在前面的系列文章中,我们深入探讨了数据驱动决策的各个方面。现在,是时候将这些知识付诸实践了。本文将通过一个虚构但贴近现实的案例,展示如何在一个组织中实施数据驱动决策,同时我们将讨论在这个过程中可能遇到的挑战和解决方案。

目录
-
- 案例背景:电子商务公司 "TechMart"
- [1. 确定业务目标和关键问题](#1. 确定业务目标和关键问题)
- [2. 评估数据准备情况](#2. 评估数据准备情况)
- [3. 数据收集和整合](#3. 数据收集和整合)
- [4. 数据分析和洞察发现](#4. 数据分析和洞察发现)
- [5. 制定数据驱动的策略](#5. 制定数据驱动的策略)
- [6. 实施和监控](#6. 实施和监控)
- [7. 持续优化和学习](#7. 持续优化和学习)
- [8. 实施过程中的挑战和解决方案](#8. 实施过程中的挑战和解决方案)
- [9. 数据安全和隐私问题](#9. 数据安全和隐私问题)
- 实施成果
- 经验总结
- 未来展望
- 结语
案例背景:电子商务公司 "TechMart"
TechMart 是一家中型电子商务公司,主要销售电子产品。公司最近面临增长放缓和客户流失率上升的问题。管理层决定采用数据驱动方法来解决这些问题。让我们跟随 TechMart 的journey,看看他们如何实施数据驱动决策。
1. 确定业务目标和关键问题

第一步是明确我们想要解决的具体问题。
python
class BusinessObjective:
def __init__(self, name, description, metrics):
self.name = name
self.description = description
self.metrics = metrics
def __str__(self):
return f"Objective: {self.name}\nDescription: {self.description}\nMetrics: {', '.join(self.metrics)}"
# TechMart的业务目标
objectives = [
BusinessObjective("提高客户留存率", "在未来6个月内将客户流失率降低15%", ["客户流失率", "客户生命周期价值"]),
BusinessObjective("增加平均订单价值", "在未来3个月内将平均订单价值提高10%", ["平均订单价值", "交叉销售率"]),
BusinessObjective("优化营销支出", "提高营销ROI 20%", ["营销ROI", "客户获取成本"])
]
for objective in objectives:
print(objective)
print("---")2. 评估数据准备情况

在开始分析之前,我们需要评估现有的数据资产和基础设施。
python
def assess_data_readiness(data_sources, required_data):
readiness_score = 0
missing_data = []
for data in required_data:
if data in data_sources:
readiness_score += 1
else:
missing_data.append(data)
readiness_percentage = (readiness_score / len(required_data)) * 100
return {
"readiness_score": readiness_percentage,
"missing_data": missing_data
}
# TechMart的数据源
data_sources = ["客户信息", "订单历史", "网站点击流", "客户服务记录"]
# 所需数据
required_data = ["客户信息", "订单历史", "网站点击流", "营销活动数据", "产品库存数据"]
readiness = assess_data_readiness(data_sources, required_data)
print(f"数据准备情况: {readiness['readiness_score']}%")
print(f"缺失数据: {', '.join(readiness['missing_data'])}")3. 数据收集和整合

基于评估结果,TechMart 需要收集额外的数据并将所有数据整合到一个统一的平台。
python
import pandas as pd
from sklearn.impute import SimpleImputer
def integrate_data(data_sources):
# 模拟数据整合过程
integrated_data = pd.DataFrame()
for source in data_sources:
# 在实际情况中,这里会是从不同源读取数据的代码
source_data = pd.read_csv(f"{source.lower().replace(' ', '_')}.csv")
integrated_data = pd.concat([integrated_data, source_data], axis=1)
# 处理缺失值
imputer = SimpleImputer(strategy='mean')
integrated_data = pd.DataFrame(imputer.fit_transform(integrated_data), columns=integrated_data.columns)
return integrated_data
# 使用示例
integrated_data = integrate_data(data_sources)
print(integrated_data.head())
print(f"整合后的数据维度: {integrated_data.shape}")4. 数据分析和洞察发现

