在当今数据驱动型时代,数据采集和分析能力算是个人和企业的核心竞争力。然而,手动采集数据耗时费力且效率低下,而且容易被网站封禁。
我之前使用过一个爬虫工具,亮数据(Bright Data) ,是一款低代码爬虫平台,既有现成的爬虫解锁框架,还提供IP代理服务。

亮数据网站:https://get.brightdata.com/weijun
亮数据基于全球代理IP网络和强大数据采集技术的解决方案,可帮助轻松采集各种网页数据,如产品信息、价格信息、评论信息、社交媒体数据等。

它提供了数据采集浏览器、网络解锁器、数据采集托管IDE三种方式,能通过简单的几十行Python代码实现复杂网络数据的采集,对于反爬、验证码、动态网页等进行自动化处理,完全不需要你操心。
而且你无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
亮数据浏览器支持对多个网页进行批量数据抓取,适用于需要JavaScript渲染的页面或需要进行网页交互的场景。

另外,亮数据浏览器内置了自动网站解锁功能,能够应对各种反爬虫机制,确保数据的顺利抓取。它能兼容多种自动化工具,如Puppeteer、Playwright和Selenium等,用户可以根据需求选择合适的工具进行数据抓取。
主要优势:
-
平台化操作:无需搭建服务器,可直接在平台上创建、管理爬虫任务
-
数据源丰富:支持网页、API、数据库等多种数据源
-
模板化服务:提供丰富的爬虫模板,快速创建爬虫任务
使用方法:
-
注册亮数据账号
-
创建爬虫任务,选择数据源
-
选择爬虫模板或编写爬虫代码
-
设置任务参数,包括采集规则、数据存储等
-
点击"启动任务"按钮,即可获取数据

有数据抓取需求的可以试试,非常简单,能节省大量时间和精力!!!
如下是使用亮数据浏览器采集亚马逊电商数据的简单步骤:
1、登录亮数据网站
https://get.brightdata.com/weijun
2、选择亮数据浏览器
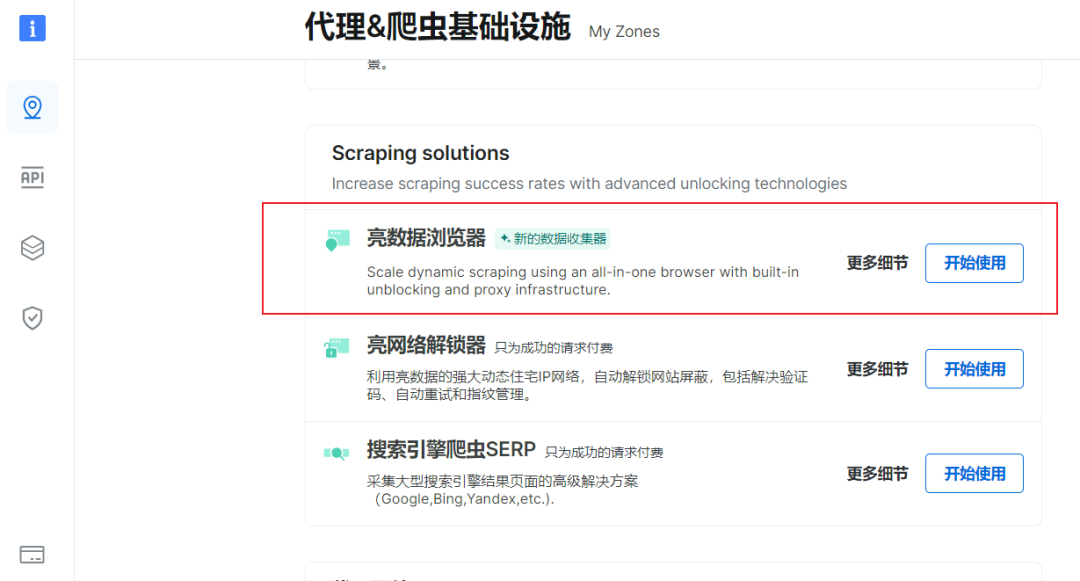
3、选择和命名通道
