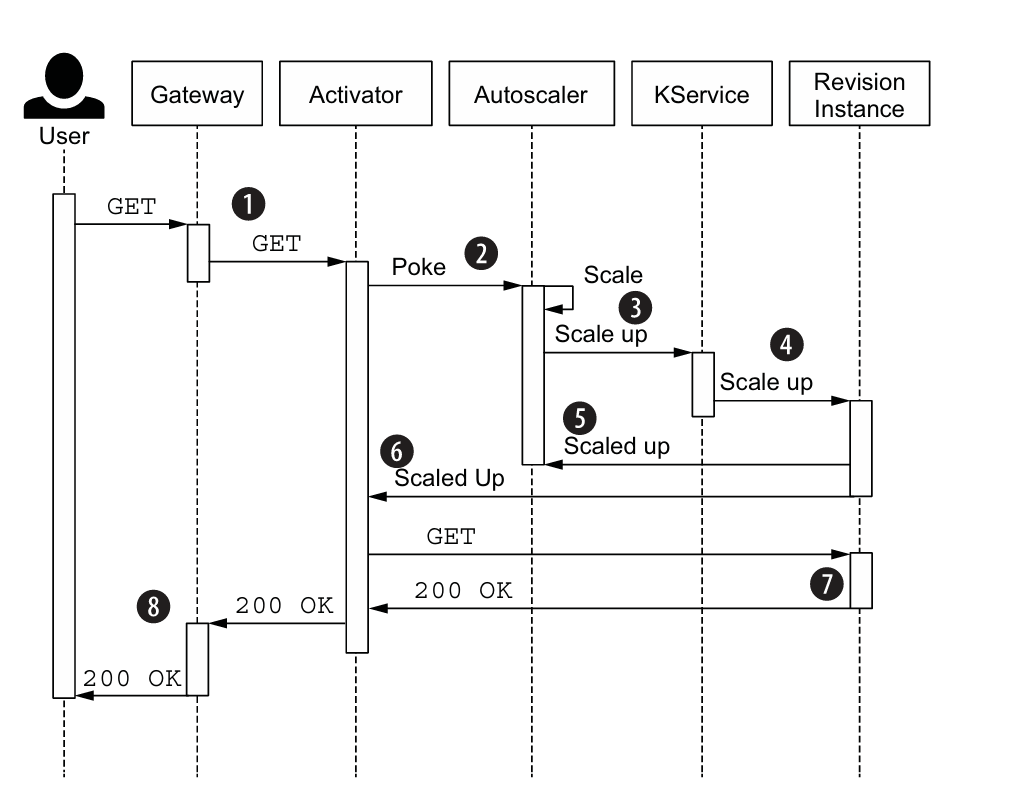
分解序列图,我们可以得到以下步骤:
- 用户发送一个 GET 请求。请求首先到达网关,网关当前将流量发送到 Activator(激活器)。
- Activator 缓存请求,然后通知 Autoscaler(自动伸缩器)。
- Autoscaler 做出扩展决定,将实例数扩展到 1。Autoscaler 更新 Knative 服务,将其状态设置为一个实例。
- 最终,这导致启动一个新的 Revision 实例。
- Autoscaler 记录到实例数已达到 1。
- Activator 注意到一个 Revision 实例现在已启动。
- Activator 现在将之前缓存的请求转发给 Revision 实例。
- Revision 实例发送响应。
- 响应随后从 Activator 流经网关返回给用户。
2. 冷启动问题深析
2.1 什么是冷启动?
冷启动指的是当服务从零实例扩展到至少一个运行实例所需的时间。这个过程可能包括:
- 调度Pod
- 拉取容器镜像
- 启动容器
- 初始化应用
2.2 冷启动的影响
冷启动可能导致:
- 首次请求的延迟增加
- 用户体验下降
- 在高并发情况下可能引发连锁反应
2.3 Knative如何缓解冷启动问题
- 预热 :通过设置
minScale确保始终有最小数量的Pod运行。 - Activator:在冷启动过程中缓存请求。
- 渐进式扩容:使用算法避免过度扩容。
3. Knative自动扩缩容配置详解
3.1 关键配置参数
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "100"
enable-scale-to-zero: "true"
stable-window: "60s"
scale-to-zero-grace-period: "30s"container-concurrency-target-default:每个Pod的目标并发请求数enable-scale-to-zero:是否允许缩减至零stable-window:稳定窗口期,用于计算平均并发scale-to-zero-grace-period:缩减至零前的等待时间
3.2 服务级别配置
可以在Knative Service定义中覆盖全局配置:
yaml
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: example-service
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "1"
autoscaling.knative.dev/maxScale: "5"
autoscaling.knative.dev/target: "10"这里设置了最小1个Pod,最大5个Pod,每个Pod的目标并发为10。
4. 使用Apache Kafka增强Knative自动扩缩容
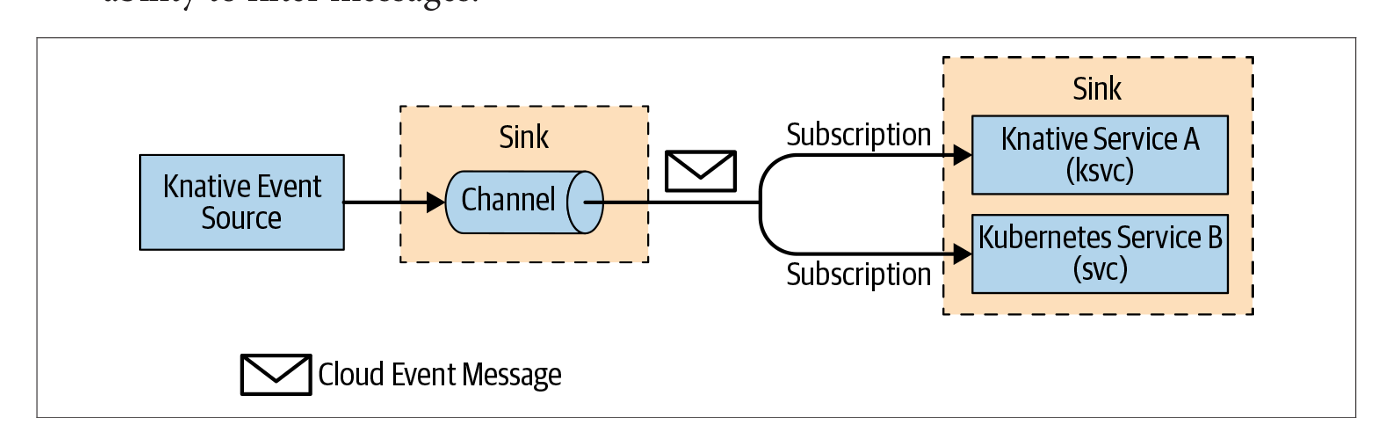
在 Knative Eventing 系统中,通过 Channels(通道)和 Subscriptions(订阅)定义了一个 Channel(通道),它可以连接到各种后端,如 In-Memory(内存中)、Kafka 和 GCP Pub/Sub,用于事件源。每个 Channel 可以有一个或多个以 Sink Services(接收服务)的形式存在的 Subscriber(订阅者),这些订阅者可以接收事件消息并按需处理。来自 Channel 的每条消息都被格式化为 CloudEvent 并发送到链中的其他 Subscriber 以进行进一步处理。Channels 和 Subscriptions 的使用模式不支持消息过滤功能。
4.1 为什么选择Kafka?
- 解耦:Kafka可以解耦事件产生和消费。
- 缓冲:在流量突增时作为缓冲。
- 持久化:确保消息不会丢失。
4.2 Kafka与Knative Eventing集成
- 部署Kafka集群。
- 配置KafkaSource连接Kafka和Knative服务。
- 利用Knative Eventing的自动扩缩容特性。
4.3 配置示例
yaml
apiVersion: sources.knative.dev/v1beta1
kind: KafkaSource
metadata:
name: kafka-source
spec:
consumerGroup: knative-group
bootstrapServers:
- my-cluster-kafka-bootstrap:9092
topics:
- my-topic