现在我们有了整合的数据,可以开始进行分析了。
python
import matplotlib.pyplot as plt
import seaborn as sns
def analyze_customer_churn(data):
# 计算流失率
churn_rate = data['churned'].mean()
# 分析流失客户的特征
churned_customers = data[data['churned'] == 1]
loyal_customers = data[data['churned'] == 0]
# 比较平均订单价值
avg_order_value_churned = churned_customers['avg_order_value'].mean()
avg_order_value_loyal = loyal_customers['avg_order_value'].mean()
# 可视化
plt.figure(figsize=(12, 6))
sns.histplot(data=data, x='avg_order_value', hue='churned', kde=True)
plt.title('Average Order Value Distribution: Churned vs Loyal Customers')
plt.show()
return {
"churn_rate": churn_rate,
"avg_order_value_churned": avg_order_value_churned,
"avg_order_value_loyal": avg_order_value_loyal
}
# 使用示例
churn_analysis = analyze_customer_churn(integrated_data)
print(f"客户流失率: {churn_analysis['churn_rate']:.2%}")
print(f"流失客户的平均订单价值: ${churn_analysis['avg_order_value_churned']:.2f}")
print(f"忠诚客户的平均订单价值: ${churn_analysis['avg_order_value_loyal']:.2f}")5. 制定数据驱动的策略

基于分析结果,TechMart 可以制定针对性的策略。
python
def develop_strategies(analysis_results):
strategies = []
if analysis_results['avg_order_value_churned'] < analysis_results['avg_order_value_loyal']:
strategies.append("实施个性化的促销活动,针对低价值客户提高其平均订单价值")
if analysis_results['churn_rate'] > 0.1: # 假设10%是可接受的流失率
strategies.append("建立预警系统,识别可能流失的客户并采取挽留措施")
strategies.append("优化产品推荐系统,提高交叉销售和追加销售")
return strategies
# 使用示例
strategies = develop_strategies(churn_analysis)
for i, strategy in enumerate(strategies, 1):
print(f"策略 {i}: {strategy}")6. 实施和监控

制定策略后,下一步是实施这些策略并持续监控其效果。
python
import random
from datetime import datetime, timedelta
class Strategy:
def __init__(self, name, implementation_date):
self.name = name
self.implementation_date = implementation_date
self.kpi_values = {}
def track_kpi(self, kpi_name, value, date):
if kpi_name not in self.kpi_values:
self.kpi_values[kpi_name] = []
self.kpi_values[kpi_name].append((date, value))
def monitor_strategy_performance(strategies, start_date, end_date):
current_date = start_date
while current_date <= end_date:
for strategy in strategies:
if current_date >= strategy.implementation_date:
# 模拟KPI数据
churn_rate = random.uniform(0.05, 0.15)
avg_order_value = random.uniform(80, 120)
strategy.track_kpi("churn_rate", churn_rate, current_date)
strategy.track_kpi("avg_order_value", avg_order_value, current_date)
current_date += timedelta(days=1)
# 使用示例
start_date = datetime(2023, 1, 1)
end_date = datetime(2023, 3, 31)
implemented_strategies = [
Strategy("个性化促销活动", datetime(2023, 1, 15)),
Strategy("客户流失预警系统", datetime(2023, 2, 1)),
Strategy("优化产品推荐", datetime(2023, 2, 15))
]
monitor_strategy_performance(implemented_strategies, start_date, end_date)
# 可视化策略效果
plt.figure(figsize=(12, 6))
for strategy in implemented_strategies:
dates, values = zip(*strategy.kpi_values["churn_rate"])
plt.plot(dates, values, label=strategy.name)
plt.title("策略实施后的客户流失率变化")
plt.xlabel("日期")
plt.ylabel("客户流失率")
plt.legend()
plt.show()7. 持续优化和学习
数据驱动决策是一个持续的过程。基于监控结果,TechMart 需要不断调整和优化其策略。
python
def evaluate_and_adjust_strategies(strategies, target_improvement):
adjustments = []
for strategy in strategies:
initial_churn_rate = strategy.kpi_values["churn_rate"][0][1]
final_churn_rate = strategy.kpi_values["churn_rate"][-1][1]
improvement = (initial_churn_rate - final_churn_rate) / initial_churn_rate
if improvement < target_improvement:
adjustments.append(f"加强 {strategy.name}: 当前改善 {improvement:.2%}, 目标 {target_improvement:.2%}")
else:
adjustments.append(f"保持 {strategy.name}: 当前改善 {improvement:.2%}, 达到目标")
return adjustments
# 使用示例
target_improvement = 0.15 # 15%的改善目标
strategy_adjustments = evaluate_and_adjust_strategies(implemented_strategies, target_improvement)
for adjustment in strategy_adjustments:
print(adjustment)8. 实施过程中的挑战和解决方案
在实施数据驱动决策的过程中,TechMart 遇到了一些常见的挑战。让我们来看看这些挑战以及相应的解决方案:
- 数据质量问题
挑战:在整合数据时,发现不同系统的数据存在不一致和缺失。

