1.Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions

标题:单目深度估计的扩散模型:克服具有挑战性的条件
作者:Fabio Tosi, Pierluigi Zama Ramirez, Matteo Poggi
文章链接:https://arxiv.org/abs/2407.16698
项目代码:https://github.com/fabiotosi92/Diffusion4RobustDepth
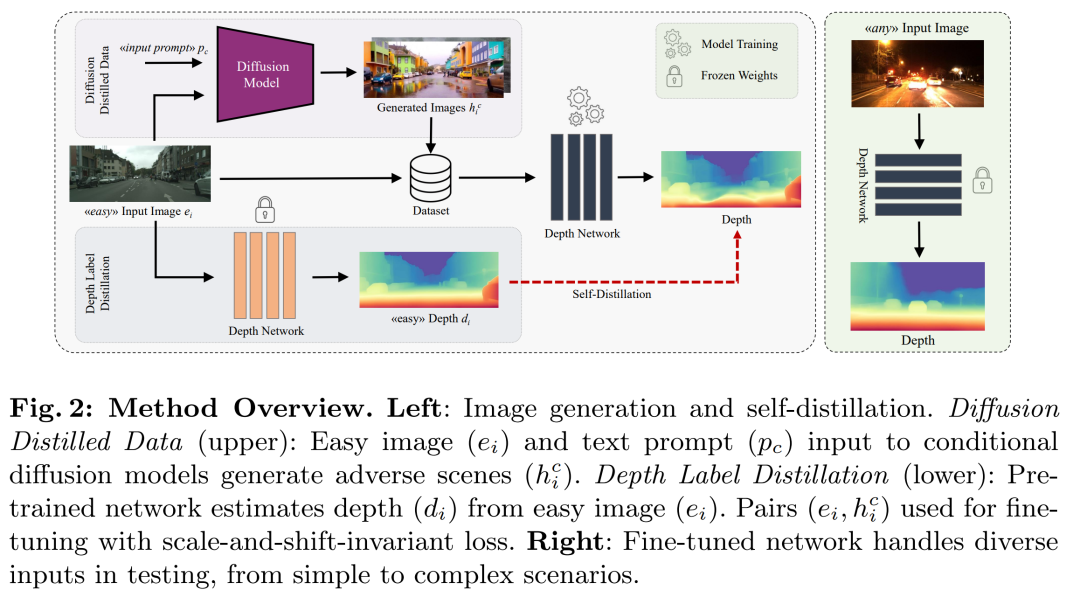


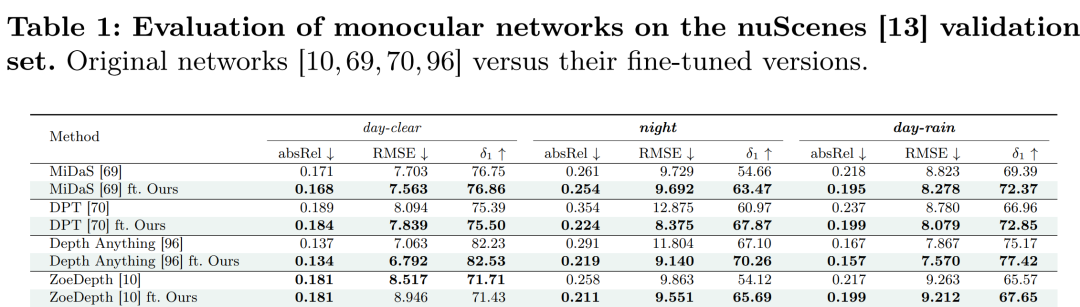
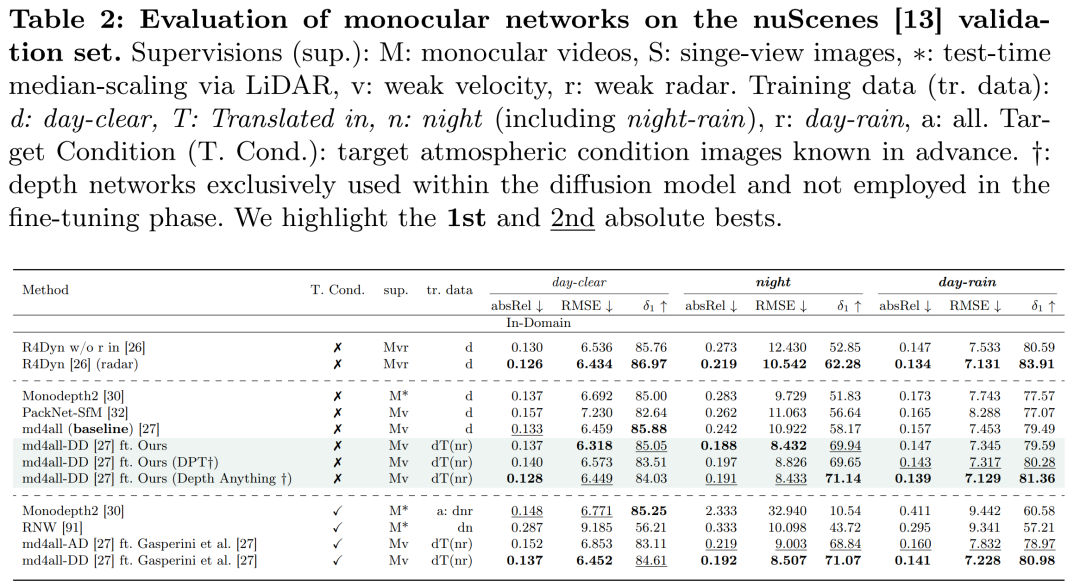
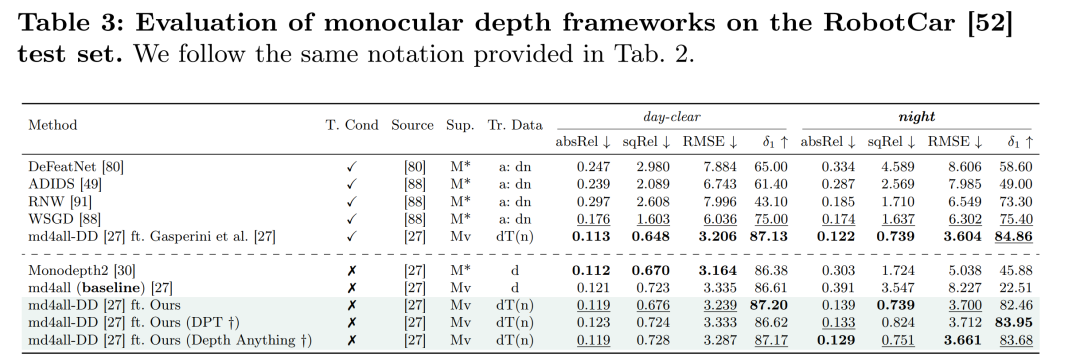


摘要:
视我们提出了一种新颖的方法,旨在解决单图像深度估计任务中具有挑战性的非分布数据所带来的复杂性。从由于不存在不利因素而促进深度预测的图像开始,我们系统地生成新的、用户定义的场景,并具有全面的挑战和相关的深度信息。这是通过利用具有深度感知控制的尖端文本到图像扩散模型来实现的,该模型以根据文本提示合成高质量图像内容而闻名,同时保留生成图像和源图像之间 3D 结构的一致性。任何单目深度网络的后续微调都是通过自蒸馏协议进行的,该协议考虑了使用我们的策略生成的图像以及它自己对简单、没有挑战性的场景的深度预测。针对我们的目的量身定制的基准实验证明了我们建议的有效性和多功能性。
这篇论文试图解决什么问题?
