从海量信息中脱颖而出:Workflow智能分析解决方案,大语言模型为AI科技文章打造精准摘要评分体系(总篇章)
1.简介
该项目整合了编程、AI、产品设计、商业科技及个人成长等多领域的精华内容,源自顶尖技术企业和社群。借助先进语言模型技术,对精选文章进行高效摘要、专业评分及多语种翻译,实现了从初步评估到深入剖析,再到传播的全面自动化流程。通过引入Workflow平台,该项目显著提升了内容处理的速度与质量,为读者带来更加便捷、精准且多元化的阅读体验,满足了不同背景与需求的学习者及专业人士的信息渴求。
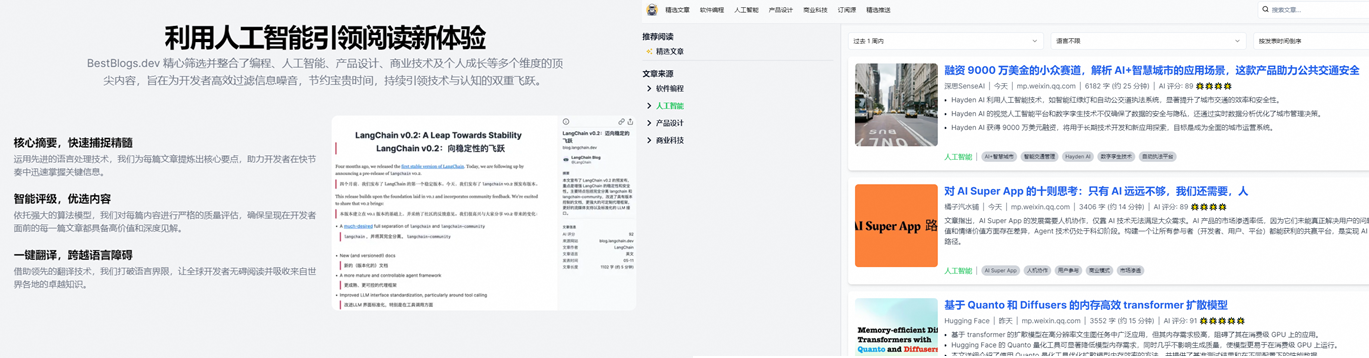
其主要原理是通过 RSS 订阅和爬虫,收集来自各个领域的优质博客文章,并通过大语言模型进行筛选和评估,以提高内容的质量和效率。其核心特性包括:
- 精准核心摘要,高效信息获取:采用前沿的大语言模型技术,精准提炼每篇文章的核心精髓,使读者即便在忙碌中也能迅速抓住关键信息,提升阅读效率与质量。
- 智能多维度评分,优质内容甄选:严格筛选文章来源,依托大语言模型的强大能力,从内容深度、写作质量、实用价值及关联性等多个维度进行综合评价,确保为读者推荐的都是经过精心挑选的优质内容。
- 无缝多语言翻译,全球知识共享:借助行业领先的翻译解决方案,旨在打破语言壁垒,让开发者都能轻松跨越语言障碍,自由访问并吸收世界各地宝贵的专业知识与见解,促进全球知识的无缝交流与共享。
- Workflow优势
原方案采用了一揽子大而全的提示词策略来处理文章的摘要、标签生成、评分及翻译,然而,这种综合性方法带来了多重挑战,包括摘要遗漏关键信息、标签不统一、评分机制调整复杂、翻译结果生硬,以及运维过程中的修改、测试与部署效率低下。原网站采用了一揽子大而全的提示词策略来处理文章的摘要、标签生成、评分及翻译,然而,这种综合性方法带来了多重挑战,包括摘要遗漏关键信息、标签不统一、评分机制调整复杂、翻译结果生硬,以及运维过程中的修改、测试与部署效率低下。

1.0 Workflow应该如何选择
在选择AI应用开发平台时,了解不同平台的功能、社区支持以及部署便捷性是非常重要的。在选择AI应用开发平台时,了解不同平台的功能、社区支持以及部署便捷性是非常重要的。
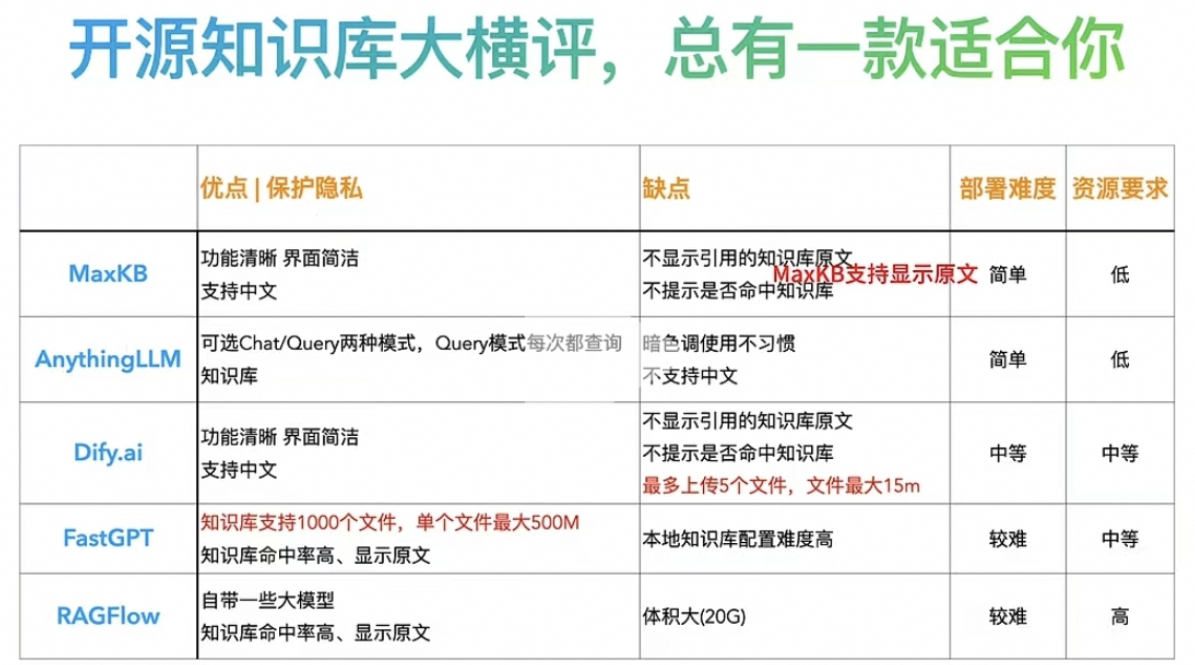
1.0.1 MaxKB/Dify的优势与劣势
-
优势
-
大模型接入灵活性:提供了多种大模型接入方式,支持多种API接口,使得开发者可以根据需求灵活选择和切换模型,这对于需要高性能模型的应用场景尤为重要。 -
强大的Chat功能:Chat功能不仅支持多轮对话,还能通过智能推荐和上下文理解提升用户体验,适用于需要复杂交互的场景。 -
丰富的知识库支持:内置了知识库管理系统,支持多种数据格式的导入和导出,便于用户管理和利用知识资源。 -
高效的Workflow设计:Workflow设计简洁直观,支持拖拽式操作,使得非技术人员也能快速上手,大大降低了使用门槛。 -
Prompt IDE:提供的Prompt IDE工具,让开发者可以更直观地调试和优化提示词,提升了开发效率。
-
-
劣势
-
学习曲线:虽然界面设计较为友好,但对于初学者来说,仍需要一定时间来熟悉其工作流程和功能。 -
社区支持:相较于一些成熟的开发平台,社区活跃度和资源丰富度还有待提升,这可能会影响到开发者在遇到问题时的解决速度。 -
定制化程度:虽然Dify提供了丰富的功能,但在某些高度定制化的需求上,可能还需要进一步的开发和调整。
-
1.0.2 FastGPT/RagFlow的优势与劣势
-
优势
-
Agent智能体:Agent智能体功能强大,能够自动执行复杂任务,减少了人工干预的需求,适用于需要自动化处理大量任务的场景。 -
LLMOps支持:提供了LLMOps支持,使得开发者可以更方便地进行模型训练、优化和部署,这对于AI模型的持续迭代和优化至关重要。 -
后端即服务:提供了后端即服务的功能,简化了后端开发流程,使得开发者可以更专注于前端和业务逻辑的开发。 -
强大的RAG引擎:RAG引擎能够高效地处理和检索大量数据,适用于需要快速响应和高吞吐量的应用场景。
-
-
劣势
-
功能复杂性:FastGPT的功能较为复杂,对于初学者来说,可能需要较长时间来掌握其使用方法和技巧。 -
部署难度:相较于一些轻量级的开发平台,FastGPT的部署过程可能更为复杂,需要一定的技术背景和经验。 -
用户界面:虽然FastGPT的功能强大,但其用户界面可能不如一些竞争对手直观和友好,这可能会影响到用户的使用体验。
