往期精选文章推荐:
- 深入理解 go map
- go 常用关键字
- 深入理解 Go 数组、切片、字符串
- 深入理解channel
- 深入理解 go context
- 深入 go interface 底层原理
- 深入理解 go reflect
- 深入理解 go unsafe
为什么有go unsafe
Go 是支持指针的语言,但是为了保持简洁、安全,Go 的指针有很多限制,但是一些场景又需要绕过这些安全限制,因此提供了 unsafe 包,unsafe 可以绕过:指针运算、不同的指针类型不能转换、任意类型指针等限制,进而可以实现更高级的功能。
下面通过对比可以更直观的了解 unsafe 的特点:
支持指针运算
Go 的指针是不支持指针的,指针运算在直接操作内存有很大作用,例如:通过指针运算访问数组元素、或者通过指针运算访问结构体的导出字段等等。
go 指针
Go
var arr = [3]int{1, 2, 3}
ptr := &arr
fmt.Println(ptr++) // 报错
$ go run main.go
//./main.go:8:17: syntax error: unexpected ++, expecting comma or )unsafe.Pointer
Go
var arr = [3]int{1, 2, 3}
ptr := (unsafe.Pointer(uintptr(unsafe.Pointer(&arr)) + unsafe.Sizeof(arr[0])))
fmt.Println(*(*int)ptr)
$ go run main.go
2支持不同的指针类型转换
go 指针
Go
// go 指针
type MyInt int
func main() {
var num int = 5
var miPtr *MyInt
miPtr = &num
}
$ go run main.go
./main.go:12:8: cannot use &num (type *int) as type *MyInt in assignmentunsafe.Pointer
Go
// unsafe.Pointer
type MyInt int
func main() {
var num int = 5
var miPtr *MyInt
miPtr = (*MyInt)(unsafe.Pointer(&num))
fmt.Println(*miPtr)
}
$ go run main.go
5支持任意类型指针
unsafe.Pointer 的定义如下,其语义是任意类型的指针:
Go
type Pointer *ArbitraryTypeunsafe.Pointer 在 Go 源码中有广泛的应用,例如接口的底层数据结构:
Go
type iface struct {
tab *itab
data unsafe.Pointer
}
type eface struct {
_type *_type
data unsafe.Pointer
}data 字段就是 unsafe.Pointer 类型,意味着 data 可以存储任意类型的数据。
什么是 go unsafe
unsafe 是 Go 语言中的一个包,用于进行一些底层的、不安全的操作。
在 Go 语言中,通常强调的是安全性和内存安全性,以防止常见的编程错误,比如缓冲区溢出和悬空指针等。但在某些特定的场景下,可能需要突破这些安全限制来实现一些特殊的功能或优化性能。
使用 unsafe 包时需要非常谨慎,因为不正确的使用可能会导致程序出现难以调试的错误,甚至破坏程序的稳定性和安全性,应仅在有充分理由和完全理解其风险的情况下使用。
Unsafe 包比较简单,主要是通过 Pointer、Sizeof、Offsetof、Alignof 来实现一些高级特性。
unsafe.Pointer
可以说 unsafe.Pointer 是 unsafe 包里的重中之重,没有 unsafe.Pointer unsafe 包就没有存在的意义。我们先看一下unsafe.Pointer 的定义:
Go
// ArbitraryType is here for the purposes of documentation only and is not actually
// part of the unsafe package. It represents the type of an arbitrary Go expression.