解决方案:
- 实施数据治理政策
- 使用ETL工具进行数据清洗和转换
- 建立数据质量监控系统
python
def data_quality_check(data, rules):
quality_issues = []
for column, rule in rules.items():
if rule == "no_nulls" and data[column].isnull().sum() > 0:
quality_issues.append(f"列 '{column}' 存在空值")
elif rule == "unique" and data[column].nunique() != len(data):
quality_issues.append(f"列 '{column}' 存在重复值")
return quality_issues
# 使用示例
quality_rules = {
"customer_id": "unique",
"email": "no_nulls",
"purchase_date": "no_nulls"
}
issues = data_quality_check(integrated_data, quality_rules)
for issue in issues:
print(f"数据质量问题: {issue}")- 技能缺口

挑战:团队缺乏高级数据分析技能。
解决方案:
- 投资员工培训
- 招募数据科学家
- 与外部咨询公司合作
python
def assess_team_skills(team_members, required_skills):
skill_gap = {skill: 0 for skill in required_skills}
for member in team_members:
for skill in member['skills']:
if skill in skill_gap:
skill_gap[skill] += 1
missing_skills = [skill for skill, count in skill_gap.items() if count == 0]
return missing_skills
# 使用示例
team = [
{"name": "Alice", "skills": ["SQL", "Python", "Data Visualization"]},
{"name": "Bob", "skills": ["Data Analysis", "Statistics", "R"]},
{"name": "Charlie", "skills": ["Machine Learning", "Python", "Big Data"]}
]
required_skills = ["SQL", "Python", "Machine Learning", "A/B Testing", "Deep Learning"]
missing_skills = assess_team_skills(team, required_skills)
print(f"团队技能缺口: {', '.join(missing_skills)}")- 文化阻力

