Stale diffusion+Webui使用教程
- [一、 Stable Diffusion简介](#一、 Stable Diffusion简介)
- 二、界面基础
一、 Stable Diffusion简介
Stable Diffusion (稳定扩散) 是一个扩散模型,2022年8月由德国CompVis协同Stability AI和Runway发表论文,并推出相关程序。同年,AUTOMATIC1111开发了图形化界面:「Stable Diffusion WebUI」,这是能用AI技术生成图片的开源软件,只要给定一组描述文本,AI就会开始绘图(准确的说是「算图」或「生图」);亦能模仿现有的图片,生成另一张图片。
以下是一些Stable Diffusion WebUI生成的图像,无后期处理,来源:哩布哩布ai

Stable Diffusion原理介绍
Stable Diffusion 是一种深度学习模型,主要用于生成高质量的图片。它基于一种被称为扩散过程的原理,该过程在时间上正向进行时逐渐将数据(如图像)加入噪声,使其变得越来越不清晰,直至完全随机;而在时间上逆向进行时则从噪声中逐渐恢复出清晰的数据。这种模型可以用于文本到图像的生成、图像编辑、风格迁移等多种应用。

关键特点:
文本到图像生成 :用户可以输入一段描述性的文字,模型便能根据这段文字生成相应的图像。
高质量输出:Stable Diffusion 能够生成非常高质量的图像,其分辨率和细节程度可以达到非常高的标准。
多模态应用:除了文本到图像的生成,Stable Diffusion还可以应用于图像到图像的转换、图像编辑、视频生成等多个领域。
模型结构:Stable Diffusion模型通常包括一个变分自编码器(VAE)和一个去噪扩散过程。VAE负责将图像编码成潜在表示,并从潜在空间解码回图像;去噪扩散过程则在潜在空间中逐步去除噪声,生成新的图像。
基本原理
扩散模型的工作原理分为两个过程:正向过程和反向过程。
正向过程(扩散过程):这个过程将真实图像逐渐加入噪声,直至图像变成随机噪声。这个过程是多步骤的,每一步都会增加一些噪声。
反向过程(去噪过程) :与正向过程相反,反向过程从纯噪声开始,通过学习逐步去除噪声,最终恢复出清晰的图像。

