使用扩展正则表达式 egrep
首先来看一条前面章节学习过的用来去除空白行和注释行的指令:
bash
grep -v '^$' regular_express.txt |grep -v '^#'可见,通常的 grep 指令需要使用两次管线命令。那么如果使用扩展正则表达式,则可以简化为:
bash
egrep -v '^$|^#' regular_express.txt利用支持扩展正则表达式的 egrep 与特殊字符 | 的组合功能来间隔两组字符串,如此一来,可以极大地化简指令。
此外,也可以使用 grep -E 来使用扩展正则表达式,不过一般更建议直接使用 egrep,grep -E 与 egrep 之间类似命令别名的关系。
扩展规则(一)
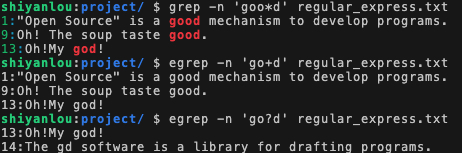
回忆一下,在非扩展正则表达式中,我们使用 * 来表示任意个重复字符(零至无穷多个):
bash
grep -n 'goo*d' regular_express.txt在扩展正则表达式中,则可以进一步细分为一个或一个以上 和零个或一个字符:
+ 表示重复一个或一个以上的前一个字符
bash
egrep -n 'go+d' regular_express.txt? 表示重复零个或一个的前一个字符
bash
egrep -n 'go?d' regular_express.txt执行上述三条指令,比较三者的不同。
扩展规则(二)
| 表示用或(or)的方式找出数个字符串
查找 gd 或 good:
bash
egrep -n 'gd|good' regular_express.txt() 表示找出组字符串
查找 glad 或 good,注意到由于二者存在重复字母,所以可以将其合并:
bash
egrep -n 'g(la|oo)d' regular_express.txt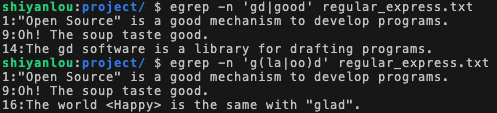
()+ 多个重复群组判别
查找开头是 A 结尾是 C 中间有一个以上的 xyz 或 xz 字符串:
bash
echo 'AxyzxyzxyzxyzC'|egrep 'A(xyz)+C'
echo 'AxyzxyzxyzxyzC'|egrep 'A(xz)+C'结果显示 A(xyz)+C 可以匹配,A(xz)+C 没有匹配项。

至此,关于正则表达式的基本知识就介绍完了,希望同学们多加练习,最终能够熟练地运用所学的关于正则表达式的知识,达到简化字符串处理的目的。