背景介绍
我司中创新航(CALB),是全球领先的新能源科技企业 ,致力于成为能源价值创造者(<https://baike.baidu.com/item/创造者/10818258?fromModule=lemma_inlink" t "/Users/shangeyao/Documents\x/_blank>),构建全方位能源运营体系,为以动力及储能为代表的新能源全场景应用市场提供完善的产品解决方案和全生命周期管理。

随着业务的不断发展,日益增长的跨基地生产数据同步及计算对我们的整体数据架构带来了极大的挑战。
数据架构
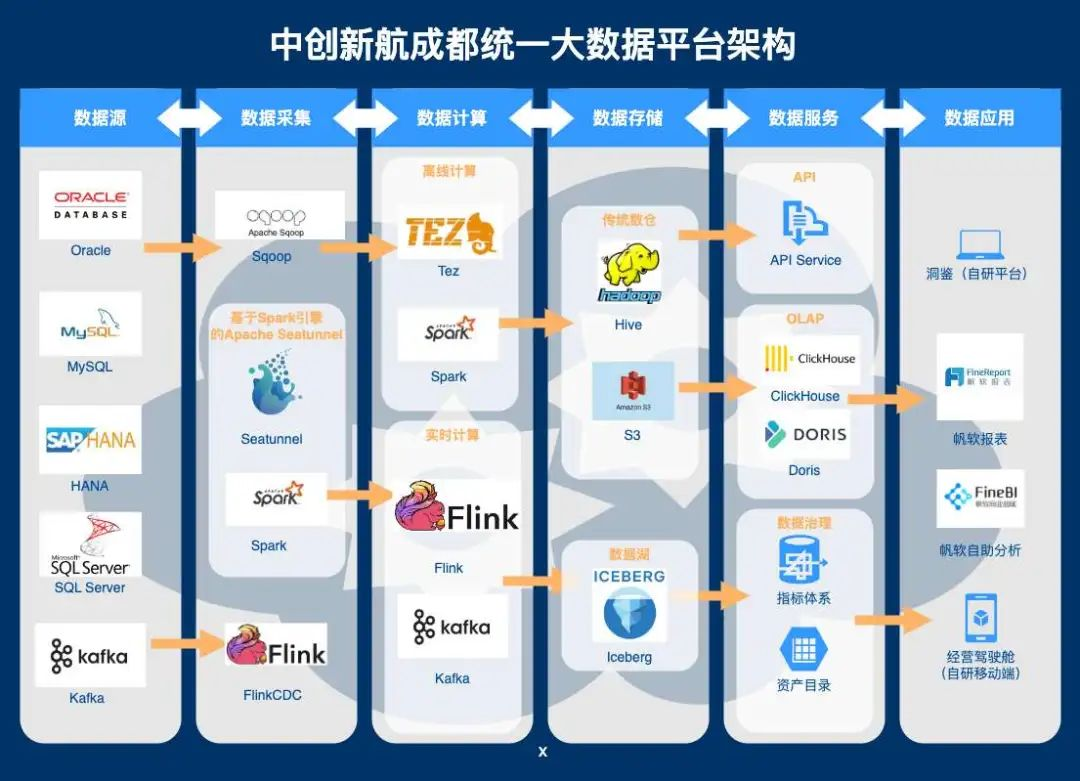
以上为我司现有的数据架构图,其中最大的特点为跨基地的多机房设计,运维难度高,资源需求量大。传统意义上的多机房数据架构存在以下两大问题:
带宽瓶颈
离线场景主要是批处理场景,是对海量历史数据进行离线分析/处理的场景,该场景对延迟不敏感,但由于其处理数据量巨大对网络带宽等资源消耗较大;
另外,生产场景中作业数量一般较多且执行时间不受控,若两个机房的主机只是简单叠加在一起做为一个集群来用,可能会存在大量的跨机房互访,产生大量的随机流量打满有限的跨机房带宽, 此时除离线自身受影响外, 还可能对其它跨机房业务造成影响。
网络抖动
跨城网络会受供应商服务质量影响(或施工影响)造成抖动(或断网), 与机房内CLOS架构的网络质量相比会低很多。
若两个机房的主机当做为一个集群来用,以HDFS为例,当网络抖动时,不但会导致跨机房读写延迟增加,还会影响DN的IBR等过程,造成服务性能和稳定性下降;
当网络出现严重问题造成断网时,会导致异地机房数据不可用,还会导致异地机房DN失联,造成大量Block低于预期副本数,触发NN大量补副本等问题。
综上所述,多机房的主要矛盾是跨机房网络带宽不足、稳定性差与离线海量数据处理任务高效产出之间的矛盾,解决该主要矛盾面临的核心问题是如何减少跨机房带宽的消耗,防止异地出现多次数据交换而带来的额外开销。
根据以上存在的问题,我们选择了成都基地,用于部署统一的数据集群,其中包括数据计算集群、数据存储、数据应用、数据治理等工具,构建以成都基地为中心的大数据统一平台。
存储相关,我们采购了某知名供应商的分离存储业务,实施存算分离架构,同时支持S3、Hadoop等多项存储协议,空间易于扩展,极大补全了原生HDFS存在大量Block时对NameNode的负载压力这一方面的缺陷。
选型及落地
之前,我们原有的调度系统来自于我们供应商提供的基于Azkaban的开发的平台,存在以下问题:
单点故障
如果Azkaban Web Server或Executor Server出现故障,可能会导致整个工作流执行中断。虽然Azkaban支持多Executor Server模式,但在Web Server上仍可能存在单点故障风险。
资源管理与隔离
Azkaban默认并不提供细粒度的资源管理和任务隔离机制,这意味着在共享资源环境下,任务执行可能会受到其他高负载任务的影响。