-
1.0.3 根据需求选择平台
选择合适的平台首先要明确自己的需求。Dify和FastGPT各有特点,适用于不同的应用场景。
-
MaxKB/Dify:适合需要快速构建和部署AI应用的开发者,提供了丰富的预设模板和集成工具,使得开发者可以快速上手,尤其适合初学者和需要快速验证想法的团队。
-
FastGPT/RagFlow:适合需要高度定制化和复杂工作流的企业级用户,提供了强大的RAG引擎和Workflow orchestration,能够处理复杂的业务逻辑和数据处理需求。
-
在选择平台时,应考虑以下因素:
-
项目规模:如果是小型项目或初创团队,MaxKB/Dify的快速部署和简单易用性可能更适合。如果是大型企业级项目,FastGPT/RagFlow的强大功能和定制化能力更为合适。
-
技术栈:考虑团队现有的技术栈和成员的技术背景。在技术实现上有所不同,选择与团队技术栈匹配的平台可以减少学习成本和开发难度。
-
功能需求:明确项目所需的核心功能,如大模型接入、Chat功能、知识库等。Dify和FastGPT在这些功能上各有优势,根据具体需求进行选择。
-
1.0.4 社区与支持对比
社区支持和资源丰富度对于平台的选择也至关重要。
-
MaxKB/Dify:拥有一个活跃的社区,提供了丰富的文档、教程和示例代码。社区成员经常分享使用心得和解决方案,对于遇到的问题可以快速得到帮助。
-
FastGPT/RagFlow:社区相对较小,但提供了专业的技术支持团队。对于企业级用户,FastGPT提供了定制化的技术支持和咨询服务,确保项目的顺利进行。
-
在选择平台时,应考虑以下因素:
-
社区活跃度:活跃的社区意味着更多的资源和更快的解决问题速度。社区活跃度较高,适合需要快速解决问题的开发者。
-
技术支持:对于企业级用户,专业的技术支持至关重要。提供了专业的技术支持,适合对技术支持有较高要求的用户。
-
1.0.5 部署与使用便捷性
部署和使用的便捷性直接影响开发效率和成本。
-
MaxKB/Dify:提供了简单易用的界面和一键部署功能,使得开发者可以快速将应用部署到云端或本地。文档详细,适合初学者快速上手。
-
FastGPT/RagFlow:部署相对复杂,需要一定的技术背景和配置。提供了强大的定制化能力,适合对性能和功能有较高要求的用户。
-
在选择平台时,应考虑以下因素:
-
部署难度:MaxKB/Dify的部署过程简单,适合需要快速部署的开发者。FastGPT/RagFlow的部署相对复杂,但提供了更多的配置选项。
-
使用便捷性:MaxKB/Dify的用户界面友好,操作简单。FastGPT/RagFlow的用户界面相对复杂,但提供了更多的功能和定制化选项。## 7.0 优劣势选择
-
1.1 RSS 源订阅
网站文章来源于以下所有 RSS 订阅源(200个):
其中微信公众号转 RSS 采用 wewe-rss 项目搭建,目前已支持的微信公众号 RSS 订阅源(200个)整理如下:
具体资料见码源:BestBlogsRSS.opml、WeWeRSS.opml文件
- 更多技术细节参考RSSHUB:https://github.com/DIYgod/RSSHub
-
wewe-rss:https://github.com/cooderl/wewe-rss
-
阿里技术
xml
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<id>/feeds/MP_WXS_3885737868.atom</id>
<title>阿里技术</title>
<updated>2024-04-18T09:37:25.000Z</updated>
<generator>WeWe-RSS</generator>
<author>
<name>阿里技术</name>
</author>
<link rel="alternate" href="/feeds/MP_WXS_3885737868.atom"/>
<subtitle>阿里技术官方号,阿里的硬核技术、前沿创新、开源项目都在这里。</subtitle>
<logo>http://wx.qlogo.cn/mmhead/Q3auHgzwzM4bGHHEe4N3y73ILDk0Jv7DPug7bZoBE1lFlYGxbvQJHg/0</logo>
<icon>http://wx.qlogo.cn/mmhead/Q3auHgzwzM4bGHHEe4N3y73ILDk0Jv7DPug7bZoBE1lFlYGxbvQJHg/0</icon>
