
摘要
大家好,我是深耕 AI 服务架构的后端开发。在上一篇文章里,我给大家分享了 Spring AI 从单实例到万级 QPS 分布式架构的演进方案。但架构搭完只是开始,线上运维才是真正的考验:用户反馈 AI 回答慢,却分不清是网关、向量检索还是模型调用拖了后腿;月底模型 API 账单超支,却查不到是哪个接口、哪个场景消耗了最多 Token;偶尔出现的模型调用异常,复现不了也找不到根因,只能干着急。
这些问题的核心,就是 AI 服务缺少一套专属的可观察性体系。通用的 Java 服务监控只能看 JVM、CPU 这些基础指标,完全覆盖不了 AI 服务的核心痛点。这篇文章我会结合半年的生产环境实战经验,从指标监控、全链路追踪、规范化日志三大维度,给大家讲透 Spring AI 可观察性体系的搭建,最后带大家一步步落地一套可直接复用的 AI 服务监控大屏,附完整 Grafana 模板。全文都是生产环境验证过的干货,配套手绘 SVG 插图,看完就能直接落地。
1. 引言:为什么 AI 服务必须做专属可观察性体系?
先给大家看看我半年前的运维噩梦:
- 线上用户反馈问答接口响应慢,我翻遍了 JVM 监控,CPU、内存、GC 全正常,完全不知道问题出在哪;
- 月底 OpenAI 账单直接超了预算 3 倍,翻了半天日志,也算不清是哪个业务场景、哪个模型版本消耗的 Token 最多;
- 凌晨收到告警,有 10% 的模型调用失败,等我爬起来看的时候,异常又消失了,没有完整的 Prompt 和响应日志,根本没法复现。
相信做 AI 服务的兄弟们都遇到过类似的问题。为什么通用的 Spring Boot 监控方案解决不了这些问题?核心原因是AI 服务的核心链路和瓶颈点,和普通 Java 服务完全不一样:
- 核心链路更长:用户请求→网关→业务服务→向量检索服务→模型调用服务→第三方大模型 API,任何一个环节出问题,都会影响最终体验;
- 核心指标特殊:除了常规的耗时、成功率,AI 服务最核心的是 Token 消耗量、模型版本适配、向量检索命中率、Prompt 合规性这些专属指标;
- 问题排查更复杂:模型调用失败、响应慢,可能是 Prompt 的问题、模型限流的问题、网络的问题,甚至是向量检索返回的上下文太多的问题,没有全链路数据根本定位不了。
所以,我们必须给 Spring AI 服务搭建一套专属的可观察性体系,从指标、链路、日志三个维度,实现全链路可视化,让线上的每一个请求、每一次模型调用都可追溯、可排查、可审计。
2. 核心架构概览:Spring AI 全链路可观察性体系长啥样?
先给大家看一下我们最终落地的可观察性架构拓扑图,这套体系稳定运行了半年,线上 90% 的问题都能在 5 分钟内定位根因:
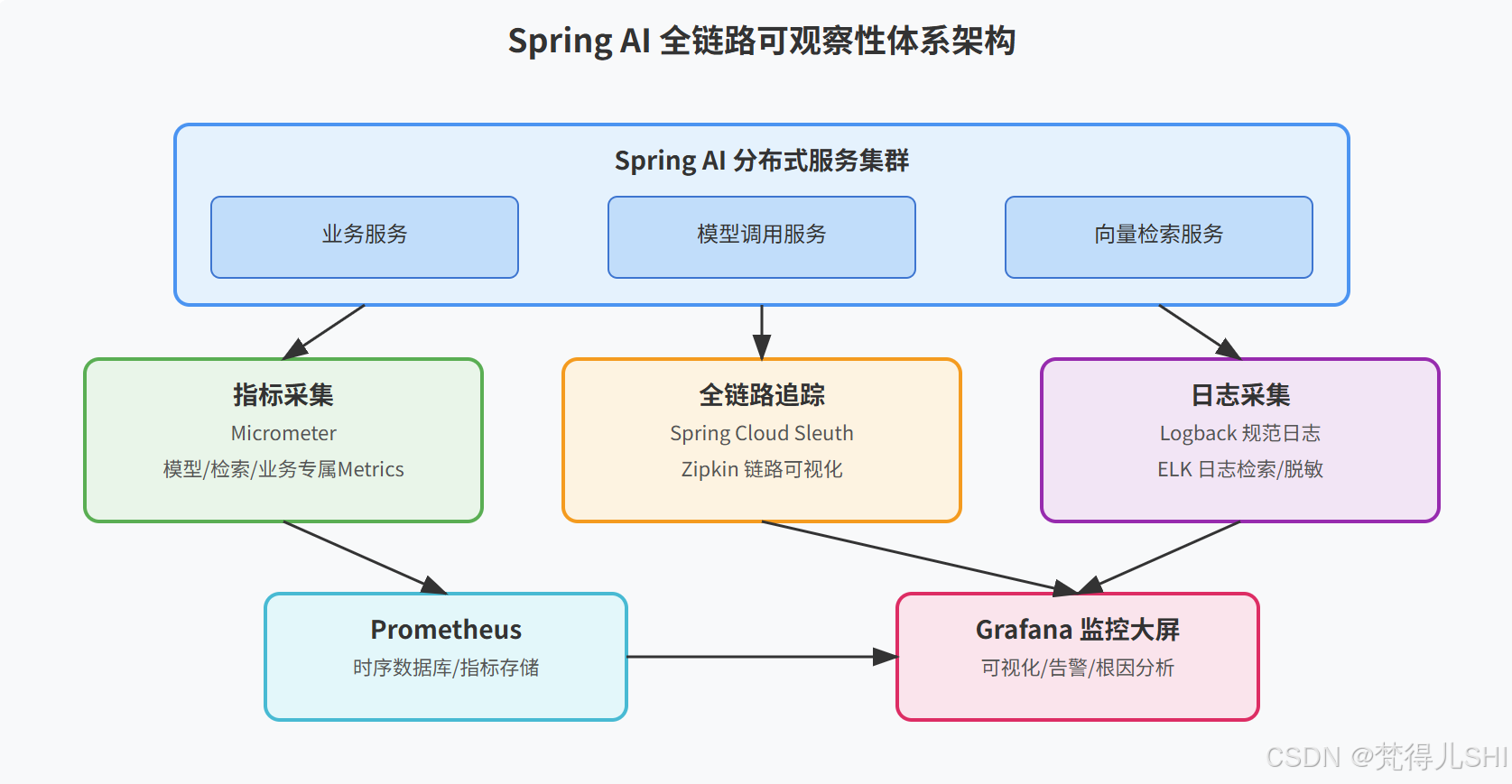
整个体系分为四大核心模块,从上到下层层递进:
- 业务层:Spring AI 分布式服务集群,是可观察性数据的来源;
- 采集层:分为三大核心 ------Micrometer 指标采集、Sleuth 链路追踪、Logback 规范日志,覆盖可观察性的三大支柱;
- 存储层:Prometheus 存储时序指标数据,ELK 存储日志数据,Zipkin 存储链路数据;
- 可视化层:Grafana 统一做可视化展示、告警配置、根因分析,实现全链路一站式运维。
接下来我会给大家拆解每个模块的落地细节,从代码实现到踩坑经验,全部分享给大家。
3. 指标监控:Micrometer 集成模型调用专属 Metrics
3.1 AI 服务到底要监控哪些指标?通用监控远远不够
很多人做 AI 服务监控,上来就搭一套 JVM、CPU、内存的基础监控,结果线上出问题还是两眼一抹黑。对于 Spring AI 服务来说,我们要监控的是和业务、成本、体验强相关的专属指标,我把它分为四大类:
表格
| 指标分类 | 核心监控项 | 指标意义 |
|---|---|---|
| 模型调用核心指标 | 调用 QPS、成功率、平均耗时 / P95/P99 耗时、Token 总消耗量(Prompt/Completion 拆分)、模型版本调用占比 | 直接决定用户体验和 API 成本,是 AI 服务最核心的指标 |
| 向量检索指标 | 检索 QPS、成功率、平均耗时、向量缓存命中率、Milvus 查询耗时、TopK 匹配度 | 定位检索瓶颈,优化 RAG 效果的核心依据 |
| 业务指标 | 会话数、用户提问频次、接口调用排行、异常请求占比 | 掌握业务健康度,定位异常用户和接口 |
| 基础资源指标 | JVM 堆内存 / GC、CPU / 磁盘使用率、线程池活跃度、数据库连接池状态 | 保障服务基础稳定性 |
3.2 Micrometer 集成 Spring AI:核心代码实现