可伸缩性限制
尽管Azkaban支持水平扩展(添加更多的Executor Server),但在极端高并发的场景下,系统的整体可伸缩性可能会受到网络通信、元数据存储(如MySQL)或其他瓶颈的限制。
可扩展性
前段虽然也支持了可拖拉拽式的开发,但支持的大数据组件较少,后期难以进行二次开发,以适应日新月异的大数据技术变化。
社区支持及文档
相较于其他调度系统Apache DolphinsScheduler、Airflow的应用广泛程度相比,Azkaban的社区在国内的影响力较小,因此获取帮助和支持的渠道较为有限。
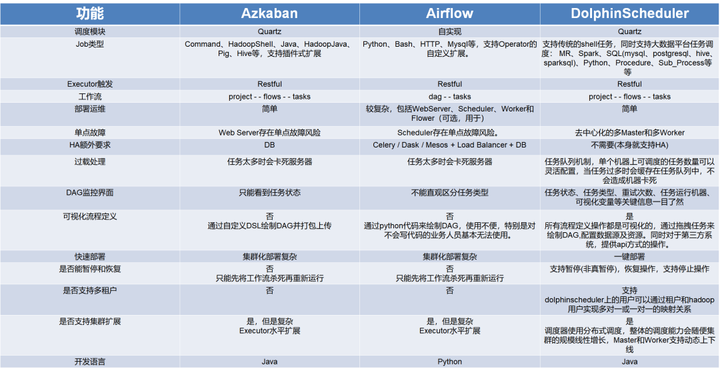
根据以上对于扩展性、易用性 及团队技术栈的整体考虑,我们选择了Apache Dolphinscheduler,并准备采用白鲸开源团队参与开发的另一款数据集成工具Apache SeaTunnel,用于解决我们目前应用DataX组件运行hive2doris、hive2clickhouse任务时存在的单点性能瓶颈及难以全局监控资源使用量的问题。
我们基于Apache Ambari和HDP构建了大数据架构体系,得益于HiDataPlus社区的帮助,我们在Ambari中集成了对于DolphinScheduler的配置与监控
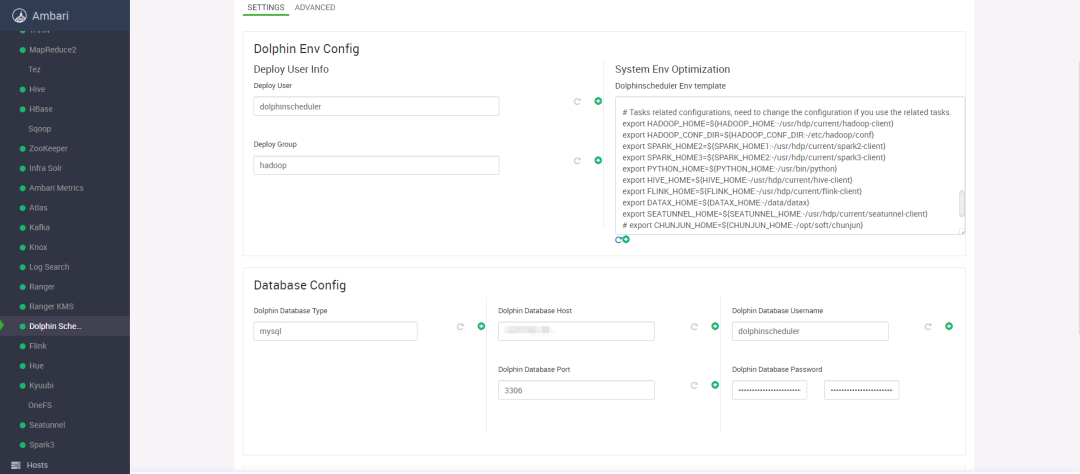
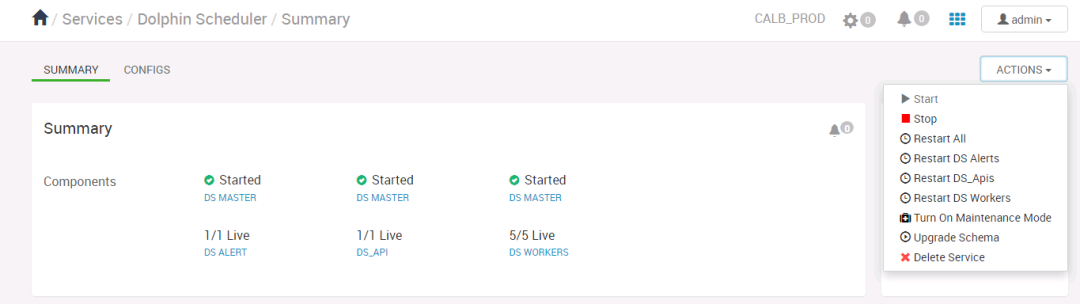
在Hive 3.1.3与Hadoop 3.3.4的基础上构建了现有的数仓体系,以DolphinScheduler为调度工具,Sqoop与SeaTunnel做数据集成工具,Spark3与Tez作为离线计算引擎,并在此基础上搭建了Iceberg数据湖,后期考虑用Iceberg替代目前的部分离线业务。

并且在引入初期部署了3.1.7版本,投入了5台 物理机器,搭建了3Master、5Worker的架构,为了让 DolphinScheduler 更加符合我们应用场景的需要,但又不希望过多代码侵入导致脱离社区,于是我们基于DolphinScheduler 只进行了少量的二次改造,包括以下方面:
-
加入SAP、Doris等数据源,后3.2版本社区也提供了相关PR,我们根据此进行了相关的一些合并。
-
Sqoop任务改造,我们主要的离线同步包括
oracle2hive、mysql2hive、hana2hive这三种,基于此前提,我们对DS已有Ssqoop任务插件进行了改造,包括但不限于支持自动生成target-dir临时目录,添加导入到hive时可以自己定义表存储类型,支持行列分隔符、替换符设置,极大的提高了离线任务的开发效率。 -
SeaTunnel的任务改造,引入ST后,我们准备将以后的Datax任务替换掉,于是我们利用已有的spark3.3.2作为执行引擎,替换了已有的
hive2ck与hive2doris任务,并对SeaTtunnel做了一些易用性的改造,比如可视化字段映射等。 -