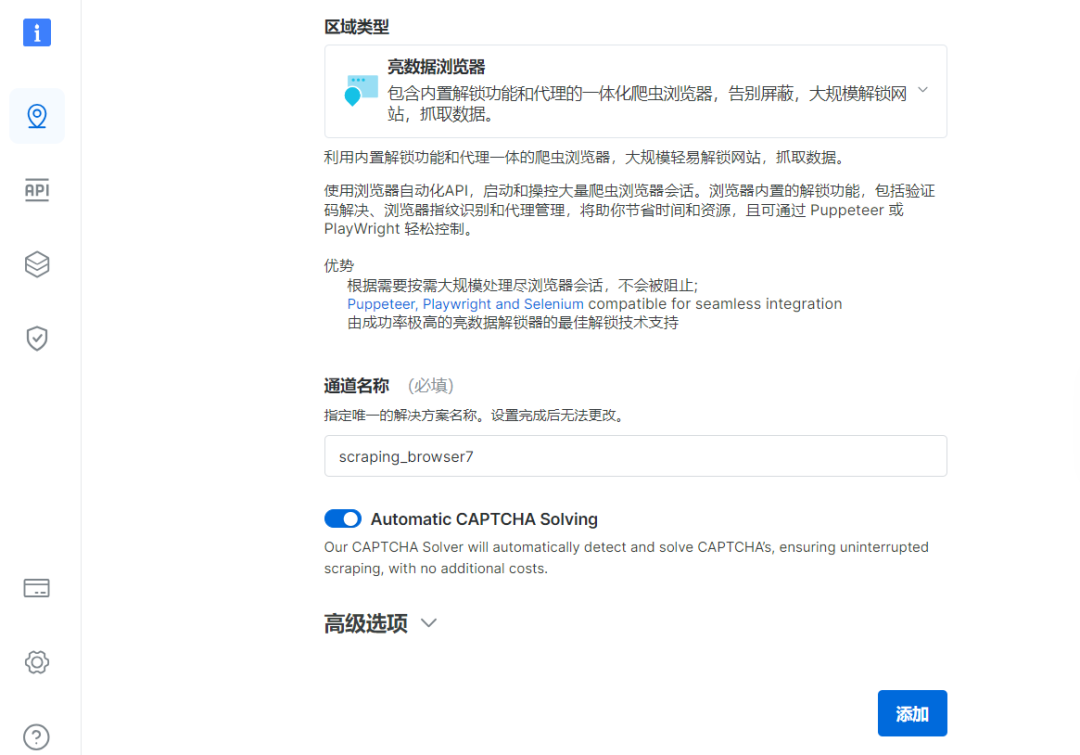
4、设置IP权限
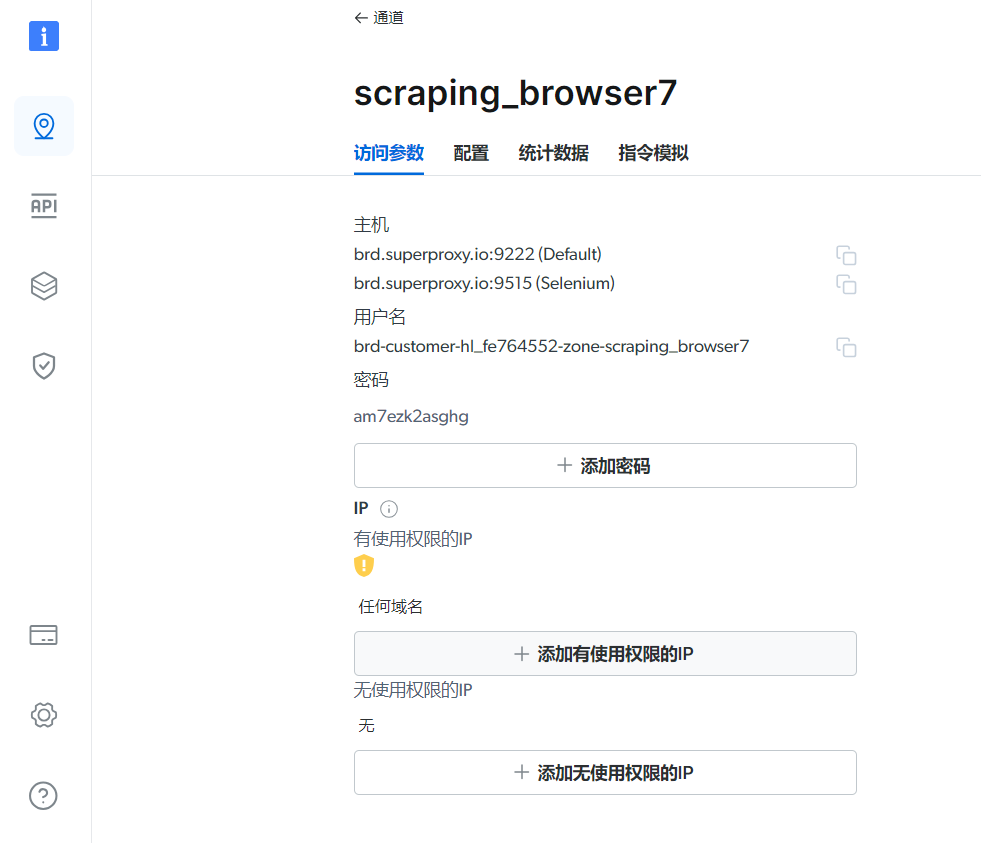
5、生成代码示例


6、添加需要爬取的网站,设置爬虫语言和框架
这里添加的亚马逊IPhone商品页,爬虫语言选择Python,框架选择selenium

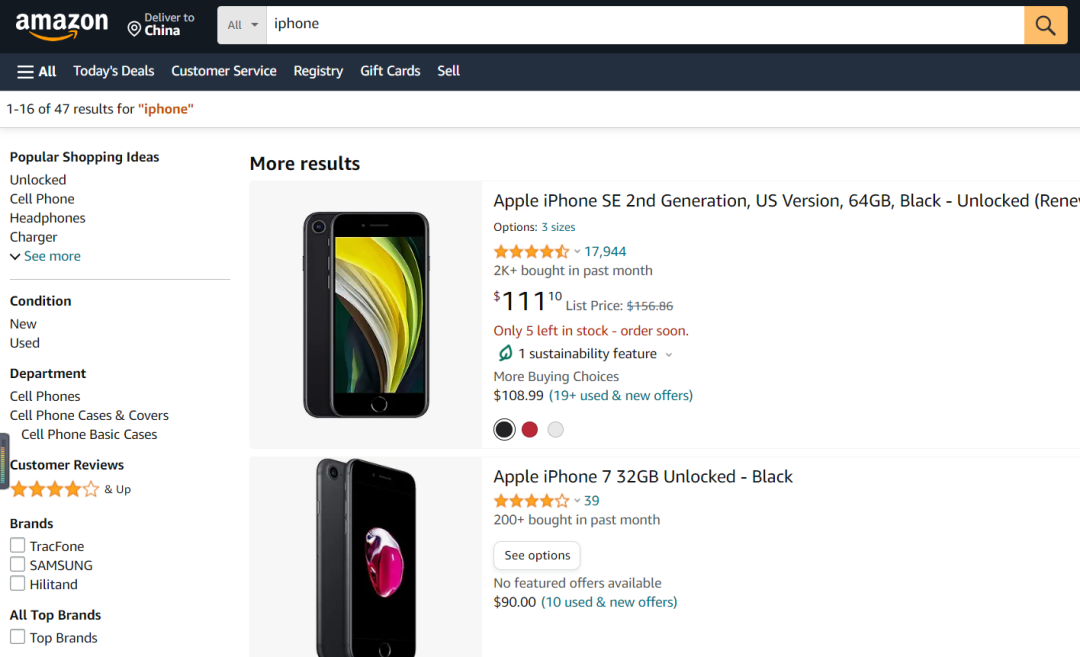
如下是代码:
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
SBR_WEBDRIVER = 'https://brd-customer-hl_fe764552-zone-scraping_browser7-country-gb:am7ezk2asghg@brd.superproxy.io:9515'
def main():
print('Connecting to Scraping Browser...')