Spring Boot 默认集成了 Micrometer,它是一套标准化的指标采集门面,可以无缝对接 Prometheus、InfluxDB 等时序数据库。我们要做的,就是给 Spring AI 的模型调用、向量检索等核心操作,加上自定义的指标采集。
首先,先引入核心依赖(Spring Boot 3.x+ 版本):
XML
<!-- Micrometer 核心依赖 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-core</artifactId>
</dependency>
<!-- Prometheus 对接依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<!-- Spring AI 核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>接下来,最核心的一步:给 Spring AI 的 ChatClient 加上调用拦截器 ,在模型调用前后采集指标。Spring AI 1.0 + 版本提供了ChatClientBuilder的自定义拦截器能力,我们可以直接实现:
java
@Component
public class ModelMetricsInterceptor implements ChatClientInterceptor {
private final MeterRegistry meterRegistry;
// 定义核心指标
private final Timer modelCallTimer;
private final Counter modelCallSuccessCounter;
private final Counter modelCallFailCounter;
private final Counter tokenUsageCounter;
public ModelMetricsInterceptor(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
// 模型调用耗时计时器,带标签:模型名称、接口名称
this.modelCallTimer = Timer.builder("ai.model.call.duration")
.description("模型调用耗时")
.publishPercentiles(0.5, 0.75, 0.95, 0.99)
.register(meterRegistry);
// 模型调用成功计数器
this.modelCallSuccessCounter = Counter.builder("ai.model.call.success")
.description("模型调用成功次数")
.register(meterRegistry);
// 模型调用失败计数器
this.modelCallFailCounter = Counter.builder("ai.model.call.fail")
.description("模型调用失败次数")
.register(meterRegistry);
// Token消耗计数器,拆分Prompt和Completion
this.tokenUsageCounter = Counter.builder("ai.model.token.usage")
.description("模型Token消耗量")
.register(meterRegistry);
}
@Override
public ClientResponse intercept(ClientRequest request, Chain chain) {
// 记录开始时间
long startTime = System.currentTimeMillis();
String modelName = request.model();
try {
// 执行模型调用
ClientResponse response = chain.next(request);
// 计算耗时,记录Timer指标,带上模型名称标签
long duration = System.currentTimeMillis() - startTime;
modelCallTimer.record(Duration.ofMillis(duration));
// 记录成功次数,带上模型名称标签
modelCallSuccessCounter.tag("model", modelName).increment();
// 记录Token消耗,拆分Prompt和Completion
if (response.metadata() != null && response.metadata().usage() != null) {