这篇论文提出了一种新的方法,旨在解决单图像深度估计任务中,由于面临具有挑战性的、分布外的数据而带来的复杂性问题。具体来说,该方法针对以下挑战:
-
不利条件下的深度预测:如在恶劣天气(例如雨夜)或具有非朗伯表面的对象等条件下,现有的深度估计模型可能无法准确预测深度。
-
高质量标注数据的不足:这些不利条件的数据往往缺乏高质量的标注信息,这对于训练健壮的深度估计模型是必要的。
-
现有技术的局限性:无论是基于视觉的深度提取技术还是主动传感器(如激光雷达、ToF、Kinect等)在复杂环境中的表现都可能受限。
论文的主要贡献包括:
-
引入了一种使用扩散模型作为解决单图像深度估计挑战的新策略,特别是针对不利的天气条件和非朗伯表面。
-
通过从扩散模型中提取知识,提高了现有单目深度估计模型在具有挑战性的分布外设置中的鲁棒性。
-
同时解决不利天气和非朗伯表面挑战,展示了在不牺牲性能的情况下,同时处理多种挑战性场景的潜力。
论文通过生成具有挑战性的场景,并结合简单的图像和深度预测进行自我蒸馏的微调过程,来提高模型在复杂环境中的深度估计能力。
论文如何解决这个问题?
论文通过以下步骤解决单图像深度估计中的挑战性问题:
-
生成具有挑战性的场景:
-
利用文本到图像的扩散模型(如ControlNet和T2I-Adapter),从简单的图像生成具有挑战性条件(如恶劣天气或非朗伯表面)的新场景。
-
这些模型能够根据文本提示和深度图等条件生成图像,同时保持与原始图像相同的3D结构。
-
-
预训练深度网络:
-
使用任何现成的单目深度估计网络为初始简单图像提供3D表示。
-
这个模型可以是在不同大规模数据集上预训练的,或者根据特定领域要求定制的。
-
-
自我蒸馏训练:
-
将预训练的深度网络用于生成的具有挑战性的图像和简单图像的深度标签预测。
-
使用生成的图像和对应的深度图进行微调,以提高模型在复杂环境中的深度估计能力。
-
-
规模和位移不变损失:
- 在微调阶段,使用规模和位移不变损失(scale-and-shift-invariant loss)来比较预测的深度和教师网络提供的注释。
-
模型无关性:
- 该方法不依赖于特定的预训练方法或微调模型,使其适用于各种现有的和未来的扩散或单目模型。
-
实验验证:
- 在多个数据集上进行实验,包括自动驾驶数据集(如nuScenes和RobotCar)和非朗伯数据集(如Booster和ClearGrasp),以验证方法的有效性。
-
性能提升:
- 通过与现有方法的比较,展示了该方法在处理不利条件下的深度估计任务时的性能提升。
通过这种方法,论文成功地提高了单目深度估计模型在面对复杂和不利条件时的鲁棒性和准确性。
论文做了哪些实验?
论文中进行了一系列实验来验证所提出方法的有效性。以下是实验的主要方面:
-
评估数据集与协议:
- 使用了多个数据集进行全面评估,包括自动驾驶场景数据集(nuScenes、RobotCar、DrivingStereo、KITTI 2012、KITTI 2015、Apolloscape、Mapillary、Cityscapes)和非朗伯数据集(Booster、ClearGrasp)。
-
生成具有挑战性的图像:
- 利用T2I-Adapter和文本提示从简单图像生成具有夜间和雨天条件的图像,以及使用Stable Diffusion生成非朗伯表面图像。
-
训练细节:
- 在单个NVIDIA GPU上进行所有实验,遵循先前工作的协议,使用AdamW优化器,并应用数据增强技术。
-
不利天气条件下的性能提升:
- 微调了几种最先进的单图像深度网络(DPT、MiDaS、ZoeDepth、Depth Anything),并在nuScenes数据集上评估了它们在不同天气条件下的性能。