模型架构
文本编码器 :将输入的文本描述转换为对应的嵌入向量。
U-Net :一种编解码器结构,用于在去噪过程中预测噪声残差。
变分自编码器(VAE):将图像编码到潜在空间,并在生成图像时从潜在空间解码图像。
二、界面基础
1、Ckp大模型、VAE模型、CLIP skip
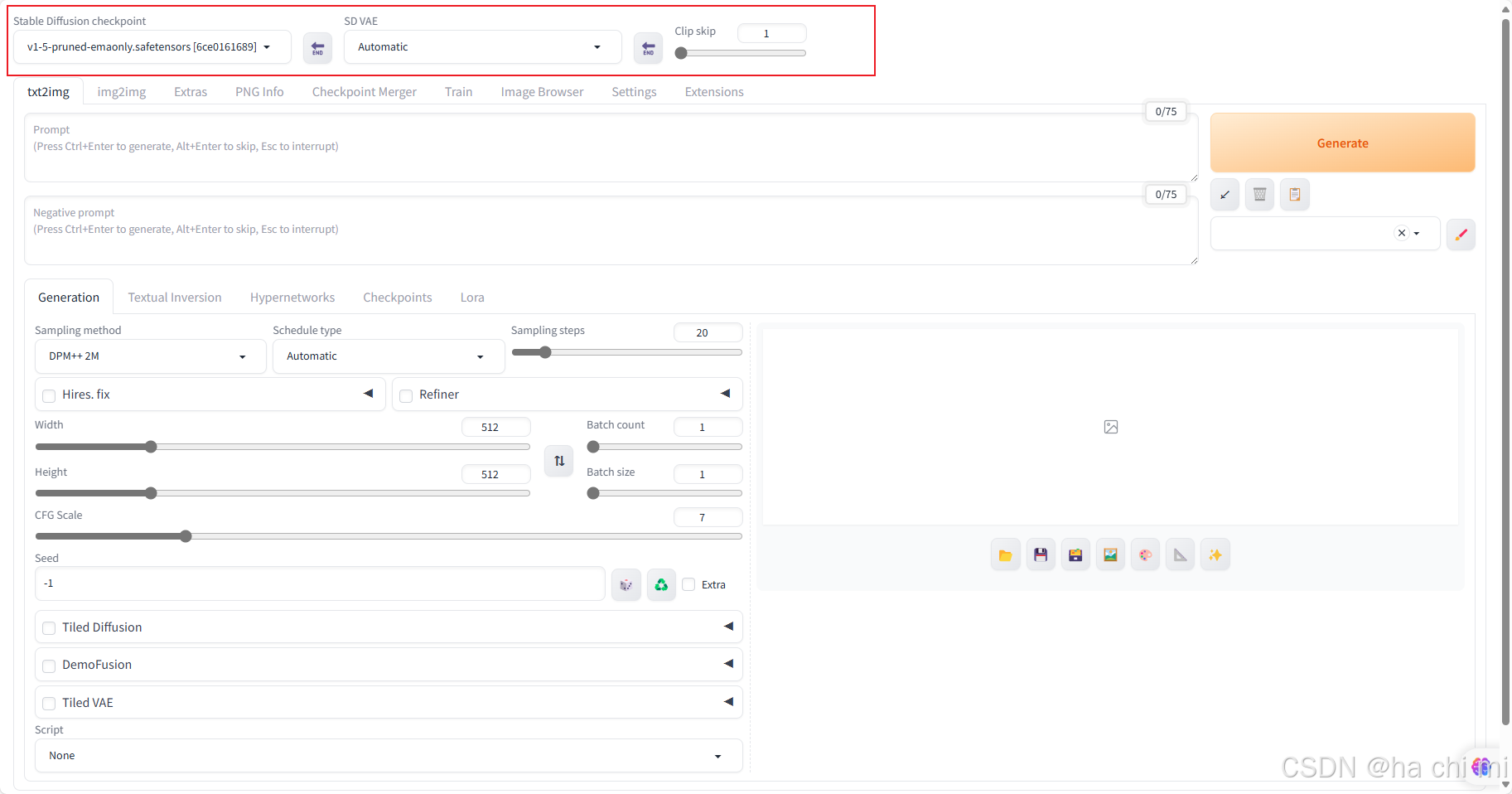
上图红色框框处「v1-5-pruned-emaonly.safetensors」是Stable Diffusion WebUI预先为我安装的主模型。 一般用户可以通过自己喜欢的风格或更热门的模型来使用。 我推荐使用最主流的模型下载网站https://www.liblib.art/,下载回来的主模型应存放在「安装目录/models/Stable-diffusion」。VAE,即变分自编码器(Variational Autoencoder),可以与Checkpoint模型结合使用,改善图像。CLIP内部有十二层结构,由上而下的分类越来越细致,至于所谓的CLIP Skip,它告诉AI在某层之后不再进行更细的分类。
具体解析
Checkpoint :我们通常将其尊称为"基础模型"或"主干网络"。这个基础模型是整个绘图系统的基石,它承载了庞大的图像数据信息集,是实现高级图像生成功能的核心要素。
在文件体积上,基础模型通常庞大无比,其大小往往超过2GB。这是因为,训练这样一个模型需要海量的计算资源和时间投入------涉及到数千张高端显卡的并行计算、数十亿张图片的数据处理,以及数月甚至更长时间的持续训练,这样的资源投入远非常人所能承担。
即便个人有能力在官方模型的基础上训练出具有特定风格和特色的Checkpoint模型,但由于模型文件体积巨大,对其进行全面调整仍然需要昂贵的硬件资源和大量的时间。为了提高效率,尤其是在仅需对模型进行局部风格调整时,社区发展出了更为精简和高效的辅助模型技术,如embedding、Hypernetwork、LoRA、LyCORIS等。
这里是我们用来切换CheckPoint模型(cpt文件)的地方,就是我们通常说的切换大模型的地方,点开这里会看到你的Stable Diffusion(下文简称SD)已安装了哪些大模型,可以选择进行切换。
VAE :即变分自编码器(Variational Autoencoder),在图像生成领域,尤其是与Checkpoint模型结合使用时,其主要功能确实如您所述,用于提升图像的质量,尤其是在色彩饱和度和亮度方面。VAE通过编码图像数据到一个潜在空间,并从该空间解码以重构图像,在此过程中能够有效地改善图像的视觉效果。
VAE的作用具体如下 :
色彩增强:VAE能够学习到图像数据的潜在表示,这使得它能够在重构图像时增强色彩的饱和度和亮度,从而使图像看起来更加鲜明和生动。
细节优化:除了色彩调整,VAE还能帮助细化图像的细节,减少模糊和噪点,提高图像的清晰度。
风格调整:在某些情况下,VAE还能用于调整图像的风格,使得生成的图像更符合特定的视觉风格偏好。
CLIP模型 :包含了一个由十二层组成的结构,每一层从顶层到底层对分类信息进行逐级细化。例如,假设第X层负责编码"person"(人物)的概念,那么在第X+1层,这种分类会更加具体,如"man"(男人)、"woman"(女人)或"1girl"(一个女孩)等。尽管实际的分类机制更为复杂,但可以大致这样理解其层次化的分类逻辑。
关于"CLIP Skip"的概念,它实质上是指导AI在处理到某个特定层级后停止进一步的细分。以CLIP Skip 2为例,如果你输入的提示词是描述一个有着白胡子、穿白袍、戴白帽、手持魔杖的老年巫师,AI可能会忽略掉白胡子、白袍或巫师等细节。随着CLIP Skip值的提升,AI将忽略更多的分类信息。当CLIP Skip设置为最大值12时,所有层级的信息都将被忽略,此时AI将不会依据任何提示词进行创作,而是完全自由发挥。
2、Stable Diffusion WebUI 基础功能
2.1 文生图 Text to image
