前言
在现代分布式系统和云原生环境中,为了确保复杂的分布式系统和服务的高可用性、可靠性和性能,通常采用实时可视化监控和分析,实现故障快速响应、资源优化和安全保障,从而提升用户满意度和运营效率。
在目前主流的解决方案中,Prometheus 和 Grafana 是两个使用 Go 开发的强大开源工具,通常一起使用来实现全面的监控和可视化系统。其中 Grafana 负责将数据源转化为图表、仪表盘等可视化显示。
概述
什么是 Grafana?Grafana 是一个监控仪表系统,专门用于监控指标数据的图形化展示,支持多种数据来源,Prometheus 便是其中一种。它看上去是这样的:
外链图片转存中...(img-yvS46ihY-1723538656269)
Grafana 还带有告警功能,在系统出现问题时通知你。且告警规则可在监控图形上直接配置!
官方文档:https://grafana.com/docs/grafana/latest/fundamentals/dashboards-overview/
Grafana 安装
下载地址:https://grafana.com/grafana/download
bash
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-11.1.3.linux-amd64.tar.gz
tar -zxvf grafana-enterprise-11.1.3.linux-amd64.tar.gz下载安装好后启动 Grafana 服务:
bash
./bin/grafana-server web默认端口为 3000,访问 http://localhost:3000 即可开始使用 Grafana:
外链图片转存中...(img-9buXA9yU-1723538656270)
初次登录默认的账号密码都是:admin,登录后修改密码。
配置数据源
在开始使用 Grafana 前需要先配置一下数据源,在配置前若还不了解 Prometheus,详见:Prometheus 监控指标采集
外链图片转存中...(img-5PY8aGXJ-1723538656270)
搜索 Prometheus 添加,并配置上 Prometheus 的服务器地址 http://localhost:9090:
外链图片转存中...(img-mQV8nZQQ-1723538656270)
其他参数根据实际情况选择配置,基础使用可直接点击底部 Save & test 按钮:
外链图片转存中...(img-woNndG0C-1723538656270)
快速创建一个仪表盘
通过菜单切换到 Dashboard 页面,创建一个新的仪表盘,选择可视化的流程步骤开始一步一步配置:
外链图片转存中...(img-rK7kQ2u0-1723538656270)
选择刚才配置的 Prometheus 数据源,然后配置这个图表面板的一些基础信息,见下图:
外链图片转存中...(img-PNGUYysI-1723538656271)
若我要查看 3 个接口的响应数据总 MB 大小变化曲线,则可以使用 PromQL:
prometheus_http_response_size_bytes_sum{handler=~"/api/v1/query_range|/static/.*|/metrics"} / 1024 / 1024外链图片转存中...(img-ojwaEKWu-1723538656271)
手动一个个添加 Dashboard 非常繁琐,Grafana 社区鼓励用户分享 Dashboard,通过https://grafana.com/dashboards 网站,可以找到大量可直接使用的 Dashboard 模板。
Grafana 中所有的 Dashboard 通过 JSON 进行共享,下载并且导入这些 JSON 文件,就可以直接使用这些已经定义好的 Dashboard。如搜索 node_expoter 相关的:
外链图片转存中...(img-uctEubjo-1723538656271)
下载后导入 JSON:
外链图片转存中...(img-TDioIekY-1723538656271)
外链图片转存中...(img-KfBWeoj5-1723538656271)
导入成功后就可以在 Grafana 中看到实时监控信息了!通过模板,你可以学习和参考别人的配置项!