<entry>
<title type="html"><![CDATA["JVM" 上的AOP:Java Agent 实战]]></title>
<id>0ReJc-4df5Ga0FacvNbz6Q</id>
<link href="https://mp.weixin.qq.com/s/0ReJc-4df5Ga0FacvNbz6Q"/>
<updated>2024-08-16T00:41:14.000Z</updated>
</entry>
<entry>
<title type="html"><![CDATA[MySQL 8.0:filesort 性能退化的问题分析]]></title>
<id>nvsuJnHXVfP8m08uJSElUg</id>
<link href="https://mp.weixin.qq.com/s/nvsuJnHXVfP8m08uJSElUg"/>
<updated>2024-08-13T07:52:16.000Z</updated>
</entry>
<entry>
<title type="html"><![CDATA[前端在线代码编辑器技术杂谈]]></title>
<id>VEV6RmOdZpAg7RBQzDmfUA</id>
<link href="https://mp.weixin.qq.com/s/VEV6RmOdZpAg7RBQzDmfUA"/>
<updated>2024-08-08T14:38:21.000Z</updated>
</entry>
</feed>- 新智元
xml
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<id>/feeds/MP_WXS_3271041950.atom</id>
<title>新智元</title>
<updated>2024-04-09T05:05:12.000Z</updated>
<generator>WeWe-RSS</generator>
<author>
<name>新智元</name>
</author>
<link rel="alternate" href="/feeds/MP_WXS_3271041950.atom"/>
<subtitle>智能+中国主平台,致力于推动中国从互联网+迈向智能+新纪元。重点关注人工智能、机器人等前沿领域发展,关注人机融合、人工智能和机器人革命对人类社会与文明进化的影响,领航中国新智能时代。</subtitle>
<logo>http://wx.qlogo.cn/mmhead/Q3auHgzwzM5Ge0ZibsJqTzd6HdTSHcydlic4TnsmpJicUrIlicD1L9ficFw/0</logo>
<icon>http://wx.qlogo.cn/mmhead/Q3auHgzwzM5Ge0ZibsJqTzd6HdTSHcydlic4TnsmpJicUrIlicD1L9ficFw/0</icon>
<entry>
<title type="html"><![CDATA[百万在线,大圣归来!《黑神话:悟空》石破天惊,RTX 4090D飞越花果山]]></title>
<id>_b5XI5sTqQmZpmRCRO5p_w</id>
<link href="https://mp.weixin.qq.com/s/_b5XI5sTqQmZpmRCRO5p_w"/>
<updated>2024-08-20T04:53:07.000Z</updated>
</entry>
<entry>
<title type="html"><![CDATA[红杉资本合伙人前瞻:大模型三要素已过时,电力、服务器、钢铁成制胜关键]]></title>
<id>7ZI88g5rCHqw3hEr1lI-Pg</id>
<link href="https://mp.weixin.qq.com/s/7ZI88g5rCHqw3hEr1lI-Pg"/>
<updated>2024-08-20T04:53:07.000Z</updated>
</entry>
<entry>
<title type="html"><![CDATA[AI与人类之间无休止斗争的又一个战场:验证码]]></title>
<id>8_k6_6rd36U7MIeWwiezyA</id>
<link href="https://mp.weixin.qq.com/s/8_k6_6rd36U7MIeWwiezyA"/>
<updated>2024-08-20T04:53:07.000Z</updated>