启动Stable Diffusion WebUI网页界面后,首先映入眼帘的是文生图的操作页面。
参数说明
-
Stable Diffusion checkpoint:当前选用的模型存盘点。
-
Prompts 提示词:在这里输入正面和负面提示词。
-
Sampling Methods 采样方法:取样方法可以视为模型在运算过程使用的不同算法方法,采用不同的采样策略和步骤会带来明显不同的输出效果,并且对生成速度也会产生影响。以下是对各采样方法特性的概述:
- Euler a:Euler a 方法简捷高效,通常适用于生成低分辨率图像,是众多采样方法中速度最快之一。
- DPM++2M Karras:DPM++2M Karras 方法更为先进,适用于生成较高分辨率的图像。虽然它的速度不及 Euler a,但仍然较快。
- DPM++ SDE Karras :DPM++ SDE Karras 是最先进的方法之一,能够生成极高分辨率的图像,同时也是速度较慢的采样方法之一。
以下是基于文件名的快速分类指南: - 带"-a":这类采样器的文件名中包含"-a",它们的去噪能力较为分散,对关键词的识别能力相对较弱。
- 带"-karras":这类采样器的去噪能力迅速。
- DDIM、LMS、PLMS:这些是Stable Diffusion早期版本的采样方法,现在已经较为落后,不太推荐使用。
- DPM推荐:DPM++ SDE Karras 是目前广泛使用的采样方式,它在去噪速度和关键词识别精度上都表现良好。
- 新版UniPC:UniPC作为新型采样器,也集成了上述采样器的优点,可视为一颗新兴之星。
-
Sampling Steps 采样步数:建议至少设置为20步,特别是使用Euler a和UniPC方法时效果较好。而DDIM则需要超过80步才能获得良好结果。
-
Hires_fix 高清修复 :Hires fix(高分辨率修复)
由于stable diffusion的模型训练使用的是768*768(2.0)分辨率的图,768的分辨率对于现在来说是不太够用的,这就需要高分辨率修复或者后期处理。注意在生成图片时最好宽度和高度有一边是768,否则可能出现像两张图片拼接在一起的效果。
- Upscaler:选择使用的放大器。
- Hires steps:高清修复的步数。
- Denoising strength:降噪强度。
- Upscale by:缩放比例。
-
Refiner:Refiner(SDXL精细化模型)是一种先进的图像生成技术,它可以进一步优化和改进生成的图像质量。SDXL模型分为两部分,
- 基础模型,各操作跟1.5没有区别;
- 精细化模型,其作用是对基础模型的生成图进行细节优化,仅使用基础模型生成也没有问题,但只有两个模型同时使用时才是完整的SDXL。
-
Width x Height 图片宽高 :设置生成图片的尺寸,尺寸越大质量越好,但显存消耗也越大。
v1.5模型默认为512x512,v2模型建议尝试768x768。
-
CFG Scale:Classifier-free guidance scale,影响AI生成图片与提示词的相关度,数值越高,生成图片越符合提示词。
-
Batch count:设置生成图片的次数。
-
Batch size:设置一次性生成的图片数量。通常只需调整Batch count,Batch size保持为1即可。
-
Seed 种子码:用于生成图片的随机种子,保存种子码有助于复现风格。
-
Seeds Extra:用于测试不同的种子码变化。
-
Scripts:加载用户编写的脚本。内置脚本包括:
- Prompt Matrix:生成表格图片,比较不同提示词的生成效果。
- Prompts from files or textbox:从文件或文本框中的提示词生成图片。
- X/Y/Z plot:比较不同提示词、采样方法、CFG Scale、种子码组合的生成效果。
生成按钮下面3个按钮作用由左至依序为 :1. 叫出上次生图使用的设置值 2. 清空提示词 3. 套用选中的风格