变量
在导入的 Node Exporter Full 仪表盘中,点击顶部的设置,可在设置页面中配置一些常用变量:
外链图片转存中...(img-fFFvJ5lV-1723538656271)
参考如 CPU Basic 面板的一个 PromQL 查询:
sum(irate(node_cpu_seconds_total{instance="$node",job="$job", mode="system"}[$__rate_interval])) / scalar(count(count(node_cpu_seconds_total{instance="$node",job="$job"}) by (cpu)))其中就用到了 $node 和 $job 这两个变量:
外链图片转存中...(img-Z0Lvf5k8-1723538656271)
变量是值的占位符,可以用变量来代替服务器或应用名称的硬编码,且变量值会呈现在仪表盘顶部供切换选择:
外链图片转存中...(img-Dvj5iO7E-1723538656271)
变量和模板还允许您使用单源仪表板。如果您有多个相同的数据源或服务器,您可以创建一个仪表板并使用变量来更改您正在查看的内容。
官方文档:https://grafana.com/docs/grafana/latest/dashboards/variables/
变量类型
Dashboard 的变量有多种类型:
| 变量类型 | 描述 |
|---|---|
| Query | 查询生成的值列表,如指标名称、服务器名称、传感器ID、数据中心等。添加查询变量。 |
| Custom | 使用逗号分隔的列表手动定义变量选项。添加自定义变量。 |
| Text box | 显示带有可选默认值的自由文本输入字段。添加文本框变量。 |
| Constant | 定义隐藏常数。添加一个常量变量。 |
| Data source | 快速更改整个仪表板的数据源。添加数据源变量。 |
| Interval | 间隔变量表示时间跨度。添加一个间隔变量。 |
| Ad hoc filters | 自动添加到数据源的所有指标查询的键/值过滤器(仅限Prometheus、Loki、InfluxDB和Elasticsearch)。添加临时筛选器。 |
| Global variables | 可在查询编辑器的表达式中使用的内置变量。参见全局变量。 |
| Chained variables | 变量查询可以包含其他变量。参见链接变量。 |
各类变量类型的应用场景和使用方法详见官方文档:https://grafana.com/docs/grafana/latest/dashboards/variables/add-template-variables/
创建一个实用的仪表盘
上文演示了快速创建一个最简单的仪表盘入门和使用模板导入非常复杂的仪表盘,显然这些都不符合我们的实际应用场景。在开始创建一个实用完整的仪表盘前,我们要明确如下几个步骤:
- 明确监控的指标项和目的,如:监控接口 qps 变化,以了解流量高峰时间段和服务业务量规模
- 编写相应的 PromQL 查询语句
- 选择合适的图表类型呈现 ,如 qps 变化曲线可选择时序曲线图
- 是否有可以将各类值抽象为变量的地方或整体细节优化
接下来,为了降低动手创建一个复杂仪表盘的门槛,以上文提到的 node_expoter 为例,创建一个和监控主机状态和各项指标相关的仪表盘!
第一步 - 明确监控指标
监控服务器节点硬件的基础使用率指标:
- CPU使用率和空闲率变化曲线、百分比数值;
- CPU 核心数数值;
- 内存使用率和空闲率变化曲线、百分比数值、总数数值;
- 磁盘使用率和空闲率变化曲线、百分比数值、总数数值;
