机器学习基本术语:
数据集
数据记录的集合称为一个"数据集" (data set)
样本
数据集中每条记录是关于一个事件或对象的描述,称为"样本"
特征
反映事件或对象在某方面的表现或性质的事项,例如"色泽"
属性空间
属性张成的空间称为"属性空间" 或"样本空间
向量
一般地,令D = {x1 x2.. xm } 表示包含m 个示例的数据集,每个样本由d 个属性描述,则每个样本xi = (xi1; xi2; . . . ; xid) 是d 维样本空间X中的一个向量,d 称为样本Xi的"维数"
训练集:机器学习中用于训练模型的数据集合,包含标记信息
测试集:机器学习中用于测试模型的数据集合
监督学习:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。
监督学习的数据集由"正确答案"(标记)组成。
监督学习分为两大类
分类:机器学习模型输出的结果被限定为有限的一组值,即离散型数值。
回归:机器学习模型的输出可以是某个范围内的任何数值,即连续型数值。
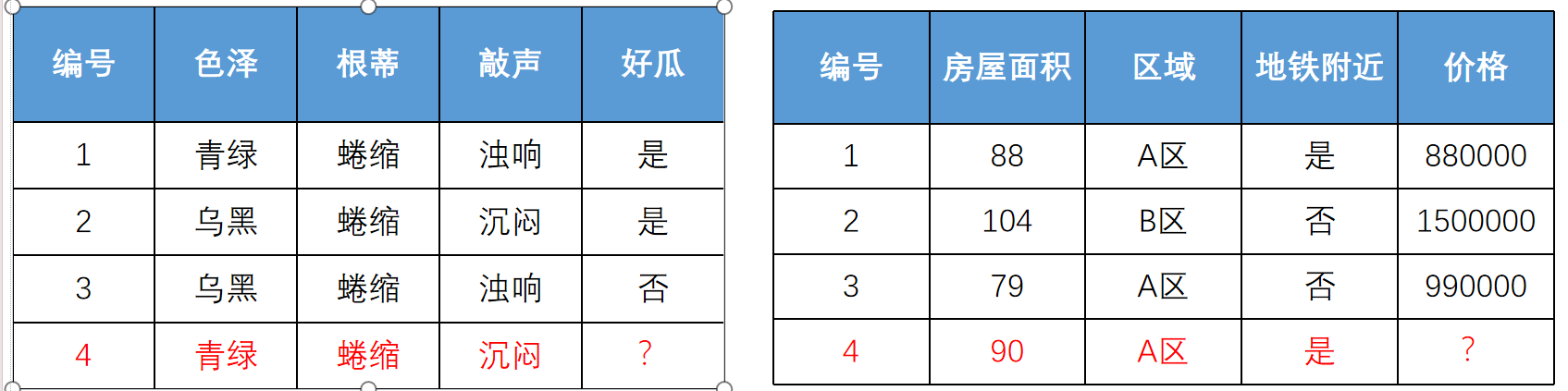
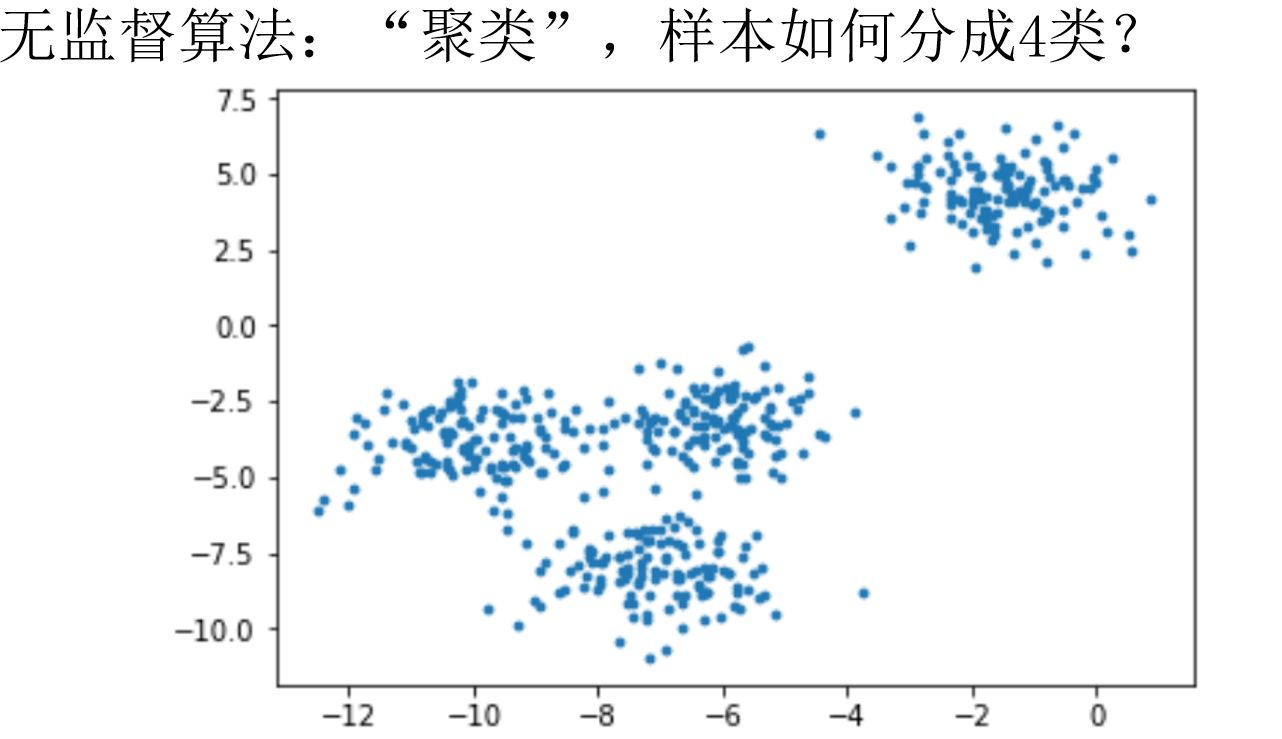