下方的Styles列表可以保存的提示词
点击右边画笔按钮进行编辑,点击保存的提示词。再点击上面的套用选中的风格,即会将该提示词组合加到左边的提示词字段。
生成图像的下方五个按钮作用由左至依序为:
1.打开图片输出目录 2.保存图片到指定的目录(log/images)3.将图片压缩为zip文件并保存到指定的目录(log/images)4.将图片发送到img2img选项卡进行处理。5.将图片发送到Inpaint选项卡进行处理。6.将图片发送到extras选项卡进行处理。7.表示使用hires fix设置创建当前图片的高分辨率版本。

实际操作
-
在Stable Diffusion WebUI界面的顶部,进行模型的选择。模型切换大约需要30秒的等待时间。

-
在页面的左上方部分,输入您想要的正面和负面提示词(英文)。

-
采样方法,建议首先尝试速度最快的「UniPC」,其次是「Euler a」和「DPM++ 2M Karras」。将采样步数设置为20,并将图片的宽度和高度设置为512x512。

-
点击位于右上角的Generate按钮开始生成图像。

图像的生成时间取决于您的显卡性能。生成完成后,您可以点击下面按钮进行保存,或者点击图片进行放大,右键保存,还可以点击右下角的Zip按钮,将图片压缩成压缩文件下载。
在左下角,您可以设置Batch count的数值,以一次性生成多张图像。
如果您对生成结果感到满意,可以考虑保存种子码(Seed),这样可以在未来复现相同的风格。
注意无论是否选择右键保存图片,Stable Diffusion WebUI生成的所有图像都会自动保存在主程序目录下的outputs文件夹中。
2.2 图生图 Image to image
图生图主要分为全局重绘与局部重绘两个功能,相比文生图的抽卡,图生图因为有个参考图片打底,所以有更高的可控性

全局重绘
img2img和sketch会根据重绘强度的高低对全图进行重新绘制,因此参考图最重要的部分是颜色和构图,而不是细节。
- 参数栏
- 从左到右依次是拉伸模式,直接把短边拉长;裁剪模式,把长边的上下剪掉;填充模式,填充短边;直接缩放

