Flink简介
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
Flink技术栈如图1所示。
图1Flink技术栈
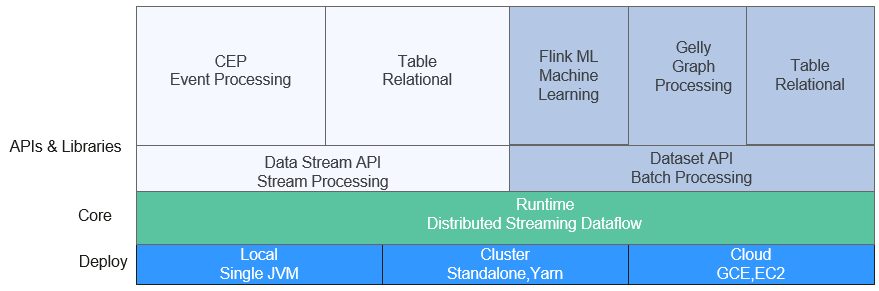
Flink在当前版本中重点构建如下特性:
- DataStream
- Checkpoint
- 窗口
- Job Pipeline
- 配置表
其他特性继承开源社区,不做增强,具体请参考:Apache Flink 1.12 Documentation: Apache Flink Documentation。
Flink结构
Flink结构如图2所示。
图2Flink结构
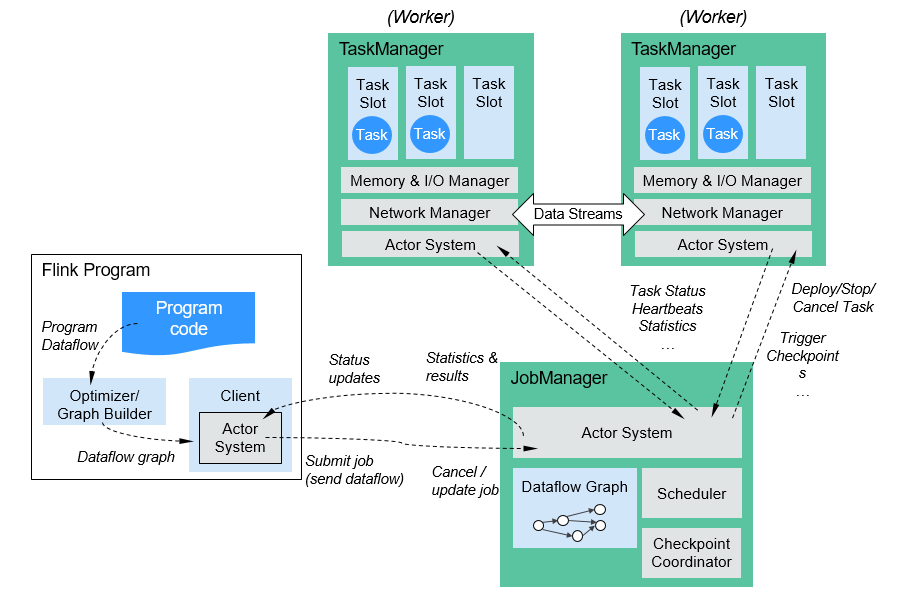
Flink整个系统包含三个部分:
-
Client Flink Client主要给用户提供向Flink系统提交用户任务(流式作业)的能力。
-
TaskManager Flink系统的业务执行节点,执行具体的用户任务。TaskManager可以有多个,各个TaskManager都平等。
-
JobManager Flink系统的管理节点,管理所有的TaskManager,并决策用户任务在哪些TaskManager执行。JobManager在HA模式下可以有多个,但只有一个主JobManager。
如果您想了解更多关于Flink架构的信息,请参考链接:https://ci.apache.org/projects/flink/flink-docs-master/docs/concepts/flink-architecture/。
Flink原理
-
Stream & Transformation & Operator
用户实现的Flink程序是由Stream和Transformation这两个基本构建块组成。
-
Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
-
当一个Flink程序被执行的时候,它会被映射为Streaming Dataflow。一个Streaming Dataflow是由一组Stream和Transformation Operator组成,它类似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。 图3为一个由Flink程序映射为Streaming Dataflow的示意图。
图3Flink DataStream示例
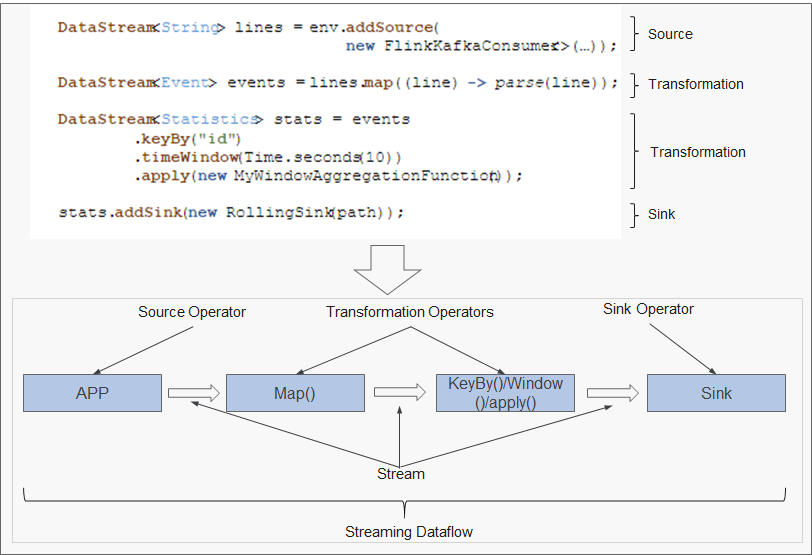
图3中"FlinkKafkaConsumer"是一个Source Operator,Map、KeyBy、TimeWindow、Apply是Transformation Operator,RollingSink是一个Sink Operator。
-
-
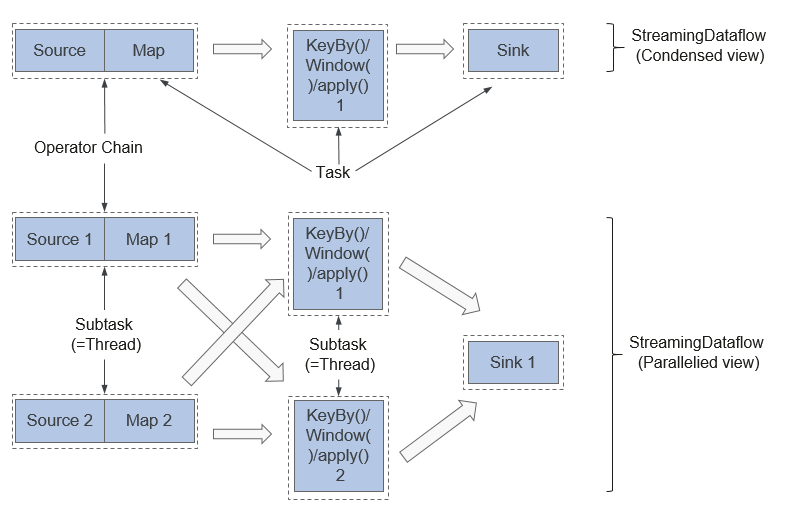
Pipeline Dataflow
在Flink中,程序是并行和分布式的方式运行。一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask。
Flink内部有一个优化的功能,根据上下游算子的紧密程度来进行优化。

Flink关键特性
- 流式处理 高吞吐、高性能、低时延的实时流处理引擎,能够提供毫秒级时延处理能力。
-
丰富的状态管理流处理应用需要在一定时间内存储所接收到的事件或中间结果,以供后续某个时间点访问并进行后续处理。Flink提供了丰富的状态管理相关的特性,包括:
- 多种基础状态类型:Flink提供了多种不同数据结构的状态支持,如ValueState、ListState、MapState等。用户可以基于业务模型选择最高效、合适状态类型。
