一、线程池状态
线程结构关系
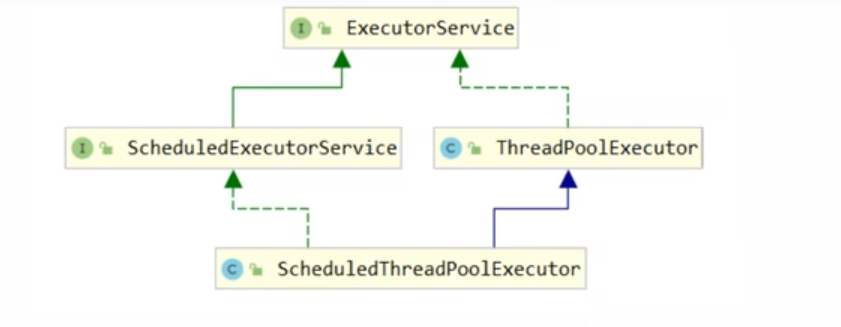
ThreadPoolExecutor使用int的高3位来表示线程池状态,低29位标识线程数量.
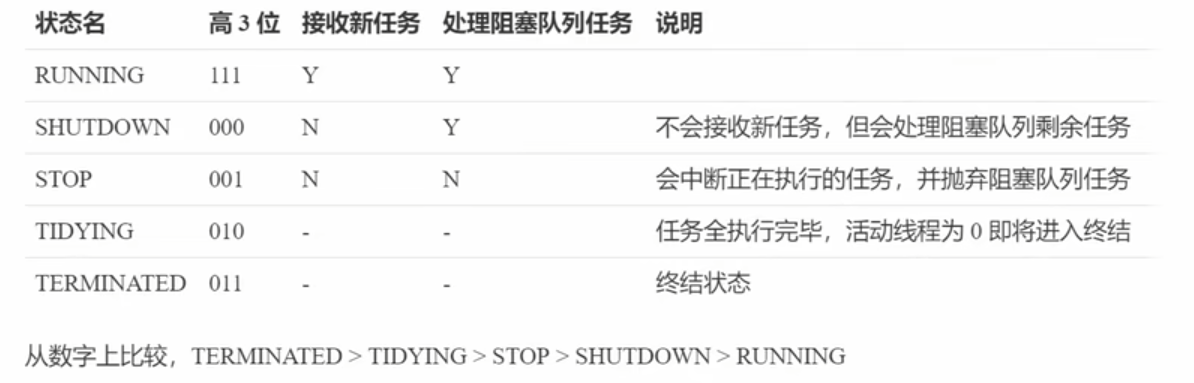
注意 : 第一位为符号位,所以RUNNING状态为负数,最小.
这些信息存储在一个原子变量ctl中,目的是将线程池状态与线程个数合二为一,这样就可以用一次cas原子操作进行赋值.
java
// c 为旧值,ctlOf返回结果为新值
ctl.compareAndSet(c,ctlOf(targetState,workerCountOf(c)));
// rs 为高3位代表线程池状态, wc 为低29位代表线程个数,ctl 是合并它们
private static inbt ctlOf(int rs,int wc)
{
return rs | wc;
}二、线程池七大核心参数
查看线程ThreadPoolExecutor的构造方法

- corePoolSize: 核心线程数目(最终能够保留的最多的线程数)
- maximumPoolSize: 最大的线程数目
- keepAliveTime: 线程的生存时间,也就是空闲线程的存活时间(针对救急线程而不是核心线程)
- unit: 存活时间的单位.
- workQueue: 阻塞队列,核心线程数处理不过来的任务,首先都是放入阻塞队列当中
- threadFactory: 线程工厂,可以给线程创建一个名字,方便日志追踪
- handler: 拒绝策略.
(一) 拒绝策略
- AbortPolicy: 让调用者抛出RejectedExecutionException异常,这是默认策略
- CallerRunsPolicy: 让调用者直接调用run方法.
- DiscardPolicy: 放弃本次任务
- DiscardOldestPolicy: 放弃队列中最早的任务,将本任务取而代之.