- Denoising strength : 降噪强度数值越小,生成的图与原图越相似,可用来微调图片。

- 其余参数在文生图部分讲过,不再赘述
- 从左到右依次是拉伸模式,直接把短边拉长;裁剪模式,把长边的上下剪掉;填充模式,填充短边;直接缩放
局部重绘
无论是img2img还是sketch,无论您在提示词中指定了哪个部分,它都会对整张图像进行重绘,可能无意中改变了我们原本不想变动的地方,导致画面效果不尽人意。 Inpaint和Inpaint sketch就是为了解决这一问题而设计的,它们的主要特点是仅对标记的区域进行重绘,即进行局部重绘,从而避免了不必要的全局改动。
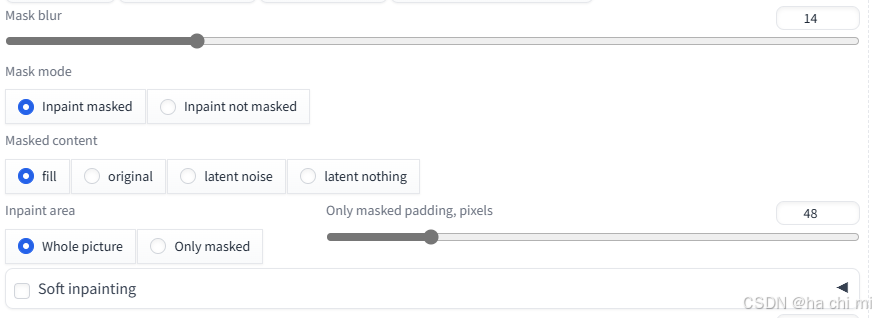
-
Mask blur 这个选项用于调整图片上笔刷边缘的柔和程度。
-
Mask mode 这个设置决定了AI是填满涂黑区域(Inpaint masked)还是填满未涂黑区域(Inpaint not masked)。
-
Masked content 这个指的是将要填充到涂黑区域的内容类型。
- Fill:指示AI根据涂黑区域周边的颜色来填充区域。
- Original:在填充区域时,参考原始图片下的内容。
- Latent noise:使用潜在空间来填充,可能会产生与原图完全无关的内容。
- Latent nothing:使用潜在空间来填充,但不加入任何噪声。
-
Inpaint area 这个选项用来选择是填满整张图片(Whole picture)还是只填满涂黑区域(Only masked)。Only masked padding, pixels 这里的"Only masked"指的是仅对涂黑区域进行外补绘制的模式,而"pixels"是指定涂黑区域边缘的像素内距。
-
Soft inpainting 是 Stable Diffusion 1.8 版本中引入的一项技术,主要应用于图像修复和局部编辑。核心优势在于能够更加自然和无缝地将修复区域与原始图像融合,减少了传统图像编辑中常见的边缘痕迹和违和感。下面是参数的详细说明:
- Schedule bias(时间表偏差)
- Schedule Bias < 1:当时间表偏差小于1时,在修复过程的后阶段会更多地保留原始图像内容,这意味着在重绘的早期阶段,模型会更加侧重于引入修复内容。
- Schedule Bias > 1:相反,当时间表偏差大于1时,在修复的早期阶段就会更多地保留原始图像内容,随着过程的推进,逐渐引入更多的修复内容。
- Preservation strength(保留强度)
保留强度与时间表偏差相似,也是控制原图内容保留程度的参数,但其变化是线性的,这使得调整时更加直观和易于控制。 - Transition contrast boost(过渡对比度增强)
低值:过渡对比度增强的低值会产生较为柔和的混合效果,使得修复区域与原图的过渡更加平滑自然。
高值:高值则会增强对比度,使得修复区域与原图之间的界限更加明显,适合需要突出修复细节的场景。 - Difference threshold(差异阈值)
差异阈值用于控制重绘区域与原图之间的差异程度。增加这一阈值会使修复区域更加接近原图,减少差异,从而实现一种淡出效果。当差异阈值达到最大时,图像将不会显示任何重绘内容,保持原始状态。
实际操作:
在文生图生成完毕之后,点击下方按钮发送将图像发送到img2img选项卡进行处理
或者直接在图生图界面上传图像。
模型改为二次元动漫模型,进行真人图像转动漫画风
采样方法选择「UniPC」,其余参数保持默认
效果如下图