-
与现有方法的比较:
- 将所提出的方法与现有方法进行了比较,特别是在处理具有挑战性条件的单图像深度估计方面。
-
日间数据集的适用性:
- 展示了即使在只有简单图像的日间数据集上训练,所提出的方法也能够提高在具有挑战性条件下的性能。
-
非朗伯材料的处理:
- 评估了所提出的方法在处理透明和反射物体(ToM)方面的有效性,并与专门针对这些问题的方法进行了比较。
-
定性结果:
- 提供了定性结果,展示了原始模型和使用所提出方法微调后的模型在预测深度图方面的对比。
-
性能指标:
- 使用了标准的性能指标,如AbsRel、RMSE、δ<τ(不同阈值τ下的准确率)和MAE,来评估深度估计的准确性。
通过这些实验,论文证明了所提出方法在提高单图像深度估计模型在面对不利条件和非朗伯表面时的鲁棒性和准确性方面的有效性。
论文的主要内容:
这篇论文提出了一种新的方法来提高单图像深度估计在具有挑战性条件下的鲁棒性和准确性。以下是主要内容的总结:
-
问题定义:论文针对单图像深度估计任务中,模型在面临不利条件(如恶劣天气、非朗伯表面等)时性能下降的问题。
-
方法概述:提出了一种使用扩散模型的方法,通过生成具有挑战性条件的新场景来增强模型的鲁棒性。
-
技术路线:
-
利用文本到图像的扩散模型,从简单场景生成复杂场景,同时保持3D结构的一致性。
-
使用预训练的单目深度估计网络为简单图像提供初始深度表示。
-
通过自我蒸馏协议,结合生成的复杂图像和对应的深度信息,对深度网络进行微调。
-
-
主要贡献:
-
引入扩散模型解决单图像深度估计中的挑战性问题。
-
提高了现有模型在分布外设置中的鲁棒性。
-
同时处理多种挑战性场景,展示了方法的通用性和有效性。
-
-
实验验证:
-
在自动驾驶和非朗伯数据集上进行了广泛的实验。
-
与现有方法进行了比较,证明了所提方法的性能提升。
-
-
结果分析:
-
微调后的模型在不利条件下的深度估计准确性得到显著提高。
-
展示了生成的具有挑战性场景的示例和定性结果。
-
-
未来工作:
- 提出了一些潜在的研究方向,包括更广泛的环境条件、模型优化、实时性能、跨域适应性等。
-
结论:
- 论文成功地展示了使用扩散模型来增强单图像深度估计模型在复杂条件下的性能是一种有效的方法。
论文的方法为解决单图像深度估计中的挑战性问题提供了一种新的视角,并为未来的研究和应用奠定了基础。
2.AbdomenAtlas: A Large-Scale, Detailed-Annotated, & Multi-Center Dataset for Efficient Transfer Learning and Open Algorithmic Benchmarking

标题:AbdomenAtlas:大规模、详细注释的多中心数据集,用于高效迁移学习和开放算法基准测试
作者:Wenxuan Li, Chongyu Qu, Xiaoxi Chen, Pedro R. A. S. Bassi, Yijia Shi, Yuxiang Lai, Qian Yu, Huimin Xue
文章链接:https://arxiv.org/abs/2407.16697
项目代码:https://www.zongweiz.com/dataset



摘要:
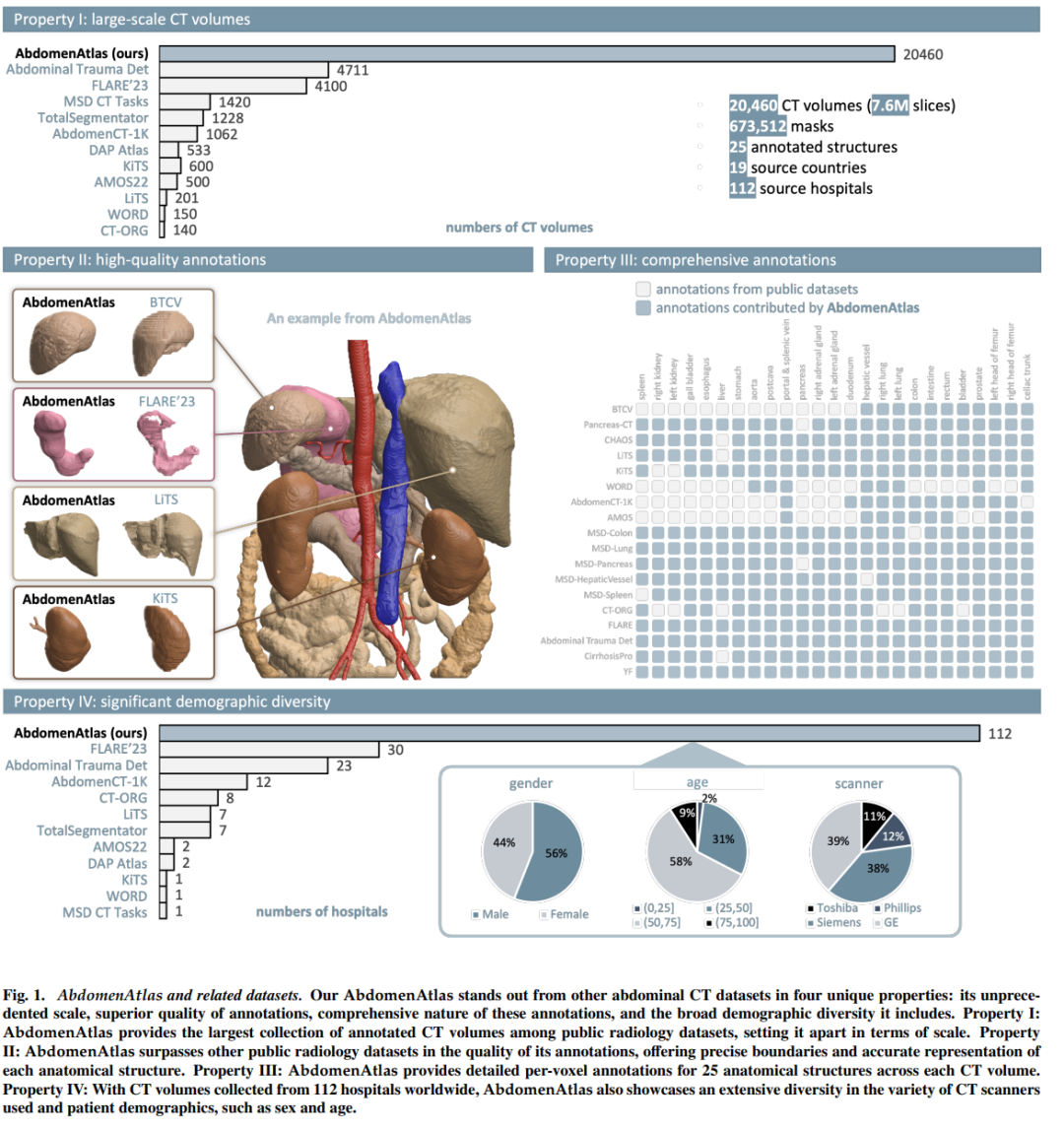
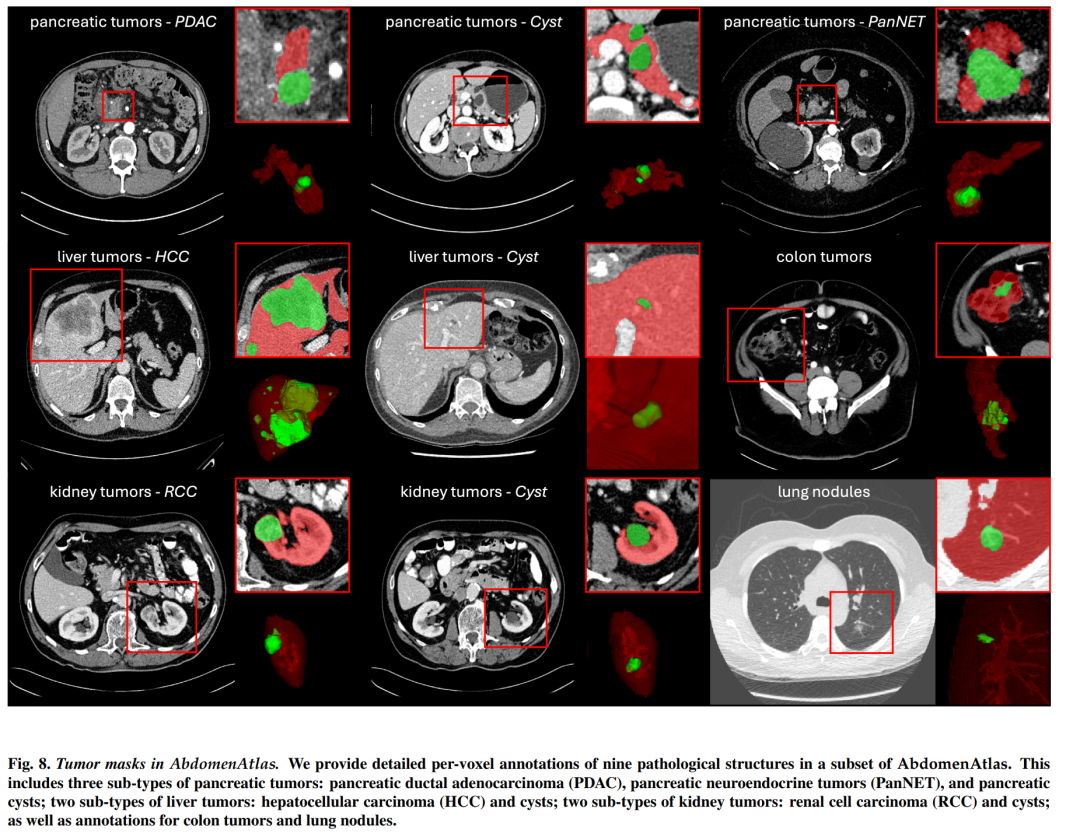