挑战:某些部门习惯于基于直觉做决策,对数据驱动方法持怀疑态度。
解决方案:
- 高管层的支持和倡导
- 展示早期的成功案例
- 逐步引入数据驱动的决策流程
python
def culture_change_program():
initiatives = [
"组织数据驱动决策工作坊",
"建立数据冠军网络",
"实施数据驱动决策奖励计划",
"创建和分享数据驱动成功案例",
"将数据素养纳入绩效评估"
]
return initiatives
# 使用示例
change_program = culture_change_program()
print("文化转型计划:")
for i, initiative in enumerate(change_program, 1):
print(f"{i}. {initiative}")非常好,让我们继续探讨 TechMart 在实施数据驱动决策过程中的其他挑战和解决方案,以及最终的成果和经验总结。
## 4. 技术基础设施限制
挑战:现有的IT基础设施无法支持大规模的数据处理和实时分析。
解决方案:
- 评估并升级数据基础设施
- 考虑采用云计算解决方案
- 实施数据湖架构
```python
def assess_infrastructure(current_setup, requirements):
gaps = []
for req, needed_capacity in requirements.items():
if req not in current_setup or current_setup[req] < needed_capacity:
gaps.append(f"需要升级 {req}: 当前 {current_setup.get(req, 0)}, 需要 {needed_capacity}")
return gaps
# 使用示例
current_infrastructure = {
"存储容量": 100, # TB
"处理能力": 1000, # 每秒事务数
"数据库类型": "关系型"
}
requirements = {
"存储容量": 500, # TB
"处理能力": 5000, # 每秒事务数
"数据库类型": "关系型 + NoSQL",
"实时处理": "必需"
}
infrastructure_gaps = assess_infrastructure(current_infrastructure, requirements)
for gap in infrastructure_gaps:
print(gap)9. 数据安全和隐私问题

挑战:随着数据使用的增加,确保数据安全和用户隐私变得更加复杂。
解决方案:
- 实施强大的数据加密措施
- 建立细粒度的访问控制
- 进行定期的安全审计
- 遵守数据保护法规(如GDPR)
python
import hashlib
def encrypt_sensitive_data(data, sensitive_columns):
for column in sensitive_columns:
if column in data:
data[column] = data[column].apply(lambda x: hashlib.sha256(str(x).encode()).hexdigest())
return data
# 使用示例
sensitive_columns = ['email', 'phone_number', 'credit_card']
encrypted_data = encrypt_sensitive_data(integrated_data, sensitive_columns)
print(encrypted_data[sensitive_columns].head())
def data_access_control(user_role, data_sensitivity):
access_matrix = {
"analyst": ["low", "medium"],
"manager": ["low", "medium", "high"],
"admin": ["low", "medium", "high", "very_high"]
}
return data_sensitivity in access_matrix.get(user_role, [])
# 使用示例
print(data_access_control("analyst", "medium")) # True
print(data_access_control("analyst", "high")) # False实施成果

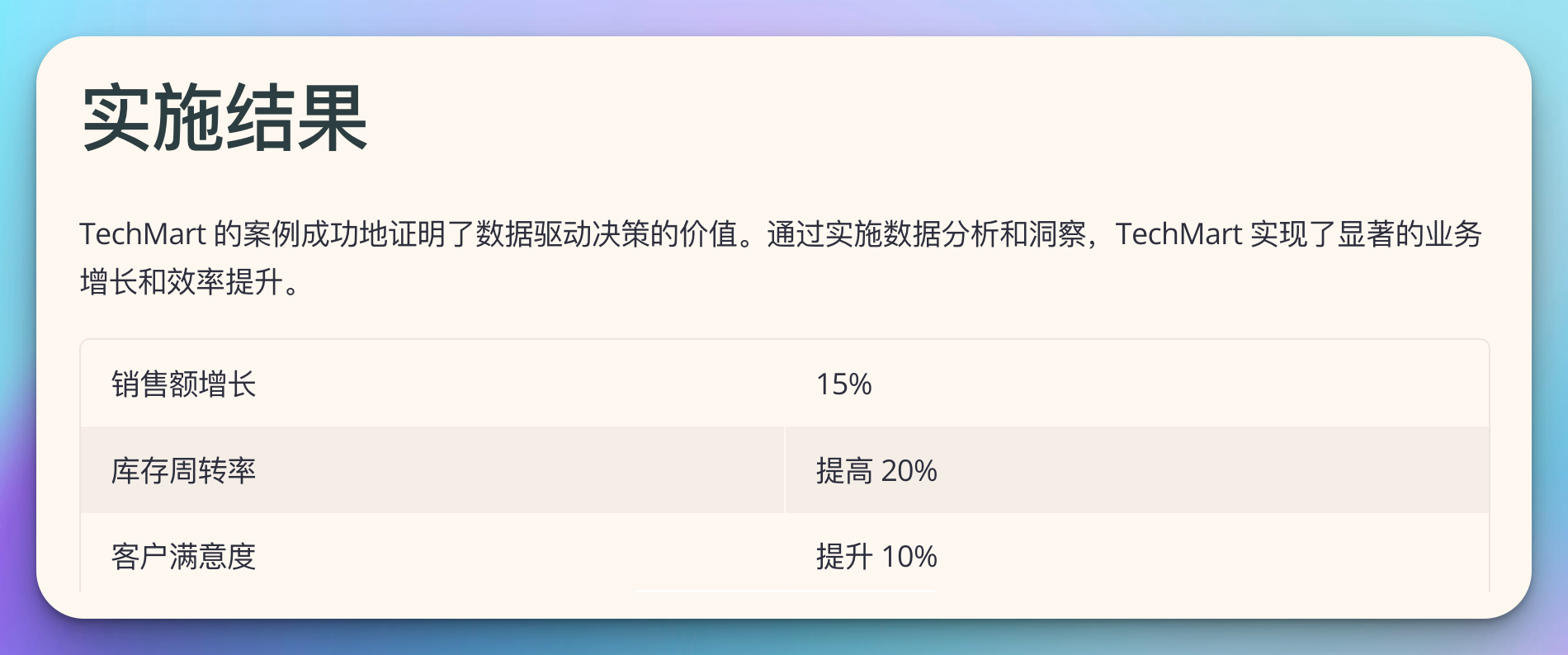
经过六个月的努力,TechMart 在多个方面取得了显著的进步:
- 客户流失率下降
- 平均订单价值提升
- 营销ROI增加
让我们通过一些可视化来展示这些成果:
python
import matplotlib.pyplot as plt
import numpy as np
# 模拟数据
months = ['1月', '2月', '3月', '4月', '5月', '6月']
churn_rate = [0.15, 0.14, 0.12, 0.10, 0.09, 0.08]
avg_order_value = [85, 87, 90, 95, 98, 102]
marketing_roi = [1.5, 1.6, 1.8, 2.0, 2.2, 2.4]
# 创建一个包含三个子图的图表
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(12, 15))