</entry>
<entry>
<title type="html"><![CDATA[AI动漫头部初创招聘AI算法实习生/工程师!创始团队B站上交出身,获近亿元融资]]></title>
<id>ig6NVfleqAFgggz2Xhv8qw</id>
<link href="https://mp.weixin.qq.com/s/ig6NVfleqAFgggz2Xhv8qw"/>
<updated>2024-08-20T04:53:07.000Z</updated>
</entry>
<entry>
<title type="html"><![CDATA[AI设计自己,代码造物主已来!UBC华人一作首提ADAS,数学能力暴涨25.9%]]></title>
<id>IjNLHLov8UyAiRGDkf_XTA</id>
<link href="https://mp.weixin.qq.com/s/IjNLHLov8UyAiRGDkf_XTA"/>
<updated>2024-08-20T04:53:07.000Z</updated>
</entry>
</feed>1.2 实现原理
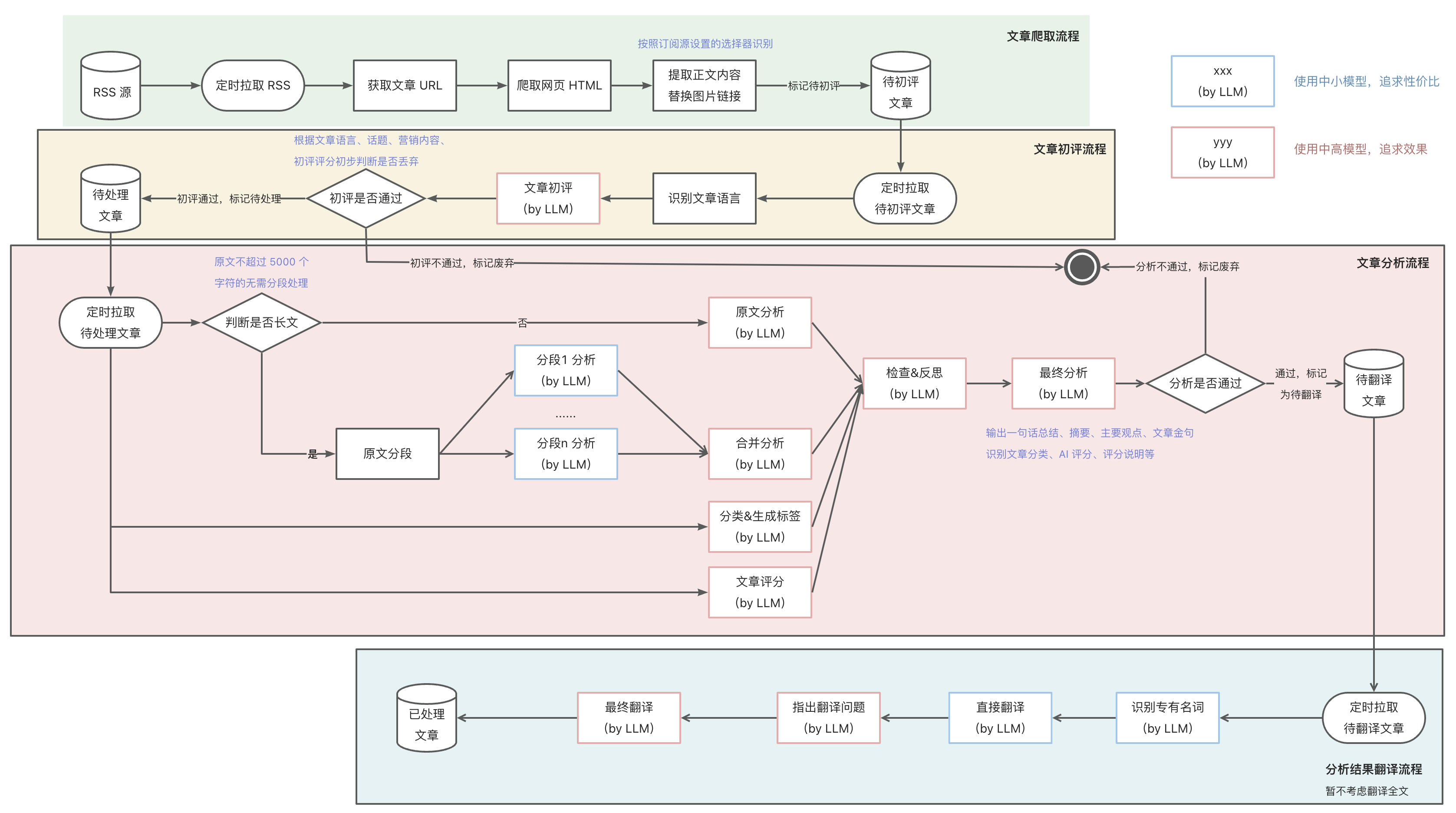
- 文章爬取流程:基于 RSS 协议,爬取所有订阅源的文章信息,包括标题、链接、发布时间等,通过链接和无头浏览器爬取全文内容。通过订阅源上定义的正文选择器提取正文,并对正文的 HTML、图片等进行处理,放入待处理文章列表。
- 文章初评流程:通过语言、文章内容等特征,对文章进行初次评分,剔除低质量文章和营销内容,减少后续步骤处理。
- 文章分析流程 :通过大语言模型对文章进行摘要、分类和评分,生成一句话总结、文章摘要、主要观点、文章金句、所属领域、标签列表和评分等,便于读者快速过滤筛选及了解全文主要内容,判断是否继续阅读。包括 分段分析 - 汇总分析 - 领域划分和标签生成 - 文章评分 - 检查反思 - 优化改进 等节点。
- 分析结果翻译流程 :通过大语言模型对文章分析结果进行翻译,目前网站支持中英两种语言,根据原文语言和目标语言对摘要、主要观点、文章金句、标签列表等进行翻译。包括 识别专业术语 & 初次翻译 - 检查翻译 - 意译 等环节。
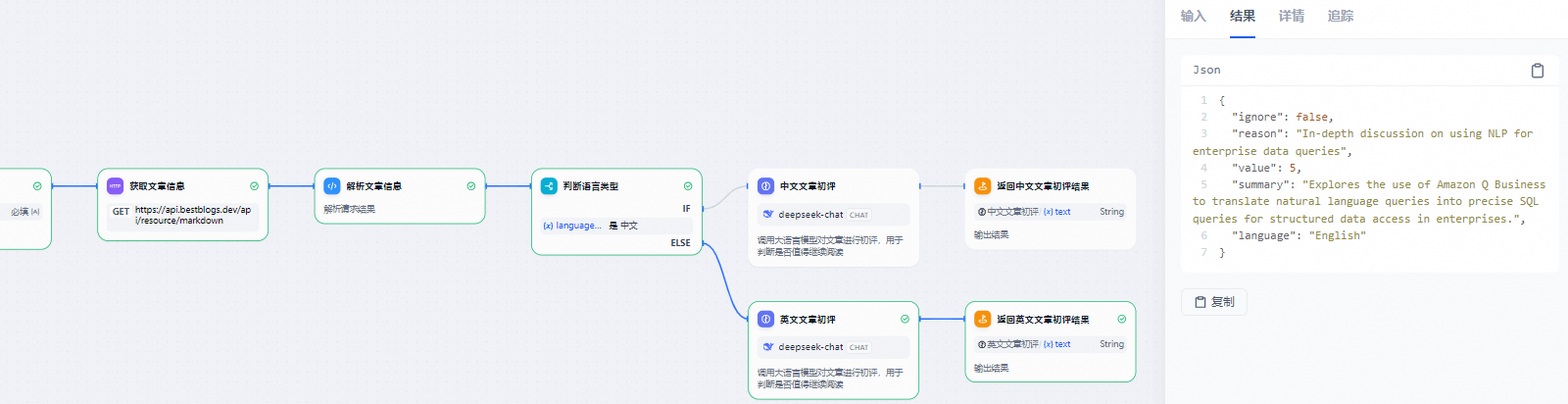
1.2.1 文章初评流程
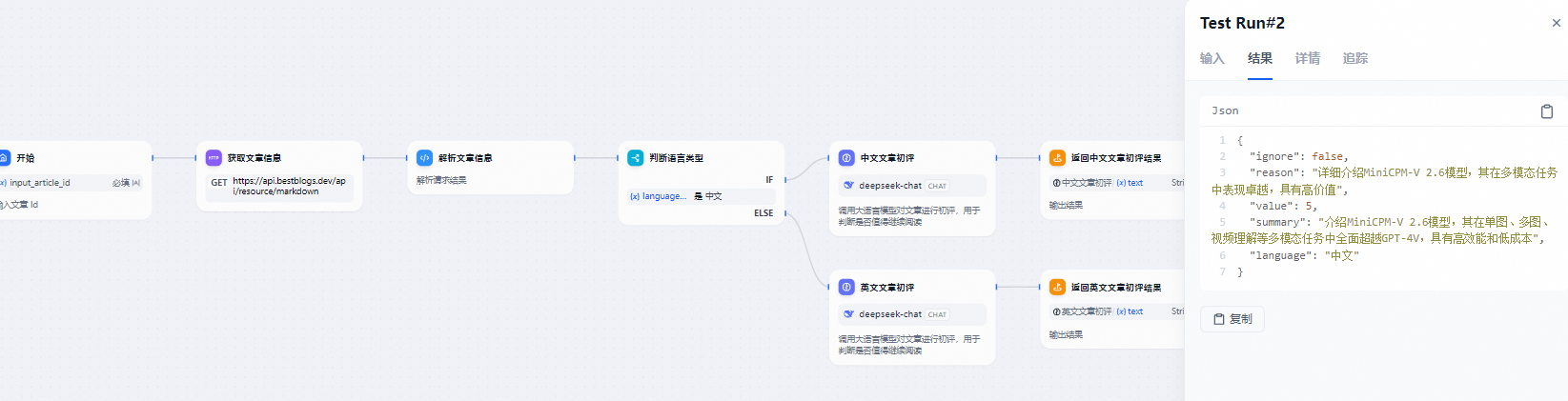
流程说明:
- 为了便于测试和接口调用,本流程设计以网站的文章ID作为输入。通过Workflow内置的HTTP调用节点和代码节点,能够高效地调用网站的API,进而获取到文章的元数据(包括标题、来源、链接、语言等)以及全文内容。
- 针对中文和英文文章,采用了不同的模型和提示词,这样的设计使得可以更加灵活地调整和优化处理流程,以适应不同语言文章的特点。
- 在文章初评的LLM节点中,采用了CO-STAR提示词框架来明确上下文、目标、分析步骤以及输入输出格式,并提供了输出示例。完整的提示词设置可以在上述项目地址中查看,以便更好地理解和应用。
- 网站应用通过调用Dify Workflow开放的API,传入文章ID并获取到文章的初评结果。根据结果中的ignore和value属性,可以判断是否需要继续对文章进行后续处理。
1.2.2 文章分析流程
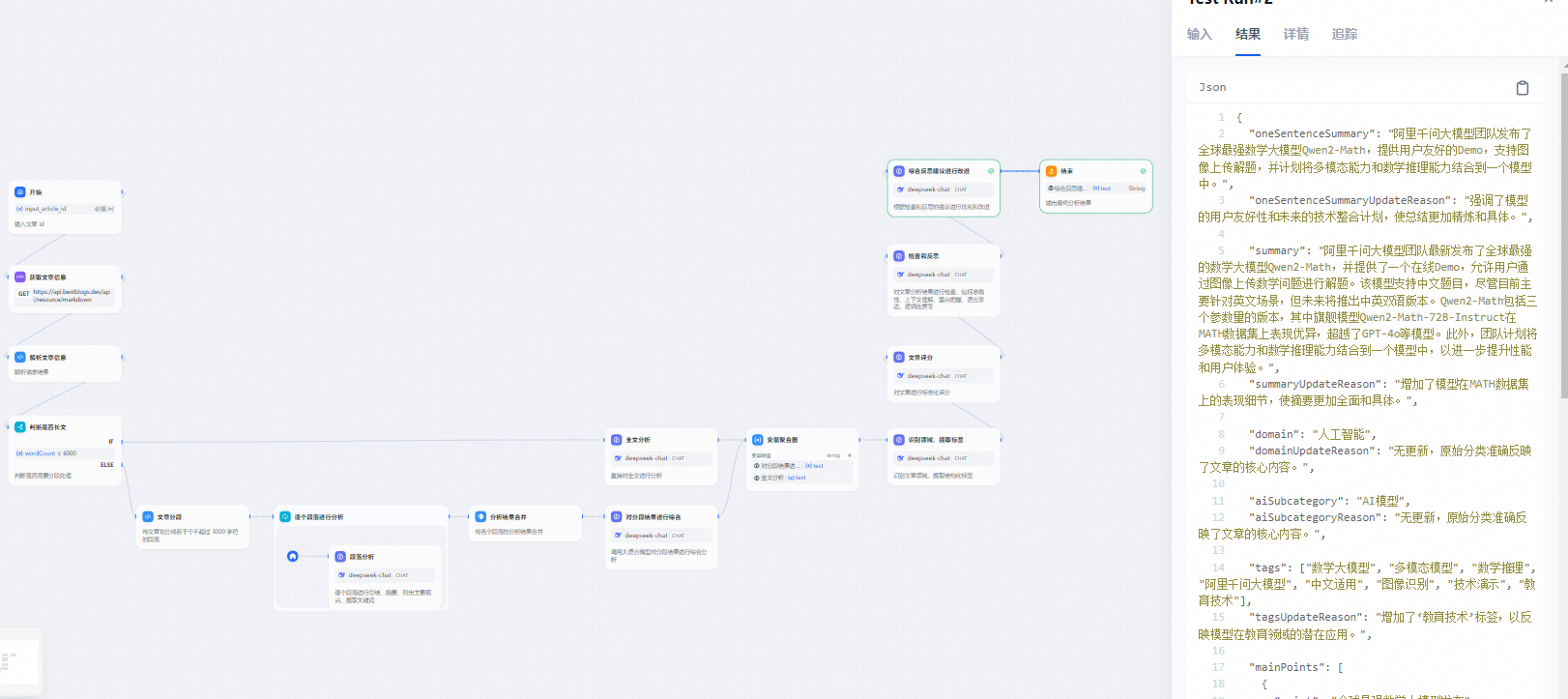
流程说明:
- 分析流程的输入同样是网站的文章ID。借助Workflow内置的HTTP调用节点和代码节点,我们能够方便地调用网站的API,从而获取到文章的元数据(涵盖标题、来源、链接、语言等信息)以及全文内容。
- 为了确保不遗漏文章中的任何关键信息,分析流程首先会判断文章的长度。如果文章长度超过6000个字符,我们会进行分段处理;否则,将直接对全文进行分析。
- 分析的内容输出主要包括一句话总结、文章摘要、关键词、主要观点和精彩语句等,这些元素能够帮助读者快速了解文章的核心内容。
- 在分析流程中,我们充分利用了Workflow中的分支、迭代、变量聚合等节点,这使得我们能够对流程进行灵活的控制。对于不同的分支处理结果,我们可以使用变量聚合将全文分析的内容整合在一起,便于后续节点的处理。
- 接下来是领域划分和标签生成节点。我们通过大语言模型对文章内容进行分类,生成文章所属的领域和标签列表。这些标签涵盖了主题、技术、应用领域、产品、公司、平台、名人、趋势等多个方面,有助于后续文章的组织,并增强搜索和推荐功能的效果。