type ArbitraryType int
type Pointer *ArbitraryTypeunsafe.Pointer 表示指向任意类型的指针。
什么是 uintptr
其实 unsafe.Pointer 本身并不支持指针运算,需要借助 uintptr 来实现指针运算,uintptr 的定义如下:
Go
// uintptr 是一种整数类型,具有足够大小,可以保存任何指针类型。
type uintptr uintptruintptr 在源码中有广泛的应用,一般用来保存整数形式的内存地址,因为 uintptr 是整数类型所以它可以进行运算:
Go
func main() {
var num1 int = 5
var num2 int = 5
p1 := uintptr(unsafe.Pointer(&num1))
p2 := uintptr(unsafe.Pointer(&num2))
fmt.Println("num1 的内存地址:", p1)
fmt.Println("num2 的内存地址:", p2)
}
$ go run main.go
num1 的内存地址: 824634183432
num2 的内存地址: 824634183424但是有一点需要注意:uintptr 并不具有指针语义,也就是 uintptr 保存的内存地址中的内容是可能被 GC 回收的。
unsafe.Pointer 类型转换
unsafe.Pointer 类型有四种特殊操作:
-
任何类型的指针值都可以转换为unsafe.Pointer。
-
unsafe.Pointer 也可以转换为任何类型的指针值。
-
uintptr 可以转换为 unsafe.Pointer。
-
unsafe.Pointer 可以转换为 uintptr。
因此,unsafe.Pointer 允许程序突破类型系统并读写任意内存,应谨慎使用unsafe.Pointer。

unsafe.Pointer 使用模式
unsafe.Pointer 如同双刃剑,在赋予强大功能的同时也伴随着风险。官方包中提供了几种相对安全的使用模式,然而即使遵循这些模式,也无法确保绝对的安全性。
使用 "go vet" 可以帮助找到不符合这些模式的 Pointer 的使用,但是"go vet"的沉默并不能保证代码有效。
(1)将 *T1 转换为指向 *T2 的指针。
如果想将 *T1 转换为 *T2 需要满足两个条件:
-
假设 unsafe.Sizeof(T2) 小于等于 unsafe.Sizeof(T1);
-
T1 和 T2 具有相同的内存布局(不是完全相同,保证T2大小范围内布局相同就行)。
Go
type T1 struct {
Name string
Age int
Language string
}
type T2 struct {
Name string
Age int
}
func main() {
t1 := &T1{Name: "xiaoming", Age: 18, Language: "golang"}
t2 := (*T2)(unsafe.Pointer(t1))
fmt.Println(t2.Name, t2.Age)
}
$ go run main.go
xiaoming 18(2)将指针转换为 uintptr(但不能转换回指针)。
将 Pointer 转换为 uintptr 会得到 Pointer 指向的内存地址,是一个整数。但是,将 uintptr 转换回 Pointer 通常无效。uintptr 是一个整数,而不是一个引用。将指针转换为 uintptr 会创建一个没有指针语义的整数值。 即使 uintptr 持有某个对象的地址,如果该对象移动,垃圾收集器也不会更新该 uintotr 的值, 也不会阻止该对象被回收。
如下面这种,我们取得了变量的地址 p,然后做了一些其他操作,最后再从这个地址里面读取数据:
Go
package main
import (
"fmt"
"unsafe"
)
func main() {
var a int = 10
var p = uintptr(unsafe.Pointer(&a))
// ... 其他代码
// 下面这种转换是危险的,因为有可能 p 指向的对象已经被垃圾回收器回收
fmt.Println(*(*int)(unsafe.Pointer(p)))
}(3)通过算术运算,将 unsafe.Pointer 转换为 uintptr 并转换回来。
如果 p 指向一个已分配的对象,我们可以将 p 转换为 uintptr 然后加上一个偏移量,再转换回 Pointer。如:
Go
p = unsafe.Pointer(uintptr(p) + offset)此模式最常见的用途是访问结构中的字段或数组中的元素:
Go
// equivalent to f := unsafe.Pointer(&s.f)
f := unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Offsetof(s.f))
// equivalent to e := unsafe.Pointer(&x[i])
e := unsafe.Pointer(uintptr(unsafe.Pointer(&x[0])) + i*unsafe.Sizeof(x[0]))这种模式有几个注意点:
- 将指针加上一个超出其原始分配的内存区域的偏移量是无效的:
Go
// INVALID: end points outside allocated space.
var s thing
end = unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Sizeof(s))
// INVALID: end points outside allocated space.
b := make([]byte, n)
end = unsafe.Pointer(uintptr(unsafe.Pointer(&b[0])) + uintptr(n))- Pointer => uintptr, uintptr => Pointer两种转换必须出现在同一个表达式中,并且它们之间只有中间的算术:
Go
// INVALID: uintptr cannot be stored in variable
// before conversion back to Pointer.