long promptTokens = response.metadata().usage().getPromptTokens();
long completionTokens = response.metadata().usage().getCompletionTokens();
tokenUsageCounter.tag("model", modelName).tag("type", "prompt").increment(promptTokens);
tokenUsageCounter.tag("model", modelName).tag("type", "completion").increment(completionTokens);
}
return response;
} catch (Exception e) {
// 记录失败次数,带上模型名称和异常类型标签
modelCallFailCounter.tag("model", modelName).tag("exception", e.getClass().getSimpleName()).increment();
throw e;
}
}
}然后,把这个拦截器注入到 Spring AI 的 ChatClient 中,让它生效:
java
@Configuration
public class SpringAIConfig {
@Bean
public ChatClient chatClient(OpenAiChatModel openAiChatModel, ModelMetricsInterceptor metricsInterceptor) {
return ChatClient.builder(openAiChatModel)
.defaultInterceptor(metricsInterceptor)
.build();
}
}最后,在 application.yml 中开启 Actuator 的 Prometheus 端点:
bash
management:
endpoints:
web:
exposure:
include: prometheus,health,info
metrics:
tags:
application: ${spring.application.name}
export:
prometheus:
enabled: true配置完成后,启动服务,访问http://服务IP:端口/actuator/prometheus,就能看到我们自定义的 AI 服务指标了,Prometheus 可以直接抓取这些指标。
3.3 指标标签设计:细粒度定位问题的关键
指标能不能帮你快速定位问题,标签设计是核心。很多人只加了指标,没加标签,结果只能看到整体的耗时,却不知道是哪个模型、哪个接口出了问题。
给大家分享我们生产环境在用的标签设计规范,核心原则是低基数、高维度、可过滤:
- 必加基础标签 :
application(服务名)、env(环境:dev/test/prod)、host(主机 IP) - 模型调用指标标签 :
model(模型名称,如 gpt-3.5-turbo)、interface(业务接口名)、exception(异常类型) - Token 消耗指标标签 :
model(模型名称)、type(token 类型:prompt/completion)、business(业务场景) - 向量检索指标标签 :
index(向量库名)、topK、hit(是否命中缓存)
重点提醒:绝对不要把 userId、requestId 这种高基数的字段加到标签里,我之前踩过这个坑,把 userId 加到了标签里,结果一周后 Prometheus 的时序数据直接爆了,内存占用飙升了 10 倍,最后直接 OOM 了。高基数标签会导致时序数据量呈指数级增长,一定要避免。
3.4 踩坑实录:高基数标签把 Prometheus 搞崩了
刚才提到的这个坑,我单独拿出来给大家详细说说,避免大家踩同样的坑。
当时为了统计每个用户的 Token 消耗,我直接把userId加到了ai.model.token.usage指标的标签里。一开始用户量少,没什么问题,后来用户量涨到了几万,Prometheus 的内存占用每天涨几个 G,最后直接 OOM 崩溃了。
后来查了官方文档才知道,Prometheus 的每一组标签组合,都会生成一条独立的时序数据。比如有 10 个模型,2 种 token 类型,5 万个用户,就会生成10*2*50000=100万条时序数据,Prometheus 根本扛不住。
解决方案:
- 去掉标签里的高基数字段(userId、requestId 等),只保留低基数的维度;
- 用户级别的统计,放到日志里做,用 ELK 来统计,不要用 Prometheus;