我们引入了最大的腹部 CT 数据集(称为 AbdomenAtlas),其中包含 20,460 个三维 CT 体积,这些体积来自 112 家医院,涵盖不同的人群、地理位置和设施。 AbdomenAtlas 提供 673K 个高质量的腹部解剖结构模板,由 10 名放射科医生组成的团队在 AI 算法的帮助下进行注释。我们首先让专家放射科医生手动注释 5,246 个 CT 体积中的 22 个解剖结构。接下来,对剩余的 CT 体积执行半自动注释程序,放射科医生修改 AI 预测的注释,反过来,AI 通过学习修改后的注释来改进其预测。需要如此大规模、详细注释和多中心的数据集有两个原因。首先,AbdomenAtlas 为大规模人工智能开发提供了重要资源,被称为大型预训练模型,可以减轻专家放射科医生的注释工作量,从而转移到更广泛的临床应用。其次,AbdomenAtlas为评估AI算法建立了大规模的基准------我们用于测试算法的数据越多,我们就越能保证在复杂的临床场景中可靠的性能。名为"BodyMaps:走向人体 3D 图集"的 ISBI 和 MICCAI 挑战赛是使用我们的 AbdomenAtlas 的子集发起的,旨在刺激人工智能创新并衡量分割准确性、推理效率和领域通用性。我们希望我们的 AbdomenAtlas 能够为更大规模的临床试验奠定基础,并为医学影像界的从业者提供特殊的机会。代码、模型和数据集可在此 https URL获取
这篇论文试图解决什么问题?
这篇论文介绍了一个名为"AbdomenAtlas"的大型、详细注释的多中心CT扫描数据集,旨在解决以下问题:
-
大规模、高质量的医学图像数据集的缺乏:在医学图像分析领域,尤其是三维医学图像,缺乏大规模、多样化且经过详细注释的数据集,这限制了开发大型预训练模型(如在自然语言处理领域中的GPT模型)的能力。
-
AI算法的泛化能力:AI算法在从一个中心的数据训练后,往往难以泛化到其他中心的数据。这表明现有数据集在多样性和泛化性方面存在不足。
-
医学图像分析中的AI开发和评估:缺乏大规模、详细注释的多中心数据集,限制了AI算法在更广泛临床应用中的开发和评估。
-
医学图像分割的准确性和效率:通过创建一个大型的基准测试,可以更好地评估和改进AI算法在医学图像分割任务中的准确性、推理效率和领域泛化能力。
论文通过构建"AbdomenAtlas"数据集,并利用这个数据集开发了大型预训练模型(SuPreM),以及组织了一个名为BodyMaps的国际比赛,来推动医学图像分析领域的AI创新,并为AI算法提供一个开放的算法基准测试平台。
论文如何解决这个问题?
论文通过以下几个关键步骤来解决提出的问题:
-
创建大规模、详细注释的数据集(AbdomenAtlas):
-
收集了20,460个三维CT体积,这些数据来自112家医院,涵盖了不同的人群、地理和设施。
-
提供了673K个高质量的腹部解剖结构掩膜,由10位放射科医生团队在AI算法的帮助下注释。
-
-
专家和AI的协同工作:
-
首先由专家放射科医生手动注释5,246个CT体积中的22个解剖结构。
-
然后对剩余的CT体积执行半自动注释程序,放射科医生修订AI预测的注释,并反过来通过学习修订后的注释来改进AI的预测。
-
-
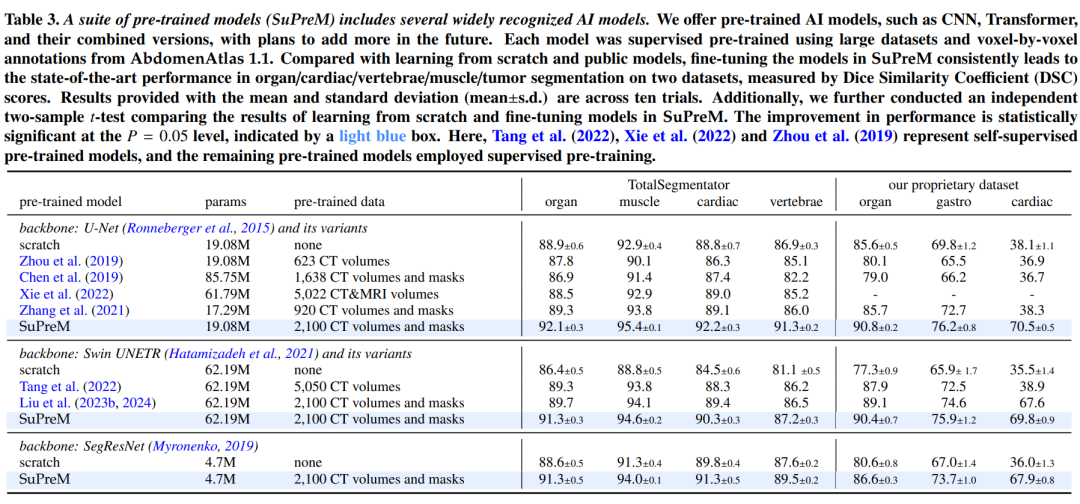
开发大型预训练模型(SuPreM):
- 利用AbdomenAtlas数据集,开发了一系列大型预训练模型,这些模型可以在多种下游任务中实现高效的迁移学习。
-
组织国际比赛(BodyMaps):
- 与ISBI和MICCAI合作,使用AbdomenAtlas的一个子集启动了一个挑战,旨在激发AI创新并为医学图像分割的准确性、推理效率和领域泛化能力提供基准测试。
-
提高数据集的多样性和泛化能力:
- AbdomenAtlas数据集涵盖了来自不同医院、不同国家、不同性别和年龄的患者,以及使用不同CT扫描仪和扫描类型收集的CT体积,这有助于提高AI算法在真实临床环境中的泛化能力。
-
关注数据集的质量和一致性:
-
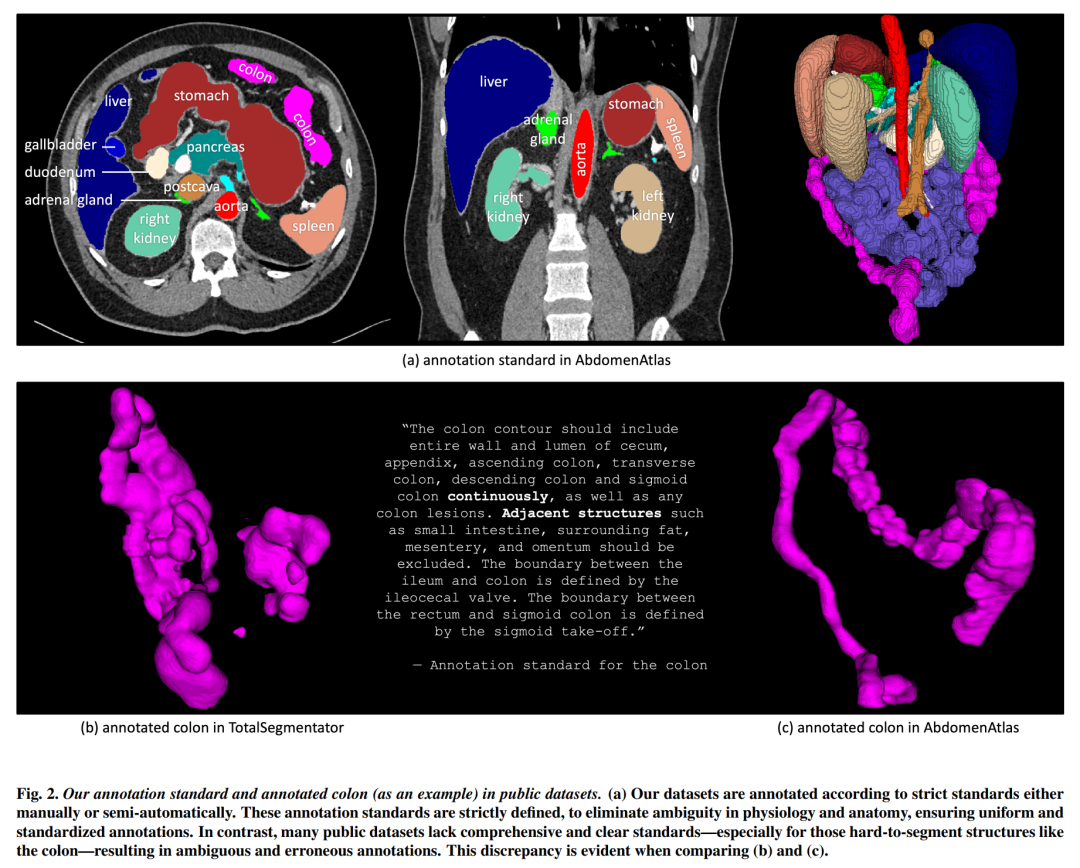
制定了全面的注释协议和标准,确保注释的准确性和一致性。
-
在数据集发布前,由四位高级放射科医生对整个AbdomenAtlas进行综合审查,并在必要时进行修订。
-
通过这些步骤,论文不仅提供了一个前所未有的大规模、详细注释的医学图像数据集,而且还推动了医学图像分析领域中AI技术的发展和评估。
论文做了哪些实验?
论文中进行了以下实验来验证AbdomenAtlas数据集和基于该数据集开发的SuPreM模型的有效性:
-
手动注释与半自动注释的比较:
- 通过专家放射科医生手动注释5,246个CT体积,并与AI预测的注释进行比较,以展示手动注释的高质量和精确性。
-
半自动注释过程的迭代优化:
- 使用注意力图(attention maps)来突出AI预测中可能的错误,指导放射科医生在半自动注释过程中进行修订。
-
SuPreM模型的预训练和微调:
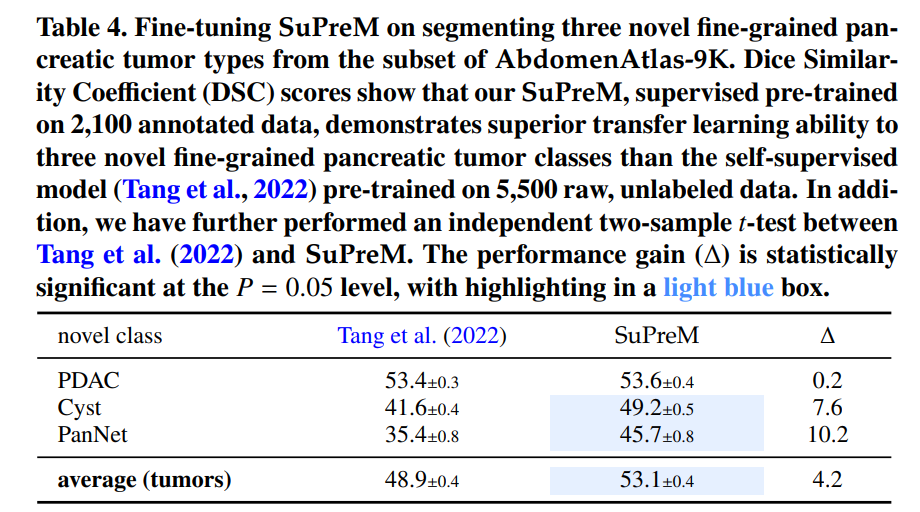
- 在AbdomenAtlas 1.1数据集上对SuPreM模型进行预训练,并在FullBodyAtlas-1K和AbdomenAtlas-9K的子数据集上进行微调,以评估模型在不同任务上的迁移学习能力。
-
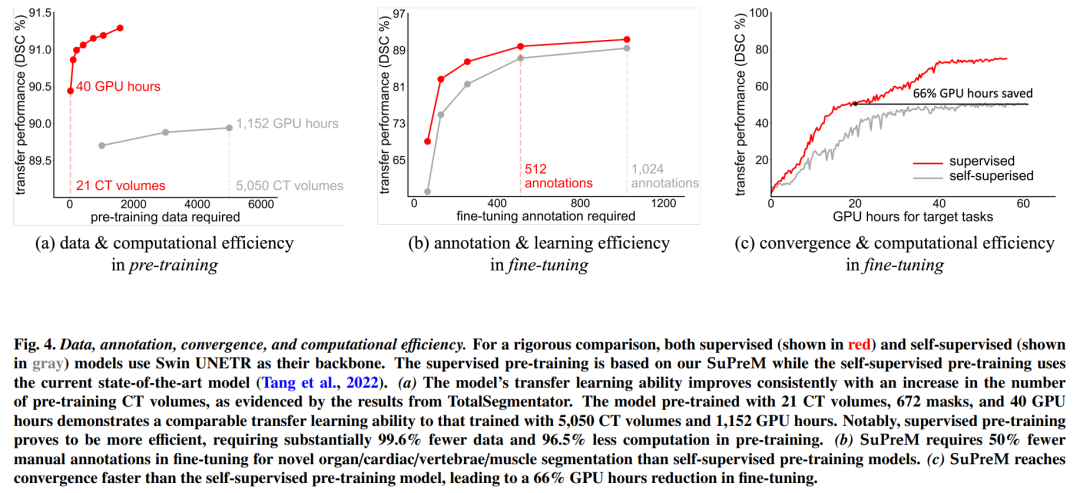
迁移学习效率的评估:
- 比较SuPreM模型与现有自监督预训练模型在数据效率、注释效率和计算效率方面的表现。
-
少样本学习场景下的迁移能力:
- 在有限的标注CT体积(N = 5, 10, 20)的情况下,评估SuPreM模型在私有数据集上的迁移性能。
-
新类别分割的迁移能力:
- 将SuPreM模型迁移到未在预训练中见过的新型胰腺肿瘤类别的分割任务上,并与自监督模型进行比较。
-
细粒度肿瘤识别的迁移能力:
- 评估SuPreM模型在从解剖结构分割迁移到细粒度肿瘤亚型分类任务上的迁移学习能力。
-
BodyMaps挑战赛的组织:
- 使用AbdomenAtlas数据集组织了一个名为BodyMaps的医学分割挑战赛,以评估AI算法在临床设置中的实用性、效率和可靠性。
这些实验不仅展示了AbdomenAtlas数据集的质量和多样性,而且证明了SuPreM模型在不同医学图像分析任务中的有效性和优越的迁移学习能力。通过这些实验,论文为医学图像分析领域提供了一个强大的基准和工具。
论文的主要内容:
这篇论文介绍了一个名为"AbdomenAtlas"的大型、详细注释的多中心CT扫描数据集,旨在推动医学图像分析领域的发展,特别是在计算机视觉和人工智能的应用方面。以下是论文的主要内容概述:
-
数据集创建:AbdomenAtlas包含20,460个三维CT体积,涵盖了来自112家医院的不同人群、地理和设施。这些数据由10位放射科医生在AI算法辅助下进行了673K个高质量解剖结构掩膜的注释。
-
注释方法:数据集的注释采用了专家放射科医生的手动注释和半自动注释程序相结合的方法。手动注释确保了注释质量,而半自动注释程序通过AI预测和医生修订相结合的方式提高了注释效率。
-
AI模型开发:利用AbdomenAtlas数据集,研究者开发了一套名为SuPreM的预训练模型,这些模型在多种下游任务中表现出高效的迁移学习能力。
-
基准测试:通过与ISBI和MICCAI合作组织的BodyMaps挑战赛,AbdomenAtlas为评估AI算法在医学图像分割中的准确性、推理效率和领域泛化能力提供了一个开放的基准测试平台。
