注意: 本文内容于 2024-08-18 23:50:33 创建,可能不会在此平台上进行更新。如果您希望查看最新版本或更多相关内容,请访问原文地址:PostgreSQL大数据量快速模糊检索实践。感谢您的关注与支持!
一、模糊检索思路
1.1 简单粗暴like
like模糊查询分为三类情况,前后模糊'%keywords%'、后模糊'keywords%'、前模糊'%keywords',它们对索引的要求和性能影响如下:
-
'keywords%':- 索引类型 :可以使用 B-tree 索引。
create index btree_test on table using btree (field) - 性能 :B-tree 索引适用于这种情况,因为它可以有效地查找以
keywords开头的任何字符串。查询性能较高。
- 索引类型 :可以使用 B-tree 索引。
-
'%keywords%':- 索引类型 :可以使用
pg_trgm或GIN/GiST索引。 - 性能 :这种查询模式要求在字符串中任何位置找到匹配,因此需要扫描更多数据。尽管
pg_trgm索引可以帮助提高性能,但由于需要检查整个字符串,性能仍然比'keywords%'查询要低。
- 索引类型 :可以使用
-
'%keywords':- 索引类型 :与
'%keywords%'类似,可以使用pg_trgm或GIN/GiST索引。 - 性能 :由于是查找以特定字符串结尾的数据,虽然匹配范围缩小了一些,但仍然需要扫描字符串的尾部,同样比
'keywords%'查询要慢。
- 索引类型 :与
如果查询中大部分是以某个前缀开头的情况(例如 'keywords%'),建议优先使用 B-tree 索引。如果需要处理任意位置的模糊匹配,则需要为特定字段创建 pg_trgm 或 GIN 索引。
1.2 PG_TRGM扩展

trgm全称为Trigram,即三元组。三元组是从字符串中取出的三个连续字符的组合。我们可以通过计算两个字符串共有的三元组的数量来衡量它们的相似性。
sql
-- 查询已开启扩展
select * from pg_extension
-- 开启pg_trgm扩展。扩展安装自行百度
create extension if not exists pg_trgm
-- 查询三元组。pg_trgm在提取三元组时,忽略非字母数字相关的字符,因此对中文的支持性不好。
-- 在确定字符串中包含的三元组集合时,每个单词都被视为有两个空格前缀和一个空格后缀。如`chatgpt`就会被转为` chatgpt`。
select show_trgm('chatgpt')postgresql内置了gin索引。gin 是一种特别适合处理包含多个值的数据类型的索引类型,例如数组、hstore 和 JSONB 等。它通过构建倒排索引来加速这些数据类型的查询。
使用pg_trgm进行模糊查询
sql
-- 两种索引任选其一,gist_trgm_ops和gin_trgm_ops是在gis索引和gin索引中开启trigram三元组功能,故需要先安装pg_trgm
-- gist索引构建效率较高、查询和占用空间上不如gin索引。适合频繁读写操作或需要快速创建索引的场景。
create index trgm_idx on poi using gist (poi_mc gist_trgm_ops);
-- gin索引查询效率较高、构建效率较低,适用于只读或者写操作较少、查询操作较多的场景,比如全文检索、模糊查询等。
create index trgm_idx on poi using gin (poi_mc gin_trgm_ops);
select poi_mc, similarity(poi_mc, '瑞幸咖啡') from poi where poi_mc % '瑞幸咖啡' order by 2 desc; -- 耗时216ms,4645条
select poi_mc, similarity(poi_mc, '瑞幸咖啡') from poi where poi_mc like '%瑞幸咖啡%' order by 2 desc; --耗时5020ms,5105条
select poi_mc, similarity(poi_mc, '咖') from poi where poi_mc % '咖' order by 2 desc; -- 耗时9ms,0条
select poi_mc, similarity(poi_mc, '咖') from poi where poi_mc like '%咖%' order by 2 desc; --耗时6415ms,39630条通过上述sql执行耗时,可知通过pg_trgm进行模糊检索对效率有提升,但是对于中文会存在不小的误差。
1.3 全文检索类型tsvector与tsquery
PostgreSQL 提供了两种数据类型,用于支持全文检索
tsvector:用于存储已处理的文本数据,便于快速搜索。对应的有to_tsvector可以将文本处理为tsvector类型tsquery:用于表示用户的搜索条件,支持复杂的逻辑运算。对应的有to_tsquery可以将查询条件转为tsquery类型
下面记录整体的一个使用流程。
1.) 创建 tsvector 列
首先,你可以在表中创建一个 tsvector 类型的列,以存储处理后的文本数据:
sql
create table documents (
title text,
content text,
search_vector tsvector
);2.) 使用 to_tsvector 函数填充 tsvector 列
插入数据时,可以使用 to_tsvector 函数来填充 search_vector 列:
sql
insert into documents (title, content, search_vector)
values
('PostgreSQL Tutorial', 'Learn PostgreSQL with this comprehensive tutorial.', to_tsvector('Learn PostgreSQL with this comprehensive tutorial.')),