- 网络出入流量变化曲线、总数数值;
第二步 - 编写PromQL
以 CPU使用率和空闲率变化曲线、百分比数值、CPU 核心数数值 为例:
-
在
http://localhost:9100/metrics下搜索cpu相关的关键字,可以找到一个node_cpu_seconds_total的指标项,通过其注释可知其记录的监控数据为CPU在每种模式下花费的秒数; -
我们直接在
Grafana中创建一个Query,选择Code模式直接输入PromQL:node_cpu_seconds_total{}先不带任何筛选条件,点击 PromQL 右侧的
Run queries,观察一下数据长什么样:外链图片转存中...(img-dwpvtK9w-1723538656272)
除了内置自带的
__name__、instance和job三个标签,主要有cpu表示多核 CPU 下的核心序号及mode表示使用 CPU 的使用对象(尤其有一个idle代表空闲);且此时 Grafana 已经在我们的 PromQL 下提示选择的指标类型为Counter,建议使用rate来计算这个Counter的比率; -
从我们的目标看,需求计算的大部分指标都为百分比,所以确实刚好需要用到建议的这个
rate函数,该函数只能是区间向量Range vector,时间范围这里我取1m,时间越短则精度越高越准确,此时的PromQL调整为:rate(node_cpu_seconds_total{}[1m]) -
对于筛选条件,我们只需要使用率和空闲率,空闲率可以直接通过
mode="idle"来选择,而使用率是由多个 CPU 的使用对象一起组成的和,一个一个去加太麻烦,这里可以直接通过100% - 空闲率 = 使用率来计算,则使用率PromQL为:(1 - rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100此时从图表曲线图来看有多条曲线,根本原因是
cpu标签值为多种:外链图片转存中...(img-Q4LGPCOB-1723538656272)
-
由于我们要看的是整体 CPU 的使用率和空闲率,所以不在乎具体是哪个 CPU 核心;但由于我们的示例场景是只有一台服务器,若在多个服务器实例的情况下还是要按照
instance来做分组区分的。既然要分组, 就要使用聚合函数,这里对于聚合函数的选择还是取决于采集的数据情况和我们的需求,从上文观察的数据来看,在同一时刻,每个 CPU 的使用对象实际在多个 CPU 核心下都有值,并不是互斥的,所以在按照instance分组后,不应该用sum这类聚合函数,而该选用avg取平均值来表示对整体 CPU 的一个实际使用率:avg by(instace)(1 - rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100 -
至此
PromQL查询出的指标数据已经能准确反映出 CPU 使用率:外链图片转存中...(img-xXGK6tUN-1723538656272)
顶部 MacOS 菜单栏显示的实时 CPU 使用率和下面 Grafana 中图表的最新值 1m 值还是很接近的 (这里的误差主要来自于 Prometheus 的采集速率和计算时选择的时间范围值)
第三步 - 配置 Grafana 仪表盘
完成 PromQL 编写后开始选择合适的图标类型,上述可以看到在编写 PromQL 时默认使用的 Time series 曲线图,这里曲线图刚好是我们需要的,这既是巧合也是因为曲线图是最常用的图表类型,所以是默认的首选,我们还可以尝试切换成其他图表类型,看看渲染效果,或者点击 Suggestions 来看看 Grafana 推荐的类型,且可以直接在建议下预览:
外链图片转存中...(img-c72LV7nY-1723538656272)
最终还是 Time series 展示效果更能帮助我们直观的观察到 CPU 的使用变化情况。
此时仔细观察我们的曲线图表,可以发现曲线的 Legend 信息,即名称显示为 PromQL 表达式,这不便于理解:
外链图片转存中...(img-b5lMBe9f-1723538656272)
所以需要给这条曲线取比一个别名 CPU 使用率,其配置位置在于 PromQL 表达式下面的 Optinos 处,选择 Custom 自定义:
外链图片转存中...(img-UpoDi2cM-1723538656272)
点击 Add query ,把 空闲率 曲线也添加上:
avg by(instace)(rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100外链图片转存中...(img-egW1ZepW-1723538656272)
接下来看看 Grafana 配置面板的右侧配置栏:
| 配置项名称 | 配置值和渲染效果截图 | 配置原因 |
|---|---|---|
| Panel options | 外链图片转存中...(img-NflENhWe-1723538656272) | 给面板配置一个 Title,这个面板通过字面含义就能理解,不需要配置 Description |
| Tooltip | 外链图片转存中...(img-sSoXxdnS-1723538656272) | 配置鼠标在图表上 hover 时显示的具体使用率和空闲率值 |
| Legend | 外链图片转存中...(img-yUSEBlzP-1723538656273) | 之前在 Options 处配置了每条曲线的别名,这里可以整体配置曲线信息的类型为表格 Table,因为要显示最近值Last* (Last 会显示空值)、平均值Mean、最小值Min和最大值Max表格更为清晰 |
| Axis | 外链图片转存中...(img-W8JIWKfU-1723538656273) | 对于坐标系的配置加个一个说明文本是百分比值 |
| Graph styles |  |
图表渲染样式主要使用了更为平滑的 Smooth 曲线、曲线填充的透明度修改为 50(看上去就有了一个背景色,且将空闲率的 PromQL 查询语句拖到第一个,让使用率的覆盖在空闲率上)、曲线上不显示数值点 |
| Standard options | 外链图片转存中...(img-vljiLmT8-1723538656273) | 设置数值单位为 Misc 下的 Percent(0-100);曲线颜色选择自己喜欢的主题,若已有的主题觉得不好看可以点击曲线颜色块自定义 |
上表的这些配置效果,在日常观察监控指标时,正常情况下绿色背景应该是占大部分,若黄色曲线图在高位,绿色背景将减少,说明 CPU 负载偏高了。
以相同的方式添加内存、磁盘、网络相关的曲线图表:
外链图片转存中...(img-gu2vKGVj-1723538656273)
再添加一些数值类的图表:
外链图片转存中...(img-W125crXD-1723538656273)
第四步 - 细节优化
最后做一些整体优化,添加 $instance 和 $job 变量,所有的 PromQL 添加上 job="${job}", instance="${instance}" 筛选条件:
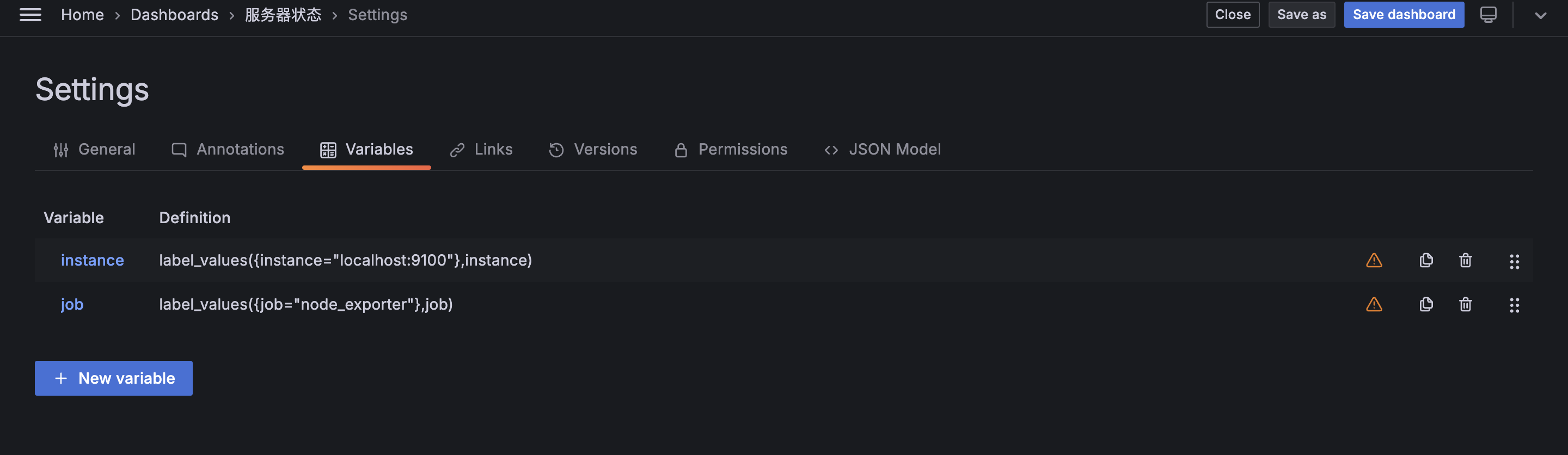
并将概览和曲线图通过 Row 来分类或折叠,最终效果:
外链图片转存中...(img-KMZB21ln-1723538656273)