java
new ThreadPoolExecutor.AbortPolicy() //默认,抛异常
new ThreadPoolExecutor.DiscardPolicy()//直接放弃
new ThreadPoolExecutor.CallerRunsPolicy()//调用run
new ThreadPoolExecutor.DiscardOldestPolicy()//放弃最早的任务,也就是等待最久的任务三、默认线程池
jdk帮我们默认实现了几种线程池
(一) newFixedThreadPool
java
// 创建一个固定大小的线程池,核心线程数与最大线程数均为2,队列容量为Integer.MAX_VALUE
ExecutorService threadPool = Executors.newFixedThreadPool(2);(二) newCachedThreadPool
java
// 缓存线程池,核心线程数为0,最大线程数为Integer.MAX_VALUE,来一个任务就创建一个线程执行,
//队列为SynchronousQueue
//synchronized队列,只有线程来获取到任务,队列才可以往里面插入任务
//适合执行很多短期异步任务,每个线程存活时间为60s
ExecutorService threadPool1 = Executors.newCachedThreadPool();(三) newSingleThreadExecutor
java
// 单线程线程池,核心线程数与最大线程数均为1,队列容量为Integer.MAX_VALUE
//适合执行少量耗时的同步任务,每个任务都是串行执行
//一个任务抛出异常,其他的任务将会创建一个新的线程执行
ExecutorService threadPool2 = Executors.newSingleThreadExecutor();四、自定义线程工厂
有时候我们可能需要排查日志,但是如果使用Jdk自带的线程工厂,会导致日志不清晰,不清楚这个线程池具体运用于哪种业务,所以我们需要自定义一个线程工厂来帮我们打印更有意义的日志
我们来查看一下JDK源码,看看JDK是如何打印线程日志的
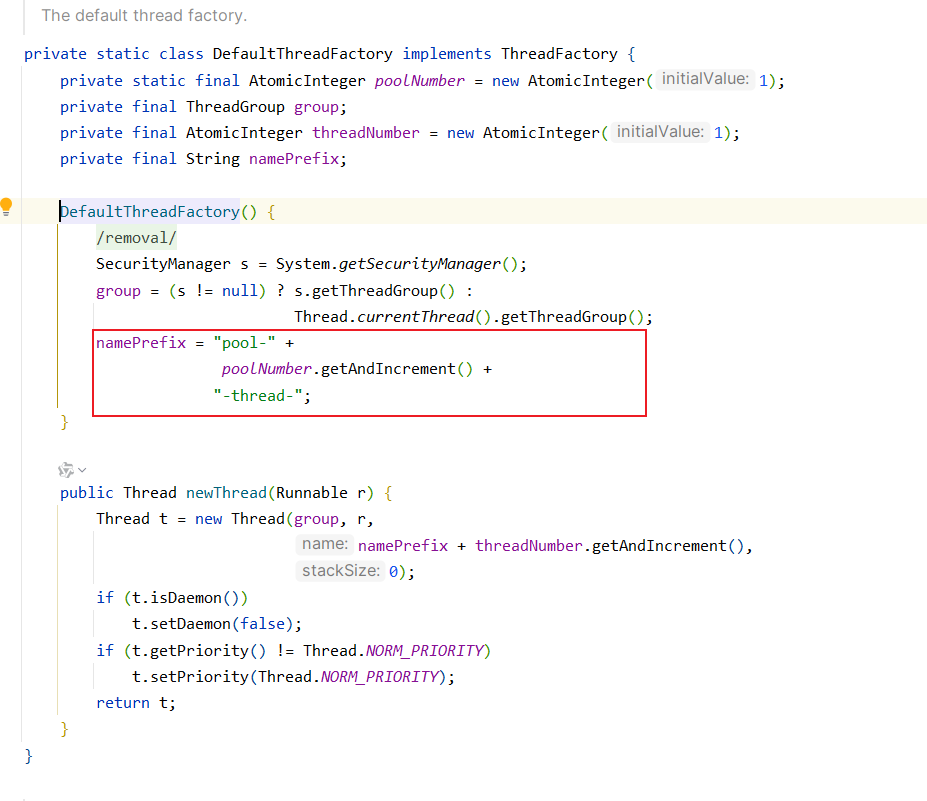
原来是通过AtomicInteger原子性CAS操作,是线程数加1.所以我们查看的日志就是namePrefix拼凑而成.我们可以效仿这样的方式,实现一个自己的线程工厂.