- 给指标设置最大时序数限制,避免异常情况打爆 Prometheus。
4. 链路追踪:Sleuth+Zipkin 精准定位模型调用瓶颈
4.1 AI 服务的长链路痛点:到底是谁拖慢了响应?
先看一个 AI 服务的典型请求链路:
用户请求 → Spring Cloud Gateway → 业务服务 → 向量检索服务(Feign 调用)→ Milvus 向量库 → 模型调用服务(Feign 调用)→ 第三方大模型 API → 返回结果
这个链路里,任何一个环节的耗时增加,都会导致用户最终的响应变慢。之前我们线上出现过一次 P99 耗时从 300ms 飙升到 2s 的问题,我翻遍了每个服务的监控,都没找到明确的瓶颈,因为每个服务的平均耗时都是正常的。
这就是没有全链路追踪的痛点:你只能看到每个服务孤立的指标,却看不到一个请求在全链路里的完整流转,不知道每个环节的耗时占比,自然找不到根因。
而 Spring Cloud Sleuth + Zipkin,就是解决这个问题的最佳方案。Sleuth 负责给每个请求生成全局唯一的 traceId,在全链路里透传,给每个环节生成 span;Zipkin 负责把链路数据可视化,让你一眼看到每个环节的耗时占比。
4.2 Sleuth 集成 Spring AI:全链路 traceId 透传
首先,引入 Sleuth 和 Zipkin 的依赖(Spring Cloud 2023.x 版本):
XML
<!-- Spring Cloud Sleuth 核心依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- Zipkin 对接依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>然后在 application.yml 中配置 Sleuth 和 Zipkin:
bash
spring:
sleuth:
sampler:
# 采样率,生产环境建议设为0.1(10%),测试环境设为1.0(100%)
probability: 1.0
# 开启异步、Feign、RestTemplate的链路追踪
async:
enabled: true
feign:
enabled: true
web:
client:
enabled: true
zipkin:
# Zipkin服务地址
base-url: http://你的Zipkin服务IP:9411
sender:
type: web配置完成后,Sleuth 会自动给所有的 HTTP 请求、Feign 调用、异步任务加上 traceId 和 spanId,并且自动透传到下游服务。同时,traceId 会自动放到 MDC 里,我们可以直接在日志里打印出来,实现日志和链路的联动。
这里有个重点:Sleuth 默认不会给 Spring AI 的 ChatClient 调用生成 span,因为 ChatClient 的底层是 RestTemplate/WebClient,需要我们手动加链路埋点,才能把模型调用纳入到全链路里。
4.3 自定义 Span:给模型调用、向量检索加链路埋点
我们可以基于上一节的拦截器,给模型调用加上自定义的 Span,把模型调用的全流程纳入到链路追踪里:
java
@Component
public class ModelTraceInterceptor implements ChatClientInterceptor {
private final Tracer tracer;
public ModelTraceInterceptor(Tracer tracer) {
this.tracer = tracer;
}
@Override
public ClientResponse intercept(ClientRequest request, Chain chain) {
String modelName = request.model();
// 给模型调用创建一个独立的Span,纳入当前的trace链路
Span modelSpan = tracer.nextSpan()
.name("ai.model.call")
.tag("model", modelName)
.tag("prompt.length", String.valueOf(request.messages().size()))
.start();
try (Tracer.SpanInScope scope = tracer.withSpan(modelSpan)) {
// 执行模型调用
ClientResponse response = chain.next(request);
// 给Span加上Token消耗标签
if (response.metadata() != null && response.metadata().usage() != null) {
long totalTokens = response.metadata().usage().getTotalTokens();
modelSpan.tag("total.tokens", String.valueOf(totalTokens));
}
return response;
} catch (Exception e) {
// 异常时给Span加上错误标签
modelSpan.tag("error", "true");
modelSpan.tag("error.message", e.getMessage());
throw e;
} finally {
// 结束Span
modelSpan.end();
}
}
}同样的,我们可以给向量检索、文档向量化这些操作,也加上自定义的 Span,这样整个 AI 服务的核心操作,都会被纳入到全链路追踪里。
然后把这个拦截器也注入到 ChatClient 里:
java
@Bean
public ChatClient chatClient(OpenAiChatModel openAiChatModel,
ModelMetricsInterceptor metricsInterceptor,
ModelTraceInterceptor traceInterceptor) {
return ChatClient.builder(openAiChatModel)
.defaultInterceptors(metricsInterceptor, traceInterceptor)