u := uintptr(p)
p = unsafe.Pointer(u + offset)- unsafe.Pointer必须指向分配的对象,因此它不能为零。
Go
// INVALID: conversion of nil pointer
u := unsafe.Pointer(nil)
p := unsafe.Pointer(uintptr(u) + offset)(4)调用 syscall.Syscall 时将指针转换为 uintptr。
syscall 包中的 Syscall 函数将其 uintptr 参数直接传递给操作系统,然后操作系统可能会根据调用的细节将其中一些参数重新解释为指针。也就是说,系统调用实现会隐式地将某些参数从 uintptr 转换回指针。
如果一个指针参数必须转换为 uintptr 以用作参数,那么该转换必须出现在调用表达式本身中:
Go
syscall.Syscall(SYS_READ, uintptr(fd), uintptr(unsafe.Pointer(p)), uintptr(n))(5)将 reflect.Value.Pointer 或 reflect.Value.UnsafeAddr 的结果从 uintptr 转换为 Pointer。
reflect.Value 的 Pointer 和 UnsafeAddr 方法返回类型 uintptr 而不是 unsafe.Pointer, 从而防止调用者在未引入 unsafe 包的情况下将结果更改为任意类型。(这是为了防止开发者对 Pointer 的误操作。) 然而,**这也意味着这个返回的结果是脆弱的,我们必须在调用之后立即转换为 **Pointer(如果我们确切的需要一个 Pointer):
Go
p := (*int)(unsafe.Pointer(reflect.ValueOf(new(int)).Pointer()))与上述情况一样,存储转换之前的结果是无效的:
Go
// INVALID: uintptr cannot be stored in variable
// before conversion back to Pointer.
u := reflect.ValueOf(new(int)).Pointer() // u 指向的内存可能被回收
p := (*int)(unsafe.Pointer(u))(6)reflect.SliceHeader或reflect.StringHeader数据字段与unsafe.Pointer互转
与前一种情况一样,反射数据结构 SliceHeader 和 StringHeader 将字段 Data 声明为 uintptr,以防止调用者在未先引入"unsafe"的情况下将结果更改为任意类型。但是,这意味着 SliceHeader 和 StringHeader 仅在解释实际切片或字符串值的内容时有效。
Go
var s string
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // case 1
hdr.Data = uintptr(unsafe.Pointer(p)) // case 6 (this case)
hdr.Len = nunsafe.Sizeof
Go
// src/unsafe/unsafe.go
func Sizeof(x ArbitraryType) uintptrSizeof 返回任意类型变量 x 所占用内存字节大小,这个大小不包含 x 底层引用的内存大小。例如,如果 x 是一个切片,那么 Sizeof 返回的是切片描述符的大小,而非切片所引用的内存的大小。
Go
func main() {
var num1 int8 = 5
var num2 int16 = 5
var slice1 []int = []int{1, 2, 3}
var slice2 []string = []string{"hello", "wrold"}
fmt.Println("num1 sizeof: ", unsafe.Sizeof(num1))
fmt.Println("num2 sizeof: ", unsafe.Sizeof(num2))
fmt.Println("slice1 sizeof: ", unsafe.Sizeof(slice1))