('HaloWode', 'Learn to spell HELLO WORLD.', to_tsvector('Learn to spell HELLO WORLD.')),
('Another Postgres Guide', 'This guide covers advanced PostgreSQL features.', to_tsvector('This guide covers advanced PostgreSQL features.'));3.) 更新 tsvector 列
在插入或更新 content 列时,可以自动更新 search_vector 列:
sql
update documents
set search_vector = to_tsvector(content)
where title = 'HaloWode';4.) 执行全文搜索
使用 @@ 操作符来查询包含特定词的记录:
sql
-- PostgreSQL 与 tutorial 是and关系
select * from documents where search_vector @@ to_tsquery('PostgreSQL & tutorial');
-- PostgreSQL 与 turorial 是or关系
select * from documents where search_vector @@ to_tsquery('PostgreSQL | tutorial');
-- PostgreSQL 与 !tutorial 是or关系
select * from documents where search_vector @@ to_tsquery('PostgreSQL | !tutorial');5.) 使用 GIN 索引优化查询
为了提高搜索性能,可以为 search_vector 列创建 GIN 索引:
sql
create index idx_fts on documents using gin(search_vector);6.) 使用 plainto_tsquery 进行简单查询
plainto_tsquery的作用就是用户输入不必去纠结&符,只需要按照口语化的内容输入,他自动转为带&的tsquery:
sql
select plainto_tsquery('PostgreSQL tutorial'); -- 返回结果 'postgresql' & 'tutorial'
-- 以下两条sql虽然写法不同,但是达到的效果是一致的,只是后者对用户输入更友好,不用去额外添加操作符
select * from documents where search_vector @@ to_tsquery('PostgreSQL & tutorial');
select * from documents where search_vector @@ plainto_tsquery('PostgreSQL tutorial');二、中文快速模糊检索实践
不需要安装pg_trgm,即可实现同样的效果。实现步骤如下
- 分词
- 建索引
- 查询
该内容参考的主要思路,放到了参考致谢内。
1.) 构建分词逻辑,创建一个支持n元组分词的函数,第二个入参不传时,默认为二元组。
可以将函数进一步优化成返回n元组的tsvector。不过该操作属于锦上添花之举,不要也罢。
sql
create or replace function n_grams(text, int default 2) returns text[] as $$
declare
res text[] := '{}'; -- 初始化结果数组
str_length int := length($1); -- 存储字符串长度
n int := coalesce($2, 2); -- 获取 n 值,默认为 2
begin
-- 检查 n 的合法性
if n < 1 or n > str_length then
raise exception 'n must be between 1 and the length of the input string';
end if;
-- 遍历输入字符串,生成 n 元组
for i in 1..str_length - n + 1 loop
res := array_append(res, substring($1 from i for n)); -- 提取 n 元组
end loop;
return res;
end;
$$ language plpgsql strict parallel safe immutable;
select n_grams('北京市西城区西单地铁站E西南口步行370米') -- {北京,京市,市西,西城,城区,区西,西单,单地,地铁,铁站,站E,E西,西南,南口,口步,步行,行3,37,70,0米}2.) 构建索引
sql
-- 不需要开启gin的gin_trgm_ops
create index poi_mc_index on poi using gin(n_grams(poi_mc));3.) 查询,数据基数为1000w
sql
-- 耗时5ms,返回125条
select * from poi where n_grams(poi_mc) @> n_grams('coffee瑞幸');
-- 查看走索引的情况
explain select * from poi where n_grams(poi_mc) @> n_grams('coffee瑞幸');
-- 耗时4754ms,返回125条
select * from poi where poi_mc like '%coffee瑞幸%';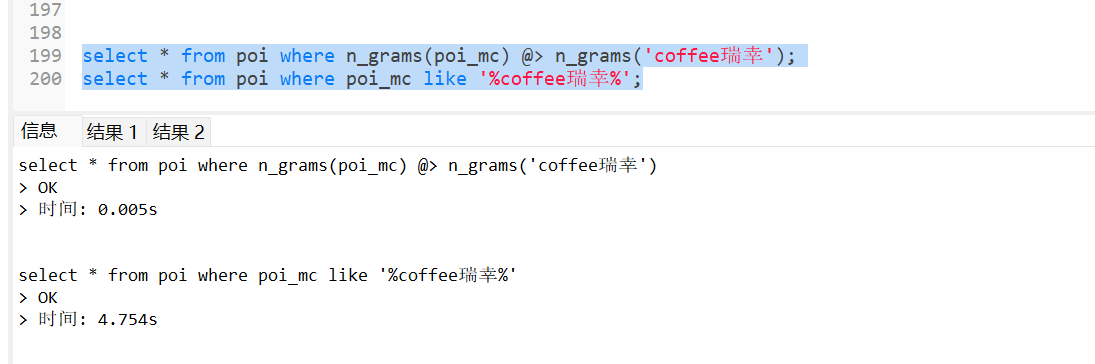
索引的占用空间,1000w数据约为400m,这只是我测试时的大小。实际大小还要取决于建索引的字段内容

三、参考致谢
PostgreSQL: Documentation: 12: F.31. pg_trgm
PostgreSQL: Documentation: 12: 8.11. Text Search Types