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: event-display这个配置将Kafka主题my-topic的消息发送到Knative服务event-display。
5. 实战案例:构建Serverless冷启动负载仿真平台
现在,让我们通过一个实际案例来整合前面所学的知识,构建一个Serverless冷启动负载仿真平台。
5.1 平台概述
我们将创建一个系统,使用真实的访问模式数据通过Kafka发送消息,触发Knative服务的自动扩缩容,并监控冷启动性能。
5.2 技术栈
- Kubernetes:底层容器编排平台
- Knative:Serverless框架
- Apache Kafka:消息队列
- Prometheus & Grafana:监控和可视化
5.3 实现步骤
- 准备环境
- 部署Kubernetes集群
- 安装Knative(Serving和Eventing)
- 部署Kafka集群
- 创建负载生成器
python
import json
from kafka import KafkaProducer
import time
producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
def send_load(timestamp, requests):
message = json.dumps({
'timestamp': timestamp,
'requests': requests
}).encode('utf-8')
producer.send('load-topic', message)
# 读取仿真数据并发送
with open('simulation_data.csv', 'r') as f:
for line in f:
timestamp, requests = line.strip().split(',')
send_load(timestamp, int(requests))
time.sleep(1) # 控制发送速率- 配置Knative服务
yaml
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: cold-start-service
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "0"
autoscaling.knative.dev/target: "10"
spec:
containers:
- image: your-test-image:latest- 配置KafkaSource
yaml
apiVersion: sources.knative.dev/v1beta1
kind: KafkaSource
metadata:
name: kafka-load-source
spec:
consumerGroup: knative-group
bootstrapServers:
- my-cluster-kafka-bootstrap:9092
topics:
- load-topic
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: cold-start-service- 部署监控
- 配置Prometheus采集Knative指标
- 设置Grafana仪表板展示关键指标:
- Pod数量变化
- 请求延迟
- 冷启动频率和持续时间
- 运行实验
- 启动负载生成器
- 观察Knative服务的扩缩容行为
- 通过Grafana分析冷启动性能
5.4 数据分析
通过这个平台,你可以:
- 研究不同负载模式对冷启动的影响
- 评估各种Knative配置对冷启动性能的影响
- 开发和测试新的冷启动优化策略
结论
通过深入理解Knative的自动扩缩容机制和冷启动问题,再结合实际的负载仿真平台,你现在有了一个强大的工具来系统地研究Serverless环境下的容器调度优化。这个平台不仅可以帮助你验证现有的理论,还可以成为你开发新的调度算法和优化策略的基础。
记住,真正的研究往往始于实践。通过不断调整参数、分析数据,你将逐步积累宝贵的经验,最终可能找到改善Serverless冷启动问题的创新方法。祝你研究顺利!
参考书籍
- Knative云原生应用开发指南
- Knative Cookbook Building Effective Serverless Applications with Kubernetes and OpenShift by Burr Sutter, Kamesh Sampath
- Knative+in+Action-2021