fmt.Println("slice2 sizeof: ", unsafe.Sizeof(slice2))
}
$ go run main.go
num1 sizeof: 1
num2 sizeof: 2
slice1 sizeof: 24
slice2 sizeof: 24unsafe.Offsetof
Go
// src/unsafe/unsafe.go
func Offsetof(x ArbitraryType) uintptrunsafe.Offsetof 返回 x 表示的字段在结构体中的偏移量,该字段必须采用 structValue.field 形式。换句话说,它返回结构体开头和字段开头之间的字节数。
Go
type Programmer struct {
Name string
Age int
}
func main() {
p := Programmer{}
NameOffset, AgeOffset := unsafe.Offsetof(p.Name), unsafe.Offsetof(p.Age)
fmt.Println("name offset: ", NameOffset)
fmt.Println("age offset: ", AgeOffset)
}
$ go run main.go
name offset: 0
age offset: 16unsafe.Alignof
Go
// src/unsafe/unsafe.go
func Alignof(x ArbitraryType) uintptrAlignof 返回某一个类型的对齐系数,就是对齐一个类型的时候需要多少个字节。 它与reflect.TypeOf(x).Align()返回的值相同。作为一种特殊情况,如果变量 s 是结构体类型并且 f 是该结构体中的字段,则 Alignof(s.f) 将返回结构体中该类型字段所需的对齐方式。这种情况与reflect.TypeOf(s.f).FieldAlign()返回的值相同。
Go
type Programmer struct {
Name string
Age int
}
func main() {
p := Programmer{}
fmt.Println("age Alignof: ", unsafe.Offsetof(p.Age))
}
$ go run main.go
age Alignof: 16后面会有专门文章讨论内存对齐,这里不详细展开。
unsafe 示例
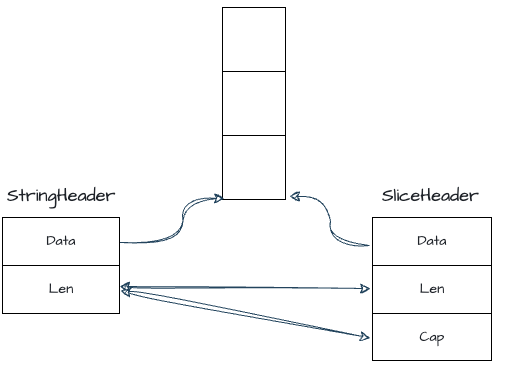
\[\]byte与string 高效互转
我们知道slice 和 string 的底层数据结构非常类似,并且 \[\]byte 和 string 都是基于字符数组实现的,所以通过共享底层字符数组技能实现零拷贝的转换。
slice 和 string 的底层数据结构:
Go
type StringHeader struct {
Data uintptr
Len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
\[\]byte与string 高效互转的实现:
Go
func string2bytes(s string) []byte {
stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
bh := reflect.SliceHeader{
Data: stringHeader.Data,
Len: stringHeader.Len,
Cap: stringHeader.Len,
}
return *(*[]byte)(unsafe.Pointer(&bh))
}
func bytes2string(b []byte) string{
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sh := reflect.StringHeader{
Data: sliceHeader.Data,
Len: sliceHeader.Len,
}
return (string)(unsafe.Pointer(&sh))
}但是需要注意的是使用 string2bytes 时如果入参字符串所引用字符数组是不可更改的情况,转换后\[\]byte也是不可修改的:
Go
package main