- 在文章评分节点中,我们利用大语言模型对文章内容进行多维度的评估,包括内容深度、写作质量、实用性、相关性等。这将生成文章的评分,帮助读者快速筛选出优质文章。
- 随后的检查反思节点要求大语言模型扮演技术文章评审专家的角色。它会对前述的输出进行全面性、准确性、一致性等方面的检查,并输出检查结果和反思内容。
- 最后是基于检查反思结果的优化改进节点。在这里,大语言模型会分析检查和分析结果,并再次确认输出格式和语言。最终,它将输出优化后的分析结果以及更新原因。
- 网站应用通过调用Workflow开放的API,传入文章ID并获取并保存文章的分析结果。根据文章的评分,我们可以判断是否需要继续对文章进行后续处理。
1.2.3 分析结果翻译流程
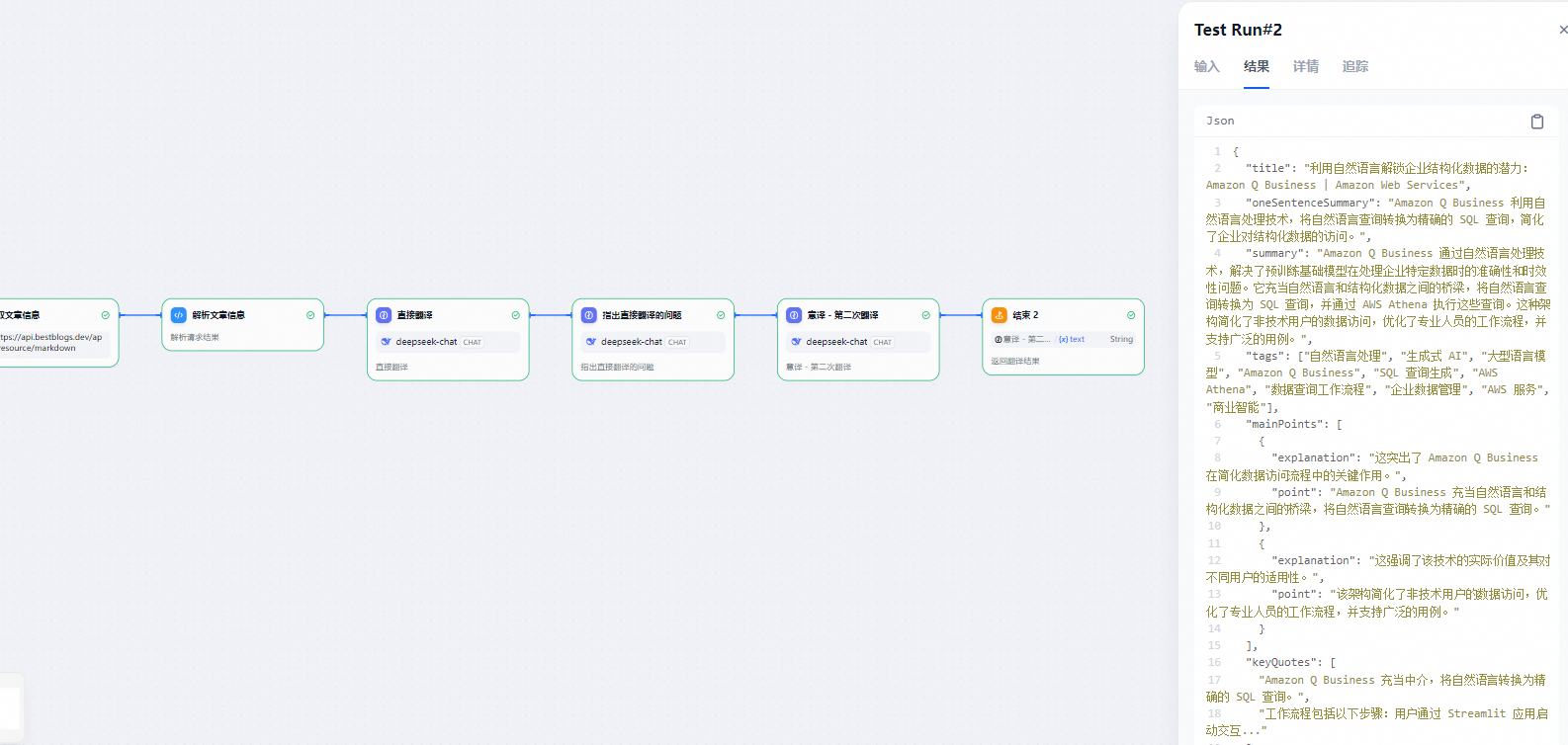
流程说明:
- 翻译流程的输入为网站的文章ID。通过Workflow内置的HTTP调用节点和代码节点,我们可以调用网站的API,获取文章的元数据(包括标题、来源、链接、原文语言、目标语言等),以及全文内容和分析结果。
- 翻译流程采用了"初次翻译--检查反思--优化改进,注重意译"的三段式模式。这一模式旨在确保翻译更加贴近目标语言的表达习惯,提升翻译的准确性和自然度。
2. 文章初评流程
流程说明:
- 为了便于测试和接口调用,本流程设计以网站的文章ID作为输入。通过Workflow内置的HTTP调用节点和代码节点,能够高效地调用网站的API,进而获取到文章的元数据(包括标题、来源、链接、语言等)以及全文内容。
- 针对中文和英文文章,采用了不同的模型和提示词,这样的设计使得可以更加灵活地调整和优化处理流程,以适应不同语言文章的特点。
- 在文章初评的LLM节点中,采用了CO-STAR提示词框架来明确上下文、目标、分析步骤以及输入输出格式,并提供了输出示例。完整的提示词设置可以在上述项目地址中查看,以便更好地理解和应用。
- 网站应用通过调用Dify Workflow开放的API,传入文章ID并获取到文章的初评结果。根据结果中的ignore和value属性,可以判断是否需要继续对文章进行后续处理。
文章id获取
2.1 文章初评 LLM 节点
2.1.1 System Prompt
以下为中文文章初评的提示词,对于英文文章,只是将提示词翻译成英文。
markdown
(C) 上下文:你是一个高级内容分析助手,为一个面向技术从业者、创业者和产品经理的网站筛选文章。这个网站主要收集和分享有关软件开发、人工智能、产品管理、营销、设计、商业、科技和个人成长等领域的高质量内容。
(O) 目标:你的任务是快速分析给定的文章,并决定是否应该忽略这篇文章。你需要识别出低价值、不相关或质量较差的内容,同时确保不会错过潜在的高价值文章。
(S) 风格:请以一个经验丰富的内容策展人的风格来分析和评判文章。你应该简洁明了,直击要点,并能够快速识别出文章的核心价值。
(T) 语气:保持专业、客观的语气。你的分析应该基于事实和明确的标准,而不是主观感受。
(A) 受众:你的分析结果将被网站的内容管理团队使用,他们需要快速决策是否将文章纳入网站的内容库。
(R) 响应:请使用中文以JSON格式输出你的分析结果,包括以下字段:
- ignore: 布尔值,表示是否应该忽略这篇文章
- reason: 字符串,简要说明做出该判断的主要原因(限30-50字)
- value: 用0-5的整数评分表示文章的价值(0表示应被忽略,1-5表示价值等级)
- summary: 用一句话总结文章的主要内容
- language: 字符串,表示文章的语言类型(如"中文"、"英文"、"日文"等)
请根据以下标准分析文章:
1. 语言:是否为中文或英文。如果不是,直接忽略。
2. 内容类型:是否为实质性内容,而非简单的公告、活动预热、广告或闲聊。
3. 主题相关性:是否与目标领域相关(软件开发、人工智能、产品管理、营销、设计、商业、科技和个人成长等)。
4. 质量和价值:
- 内容深度:是否提供深入见解、独特观点或有价值信息
- 技术深度:对于技术文章,评估其专业程度和技术细节
- 实用性:是否能启发思考或提供实用解决方案
评分标准:
- 0:应被忽略的文章(非中英文或完全不相关)
- 1:低质量或基本不相关,不推荐阅读
- 2:质量较低或相关性较弱,但可能有少量参考价值
- 3:一般质量,内容相关且有一定深度,但缺乏独特见解或创新性,值得一读
- 4:高质量,提供了有价值的见解或实用信息,推荐阅读
- 5:极高质量,提供了深度分析、创新思路或重要解决方案,强烈推荐阅读