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating to https://www.amazon.com/s?k=iphone...')
driver.get('https://www.amazon.com/s?k=iphone')
# CAPTCHA handling: If you're expecting a CAPTCHA on the target page, use the following code snippet to check the status of Scraping Browser's automatic CAPTCHA solver
# print('Waiting captcha to solve...')
# solve_res = driver.execute('executeCdpCommand', {
# 'cmd': 'Captcha.waitForSolve',
# 'params': {'detectTimeout': 10000},
# })
# print('Captcha solve status:', solve_res['value']['status'])
print('Navigated! Scraping page content...')
html = driver.page_source
print(html)
if __name__ == '__main__':
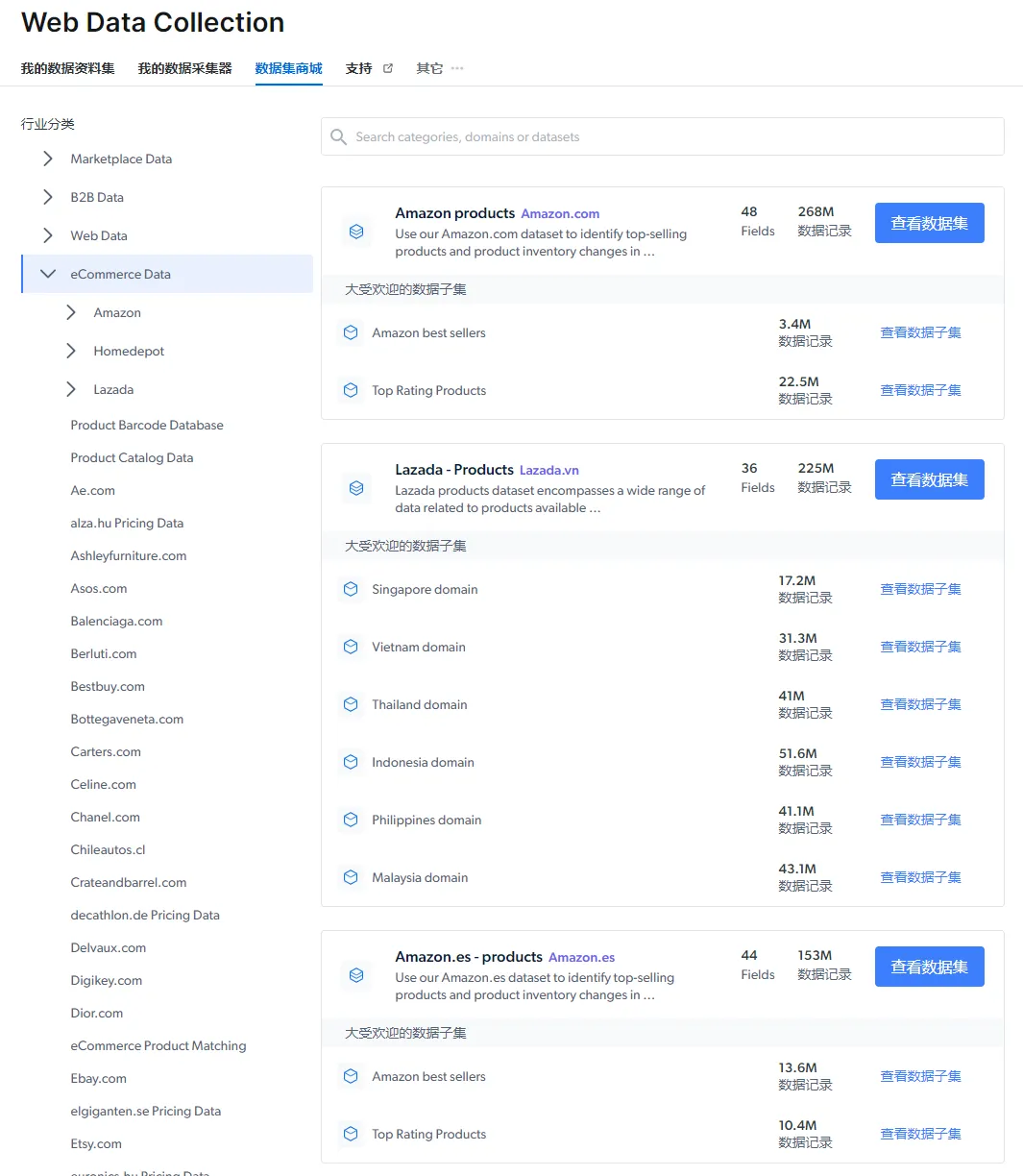
main()除了爬虫外,亮数据也提供了现成的数据集,包括电商、社媒、金融、新闻、视频等等
这些现成的数据集,对于有数据分析需求的人来说非常有节省时间,可以做市场分析、训练模型等等。