import (
"fmt"
"unsafe"
"reflect"
)
func main() {
s := "hello" // 字符串字面量被存储在只读的数据段中。
bs := string2bytes(s)
bs[0] = 'a' // 这块会编译报错,不可修改
fmt.Println(bs[0])
}
$ go run main.go直接访问数组的元素
Go
package main
import (
"fmt"
"unsafe"
)
func main() {
arr := [5]int{1, 2, 3, 4, 5}
ptr := unsafe.Pointer(&arr[0])
for i := 0; i < len(arr); i++ {
value := *(*int)(unsafe.Pointer(uintptr(ptr) + uintptr(i)*unsafe.Sizeof(arr[0])))
fmt.Println(value)
}
}通过数组的起始地址 + 每个元素的偏移量就能访问数组元素。
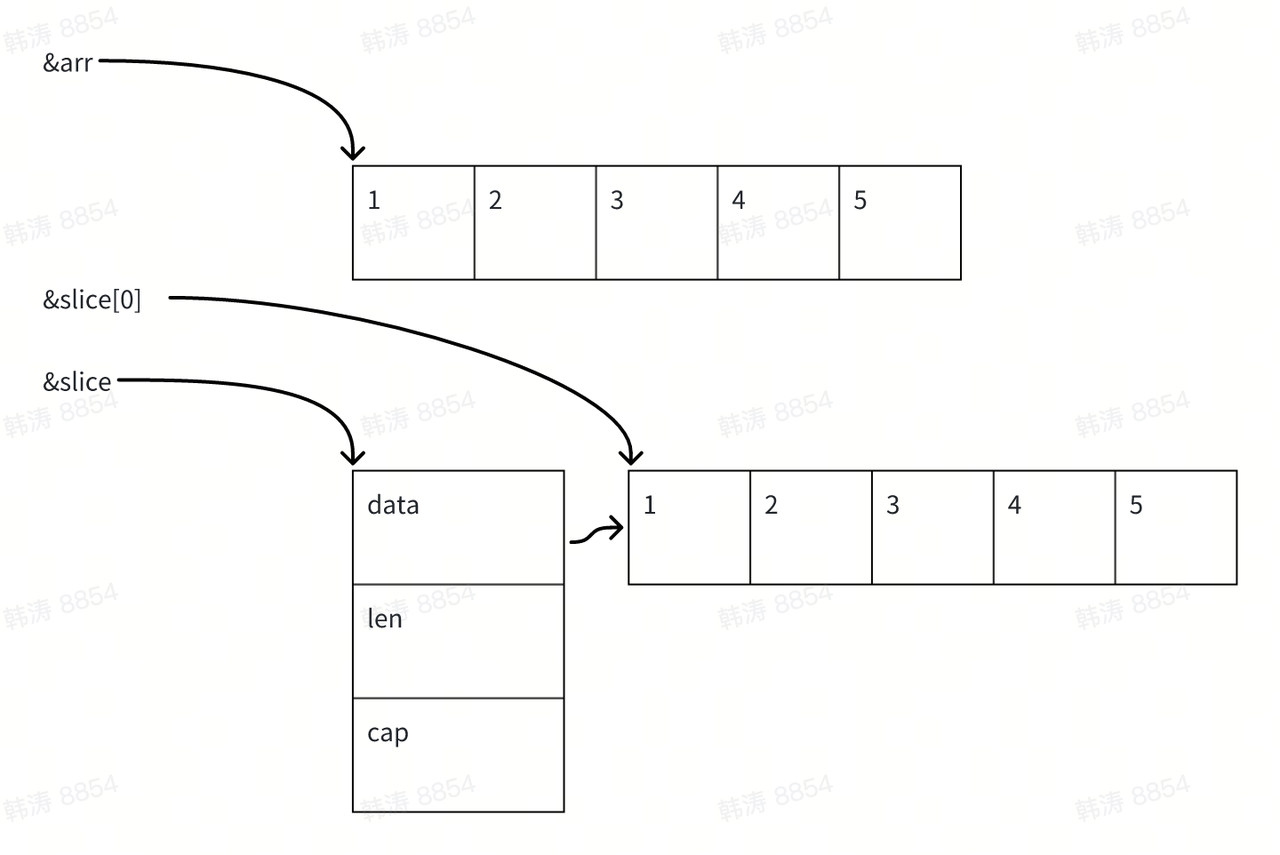
直接访问切片的元素
访问切片元素和访问数组元素的方式差不多,但是需要注意的是:要是使用 &slice0代表切片的起始位置,而数组直接使用数组指针就行。
Go
arr := [5]int{1, 2, 3, 4, 5}
slice := []int{1, 2, 3, 4, 5}如下图所示:&arr代表数组的起始位置,&slice 代表切片结构体的起始位置, &slice0代表切片底层数组的起始位置。
Go
package main
import (
"fmt"
"unsafe"
)
func main() {
slice := []int{1, 2, 3, 4, 5}
// 获取切片底层数组的指针
ptr := unsafe.Pointer(&slice[0])
ptr = unsafe.Pointer(uintptr(ptr) + uintptr(2)*unsafe.Sizeof(slice[0]))
// 直接修改底层数组的值
*(*int)(ptr) = 10
fmt.Println(slice)
}
$ go run main.go
[1 2 10 4 5]访问结构体未导出字段
同样是通过起始地址加上偏移量就能访问结构体字段:
Go
// 其他包里面定义的结构体
type Programmer struct {
name string
age int
language string
}
Go
// 在 main 包里引用结构体
func main() {
p := programmer.Programmer{}
fmt.Println(p)
name := (*string)(unsafe.Pointer(&p))
age := (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Sizeof(string(""))))
lang := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Sizeof(int(0)) + unsafe.Sizeof(string(""))))
*name = "Tom"
*age = 23
*lang = "Golang"
fmt.Println(p)
}
$ go run main.go
{ 0 }
{Tom 23 Golang}由于我们访问的是未导出字段,因此无法使用unsafe.Offsetof,只能通过将字段大小相加的方式来计算偏移量。然而,这样做存在一个问题:在计算偏移量时,如果存在内存对齐,那么计算出的偏移量就不准确了。因此,我们还需要加上内存对齐的偏移量。不同平台上的内存对齐结果也可能不同。
绕过类型检查
Go
package main
import (
"fmt"
"unsafe"
)
func main() {
var num1 int = 10
var num2 float64
// 绕过类型检查进行赋值
num2 = *(*float64)(unsafe.Pointer(&num1))
fmt.Println(num2)
}
$ go run main.go
5e-323这种转换的结果往往不是我们想要的,大家一定要小心使用。