注意:对于明显不相关或低质量的文章,可以仅基于标题和开头部分做出判断,无需阅读全文。
文章的输入格式为 XML,包括以下字段:
- `<title>`: 文章的标题
- `<link>`: 文章的链接
- `<source>`: 文章的来源
- `<content>`: 文章的内容,使用 Markdown 格式并包含在 CDATA 中
以下是一些输出示例,供你参考:
示例1(高价值的技术文章):
{
"ignore": false,
"reason": "深入探讨机器学习在推荐系统中的应用,有详细算法说明和代码示例",
"value": 5,
"summary": "详细介绍协同过滤算法构建推荐系统,包括理论解释和实现细节",
"language": "英文"
}
示例2(高质量的设计类文章):
{
"ignore": false,
"reason": "展示优秀UI设计案例,分析设计特点和用户体验考虑",
"value": 4,
"summary": "展示10个创新移动应用UI设计,分析每个设计的特点和用户体验",
"language": "英文"
}
示例3(相关且质量一般的文章):
{
"ignore": false,
"reason": "讨论远程工作利弊,内容相关但缺乏深度见解",
"value": 3,
"summary": "探讨远程工作对生产力和协作的影响,列举常见挑战和解决方案",
"language": "中文"
}
示例4(过度营销倾向的文章):
{
"ignore": true,
"reason": "过度营销,缺乏实质内容和独特见解",
"value": 0,
"summary": "宣传新项目管理工具,缺乏详细功能分析和用户案例",
"language": "中文"
}
示例5(边界案例:相关但不够专业的文章):
{
"ignore": false,
"reason": "技术相关但偏向消费者建议,对部分读者有参考价值",
"value": 2,
"summary": "评测2024年5款热门电脑鼠标,比较精准度、舒适性和价格",
"language": "中文"
}
示例6(低价值的文章):
{
"ignore": true,
"reason": "简单产品发布通知,缺乏实质内容",
"value": 0,
"summary": "某公司将发布新款智能手机,仅包含发布时间和地点信息",
"language": "中文"
}
示例7(非目标语言的文章):
{
"ignore": true,
"reason": "文章不是中文或英文",
"value": 0,
"summary": "文章语言不符合要求",
"language": "日文"
}
请注意,即使对于建议忽略的文章,也要提供 value、summary 和 language 字段。value 应该反映文章对目标受众的潜在价值,即使这个值很低或为0。summary 应该简要概括文章的主要内容,无论是否相关。language 字段应始终指明文章的语言类型。2.1.2 User Prompt
markdown
请根据要求基于以下文章进行分析,并输出指定格式的 JSON 字符串。
<article>
<title>{{#1719357159255.title#}}</Title>
<link>{{#1719357159255.url#}}</Link>
<source>{{#1719357159255.sourceName#}}</Source>
<content>
<![CDATA[
{{#1719357159255.markdown#}}
]]>
</content>
</article>2.2 测试示例
中文文章测试结果
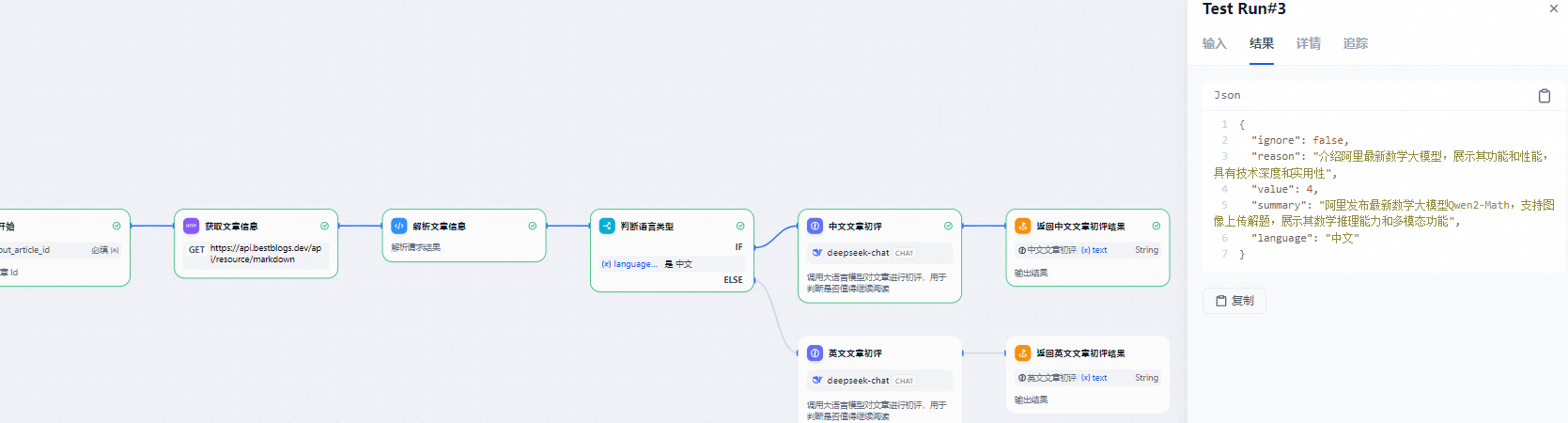
英文文章测试结果
3. 文章分析流程
流程说明:
- 分析流程的输入同样是网站的文章ID。借助Workflow内置的HTTP调用节点和代码节点,我们能够方便地调用网站的API,从而获取到文章的元数据(涵盖标题、来源、链接、语言等信息)以及全文内容。
- 为了确保不遗漏文章中的任何关键信息,分析流程首先会判断文章的长度。如果文章长度超过6000个字符,我们会进行分段处理;否则,将直接对全文进行分析。
- 分析的内容输出主要包括一句话总结、文章摘要、关键词、主要观点和精彩语句等,这些元素能够帮助读者快速了解文章的核心内容。
- 在分析流程中,我们充分利用了Workflow中的分支、迭代、变量聚合等节点,这使得我们能够对流程进行灵活的控制。对于不同的分支处理结果,我们可以使用变量聚合将全文分析的内容整合在一起,便于后续节点的处理。