Dashboard 导出的 JSON 文件下载:https://minio.hezebin.com/blog/file/Basic server status-1723457174075.json
Grafana Dashboard 下载:https://grafana.com/grafana/dashboards/21683-basic-server-status/
告警和通知
Grafana Alerting 配置非常简单,Grafana 警报会定期查询数据源并评估警报规则中定义的条件。如果条件被违反,会触发警报实例。触发(和解决)的警报实例会发送通知,可以直接发送到联系点或通过通知策略发送以获得更大的灵活性。
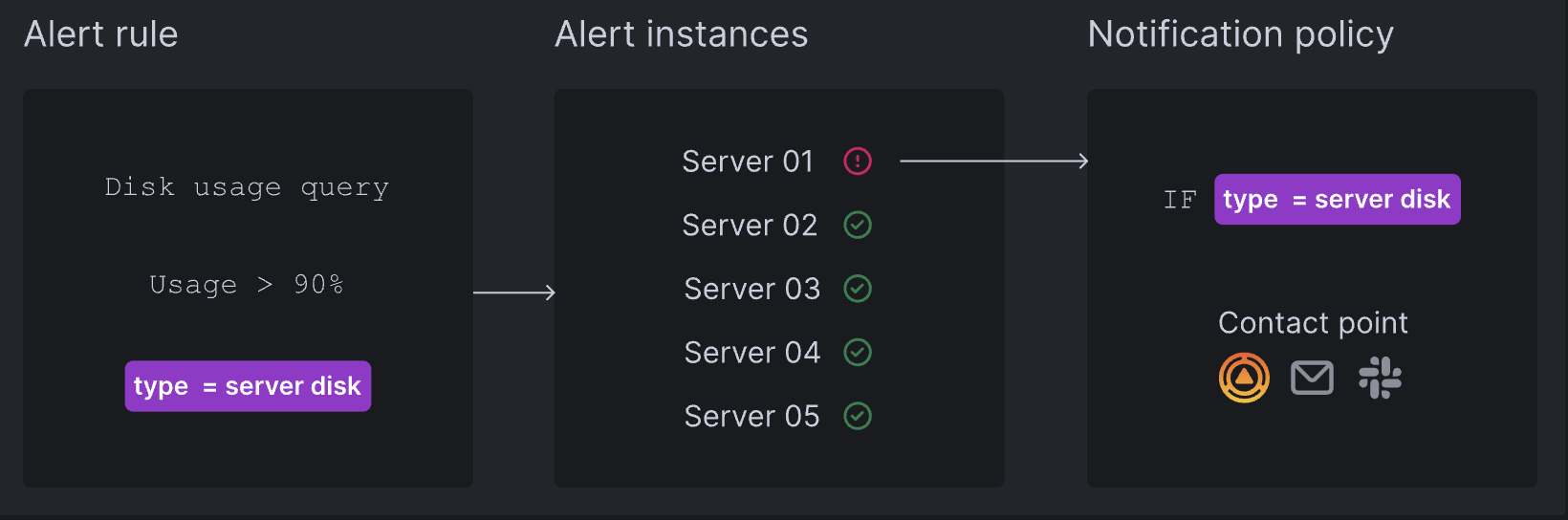
Grafana Alerting 基础概念:
-
Alert rules警报规则:包含一个或多个查询和表达式,选择要测量的数据,并包含触发警报的条件。 -
Alert instances警报实例:每个警报规则可以产生多个警报实例,每个时间序列一个实例,允许在单个表达式中观察多个系列。 -
Contact points联系点:确定通知消息的内容和发送位置,例如电子邮件地址、Slack、事故管理系统(如 Grafana OnCall 或 PagerDuty)或 Webhook。 -
Notification policies通知策略:为大型系统提供灵活的处理警报通知的方法,通过标签匹配将警报路由到联系点。外链图片转存中...(img-1q2WZci7-1723538656273)
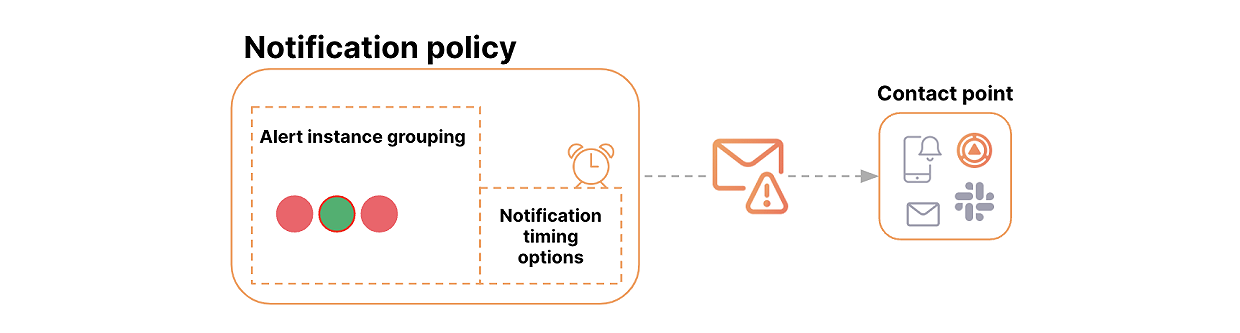
-
Silences and mute timings静默和静音时间:允许在特定警报或整个通知策略上暂停通知。 -
Architecture架构:Grafana 警报基于 Prometheus 设计警报系统模型,包括警报生成器和警报接收器(也称为 Alertmanager)。
通过菜单栏的 Altering 创建一个告警,例如要告警内存使用率超过 60%的情况,关键规则条件如下:
外链图片转存中...(img-rNTKhNsH-1723538656274)
触发配置如下:
外链图片转存中...(img-Fh1iAelj-1723538656274)
联系点的邮箱收件人替换为实际有效的:
外链图片转存中...(img-rEkQKmsH-1723538656274)
还需要配置邮箱发件人,在 conf/defaults.ini 配置文件的 smtp 处配置:
ini
[smtp]
enabled = true
host = smtp.qq.com:587
user = ihezebin@qq.com
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password = kajudlrqxxxxxx
cert_file =
key_file =
skip_verify = false
from_address = ihezebin@qq.com
from_name = Grafana
ehlo_identity =
startTLS_policy =
enable_tracing = false重启 grafana-server 服务器即可,下图为已经触发告警和邮件通知的状态:
外链图片转存中...(img-dzatExV2-1723538656274)
由于通知策略配置默认是4h后才能才触发通知,所以持续触发告警的情况下只收到一次邮件:
外链图片转存中...(img-97y3p0Lv-1723538656274)
外链图片转存中...(img-f5tKTWQb-1723538656274)