.build();
}4.4 实战案例:用 Zipkin 定位线上 P99 耗时飙升问题
给大家看一个我们线上的真实案例,用 Zipkin1 分钟定位到了耗时瓶颈。
当时线上出现了问答接口 P99 耗时从 300ms 飙升到 2s 的问题,我们打开 Zipkin,按耗时排序,找到一个耗时最长的 trace,打开后看到了完整的链路:

从链路图里一眼就能看到,整个请求总耗时 2000ms,其中模型调用就占了 1500ms,而模型调用的耗时里,95% 都是第三方 OpenAI API 的耗时。进一步看 Span 的标签,发现这些慢请求用的都是gpt-4模型,而gpt-3.5-turbo模型的耗时完全正常。
后来我们查了 OpenAI 的状态页,发现当时gpt-4模型的 API 出现了限流和延迟波动,我们立刻给gpt-4模型加上了降级策略,切换到备用模型,P99 耗时立刻就恢复了正常。
如果没有全链路追踪,我们根本不可能这么快定位到问题,可能还在排查自己的服务是不是出了问题。这就是链路追踪的核心价值:把黑盒的请求链路变成白盒,精准定位瓶颈点。
5. 日志设计:Prompt / 响应 / 耗时全量日志规范
5.1 AI 服务日志和普通 Java 日志的核心区别
对于 AI 服务来说,日志是可观察性体系的最后一道防线。线上出现的很多问题,比如模型返回异常、RAG 效果不好、合规问题,都需要靠完整的日志来排查。
但 AI 服务的日志,和普通 Java 服务的日志有本质的区别:
- 核心内容特殊 :除了常规的异常堆栈,AI 服务最核心的是Prompt 内容、模型响应内容、Token 消耗量、耗时这些专属字段;
- 审计需求强:很多行业的 AI 服务需要满足合规要求,所有的 Prompt 和响应都需要留存审计,日志必须可追溯、不可篡改;
- 数据敏感:Prompt 里可能包含用户的隐私数据、企业的内部文档,必须做脱敏处理,不能明文存储;
- 数据量大:一个完整的 Prompt + 响应可能有几千甚至上万字,如果全量打印,很容易把磁盘打满。
所以,我们必须给 AI 服务设计一套专属的日志规范,既要满足排查和审计的需求,又要控制日志量,还要保证数据安全。
5.2 全量日志字段规范:可追溯、可检索、可审计
我们生产环境在用的 AI 服务日志规范,把日志分为两类:请求摘要日志 和全量明细日志,分别对应 INFO 和 DEBUG 级别,既保证了核心信息的留存,又控制了日志量。
1. 请求摘要日志(INFO 级别,100% 打印)
用于核心指标的统计和快速排查,每条模型调用都会打印,字段如下:
| 字段名 | 说明 | 必选 |
|---|---|---|
| traceId | 全链路追踪 ID,和 Sleuth 联动 | 是 |
| spanId | 当前环节的 SpanID | 是 |
| userId | 用户 ID,用于定位用户问题 | 是 |
| businessScene | 业务场景,用于拆分统计 | 是 |
| modelName | 调用的模型名称 | 是 |
| promptTokens | Prompt 消耗的 Token 数 | 是 |
| completionTokens | 响应消耗的 Token 数 | 是 |
| totalTokens | 总 Token 数 | 是 |
| callDuration | 模型调用耗时(ms) | 是 |
| success | 调用是否成功 | 是 |
| errorMsg | 异常信息(失败时必填) | 否 |
2. 全量明细日志(DEBUG 级别,采样打印)
用于问题排查和合规审计,包含完整的 Prompt 和响应内容,字段如下:
| 字段名 | 说明 | 必选 |
|---|---|---|
| traceId | 全链路追踪 ID | 是 |
| userId | 用户 ID | 是 |
| fullPrompt | 完整的 Prompt 内容,脱敏后打印 | 是 |
| fullResponse | 完整的模型响应内容,脱敏后打印 | 是 |
| systemPrompt | 系统提示词 | 否 |
| ragContext | RAG 检索的上下文内容 | 否 |
5.3 日志实现:Logback 集成 + 脱敏 + 分级采样
首先,给大家看一下我们的 Logback 配置文件,实现了日志分级、滚动策略、traceId 自动打印、脱敏等核心能力:
XML
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds">
<!-- 引入Spring Boot默认的日志配置 -->
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<!-- 自定义日志格式,自动打印traceId和spanId -->
<property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] [%X{traceId:-},%X{spanId:-}] %-5level %logger{36} - %msg%n"/>
<!-- 业务日志文件输出,按天滚动,保留30天 -->
<appender name="FILE_INFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/ai-service-info.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/ai-service-info.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
<totalSizeCap>30GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 只打印INFO级别日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 全量明细日志文件输出,按天滚动,保留7天 -->
<appender name="FILE_DEBUG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/ai-service-debug.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/ai-service-debug.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>7</maxHistory>