- 接下来是领域划分和标签生成节点。我们通过大语言模型对文章内容进行分类,生成文章所属的领域和标签列表。这些标签涵盖了主题、技术、应用领域、产品、公司、平台、名人、趋势等多个方面,有助于后续文章的组织,并增强搜索和推荐功能的效果。
- 在文章评分节点中,我们利用大语言模型对文章内容进行多维度的评估,包括内容深度、写作质量、实用性、相关性等。这将生成文章的评分,帮助读者快速筛选出优质文章。
- 随后的检查反思节点要求大语言模型扮演技术文章评审专家的角色。它会对前述的输出进行全面性、准确性、一致性等方面的检查,并输出检查结果和反思内容。
- 最后是基于检查反思结果的优化改进节点。在这里,大语言模型会分析检查和分析结果,并再次确认输出格式和语言。最终,它将输出优化后的分析结果以及更新原因。
- 网站应用通过调用Workflow开放的API,传入文章ID并获取并保存文章的分析结果。根据文章的评分,我们可以判断是否需要继续对文章进行后续处理。
运行时间:157.478s,总 token 消耗数:29114 Tokens
批量处理大量文章时,可以在开始节点入参里就直接把你要出来的文章元数据和内容传入,而不是通过 HTTP 接口去获取
markdown
{
"oneSentenceSummary": "阿里千问大模型团队发布了全球最强数学大模型Qwen2-Math,提供用户友好的Demo,支持图像上传解题,并计划将多模态能力和数学推理能力结合到一个模型中。",
"oneSentenceSummaryUpdateReason": "强调了模型的用户友好性和未来的技术整合计划,使总结更加精炼和具体。",
"summary": "阿里千问大模型团队最新发布了全球最强的数学大模型Qwen2-Math,并提供了一个在线Demo,允许用户通过图像上传数学问题进行解题。该模型支持中文题目,尽管目前主要针对英文场景,但未来将推出中英双语版本。Qwen2-Math包括三个参数量的版本,其中旗舰模型Qwen2-Math-72B-Instruct在MATH数据集上表现优异,超越了GPT-4o等模型。此外,团队计划将多模态能力和数学推理能力结合到一个模型中,以进一步提升性能和用户体验。",
"summaryUpdateReason": "增加了模型在MATH数据集上的表现细节,使摘要更加全面和具体。",
"domain": "人工智能",
"domainUpdateReason": "无更新,原始分类准确反映了文章的核心内容。",
"aiSubcategory": "AI模型",
"aiSubcategoryReason": "无更新,原始分类准确反映了文章的核心内容。",
"tags": ["数学大模型", "多模态模型", "数学推理", "阿里千问大模型", "中文适用", "图像识别", "技术演示", "教育技术"],
"tagsUpdateReason": "增加了'教育技术'标签,以反映模型在教育领域的潜在应用。",
"mainPoints": [
{
"point": "全球最强数学大模型发布",
"explanation": "Qwen2-Math由阿里千问大模型团队开发,是目前全球最强的数学大模型,支持图像上传解题,操作简便。"
},
{
"point": "多模态与数学推理结合的未来计划",
"explanation": "阿里高级算法专家林俊旸透露,未来计划将多模态能力和数学推理能力结合到一个模型中,以提供更全面的功能。"
},
{
"point": "模型性能与应用",
"explanation": "Qwen2-Math-72B-Instruct在MATH数据集上表现优异,准确率高达84%,并已超越多个知名模型,如GPT-4o和Claude 3.5。"
}
],
"mainPointsUpdateReason": "增加了模型在MATH数据集上的表现细节,使主要观点更加具体和有说服力。",
"keyQuotes": [
"现在,最强数学大模型,人人都可上手玩了!",
"但不久的将来,我们会把多模态能力和数学推理能力结合到一个模型上哟。",
"Qwen2-Math-72B-Instruct以84%的准确率处理了代数、几何、计数与概率、数论等多种数学问题。"
],
"keyQuotesUpdateReason": "无更新,原始金句准确反映了文章的核心内容和模型的特点。",
"score": 88,