# 客户流失率
ax1.plot(months, churn_rate, marker='o')
ax1.set_title('客户流失率')
ax1.set_ylabel('流失率')
# 平均订单价值
ax2.bar(months, avg_order_value)
ax2.set_title('平均订单价值')
ax2.set_ylabel('订单价值 ($)')
# 营销ROI
ax3.plot(months, marketing_roi, marker='s')
ax3.set_title('营销ROI')
ax3.set_ylabel('ROI')
plt.tight_layout()
plt.show()
# 计算改善百分比
churn_improvement = (churn_rate[0] - churn_rate[-1]) / churn_rate[0] * 100
aov_improvement = (avg_order_value[-1] - avg_order_value[0]) / avg_order_value[0] * 100
roi_improvement = (marketing_roi[-1] - marketing_roi[0]) / marketing_roi[0] * 100
print(f"客户流失率下降了 {churn_improvement:.1f}%")
print(f"平均订单价值提升了 {aov_improvement:.1f}%")
print(f"营销ROI提升了 {roi_improvement:.1f}%")经验总结
通过 TechMart 的案例,我们可以总结出以下实施数据驱动决策的关键经验:
- 明确目标:始终将业务目标作为数据分析的指导。
- 数据质量至关重要:投入资源确保数据的准确性和一致性。
- 培养技能:持续投资于团队的数据分析能力。
- 文化转型:耐心地培养数据文化,展示成功案例来推动变革。
- 技术支持:确保有足够的技术基础设施支持数据驱动决策。
- 安全与隐私:在追求数据价值的同时,不忽视数据安全和用户隐私。
- 持续优化:将数据驱动决策视为一个持续改进的过程。
python
def data_driven_decision_making_checklist():
checklist = [
"明确定义业务目标和KPI",
"评估并改善数据质量",
"投资数据分析技能培训",
"制定数据文化转型计划",
"升级技术基础设施",
"实施数据安全和隐私保护措施",
"建立持续监控和优化机制"
]
return checklist
# 使用示例
ddm_checklist = data_driven_decision_making_checklist()
print("数据驱动决策实施清单:")
for i, item in enumerate(ddm_checklist, 1):
print(f"{i}. {item}")未来展望

随着技术的不断发展,数据驱动决策的未来充满了可能性。以下是一些 TechMart 正在考虑的未来方向:
- 高级分析:引入机器学习和人工智能技术,实现更精准的预测和个性化。
- 实时决策:建立实时数据处理能力,支持即时的业务决策。
- 自动化:将某些数据驱动的决策过程自动化,提高效率。
- 扩展数据源:整合更多外部数据源,如社交媒体数据、市场趋势数据等。
python
def future_data_initiatives():
initiatives = [
{
"name": "客户流失预测模型",
"technology": "机器学习",
"expected_impact": "提前识别90%的潜在流失客户"
},
{
"name": "实时定价引擎",
"technology": "流处理 + 强化学习",
"expected_impact": "提高15%的利润率"
},
{
"name": "智能客户服务机器人",
"technology": "自然语言处理 + 知识图谱",
"expected_impact": "降低30%的客户服务成本"
},
{
"name": "全渠道客户画像",
"technology": "大数据集成 + 图数据库",
"expected_impact": "提升25%的营销转化率"
}
]
return initiatives
# 使用示例
future_initiatives = future_data_initiatives()
print("未来数据驱动计划:")
for initiative in future_initiatives:
print(f"计划: {initiative['name']}")
print(f" 技术: {initiative['technology']}")
print(f" 预期影响: {initiative['expected_impact']}")
print()结语

TechMart 的数据驱动决策之旅展示了这一过程的复杂性和潜力。从初始的挑战到最终的显著成果,我们看到了数据如何改变一个组织的运营方式和决策过程。
然而,这仅仅是开始。随着技术的不断进步和数据量的持续增长,数据驱动决策的潜力还远未被完全开发。组织需要保持开放和学习的心态,不断探索新的方法来利用数据创造价值。
同时,我们也要记住,数据驱动决策并不意味着完全依赖数据而忽视人的因素。最终,成功的决策仍然需要将数据洞察与人类的经验、直觉和创造力相结合。
通过 TechMart 的案例,我们希望能为其他正在开始或正在深化其数据驱动之旅的组织提供一些启示和指导。无论你的组织处于哪个阶段,记住:数据驱动决策是一个持续的旅程,而不是一个终点。保持好奇,保持学习,并始终关注如何用数据为你的客户和业务创造更多价值。