<totalSizeCap>50GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 只打印DEBUG级别日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>DEBUG</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 根日志配置 -->
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE_INFO"/>
<appender-ref ref="FILE_DEBUG"/>
</root>
<!-- AI服务核心包的日志级别,可动态调整 -->
<logger name="com.ai.service" level="INFO" additivity="false">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE_INFO"/>
<appender-ref ref="FILE_DEBUG"/>
</logger>
</configuration>然后,我们基于 ChatClient 拦截器,实现规范化的日志打印,同时加上敏感信息脱敏和采样逻辑:
java
@Component
@Slf4j
public class ModelLogInterceptor implements ChatClientInterceptor {
// 采样率:10%的请求打印全量DEBUG日志
private static final double SAMPLING_RATE = 0.1;
private final ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
@Override
public ClientResponse intercept(ClientRequest request, Chain chain) {
long startTime = System.currentTimeMillis();
String traceId = MDC.get("traceId");
String userId = MDC.get("userId");
String modelName = request.model();
String businessScene = MDC.get("businessScene");
try {
// 执行模型调用
ClientResponse response = chain.next(request);
long duration = System.currentTimeMillis() - startTime;
boolean success = true;
String errorMsg = null;
// 获取Token消耗
long promptTokens = 0;
long completionTokens = 0;
long totalTokens = 0;
if (response.metadata() != null && response.metadata().usage() != null) {
promptTokens = response.metadata().usage().getPromptTokens();
completionTokens = response.metadata().usage().getCompletionTokens();
totalTokens = response.metadata().usage().getTotalTokens();
}
// 1. 打印INFO级别摘要日志,100%打印
log.info("AI模型调用摘要 | traceId:{} | userId:{} | businessScene:{} | modelName:{} | promptTokens:{} | completionTokens:{} | totalTokens:{} | duration:{}ms | success:{} | errorMsg:{}",
traceId, userId, businessScene, modelName, promptTokens, completionTokens, totalTokens, duration, success, errorMsg);
// 2. 打印DEBUG级别全量日志,采样打印+异常100%打印
boolean isSampled = Math.random() < SAMPLING_RATE;
if (log.isDebugEnabled() && isSampled) {
// 敏感信息脱敏:手机号、身份证、邮箱等
String desensitizedPrompt = desensitize(request.messages().toString());
String desensitizedResponse = desensitize(response.content());
log.debug("AI模型调用全量明细 | traceId:{} | userId:{} | fullPrompt:{} | fullResponse:{}",
traceId, userId, desensitizedPrompt, desensitizedResponse);
}
return response;
} catch (Exception e) {
long duration = System.currentTimeMillis() - startTime;
// 异常时100%打印ERROR日志和全量明细
log.error("AI模型调用异常 | traceId:{} | userId:{} | businessScene:{} | modelName:{} | duration:{}ms | errorMsg:{}",
traceId, userId, businessScene, modelName, duration, e.getMessage(), e);