如:
java
public class LogThreadPoolFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
//传入线程池的名字参数
LogThreadPoolFactory(String prefix) {
@SuppressWarnings("removal")
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
//如果传入是空值,则恢复原来的线程池名
if(prefix == null || prefix.isEmpty()){
prefix = "pool";
}
namePrefix = prefix + "-" +
poolNumber.getAndIncrement() +
"-thread-";
}
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon()) {
t.setDaemon(false);
}
if (t.getPriority() != Thread.NORM_PRIORITY) {
t.setPriority(Thread.NORM_PRIORITY);
}
return t;
}
}五、饥饿问题
(一) 问题描述
饥饿问题是指,由于线程池分工不明确,也就是线程池可以做很多事情,由于线程池资源有限导致,其他任务不能正常执行,而导致饥饿问题出现.举例说明:
也就是像在饭馆,如果一个人可以点菜又可以做饭,另一个人同样也可以.
两个人都是点完菜之后,然后自己进入厨房开始做饭.
突然来了两个顾客,然后两个人都去点菜了,导致没有人去做菜,导致饥饿问题产生
体现到代码层面为:
java
// 饥饿问题: 线程池中线程数不足,导致任务积压,导致任务无法及时执行,导致程序卡死。
@Slf4j
public class HungryQuestionDemo {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(2);
threadPool.execute(()->{
log.info("开始点餐");
Future<String> future = threadPool.submit(() -> {
String cooking = cooking();
return cooking;
});
try {
log.info("菜品为:{}", future.get());
} catch (Exception e) {
e.printStackTrace();
}
});
threadPool.execute(()->{
log.info("开始点餐");
Future<String> future = threadPool.submit(() -> {
String cooking = cooking();
return cooking;
});
try {
log.info("菜品为:{}", future.get());
} catch (Exception e) {
e.printStackTrace();
}
});
}
private static final Random RANDOM = ThreadLocalRandom.current();
private static final String[] DISHES = {"肉夹馍", "火锅", "烤鸭", "麻辣烫"};
public static String cooking(){
return DISHES[RANDOM.nextInt(DISHES.length + 1)];
}
}执行结果

(二) 问题解决
我们明确线程池的分工,一个用来点菜,一个用来做饭,这样我们就能完美的解决问题.可以用上之前的自定义线程工厂
代码如下
java
//分类使用线程池
@Slf4j
public class HungryDealMethod {
public static void main(String[] args) {
ExecutorService order = Executors.newFixedThreadPool(1, new LogThreadPoolFactory("点餐员"));
ExecutorService cooker = Executors.newFixedThreadPool(1, new LogThreadPoolFactory("厨师"));
order.execute(()->{
log.info("开始点餐");
cooker.submit(() -> {
String cooking = cooking();
log.info("菜品为:{}", cooking);
return cooking;
});
});
order.execute(()->{
log.info("开始点餐");
cooker.submit(() -> {
String cooking = cooking();
log.info("菜品为:{}", cooking);
return cooking;
});
});
}
private static final Random RANDOM = ThreadLocalRandom.current();
private static final String[] DISHES = {"肉夹馍", "火锅", "烤鸭", "麻辣烫"};
public static String cooking(){
return DISHES[RANDOM.nextInt(DISHES.length + 1)];
}
}执行结果

六、定时线程池
(一) Timer
在jdk5时,引入了Timer的工具类,用来处理定时任务的处理.但是他有很多的局限性.所以在后面基本不会被使用了.但是我们可以了解定时线程池的由来,解决Timer什么问题.