- 丰富的State Backend:State Backend负责管理应用程序的状态,并根据需要进行Checkpoint。Flink提供了不同State Backend,State可以存储在内存上或RocksDB等上,并支持异步以及增量的Checkpoint机制。
- 精确一次语义:Flink的Checkpoint和故障恢复能力保证了任务在故障发生前后的应用状态一致性,为某些特定的存储支持了事务型输出的功能,即使在发生故障的情况下,也能够保证精确一次的输出。
-
丰富的时间语义 时间是流处理应用的重要组成部分,对于实时流处理应用来说,基于时间语义的窗口聚合、检测、匹配等运算是很常见的。Flink提供了丰富的时间语义。
- Event-time:使用事件本身自带的时间戳进行计算,使乱序到达或延迟到达的事件处理变得更加简单。
- Watermark:Flink引入Watermark概念,用以衡量事件时间的发展。Watermark也为平衡处理时延和数据完整性提供了灵活的保障。当处理带有Watermark的事件流时,在计算完成之后仍然有相关数据到达时,Flink提供了多种处理选项,如将数据重定向(side output)或更新之前完成的计算结果。
- Processing-time和Ingestion-time。
- 高度灵活的流式窗口:Flink能够支持时间窗口、计数窗口、会话窗口,以及数据驱动的自定义窗口,可以通过灵活的触发条件定制,实现复杂的流式计算模式。
-
容错机制 分布式系统,单个Task或节点的崩溃或故障,往往会导致整个任务的失败。Flink提供了任务级别的容错机制,保证任务在异常发生时不会丢失用户数据,并且能够自动恢复。
- Checkpoint:Flink基于Checkpoint实现容错,用户可以自定义对整个任务的Checkpoint策略,当任务出现失败时,可以将任务恢复到最近一次Checkpoint的状态,从数据源重发快照之后的数据。
- Savepoint:一个Savepoint就是应用状态的一致性快照,Savepoint与Checkpoint机制相似,但Savepoint需要手动触发,Savepoint保证了任务在升级或迁移时,不丢失当前流应用的状态信息,便于任何时间点的任务暂停和恢复。
-
Flink SQL Table API和SQL借助了Apache Calcite来进行查询的解析,校验以及优化,可以与DataStream和DataSet API无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。简化数据分析、ETL等应用的定义。下面代码示例展示了如何使用Flink SQL语句定义一个会话点击量的计数应用。
SELECT userId, COUNT(*) FROM clicks GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId有关Flink SQL的更多信息,请参见://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/sqlclient/。
-
CEP in SQL Flink允许用户在SQL中表示CEP(Complex Event Processing)查询结果以用于模式匹配,并在Flink上对事件流进行评估。
CEP SQL通过MATCH_RECOGNIZE的SQL语法实现。MATCH_RECOGNIZE子句自Oracle Database 12c起由Oracle SQL支持,用于在SQL中表示事件模式匹配。CEP SQL使用举例如下:
SELECT T.aid, T.bid, T.cid FROM MyTable MATCH_RECOGNIZE ( PARTITION BY userid ORDER BY proctime MEASURES A.id AS aid, B.id AS bid, C.id AS cid PATTERN (A B C) DEFINE A AS name = 'a', B AS name = 'b', C AS name = 'c' ) AS T