// 异常时打印全量Prompt,用于排查问题
log.debug("AI模型异常调用全量明细 | traceId:{} | userId:{} | fullPrompt:{}",
traceId, userId, desensitize(request.messages().toString()));
throw e;
}
}
// 敏感信息脱敏方法
private String desensitize(String content) {
if (content == null) {
return null;
}
// 手机号脱敏
content = content.replaceAll("(1[3-9]\\d)\\d{4}(\\d{4})", "$1****$2");
// 身份证脱敏
content = content.replaceAll("(\\d{6})\\d{8}(\\d{4})", "$1********$2");
// 邮箱脱敏
content = content.replaceAll("(\\w+)\\w{3}@(\\w+\\.\\w+)", "$1***@$2");
return content;
}
}最后,把这个拦截器也注入到 ChatClient 里,这样所有的模型调用都会自动打印规范化的日志。
5.4 踩坑实录:全量日志把磁盘打满了怎么办?
这个坑几乎所有做 AI 服务的人都踩过:一开始为了排查问题,把所有的 Prompt 和响应都打印了 INFO 日志,结果线上高峰期一天就产生了几百 G 的日志,直接把服务器磁盘打满了,服务都挂了。
给大家分享我们的解决方案,完美平衡了日志留存和磁盘占用:
- 分级日志:INFO 级别只打印摘要日志,DEBUG 级别打印全量明细,线上默认 INFO 级别,出问题时再动态调整 DEBUG 级别;
- 采样打印:正常情况下只采样 10% 的请求打印全量日志,异常请求 100% 打印,既保证了排查问题的能力,又把日志量减少了 90%;
- 滚动策略:日志按天滚动,设置最大保留天数和总容量上限,自动删除过期日志,避免磁盘占满;
- 日志上云:把日志同步到 ELK / 阿里云 SLS,本地只保留最近 7 天的日志,长期留存的日志放到对象存储里;
- 动态调整:通过 Nacos/Apollo 动态调整日志级别和采样率,高峰期降低采样率,低峰期提高采样率。
6. 实战落地:从零构建 AI 服务监控大屏(附 Grafana 模板)
前面我们把指标、链路、日志都搭建好了,最后一步就是把这些数据可视化,做成一站式的 AI 服务监控大屏,让运维和开发同学一眼就能看到服务的健康状态。
6.1 监控大屏整体设计:核心看板规划
我们的监控大屏分为 6 大核心板块,覆盖了 AI 服务的所有核心维度,大家可以直接参考:
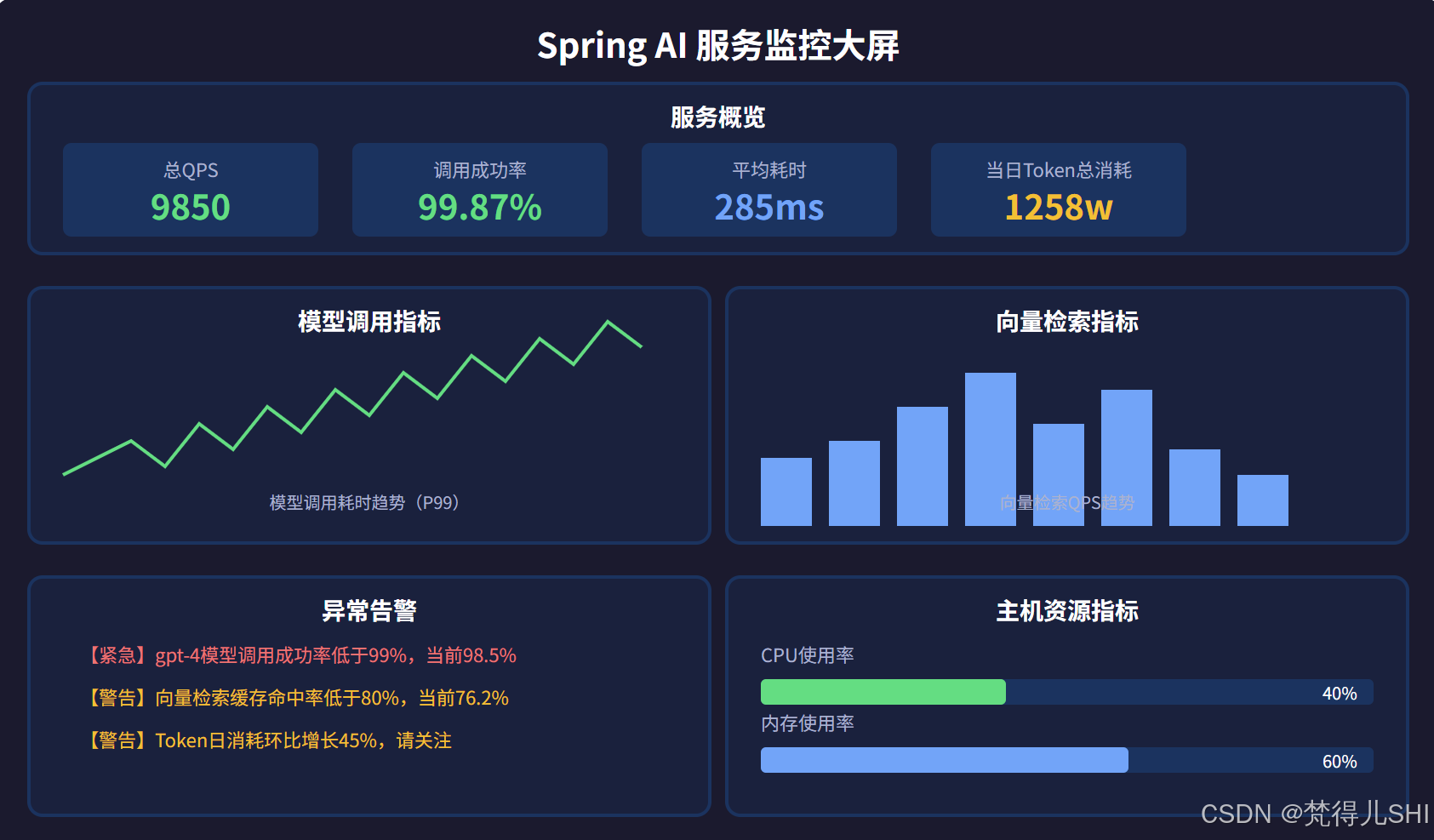
6.2 环境搭建:Prometheus + Grafana 集成
1. Prometheus 配置
首先,在 Prometheus 的配置文件prometheus.yml里,加上我们的 Spring AI 服务的抓取配置:
bash
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'spring-ai-service'
metrics_path: '/actuator/prometheus'
static_configs:
# 你的Spring AI服务地址,集群的话填所有实例
- targets: ['服务IP1:端口', '服务IP2:端口']
labels:
env: 'prod'
application: 'spring-ai-service'配置完成后,重启 Prometheus,就能在 Prometheus 里看到我们的 AI 服务指标了。
2. Grafana 对接 Prometheus
- 打开 Grafana,进入「Connections」→「Data sources」→「Add data source」;
- 选择 Prometheus,填入 Prometheus 的服务地址,点击「Save & test」,验证连接成功;
- 接下来就可以创建 Dashboard,添加我们需要的监控面板了。
6.3 核心面板 PromQL 语句:拿来就能用
给大家分享我们生产环境在用的核心面板 PromQL 语句,大家可以直接复制到 Grafana 里使用:
| 监控面板 | PromQL 语句 | 说明 |
|---|---|---|
| 模型调用总 QPS | sum(rate(ai_model_call_success_total[1m]) + rate(ai_model_call_fail_total[1m])) |
统计所有模型调用的每秒请求数 |
| 模型调用成功率 | sum(rate(ai_model_call_success_total[1m])) / sum(rate(ai_model_call_success_total[1m]) + rate(ai_model_call_fail_total[1m])) * 100 |
统计模型调用的成功率百分比 |
| 模型调用 P99 耗时 | histogram_quantile(0.99, sum(rate(ai_model_call_duration_seconds_bucket[1m])) by (le, model)) |
按模型拆分的 P99 耗时 |
| 当日 Token 总消耗量 | sum(increase(ai_model_token_usage_total[1d])) |
统计当日所有模型的 Token 总消耗 |
| 向量检索 QPS | sum(rate(ai_vector_search_total[1m])) |
向量检索的每秒请求数 |
| 向量缓存命中率 | sum(rate(ai_vector_cache_hit_total[1m])) / sum(rate(ai_vector_search_total[1m])) * 100 |
向量缓存的命中率百分比 |
| JVM 堆内存使用率 | sum(jvm_memory_used_bytes{area="heap"}) / sum(jvm_memory_max_bytes{area="heap"}) * 100 |
JVM 堆内存的使用率 |
6.4 告警规则配置:异常提前感知