-
数据集多样性:AbdomenAtlas在患者性别、年龄、扫描仪类型以及成像协议方面展现了显著的多样性,有助于提高AI算法的泛化能力和适应性。
-
实验验证:论文通过一系列实验验证了AbdomenAtlas数据集和SuPreM模型的有效性,包括迁移学习效率、少样本学习场景下的迁移能力、新类别分割和细粒度肿瘤识别的迁移能力。
-
未来探索:论文提出了未来研究的方向,包括扩展肿瘤注释、多模态数据集整合、提高AI算法泛化性、临床集成、解释性和可信赖性、安全性和隐私保护、公平性和偏见减少、不同疾病状态的表现、实时性能以及跨学科应用。
-
资源可用性:论文提供了相关代码、模型和数据集的访问链接,以促进社区的进一步研究和开发。
总的来说,这篇论文通过创建一个大规模、高质量的医学图像数据集,并基于此数据集开发了一系列预训练模型和基准测试,为医学图像分析领域的AI研究提供了重要的资源和工具。
3.PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects

标题: PartGLEE:识别和解析任何对象的基础模型
作者:Junyi Li, Junfeng Wu, Weizhi Zhao, Song Bai, Xiang Bai
文章链接:https://arxiv.org/abs/2407.16696
项目代码:https://provencestar.github.io/PartGLEE-Vision/




摘要:
我们提出了 PartGLEE,一个用于定位和识别图像中的对象和零件的零件级基础模型。 PartGLEE通过统一的框架,完成开放世界场景下任意粒度的实例检测、分割和接地。具体来说,我们提出了 Q-Former 来构建对象和部分之间的层次关系,将每个对象解析为相应的语义部分。通过合并大量对象级数据,可以扩展层次关系,使 PartGLEE 能够识别丰富多样的零件。我们进行了全面的研究来验证我们方法的有效性,PartGLEE 在各种零件级任务上实现了最先进的性能,并在对象级任务上获得了有竞争力的结果。与我们之前的 GLEE 模型相比,所提出的 PartGLEE 显着增强了分层建模能力和零件级感知。进一步的分析表明,PartGLEE 的分层认知能力能够促进 mLLM 对图像的详细理解。模型和代码将在此 https URL发布。
这篇论文试图解决什么问题?
这篇论文提出了PartGLEE,一个用于识别和解析图像中任意对象及其部分的基线模型。它试图解决的问题主要包括:
-
层次化理解:大多数现有的视觉模型缺乏对对象和它们部分之间层次关系的理解能力。PartGLEE旨在通过建立对象和部分之间的层次关系,使模型能够理解对象的内在联系,并将这种层次联系扩展到任何新的对象上。
-
语义粒度:模型应该能够学习到一种通用的特征表示,使其能够识别任何粒度的语义实例。
-
数据限制:相比于丰富的对象级别数据,部分级别数据的规模相对较小,这限制了视觉模型识别部分级别实例的能力。PartGLEE通过引入大量对象级别数据,扩展了层次关系,从而克服了部分级别数据稀缺的限制。
-
开放世界场景下的性能:在开放世界场景中,模型需要能够处理各种未见过的对象和部分,PartGLEE通过层次化建模和部分级别的感知能力,提升了在这些任务上的性能。
-
多模态大型语言模型(mLLMs)的详细理解:PartGLEE的层次化认知能力还能促进mLLMs对图像内容的更详细理解。
总的来说,PartGLEE通过其统一框架,旨在实现对图像中对象和部分的检测、分割和定位,以支持各种粒度的实例识别,并在开放世界场景中提供先进的性能。
论文如何解决这个问题?