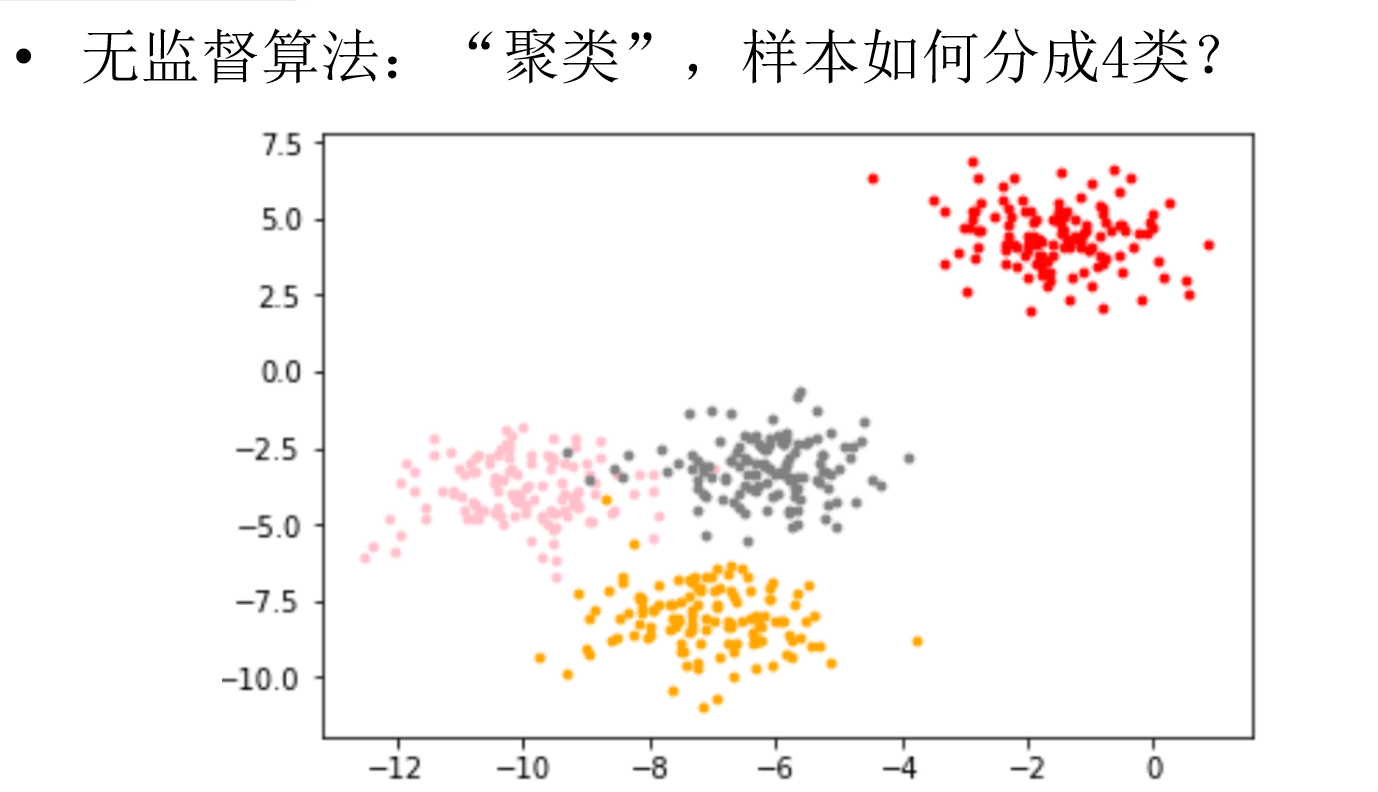
无监督学习:提供数据集合但是不提供标记信息的学习过程
模型评估与选择
残差:学习器的实际预测输出与样本的真实输出之间的差异
学习器在训练集上的误差称为"训练误差"或"经验误差"
学习器在新样本上的误差称为"泛化误差"
欠拟合:模型没有很好的捕捉到数据特征、特征集过小导致模型不能很好的拟合数据。欠拟合本质上是对数据特征学习的不够
过拟合:把训练数据学习的太彻底,以至于把噪声数据的特征也学习到了,特征集过大,这样就会导致在后期测试的时候不能够很好的识别数据,不能正确的分类,模型泛化能力太差。
过拟合的处理方式: 1. 增加训练数据:更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响。 2. 降维:即丢弃一些不能帮助我们正确预测的特征。 3. 正则化(regularization)的技术,保留所有的特征,但是减少参数的大小(magnitude),它可以改善或者减少过拟合问题。 4. 集成学习方法:集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险。