此外我们对补数选用租户无效、spark组件模块不支持spark3选项等问题皆做了一些修复,大大提升了系统的稳定性、可用性等等。
对比与提升
相较于我们以前的旧架构,Dolphinscheduler给我们带来了需要全新的体验 ,极大了提升了数据开发效率,包括但不限于以下方面:
简单易用
更加易用的界面,工作流定义、实例具有更加清晰的界面,筛选条件丰富,清晰的任务状态及类型区分,任务运行一目了然。
丰富的插件设计
我们目前自有的系统中任务插件的种类单一 ,仅支持shell、sql、sqoop、datax、gpload等任务,且扩展起来较为困难。DS(海豚调度)提供了简单易上手的任务插件机制,为其定制了完善的生命周期流程,使得我们在后续扩展中可以非常轻松的实现启动、取消、追踪状态等多种操作。
易用的补数能力
对于这个补数操作,同事们交口称赞。原先我们的调度系统依靠时间戳运行,例如调度前设置时间戳为今日,则以今日的调度时间去运行任务,若发现前几日的数据有问题,则需要手动修改时间戳 ,并且等到上一个时间戳运行完毕后,才可以继续运行下一个任务。目前Dolphinscheduler做到了可以自选串行或并行补数,并可以自行定义从已选时间区间内升序或降序补数,更好的保证了原有逻辑的正确性。
完善的告警机制
原先的调度系统告警手段较为单一和落后, 我们通过对元数据的监控,内部实现了一套DQC机制,但该机制需要定期去查看DQC告警列表,不能第一时间发现问题,基于Dolphinscheduler的告警Trigger机制,我们实现了企业微信与邮件告警,方便在任务出错时第一次发现问题,且告警内容详细,甚至包含报错的信息与日志路径,大大提高了我们问题解决的效率。
灵活的执行与重试机制
Dolphinscheduler可以将任务组装成工作流,但它提供了更多样化的执行方式,可以在任务流中选择向前执行、向后执行、只执行此节点,重跑也可以选择重跑整个工作流或从失败节点开始重跑,提高了大规模故障时重新产出数据的速度。
期待与愿景
虽然我们团队的研发人员已经对Apache Dolphinscheduler较为熟悉了,但落地在我司的时间尚短,在使用了我们虽体验到了Dolphinscheduler性能的优越性,但基于功能易用性上,数仓团队还是给我们提了一些需求。
集成Git/Subversion等版本控制
Dolphinscheduler的任务编排已经存在了版本这一概念,但无法清晰直观的看到各版本之间的差别,特别是在迭代速度较快时,一旦发生意外的故障,没有办法及时的回滚。
如果能集成版本控制的话,可惜清晰地比对各个版本各行代码或配置文件之间的差异,能帮我们更快地定位问题。
简化SeaTunnel插件的配置难度
我们在使用基于Spark的SeaTunnel后,和Datax对比性能相当优越 ,我们原先在执行很多数据量很大的同步任务,Datax的单机特性都没法满足我们的需求,便用了Waterdrop完成了这部分的同步,现在有了SeaTunnel后,和我们使用WaterDrop遇到了一样的问题,配置不够自动化!