论文通过提出PartGLEE模型来解决上述问题,具体方法包括:
-
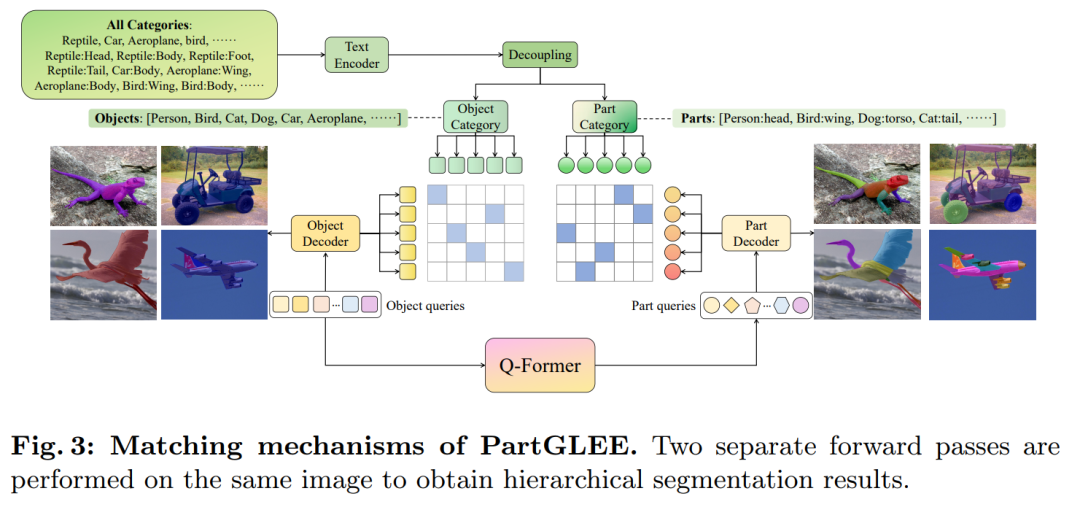
层次关系构建(Q-Former):提出了一个轻量级的Querying Transformer(Q-Former),用于构建对象和部分之间的层次关系。Q-Former使用一组通用的解析查询与对象查询进行交互,生成能够预测每个对象对应语义部分的部分级查询。
-
统一框架:PartGLEE通过一个统一的框架实现对象和部分的检测、分割和定位。这个框架包括图像编码器、Q-Former、两个独立的解码器和文本编码器。
-
数据融合:为了训练Q-Former,论文将大量对象级别的数据与部分级别的数据结合起来,以标准化不同部分级别数据集的注释粒度,并引入相应的对象级别注释,补充层次对应关系。
-
联合训练:PartGLEE在丰富的对象级别数据和有限的层次数据上进行联合训练,使得Q-Former能够学习如何将任何新对象解析为其相应的部分。
-
限制损失(Restriction Loss):引入了一种新的损失函数,用于确保部分级预测是对象级预测的组成部分,加强不同层次之间的相互对应关系。
-
跨数据集和跨类别的实验验证:在多个流行的数据集上进行了广泛的实验,包括跨数据集和跨类别的方式,验证了模型在识别新对象的各种部分方面的泛化性能。
-
分解能力评估:在ADE20K-Part和Pascal Part数据集上进行了实验,以评估模型的分解能力,结果表明PartGLEE在层次化建模方面取得了显著的性能提升。
通过这些方法,PartGLEE能够在开放世界场景中实现对对象和部分的识别和解析,同时在对象级别和部分级别任务上都取得了良好的性能。
论文做了哪些实验?
论文中进行了多种实验来验证PartGLEE模型的有效性,这些实验包括:
-
跨数据集零样本部分分割(Cross-dataset Generalization Performance):
-
在PartImageNet验证集上直接评估模型的跨数据集泛化性能。
-
使用Pascal Part数据集训练,并在PartImageNet上进行零样本测试。
-
-
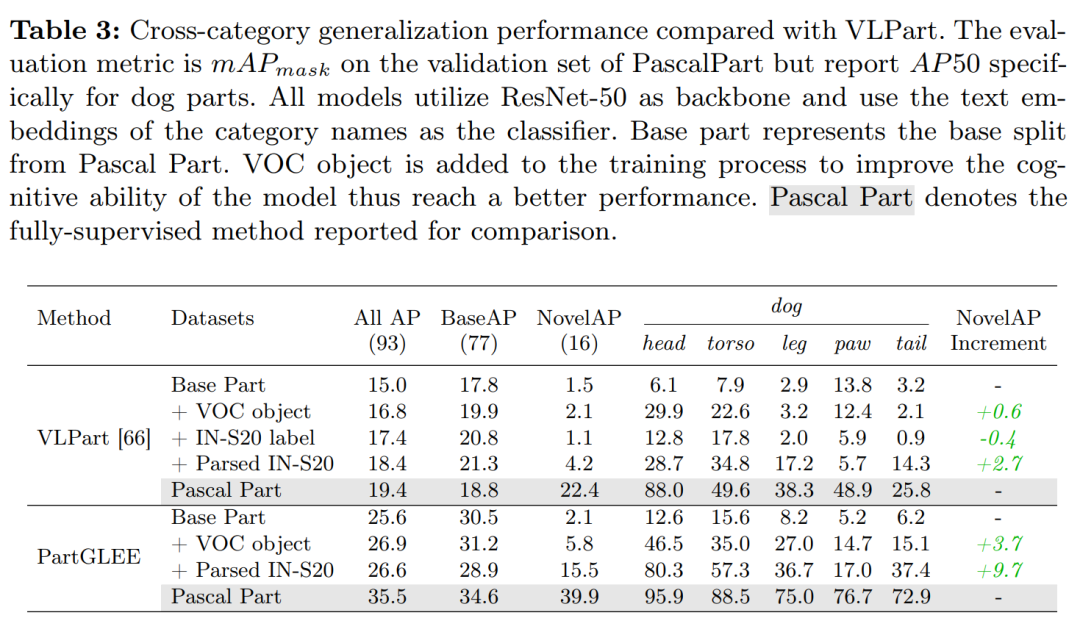
跨类别泛化性能(Cross-category Generalization Performance):
- 在Pascal Part数据集上评估模型的跨类别泛化性能,将93个部分类别分为77个基础类别和16个新颖类别。
-
泛化零样本部分分割(Generalized Zero-shot Part Segmentation):
- 在ADE-Part-234和Pascal-Part-116数据集上进行实验,使用Oracle-Obj设置,假设在推理过程中已知对象级别的真实遮罩和类别。
-
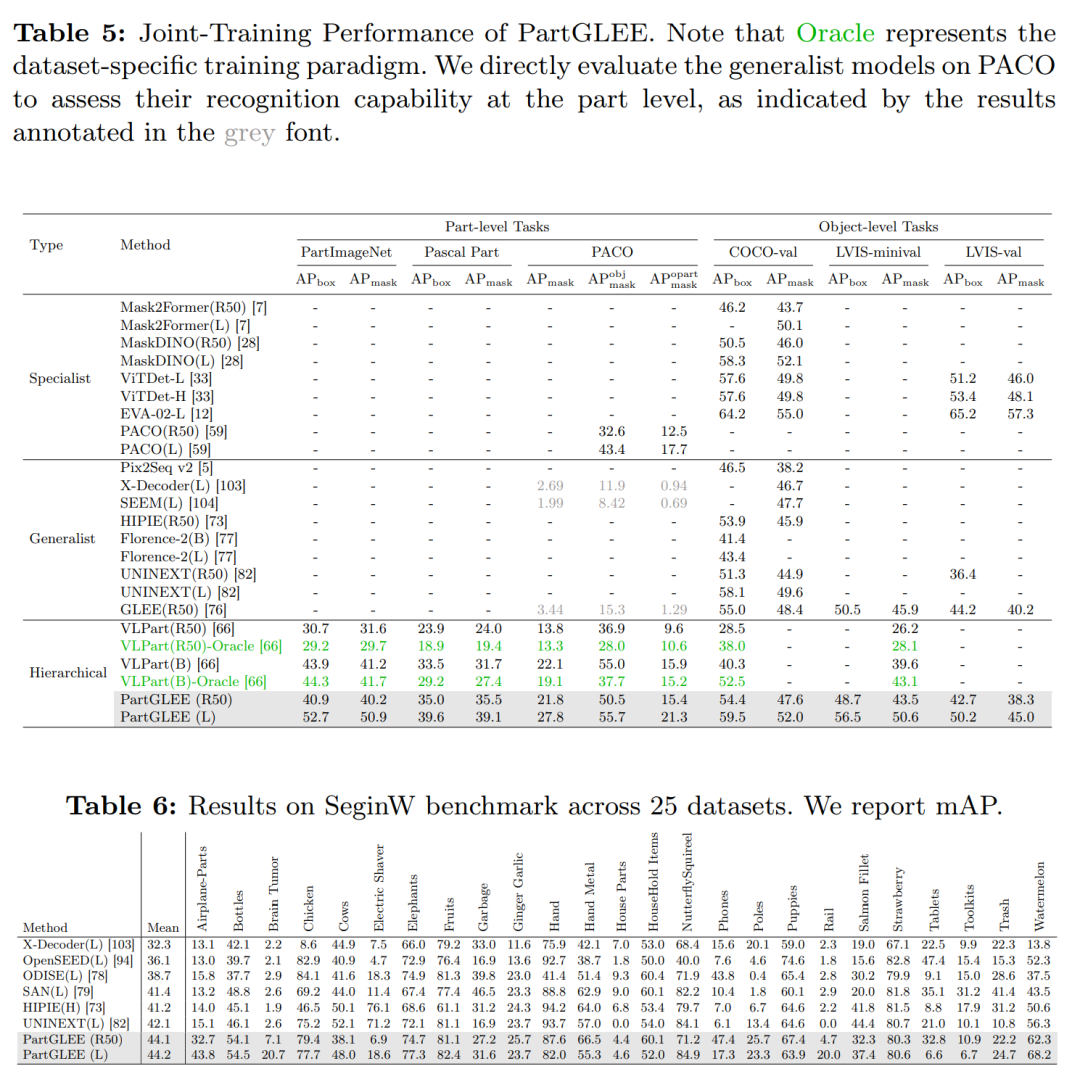
联合训练结果(Joint-training Results):
-
在多种数据集上进行联合训练,并在对象级别和部分级别任务上评估模型性能。
-
