数据虚拟化(Data Virtualization)是对数据资源的抽象,通过屏蔽数据资源的存储位置和访问方式,能够将不同数据源、不同格式的数据资源,进行逻辑上的整合集成。这一技术方案与过去面对传统数仓的弊端,业界过去经常采取的方式 Presto 方案有一定相似,但存在明显差别。
Presto 的架构本质上是一个 MPP 的引擎,其架构导致绝大部分使用 Presto 的场景都是在 ETL 最末端的消费层 ,本身面向的是 OLAP 查询。但是 Presto 可以支持跨源查询,如果想延伸到数据仓库,就意味着需要获取支持大规模数据构建的能力,而 Presto 的架构便无法再支持。
所以,数据虚拟化不等于 Presto,Presto 可以解决一部分类似于虚拟化的问题,但无法支持大规模数据构建,限制了其在数据仓库领域的应用。
其实,早期的虚拟化技术也能解决部分数据采集、数据转换的问题,而Aloudata 的数据虚拟化技术却能做到面向全场景的能力,其核心最关键的就在于 RP 技术的突破。
RP(Relational Projection)的全称是关系投影,可以理解为是一个简化传统物理作业的过程。以前 ETL 工程师需要编写 SQL,并要将数据插入到物理表中,而现在,只需编写生成数据的逻辑,再也不必关心数据是否插入了物理表。
RP 跟传统的 OLAP 引擎里面的物化视图有明显不同。传统的物化视图更多面向一些大的 SQL 的性能加速,更多的是一种加速或缓存,这种特征代表了其丢失后不会产生影响。RP 实际对标着 ETL 同学研发的作业,以前在数仓中,如果 ETL 研发作业、作业数据出现问题,查询失误则不可避免。因此物化视图与RP 的定位是不同的,在技术设计方案上也有着极大差别,包括:
一、多层 RP 构建与调度:这些真实物理作业生成的 RP 与 ETL 作业并无差别,也会有强弱依赖、分区对齐、跨周期依赖等,但其是自动生成的,而非人工配置。此外,RP 支持大规模的数据构建,支持自动推导判断全量构建、增量构建或分区构建;
二、数据的多版本能力 :RP 的数据有多个版本,而物化视图则是缓存逻辑,数据一旦构建出错,其物化视图就失效了;RP和数据通过版本切换及数据缝合技术实现新老数据的切换和组合。
三、PRP(Predictive Relational Projection)技术:这是我们在技术上取得的一个较大的突破,可以通过根据的用户的查询历史,以及定义资产的关系来实现自适应的智能加速方案;
四、RP 的自动回收:从数据仓库或 ETL 同学的视角来看,很多数仓作业在上线之后便无人关心其使用情况和生命周期的问题,造成只上不下的局面。因此,数仓数据越堆越多,必然需要通过治理来降低其计算存储成本。在拥有虚拟化之后,此过程凭借自动回收能力,取消人工操作步骤。
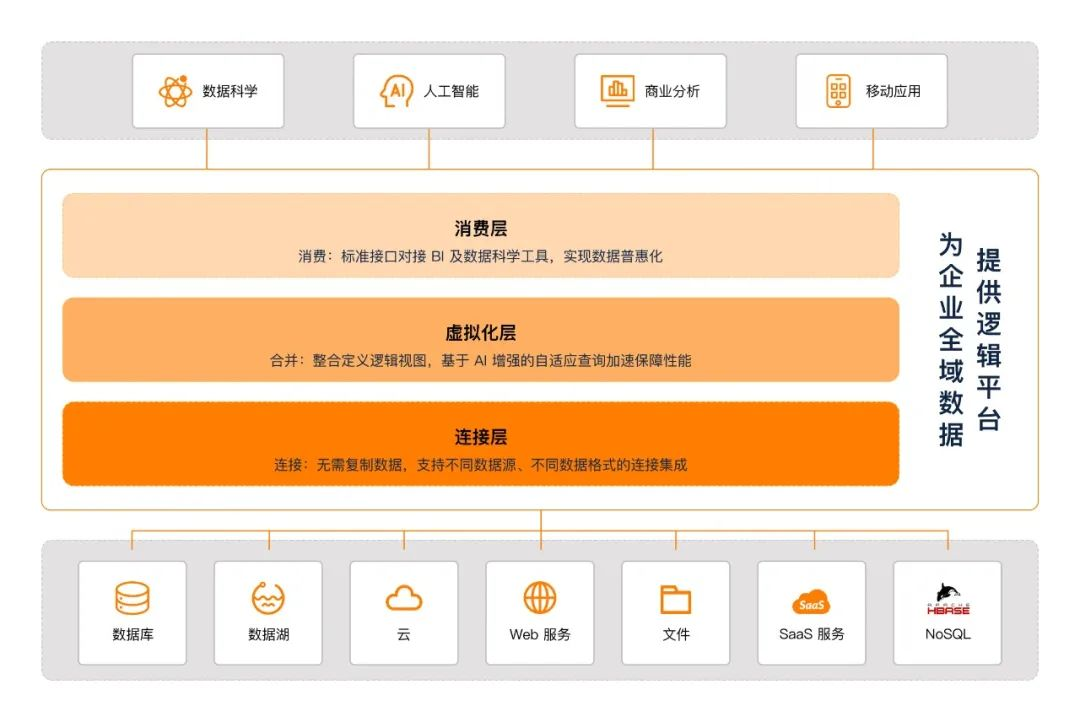
说完了数据虚拟化的技术原理,我们再来看一下数据虚拟化的应用架构,它主要包括两种典型的架构,不同的应用架构对应的应用场景也不相同:
单层的虚拟化架构:通过一个虚拟化层把公司所有元数据连接在一起,随时可用;
多层的虚拟化架构:更多的是用于集团性公司或分地域的、多层级的公司。由于组织架构的复杂性,对数据使用有着严格的隔离和权限要求,很多情况下不具备将数据进行物理集中的条件,但又希望能够实现全域数据要素的流通和价值挖掘。
值得一提的是,作为 Data Fabric 架构理念的实践者与引领者,依托于自研的数据虚拟化技术,Aloudata 打造了国内首个逻辑数据平台------Aloudata AIR,能够帮助用户轻松实现全域数据的逻辑连接、快速访问和查询,并能够根据业务分析需求,进行跨数据源的数据整合,以及灵活开展数据分析和应用工作。
同时,Aloudata AIR 支持全局数据资产目录和统一数据服务,为下游用户与应用提供了统一的数据发现和访问入口,解决了"数据孤岛"造成的全域数据查找难、跨源查询难和集中安全治理等问题;支持人工指定物化加速和 AI 增强的自适应物化加速,基于用户查询行为,实现自动化物化链路编排和智能查询下推,让用户无需担心虚拟化带来的大数据量查询性能问题,实现全域数据更低成本、更实时地流通和消费。
目前,Aloudata AIR 逻辑数据平台已帮助招商银行构建了统一的敏捷数据使用平台,使业务团队在一个地方即可统一查找和理解数据,并通过逻辑视图定义和自动化编排,轻松处理和准备数据,每月由业务团队自助生成的数据已占总数据的 70% 以上。同时,动态集成和自动化编排减少了不必要的数据复制、计算和存储,至少节约了 50% 以上的存算成本。访问Aloudata 官网,即刻了解。