欠拟合的处理方式: 1. 添加新特征,当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。 2. 增加模型复杂度:简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。 3. 减小正则化系数:正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数。
模型评估:
TP(True positive,真正例)------将正类预测为正类数。
FP(False postive,假正例)------将反类预测为正类数。
TN(True negative,真反例)------将反类预测为反类数。
FN(False negative,假反例)------将正类预测为反类数。
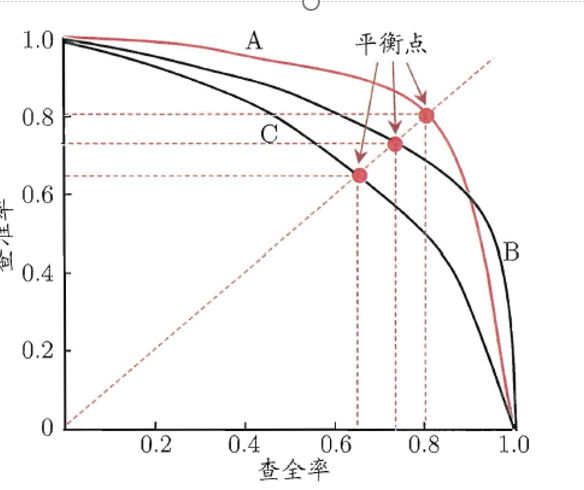
P-R 图直观地显示出学习器在样本总体上的查全率、查准率。在进行比较时,若一个学习器的P-R 曲线被另一个学习器的曲线完全"包住",则可断言后者的性能优于前者 图中学习器A 的性能优于学习器C;如果两个学习器的P-R 曲线发生了交叉,图中的A 与B ,则难以一般性地断言两者孰优孰劣。