与专家模型(specialist models)和通用模型(generalist models)进行比较。
-
-
SeginW基准测试(Segmentation Result on SeginW Benchmark):
- 在包含25个不同分割数据集的Segmentation in the Wild(SeginW)基准上评估模型的零样本迁移能力。
-
消融研究(Ablation Study):
- 对模型架构进行消融研究,包括不同的模型设计和超参数选择。
-
层次化分割结果(Hierarchical Segmentation Results):
- 展示了模型将任何对象解析为其语义部分的过程。
-
mLLMs的实验(Experiment on mLLMs):
- 探索了细粒度视觉提示对mLLMs(如GPT4V)在图像理解方面的影响。
这些实验全面评估了PartGLEE在不同层次的任务上的性能,包括对象级别的检测和分割,以及部分级别的分割。实验结果表明,PartGLEE在各种任务上都取得了良好的性能,证明了其作为一种基础模型在图像中对象和部分识别方面的有效性。
论文的主要内容:
论文提出了PartGLEE,这是一个用于识别和解析图像中任意对象及其部分的基础模型。以下是论文的主要内容总结:
-
模型介绍:PartGLEE通过统一框架实现对象和部分的检测、分割和定位,能够在开放世界场景中识别和理解不同粒度的实例。
-
Q-Former:提出了一个查询转换器(Q-Former),用于建立对象和部分之间的层次关系,将对象解析为对应的语义部分。
-
层次化认知:PartGLEE强调模型应具有层次化理解能力,能够理解对象与部分之间的内在联系,并将这种联系扩展到新对象上。
-
数据融合:为了训练Q-Former,论文将对象级别的数据与部分级别的数据结合起来,标准化了不同数据集的注释粒度,并补充了层次对应关系。
-
联合训练:模型在丰富的对象级数据和有限的层次数据上进行联合训练,以提高对新对象的泛化能力。
-
限制损失:引入了一种新的损失函数,用于确保部分级预测是对象级预测的组成部分,加强了不同层次之间的相互对应关系。
-
实验验证:在多个数据集上进行了广泛的实验,验证了PartGLEE在对象级别和部分级别任务上的性能,包括跨数据集和跨类别的测试。
-
零样本分割:PartGLEE在ADE-Part-234和Pascal-Part-116数据集上进行了零样本分割实验,展示了其在新颖对象上的泛化能力。
-
SeginW基准测试:在Segmentation in the Wild(SeginW)基准上评估了模型的零样本迁移能力。
-
消融研究:对模型的不同组件和设计选择进行了消融研究,以展示其对性能的影响。
-
mLLMs的应用:探索了PartGLEE如何促进多模态大型语言模型(mLLMs)对图像内容的更详细理解。
-
结论与未来工作:论文总结了PartGLEE的主要贡献,并提出了未来可能的研究方向。
PartGLEE模型的提出,为图像中对象和部分的识别与解析提供了一种新的方法,通过层次化建模和广泛的数据融合,显著提高了模型的泛化能力和细粒度感知能力。