Timer实际上是采用了单线程模式,这样会导致所有定时任务都是串行执行.
java
//timer 定时器: 定时执行任务,但是是单线程,串行执行
@Slf4j
public class TimerDemo {
public static void main(String[] args) throws InterruptedException {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.info("task1");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.info("task2");
}
};
log.info("start...");
timer.schedule(task1,1000);
timer.schedule(task2,1000);
Thread.sleep(3020);
timer.cancel();
}
}执行结果
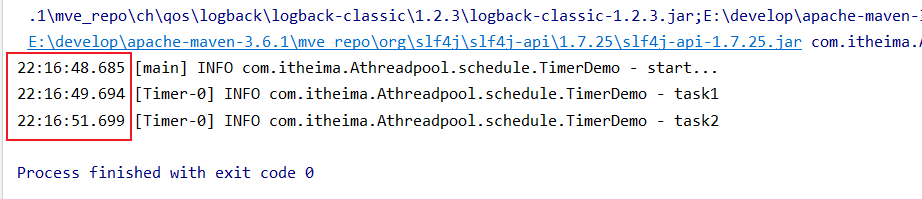
注意到,task1的执行任务时长影响到了task2的开始执行时间.
(二) ScheduledThreadPool
我们可以自定义线程池的大小,使一些定时任务并行执行(注意看注释,能够很好的帮助理解)
java
@Slf4j
public class ScheduleAPIDemo {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
// method1(scheduledThreadPool);
log.info("start...");
//2.按照固定速率执行任务,实际情况取间隔时间与执行时间的最大值,所以2秒后才执行第二次
//如果执行时间大于间隔时间,则以执行时间为准
// scheduledThreadPool.scheduleAtFixedRate(()->{
// log.info("schedule task");
// try {
// Thread.sleep(2000);
// } catch (InterruptedException e) {
// throw new RuntimeException(e);
// }
// },1,1, TimeUnit.SECONDS);
//3.按照固定时间间隔执行任务,等任务完成以后,才开始间隔时间的流逝,所以2+1=3秒后才第二次执行
//注意:线程池执行任务中如若有异常发生,是不会影响其他任务的执行的,而且不会抛出异常,所以建议在任务中捕获异常,并进行处理
//或者使用future.get()方法获取任务执行结果,如果有异常则获取的就是异常信息
scheduledThreadPool.scheduleWithFixedDelay(()->{
log.info("schedule task");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},1,1, TimeUnit.SECONDS);
}
private static void method1(ScheduledExecutorService scheduledThreadPool) {
//1.多线程可以并行执行(解决Timer单线程串行执行问题)
scheduledThreadPool.schedule(()->{
log.info("schedule task1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},1, TimeUnit.SECONDS);
scheduledThreadPool.schedule(()->{
log.info("schedule task2");
},1, TimeUnit.SECONDS);
}
}(三) 定时线程池的运用
假设我们现在需要每周四晚6点执行一个任务我们如何处理?
java
//让在一个时间点执行定时任务
//每周四下午6点执行一次任务
@Slf4j
public class ScheduleTest {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(1);
//获取到当前时间
LocalDateTime now = LocalDateTime.now();
//求得下一个定时任务执行的初始延迟时间
LocalDateTime time = now.withHour(18).withMinute(0).withSecond(0).withNano(0).with(DayOfWeek.THURSDAY);
System.out.println("start time: " + time);
//如果求出来的time小于now,则time需要增加一周.
if(now.isAfter(time)){
time = time.plusWeeks(1);
}
long innitDelayTime = Duration.between(now, time).toMillis();
System.out.println(innitDelayTime);
System.out.println("proccess time: " + time);
long period = 1000; // 1s
//innitDelayTime,初始等待时间
//period,间隔多长时间执行一次,也就是频率
//第三个参数代表前面两个参数的时间单位
scheduledThreadPool.scheduleAtFixedRate(()->{
log.info("runnning...");
},innitDelayTime,period, TimeUnit.MILLISECONDS);
}
}