光有监控还不够,我们还要配置告警规则,当服务出现异常时,第一时间收到通知。给大家分享几个核心的告警规则,配置在 Prometheus 的rules.yml里:
bash
groups:
- name: spring-ai-alert
rules:
# 模型调用成功率告警
- alert: 模型调用成功率过低
expr: sum(rate(ai_model_call_success_total[5m])) / sum(rate(ai_model_call_success_total[5m]) + rate(ai_model_call_fail_total[5m])) < 0.99
for: 2m
labels:
severity: critical
annotations:
summary: "模型调用成功率低于99%"
description: "当前成功率{{ $value | humanizePercentage }},请立即排查"
# 模型调用P99耗时告警
- alert: 模型调用耗时过高
expr: histogram_quantile(0.99, sum(rate(ai_model_call_duration_seconds_bucket[5m])) by (le)) > 2
for: 2m
labels:
severity: warning
annotations:
summary: "模型调用P99耗时超过2s"
description: "当前P99耗时{{ $value }}s,请排查模型API状态"
# Token消耗异常告警
- alert: Token消耗异常增长
expr: sum(increase(ai_model_token_usage_total[1h])) / sum(increase(ai_model_token_usage_total[1h] offset 1d)) > 1.5
for: 5m
labels:
severity: warning
annotations:
summary: "Token小时消耗环比增长超过50%"
description: "当前增长幅度{{ $value | humanizePercentage }},请关注成本"配置完成后,我们可以在 Grafana 里配置告警通知渠道,支持钉钉、企业微信、邮件、短信等,当告警触发时,就能第一时间收到通知了。
完整 Grafana 模板获取
我把我们生产环境在用的 Spring AI 监控大屏,做成了完整的 Grafana 模板,大家可以在评论区留言,我会把模板 JSON 文件发给大家,直接导入 Grafana 就能用,不用自己一个个配置面板。
7. 踩坑总结:可观察性体系搭建的避坑指南
最后,给大家总结一下我们搭建这套体系半年来,踩过的 8 个核心坑,大家可以直接避坑:
- 高基数标签打爆 Prometheus:绝对不要把 userId、requestId 这种高基数字段加到 Metrics 标签里,否则时序数据会指数级增长,直接把 Prometheus 搞崩;
- 异步调用 traceId 丢失:@Async 异步调用时,默认 MDC 里的 traceId 会丢失,需要用 TtlMDCAdapter 来透传,或者用 Sleuth 的异步支持;
- 全量日志打满磁盘:不要把完整的 Prompt 和响应都打印 INFO 级别日志,一定要做分级和采样,异常请求 100% 打印,正常请求采样打印;
- 敏感信息泄露:Prompt 和响应里可能包含用户隐私和企业敏感数据,一定要做脱敏处理,绝对不能明文存储和打印;
- 链路采样率设置不合理:生产环境不要设置 100% 的链路采样率,否则 Zipkin 的存储压力会非常大,建议设置 10% 的采样率,异常链路 100% 采集;
- 指标维度不够,无法定位问题:指标一定要加上模型名称、业务场景、接口名称这些标签,否则只能看到整体数据,无法细粒度定位问题;
- 日志和链路脱节:一定要把 traceId 加到日志里,这样通过 Zipkin 查到异常链路后,可以直接用 traceId 在 ELK 里查到完整的日志,实现一站式排查;
- 只监控不告警:监控的最终目的是提前发现问题,一定要配置合理的告警规则,不要等用户反馈了才知道服务出了问题。
8. 总结与展望
总结
AI 服务的可观察性体系,和普通 Java 服务有着本质的区别,它不是简单的搭一套监控、打几行日志就完事了,而是要围绕 AI 服务的核心痛点,从指标、链路、日志三个维度,构建一套专属的、全链路的可视化运维方案。
这篇文章里,我给大家完整分享了我们生产环境落地的 Spring AI 可观察性体系:
- 用 Micrometer 实现了 AI 服务专属的指标采集,覆盖了模型调用、Token 消耗、向量检索等核心指标;
- 用 Sleuth+Zipkin 实现了全链路追踪,把模型调用、向量检索都纳入了链路,1 分钟就能定位线上耗时瓶颈;
- 设计了 AI 服务专属的日志规范,实现了分级、采样、脱敏,既满足了排查和审计的需求,又控制了日志量;
- 从零搭建了 AI 服务监控大屏,给大家提供了可直接复用的 PromQL 语句和 Grafana 模板。
这套体系落地后,我们线上问题的平均排查时间从原来的 1 小时,缩短到了 5 分钟以内,服务可用性从 99.5% 提升到了 99.95%,同时也实现了 AI 服务成本的精细化管控。
展望
未来我们还会在这套体系的基础上,做进一步的优化:
- 接入 AIOps:用 AI 算法分析指标趋势,预测异常风险,实现故障的提前预警和自动止损;
- 根因分析自动化:当告警触发时,自动关联链路、日志、指标数据,给出根因分析和解决方案,不用人工排查;
- 合规审计体系:基于日志数据,构建 Prompt 和响应的合规审计体系,自动检测敏感内容和违规请求,满足等保和行业合规要求;
- 成本优化智能推荐:基于 Token 消耗指标,分析不同业务场景的模型使用效率,给出模型版本切换、Prompt 优化的建议,降低 API 成本。
参考文献
结语:以上就是 Spring AI 可观察性体系的全量实战分享,所有的代码和方案都是我们生产环境验证过的,大家可以直接落地。如果大家有任何问题,或者需要完整的代码和 Grafana 模板,欢迎在评论区留言,我会一一回复。如果觉得这篇文章对你有帮助,别忘了点赞、收藏、转发三连,后续我还会分享更多 Spring AI 架构优化的实战干货,感谢大家的支持!