如同步Hive,还需要填写metastore地址,没法和Sqoop插件那样实现纯表格式的傻瓜配置,我们后续决定进一步简化配置难度,以现在的SeaTunnel Web为例子,将其中的部分功能改造移植过来,降低数据开发配置SeaTunnel任务的难度。
更丰富的监控指标展示
现在首页上已经有了工作流实例与任务实例当天的的运行状态统计,能让我们巡检人员较为直观的感受到今日任务的运行状态,但我们期望最好可以有一些比较指标,如近七天任务运行时间Top10,可以观测出性能较差的任务,便于我们的后续优化。
增加数据稽核功能
Dolphinscheduler已经提供了基于Spark的数据质量检查插件,便于我们粗粒度的去比对数据的准确性,但对我们来说仍有不足。
我们制造业有一个重要的任务就是数据归档,生产系统产生的数据后续都会存储于数仓,便于后续售后或质检,归档任务均为T+1执行,但生产系统的工单会更改较为久远的数据,会导致生产系统清档时数据不一致。我们目前基于Trino做的全量或抽样数据稽核,后续在替代原调度的基础上,我们将把该功能移植过来,以满足我们当前的业务需求。
集成 Compass
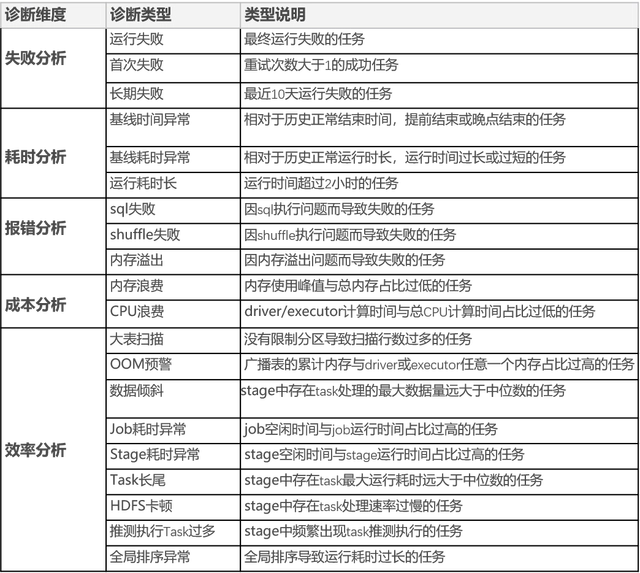
Compass是一个诊断大数据生态系统中计算引擎和调度器的平台,旨在提高故障排除的效率并降低问题调整的复杂性。
它自动收集日志和指标,除了使用启发式规则来识别问题并提供调整建议,对于日志,还使用了ChatGPT还提供诊断建议,日志将使用drain算法自动聚合为模板,可用于人工干预等,提升诊断自动化和优化方案能力。
其主要功能特性如下:
- 非侵入式,即时诊断,无需修改已有的调度平台,即可体验诊断效果。
- 支持多种主流调度平台,例如DolphinScheduler 2.x和3.x、Airflow或自研等。
- 支持多版本Spark、MapReduce、Flink、Hadoop 2.x和3.x 任务日志诊断和解析。
- 支持工作流层异常诊断,识别各种失败和基线耗时异常问题。
- 支持引擎层异常诊断,包含数据倾斜、大表扫描、内存浪费等14种异常类型。
- 支持各种日志匹配规则编写和异常阈值调整,可自行根据实际场景优化。
- 支持一键诊断全量(包含非调度平台提交任务)Spark/MapReduce任务。
- 支持ChatGPT对异常日志进行诊断,提供解决方案,使用了drain算法聚合模板,节约成本。
以下为可诊断类型概览:

详细内容可移步https://github.com/cubefs/compass.git
本文由 白鲸开源科技 提供发布支持!