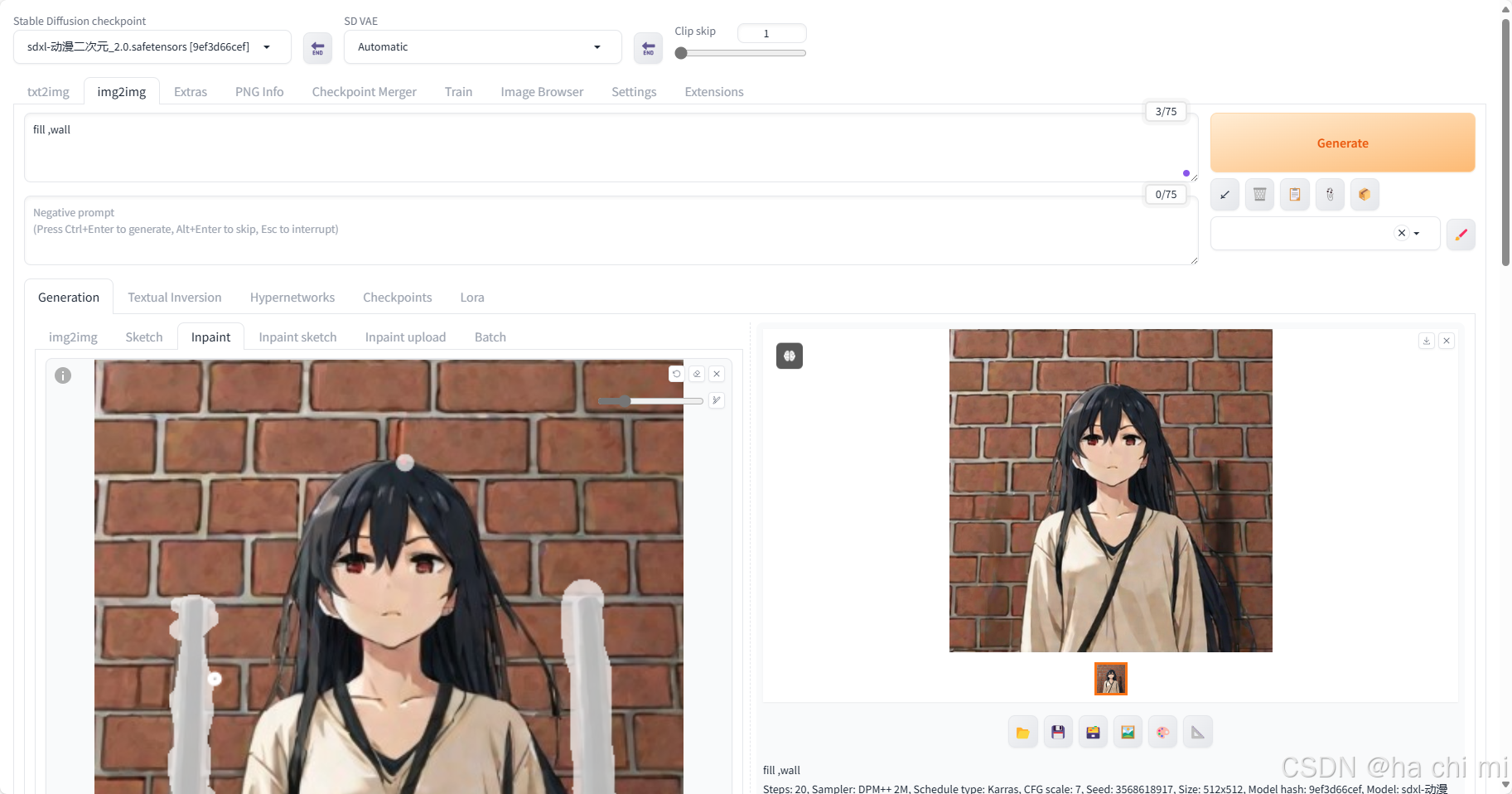
局部重绘Inpaint
导入原图后,旁边有个黑色画笔,用来画蒙版

勾选Soft inpainting,其他参数保持不变,对缺失墙体进行填充。