1、LoRA
LoRA(Low-RankAdaptation)是一种旨在微调大型预训练语言模型(如GPT-3或BERT)的技术。
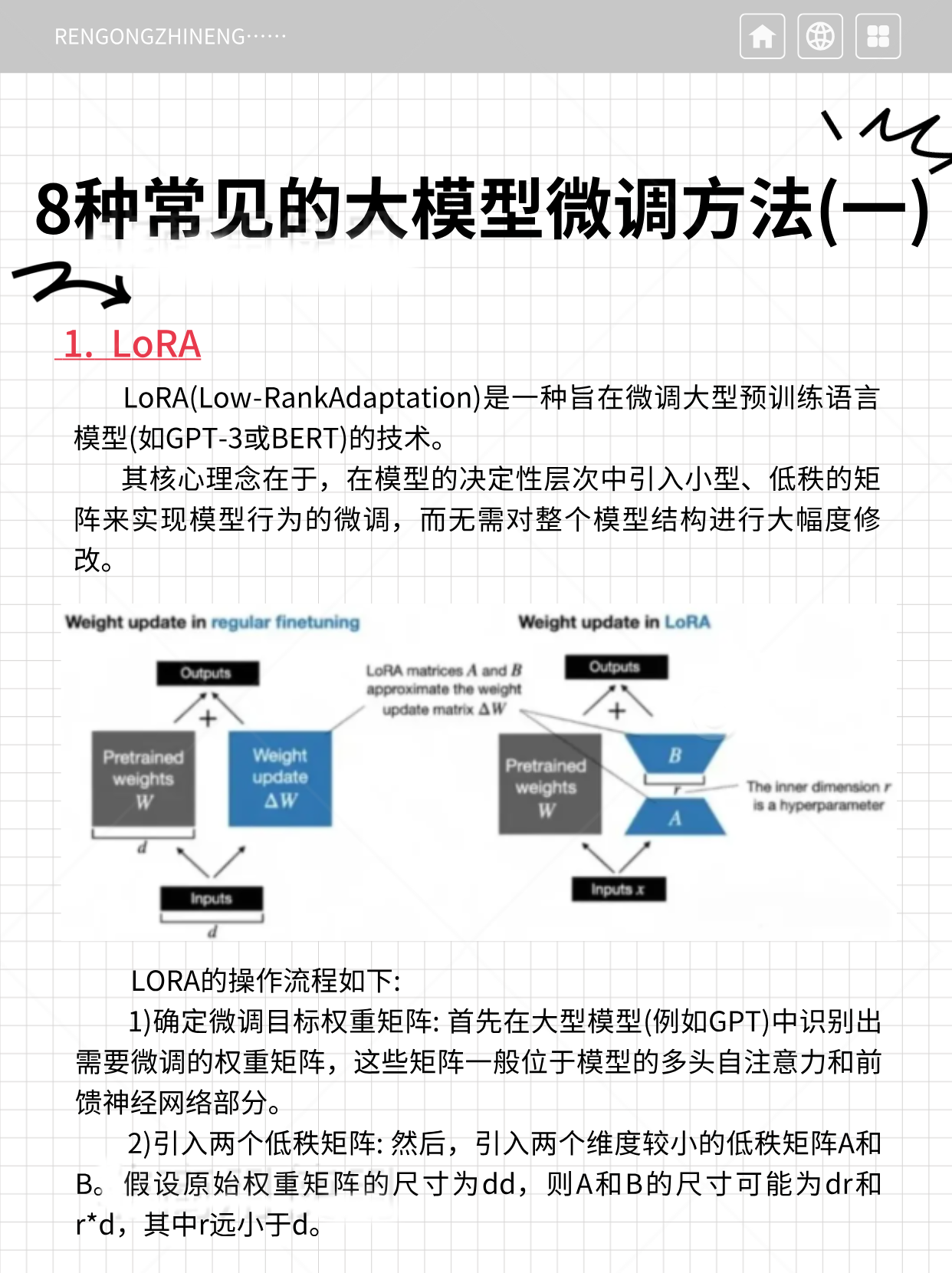
其核心理念在于,在模型的决定性层次中引入小型、低秩的矩阵来实现模型行为的微调,而无需对整个模型结构进行大幅度修改。
这种方法的优势在于,在不显著增加额外计算负担的前提下,能够有效地微调模型,同时保留模型原有的性能水准。
LORA的操作流程如下:
1)确定微调目标权重矩阵: 首先在大型模型(例如GPT)中识别出需要微调的权重矩阵,这些矩阵一般位于模型的多头自注意力和前馈神经网络部分。
2)引入两个低秩矩阵: 然后,引入两个维度较小的低秩矩阵A和B。假设原始权重矩阵的尺寸为dd,则A和B的尺寸可能为dr和r*d,其中r远小于d。
3)计算低秩更新: 通过这两个低秩矩阵的乘积AB来生成一个新矩阵,其秩(即r)远小于原始权重矩阵的秩。这个乘积实际上是对原始权重矩阵的一种低秩近似调整。
4)结合原始权重: 最终,新生成的低秩矩阵AB被叠加到原始权重矩阵上。因此,原始权重经过了微调,但大部分权重维持不变。
这个过程可以用数学表达式描述为: 新权重=原始权重+AB。
2、QLORA
OLoRA(Quantized Low-RankAdaptation)是一种结合了LORA(Low-RankAdaptation)方法与深度量化技术的高效模型微调手段。QLORA的核心在于:
1)量化技术:QLORA通过双阶段数值编码方案实现参数高效压缩,其核心包含存储环节的4-bit NormalFloat标准化浮点格式与计算环节的16-bit BrainFloat运算架构。
这种混合精度处理机制在保证神经网络计算稳定性的前提下,将模型参数存储密度提升300%,通过动态反量化策略维持了原始模型97%以上的表征能力。
相较于传统量化方法,该方案在显著降低存储资源占用的同时,构建了精度损失与硬件效能的最优平衡模型。
2)量化操作:在4-bit精度量化中,权重参数通过4比特二进制编码表征,其核心流程是通过特征值筛选与区间映射实现数据压缩。
首先基于张量分布特性划定动态范围边界(如-0.8,0.8),将该连续空间均等划分为16个离散子域,每个子域对应唯一的4-bit编码值。
最终通过最近邻匹配原则,将原始FP32精度数值投影至最邻近的离散量化点上,完成32位浮点数值到4位定点表示的精度转换。
3)微调阶段:在参数优化过程中,OLORA采用4-bit精度加载模型参数,通过动态反量化至bf16格式进行梯度计算,这种混合精度策略有效节省了83%的显存占用。
实际测试表明,该方法使得原本需要80GB显存的LLaMA-33B大模型,仅需单张RTX 4090显卡即可完成全参数微调。