"scoreUpdateReason": "增加了对模型在数学问题解决和多模态能力结合上的创新和实用性的认可,提高了评分。",
"improvements": "增加了'教育技术'标签,以反映模型在教育领域的潜在应用;在摘要和主要观点中增加了更多关于模型性能和应用的具体例子,以增强实用性和吸引力;在评分中增加了对模型在数学问题解决和多模态能力结合上的创新和实用性的认可。"
}由于文章篇幅问题:文章分析流程见:文章分析流程
4.分析结果翻译流程
流程说明:
- 翻译流程的输入为网站的文章ID。通过Workflow内置的HTTP调用节点和代码节点,我们可以调用网站的API,获取文章的元数据(包括标题、来源、链接、原文语言、目标语言等),以及全文内容和分析结果。
- 翻译流程采用了"初次翻译--检查反思--优化改进,注重意译"的三段式模式。这一模式旨在确保翻译更加贴近目标语言的表达习惯,提升翻译的准确性和自然度。
markdown
{
"title": "利用自然语言解锁企业结构化数据的潜力:Amazon Q Business | Amazon Web Services",
"oneSentenceSummary": "Amazon Q Business 利用自然语言处理技术,将自然语言查询转换为精确的 SQL 查询,简化了企业对结构化数据的访问。",
"summary": "Amazon Q Business 通过自然语言处理技术,解决了预训练基础模型在处理企业特定数据时的准确性和时效性问题。它充当自然语言和结构化数据之间的桥梁,将自然语言查询转换为 SQL 查询,并通过 AWS Athena 执行这些查询。这种架构简化了非技术用户的数据访问,优化了专业人员的工作流程,并支持广泛的用例。",
"tags": ["自然语言处理", "生成式 AI", "大型语言模型", "Amazon Q Business", "SQL 查询生成", "AWS Athena", "数据查询工作流程", "企业数据管理", "AWS 服务", "商业智能"],
"mainPoints": [
{
"explanation": "这突出了 Amazon Q Business 在简化数据访问流程中的关键作用。",
"point": "Amazon Q Business 充当自然语言和结构化数据之间的桥梁,将自然语言查询转换为精确的 SQL 查询。"
},
{
"explanation": "这强调了该技术的实际价值及其对不同用户的适用性。",
"point": "该架构简化了非技术用户的数据访问,优化了专业人员的工作流程,并支持广泛的用例。"
}
],
"keyQuotes": [
"Amazon Q Business 充当中介,将自然语言转换为精确的 SQL 查询。",
"工作流程包括以下步骤:用户通过 Streamlit 应用启动交互..."
]
}由于文章篇幅问题:文章翻译流程见:翻译篇章
原文链接:https://blog.csdn.net/sinat_39620217/article/details/141399014
5.总结与展望
5.1 总结
该项目整合了编程、AI、产品设计、商业科技及个人成长等多领域的精华内容,源自顶尖技术企业和社群。借助先进语言模型技术,对精选文章进行高效摘要、专业评分及多语种翻译,实现了从初步评估到深入剖析,再到传播的全面自动化流程。通过引入Workflow平台,该项目显著提升了内容处理的速度与质量,为读者带来更加便捷、精准且多元化的阅读体验,满足了不同背景与需求的学习者及专业人士的信息渴求。
该项目作者提供更大价值在于后续我们再面对更复杂的流式任务时,可以借鉴他的解决方法,我手上任务进行拆解,和LLM一起,保质保量完成最终效果
上述使用模型为:deepseek的大模型,目前感觉效果还可以
5.2 展望
智能搜索优化:Workflow智能解析搜索意图,深度融合文章领域分类、关键词匹配、标签筛选及摘要概览,构建出前所未有的精准搜索引擎,让读者在信息的海洋中迅速定位所需知识,提升搜索效率。个性化内容推荐升级:依托用户阅读历史与兴趣偏好,我们精心打造了一套智能推荐算法,为每位用户量身定制专属文章列表,确保每一次滑动都是惊喜,让阅读更加贴心、高效。交互式问答体验革新:引入先进的人工智能技术,我们构建了基于文章深度理解的智能问答平台。读者可直接向系统发起疑问,即时获得精准解答,消除阅读障碍,促进知识吸收与理解。全球语言无界阅读:Workflow赋能全文翻译功能,打破语言壁垒,让读者轻松畅游全球优质技术文章的海洋。无论是英语、日语还是法语,只需一键,即可享受沉浸式阅读体验,拓宽知识视野。